
第4周小组作业:WordCount优化
github地址
https://github.com/FangStars/WCpro
PSP表格
PSP2.1 |
PSP阶段 |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
10 |
20 |
|
· Estimate |
· 估计这个任务需要多少时间 |
10 |
15 |
|
Development |
开发 |
400 |
450 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
80 |
100 |
|
· Design Spec |
· 生成设计文档 |
20 |
30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
30 |
40 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
5 |
10 |
|
· Design |
· 具体设计 |
50 |
55 |
|
· Coding |
· 具体编码 |
400 |
450 |
|
· Code Review |
· 代码复审 |
60 |
100 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
200 |
200 |
|
Reporting |
报告 |
100 |
120 |
|
· Test Report |
· 测试报告 |
40 |
50 |
|
· Size Measurement |
· 计算工作量 |
10 |
20 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
20 |
30 |
|
|
合计 |
1435 |
1690 |
接口设计
根据实验前的调查与讨论,本次实验分为四个模块,分别为main(input),scan,sort,writetxt。其中main负责接受输入,scan用来统计单词的数量,sort用来排序,writetxt用来实现文本输出。我负责的模块为sort,根据讨论的结果,输入的接口为scan返回的map数组,该数组key对应单词,int值对应的是单词数目,返回一个输出结果的string以便writetxt输出。
代码如下:
1 public class sort { 2 3 public static String SortMap(Map<String,Integer> oldmap){ 4 5 ArrayList<Map.Entry<String,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(oldmap.entrySet()); 6 7 Collections.sort(list,new Comparator<Map.Entry<String,Integer>>(){ 8 @Override 9 public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { 10 return o2.getValue() - o1.getValue(); //降序 11 } 12 }); 13 StringBuilder p=new StringBuilder(); 14 for(int i = 0; i<list.size(); i++){ 15 System.out.println(list.get(i).getKey()+ ": " +list.get(i).getValue()); 16 p.append(list.get(i).getKey()+ ": " +list.get(i).getValue()+"\r\n"); 17 } 18 String res=p.toString(); 19 return res; 20 } 21 22 }
测试设计过程
测试用例的设计首先根据需求来设计,我负责的模块主要根据排序算法所产生的边界来设计,如map数组中只有一对数据的时候,或有多组数据的int值相同的时候,或不同字符对应的int值完全倒序或者部分倒序的情况,即将排序可能出现的各种情况进行考虑,将其加入测试用例。为了保证该模块的正确性,主要采取的是白盒测试,采取部分的黑盒测试输出来验证正确性。
|
Test Case ID 测试用例编号 |
Test Item 测试项 (功能模块或函数) |
Test Criticality 重要级别 |
Pre-condition 预置条件 |
Input 输入 | Procedure 操作步骤 |
Output 预期结果 |
Result 实际结果 |
Status 是否通过 |
Remark 备注 (在此描述使用的测试方法) |
| sort_1 | sort | L | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_2 | sort | L | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_3 | sort | M | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_4 | sort | L | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_5 | sort | L | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_6 | sort | L | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_7 | sort | M | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_8 | sort | M | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_9 | sort | M | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_10 | sort | L | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_11 | sort | H | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_12 | sort | H | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_13 | sort | H | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_14 | sort | L | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_15 | sort | M | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_16 | sort | L | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_17 | sort | M | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_18 | sort | H | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_19 | sort | H | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_20 | sort | H | 无 | map数组 | 无 | true | true | Y | 白盒测试 |
