
java基础编程——二维数组中的查找
题目描述
题目代码
import java.util.Scanner; /** * 题目描述 * 在一个二维数组中(每个一维数组的长度相同), * 每一行都按照从左到右递增的顺序排序, * 每一列都按照从上到下递增的顺序排序。 * 请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。 * Created by YuKai Fan on 2018/8/13. */ public class Solution { public static void main(String[] args) { Scanner scan = new Scanner(System.in); System.out.println("请输入查询的整数:"); int m = scan.nextInt(); int n = 4; int[][] array = new int[n][n]; System.out.println("请输入数组:"); for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { array[i][j] = scan.nextInt(); } } boolean find = find(m, array); System.out.println(find); } //自己写的方式:循环遍历二维数组,比较每个值 /* public static boolean Find (int target, int[][] array) { for (int i = 0; i < array.length; i++) { for (int j = 0; j <array[i].length; j++) { if (target == array[i][j]) { return true; } } } return false; }*/ /*别人的方式 把每一行看成有序递增的数组,利用二分查找,通过遍历每一行得到答案,时间复杂度是nlogn */ public static boolean Find (int target, int[][] array) { for (int i = 0; i < array.length; i++) { int low = 0; int high = array[i].length - 1; while (low <= high) { int mid = (low + high)/2; if (target > array[i][mid]) { low = mid + 1; } else if (target < array[i][mid]) { low = mid - 1; } else { return true; } } } return false; } /* 别人的方式2: 利用二维数组由上到下,由左到右递增的规律, 那么选取右上角或者左下角的元素a[row][col]与target进行比较, 当target小于元素a[row][col]时,那么target必定在元素a所在行的左边, 即col--; 当target大于元素a[row][col]时,那么target必定在元素a所在列的下边, 即row++; */ public static boolean find(int target, int[][] array) { int row = 0; int col = array[0].length - 1; while (row <= array.length - 1 && col >= 0) { if (target == array[row][col]) { return true; } else if (target > array[row][col]) { row++; } else { col--; } } return false; } }
题目延伸
在上面代码中用到了二分查找,所以这里想回顾一下二分查找的算法
1.二分查找又称折半查找,它是一种效率较高的查找方法。
2.二分查找要求:(1)必须采用顺序存储结构 (2).必须按关键字大小有序排列
3.原理:将数组分为三部分,依次是中值(所谓的中值就是数组中间位置的那个值)前,中值,中值后;将要查找的值和数组的中值进行比较,若小于中值则在中值前 面找,若大于中值则在中值后面找,等于中值时直接返回。然后依次是一个递归过程,将前半部分或者后半部分继续分解为三部分。
4.实现:二分查找的实现用递归和循环两种方式
22 //递归实现二分查找 23 public static int binarySearch(int[] dataset,int data,int beginIndex,int endIndex){ 24 int midIndex = (beginIndex+endIndex)/2; 25 if(data <dataset[beginIndex]||data>dataset[endIndex]||beginIndex>endIndex){ 26 return -1; 27 } 28 if(data <dataset[midIndex]){ 29 return binarySearch(dataset,data,beginIndex,midIndex-1); 30 }else if(data>dataset[midIndex]){ 31 return binarySearch(dataset,data,midIndex+1,endIndex); 32 }else { 33 return midIndex; 34 } 35 } 36 37 public static void main(String[] args) { 38 int[] arr = { 6, 12, 33, 87, 90, 97, 108, 561 }; 39 System.out.println("循环查找:" + (binarySearch(arr, 87) + 1)); 40 System.out.println("递归查找"+binarySearch(arr,3,87,arr.length-1)); 41 } 42 }
因为二分查找需要方便地定位查找区域,所以适合二分查找的存储结构必须具有随机存储的特性。因此,该查找方法仅适合于线性表的顺序存储结构,不适合链式存储结构,且要求元素按关键字有序排列。
判定树:
二分查找的过程可以用下图表示,称为判定树。树中每个圆形节点表示一个纪录,节点中的值表示为该记录的关键字值:树中最下面叶节点都是方形的,它表示查找不成功的情况。从判定树中可以看出,查找成功时查找的查找长度为从根节点到目的节点的路径上的节点数,而查找不成功时的查找长度为从根节点到对应失败节点的父节点的父节点路径上的节点数;每个节点值均大于其左子节点值,且均小于右子节点值。若有序序列有n个元素,这对应的判定树有n个圆形的非叶节点和n+1个方形的叶节点。
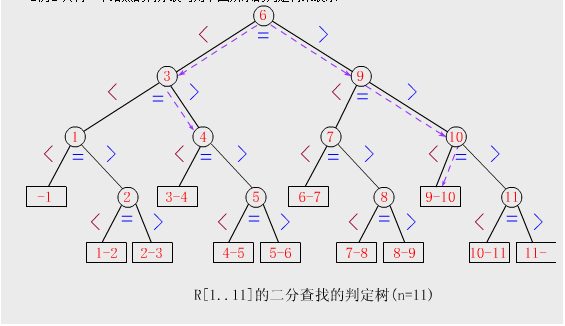
上图中,n个圆形节点(代表有序序列有n个元素)构成的树的深度与n个节点完全二叉树的深度(高度)相等,均为⌊log2n⌋+1或⌈log2(n+1)⌉
二分查找的时间复杂度为O(log2N),比顺序查找的效率高。
由上述分析可知,用二分查找到给定值或查找失败的比较次数最多不会超过树的高度。查找成功与不成功,最坏的情况下,都需要比较⌊log2n⌋+1次。
二分查找的优点和缺点
虽然二分查找的效率高,但是要将表按关键字排序。而排序本身是一种很费时的运算。既使采用高效率的排序方法也要花费O(nlgn)的时间。
二分查找只适用顺序存储结构。为保持表的有序性,在顺序结构里插入和删除都必须移动大量的结点。因此,二分查找特别适用于那种一经建立就很少改动、而又经常需要查找的线性表。
对那些查找少而又经常需要改动的线性表,可采用链表作存储结构,进行顺序查找。链表上无法实现二分查找。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号