008 项目优化与测试20378e0d-a2a6-4844-be26-3edc090c71d4

文章目录
前言
本文将会对高并发项目进行优化与测试
一、大于256KB的大块内存申请与释放问题
在threadcache中,每次申请内存对象都是小于等于256KB的,而对大于256KB的内存可以向pagecache中申请,而大于128页的内存的申请,就只能向堆申请了
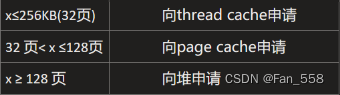
于是我们就需要修改AlignUp划分对齐范围函数,将大于256KB地内存申请按照一页大小对齐
//划分对齐范围
static inline size_t AlignUp(size_t size)
{
if (size < 128)
{
return _AlignUp(size, 8);
}
else if (size <= 1024)
{
return _AlignUp(size, 16);
}
else if (size <= 64*1024)
{
return _AlignUp(size, 128);
}
else if (size <= 128*1024)
{
return _AlignUp(size, 1024);
}
else if (size <= 256*1024)
{
return _AlignUp(size, 8*1024);
}
else
{
return _AlignUp(size, 1 << PAGE_SHIFT); //大于256KB的内存申请按页对齐
}
}
当申请内存对象的大小大于256KB时,就不从threadcache中申请了,计算出所申请的对齐后的内存大小,再计算出按页对齐所需申请的页数,通过调用NewSpan函数申请指定页数的span即可
static void* ConcurrentAlloc(size_t size)
{
if (size > MAX_BYTES)
{
size_t alignSize = AlignmentRules::AlignUp(size); //对齐数
size_t Kpage = alignSize >> PAGE_SHIFT; //页数
PageCache::GetInstance()->_pageMutex.lock();
Span* span = PageCache::GetInstance()->NewSpan(Kpage); //获取一个k页的span
span->_objSize = size;
PageCache::GetInstance()->_pageMutex.unlock();
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
return ptr;
}
else
{
if (pTLSThreadCache == nullptr)
{
static ObjectPool<ThreadCache> tcPool;
PageCache::GetInstance()->_threadMtx.lock();
pTLSThreadCache = tcPool.New();
PageCache::GetInstance()->_threadMtx.unlock();
//pTLSThreadCache = new ThreadCache;
}
//cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;
return pTLSThreadCache->Allocate(size);
}
}
另外地,当申请页数超过128页的时候,我们就不能从pagecache中申请了,因为pagecache支持申请的最大页数为128页,这时我们需要对NewSpan函数进行改动
//获取一个k页的span
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0);
if (k > NPAGES - 1) //大于128页直接找堆申请
{
void* ptr = SystemAlloc(k);
Span* span = new Span;
span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
span->_n = k;
//建立页号与span之间的映射
_idSpanMap[span->_pageId] = span;
return span;
}
//先检查第k个桶里面有没有span
if (!_spanLists[k].Empty())
{
Span* kSpan = _spanLists[k].PopFront();
//建立页号与span的映射,方便central cache回收小块内存时查找对应的span
for (PAGE_ID i = 0; i < kSpan->_n; i++)
{
_idSpanMap[kSpan->_pageId + i] = kSpan;
}
return kSpan;
}
//检查一下后面的桶里面有没有span,如果有可以将其进行切分
for (size_t i = k + 1; i < NPAGES; i++)
{
if (!_spanLists[i].Empty())
{
Span* nSpan = _spanLists[i].PopFront();
Span* kSpan = new Span;
//在nSpan的头部切k页下来
kSpan->_pageId = nSpan->_pageId;
kSpan->_n = k;
nSpan->_pageId += k;
nSpan->_n -= k;
//将剩下的挂到对应映射的位置
_spanLists[nSpan->_n].PushFront(nSpan);
//存储nSpan的首尾页号与nSpan之间的映射,方便page cache合并span时进行前后页的查找
_idSpanMap[nSpan->_pageId] = nSpan;
_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;