| sort_21 | sort | M | 无 | map数组 | 无 | String | String | Y | 黑盒测试 |
| sort_22 | sort | M | 无 | map数组 | 无 | String | String | Y | 黑盒测试 |
| sort_23 | sort | H | 无 | map数组 | 无 | String | String | Y | 黑盒测试 |
单元测试的时候通过对scan返回的map数组的分析,可知输入的为各个单词以及对应的数量,在进行测试的时候,首先自行判断测试用例文本各个单词的词频情况,并自行加入map数组,然后再使用sort函数分析测试用例,然后将两个string进行比对。以下为其中一个单元测试例子
1 @Test 2 public void testSortMap4() { 3 Map<String, Integer> testMap = new HashMap<String, Integer>(); 4 testMap.put("test2", 5); 5 testMap.put("test1", 66); 6 StringBuilder p=new StringBuilder(); 7 p.append("test1"+ ": " +66+"\r\n"); 8 p.append("test2"+ ": " +5+"\r\n"); 9 String t=p.toString(); 10 assertEquals(t, sort.SortMap(testMap)); 11 }
单元测试截图
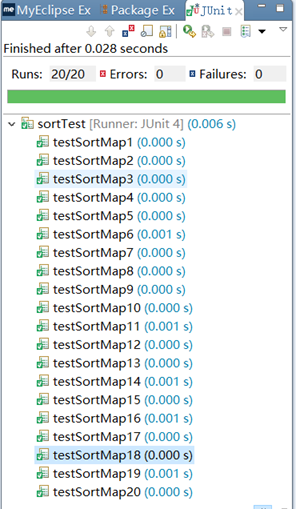
开发规范说明
选择的是Google Java编程风格指南
中文版链接:https://blog.csdn.net/zen99t/article/details/50763231
代码分析
评审的是scan模块(学号:U201517079)的代码,该代码基本符合编程规范。其中有所不符合的是代码大括号的使用,规范说明大括号前不要换行,但该模块中的代码有的进行了换行,有的则没有,这是不够好的。命名规范方面,该模块与规范一致,类名都以UpperCamelCase风格编写,方法名都以lowerCamelCase风格编写,参数名以lowerCamelCase风格编写等。
静态代码检查工具
采用了多种工具,并比对发现各种工具的检测规则不尽相同。
有PMD,findbugs,checkstyle,所需插件均能在该站点找到:http://sourceforge.net/
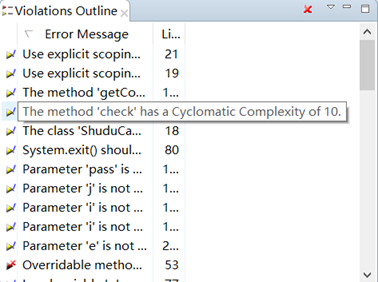
工具扫描结果
PMD和findbugs扫描结果都为无错误,选用其他代码进行展示错误结果。
PMD:
Findbugs:


Checkstyle:
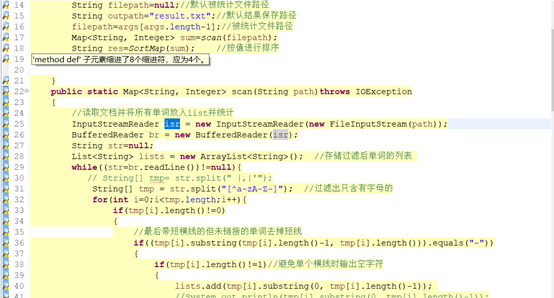
Checkstyle规范较为严格,对缩进空格有着严格的规定,导致所有代码都不符合规范,而findbugs和PMD则发现不了问题。这说明本次实验代码还是较为符合编程规范的。其遵循的好的规范主要都在Google Java编程风格指南中可以找到。
小组代码分析
本次小组实验的代码基本还是比较符合规范的,就是接口的设计不够好,模块划分的不够严谨,导致部分模块的代码可读性不够高。
数据集的设计思路
为了给程序带来压力,需要构建一个数据量足够大的txt文档,其中单词需要足够的多,不仅如此,为了能够给代码带来足够的考验,单词的种类也需要不同,即要有很多不同的单词,此时可以找到多篇英文文章连在一起即可。最后采用的txt文档总行数为3126行,单元数有785128个,此时的数据量已经足够大了。
性能指标
采用的性能指标为时间的长短。
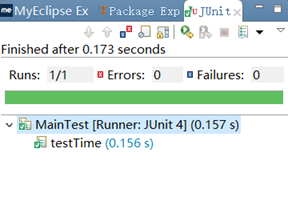
数据加倍之后:
可以发现程序的效率还是非常高的。
同行评审
全部组员都参加了同行评审,由组长进行主持,主要评审的模块是scan和sort模块,由于这两个模块消耗资源较多,所以需要进行评审改进。通过对实验需求的研究和模块效率的实验,最终评审的结论为,由于这两个模块采用的函数都是使用的Java内置函数来解决,如split(),map数组的排序等,所以效率应该最大化,不需要太大的改进。
测试结果
经过多次对比测试,可知影响效率的主要因素为scan和sort函数以及输入txt的大小。结果与评审结果一致,无需对函数进行改进,效率已经很高了。
实践总结
经过整个任务的过程,我认为软件开发、软件测试、软件质量之间的关系是,软件开发是基础,即首先应该完成项目的需求,软件测试要穿插其中,用来发现软件不符合需求的地方,软件质量可以放在最后来实现但也要时刻注意,用来提高整个项目的质量。这三个也是密不可分的,三者结合起来才能是项目实现的最好。
小组贡献
根据全员的讨论结果,我的小组贡献分为0.25
参考文献
https://blog.csdn.net/u010180815/article/details/52208924
https://blog.csdn.net/jaune161/article/details/40025861
https://www.cnblogs.com/bhlsheji/p/4807669.html
https://www.cnblogs.com/EasonJim/p/7685724.html
https://zhidao.baidu.com/question/117274778.html
https://blog.csdn.net/u013132051/article/details/54345742
https://www.cnblogs.com/fnlingnzb-learner/p/6018604.html
https://zhidao.baidu.com/question/406042091.html
https://www.cnblogs.com/huangye-dream/archive/2013/03/01/2938937.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号