//建立页号与span的映射,方便central cache回收小块内存时查找对应的span
for (PAGE_ID i = 0; i < kSpan->_n; i++)
{
_idSpanMap[kSpan->_pageId + i] = kSpan;
}
return kSpan;
}
}
//走到这里说明后面没有大页的span了,这时就向堆申请一个128页的span
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
_spanLists[bigSpan->_n].PushFront(bigSpan);
//尽量避免代码重复,递归调用自己
return NewSpan(k);
}
同样地,当释放对象的时候,也需要先判断对象的大小
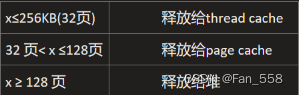
释放对象的时候,首先应确认该对象是属于哪一个span的,需要根据传入的ptr起始地址根据映射关系找到对应的span
static void ConcurrentFree(void* ptr, size_t size)
{
if (size > MAX_BYTES) //大于256KB的内存释放
{
Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
}
else
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
}
同样地,需要对ReleaseSpanToPageCache函数模块进行修改,如果span的大小是大于128页的,直接将这块内存释放给堆,然后将span结构delete掉,如果是小于等于128页的就交给pagecache进行合并
//释放空闲的span回到PageCache,并合并相邻的span
void PageCache::ReleaseSpanToPageCache(Span* span)
{
if (span->_n > NPAGES - 1) //大于128页直接释放给堆
{
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
SystemFree(ptr);
delete span;
return;
}
//对span的前后页,尝试进行合并,缓解内存碎片问题
//1、向前合并
while (1)
{
PAGE_ID prevId = span->_pageId - 1;
auto ret = _idSpanMap.find(prevId);
//前面的页号没有(还未向系统申请),停止向前合并
if (ret == _idSpanMap.end())
{
break;
}
//前面的页号对应的span正在被使用,停止向前合并
Span* prevSpan = ret->second;
if (prevSpan->_isUse == true)
{
break;
}
//合并出超过128页的span无法进行管理,停止向前合并
if (prevSpan->_n + span->_n > NPAGES - 1)
{
break;
}
//进行向前合并
span->_pageId = prevSpan->_pageId;
span->_n += prevSpan->_n;
//将prevSpan从对应的双链表中移除
_spanLists[prevSpan->_n].Erase(prevSpan);
delete prevSpan;
}
//2、向后合并
while (1)
{
PAGE_ID nextId = span->_pageId + span->_n;
auto ret = _idSpanMap.find(nextId);
//后面的页号没有(还未向系统申请),停止向后合并
if (ret == _idSpanMap.end())
{
break;
}
//后面的页号对应的span正在被使用,停止向后合并
Span* nextSpan = ret->second;
if (nextSpan->_isUse == true)
{
break;
}
//合并出超过128页的span无法进行管理,停止向后合并
if (nextSpan->_n + span->_n > NPAGES - 1)
{
break;
}
//进行向后合并
span->_n += nextSpan->_n;
//将nextSpan从对应的双链表中移除
_spanLists[nextSpan->_n].Erase(nextSpan);
delete nextSpan;
}
//将合并后的span挂到对应的双链表当中
_spanLists[span->_n].PushFront(span);
//建立该span与其首尾页的映射
_idSpanMap[span->_pageId] = span;
_idSpanMap[span->_pageId + span->_n - 1] = span;
//将该span设置为未被使用的状态
span->_isUse = false;
}
二、用定长内存池替换new
tcmalloc是要在高并发场景下替代malloc的,因此我们在此项目中是不能使用malloc函数的,也就是说不能使用new申请内存(底层为malloc)
三层框架的存在threadcache->centralcache->pagecache一层没有内存就往下一层找,注定了我们是需要在pagecache这一层申请内存
定义一个定长内存池类的对象
class PageCache
{
public:
//...
private:
ObjectPool<Span> _spanPool;
};
将原来的new和delete的地方全部替换成从定长内存池中申请,而定长内存池就是直接向直接调用VirtualAlloc函数在进程的虚拟地址空间中分配内存。
//申请span对象
Span* span = _spanPool.New();
//释放span对象
_spanPool.Delete(span);
注意:在多线程的场景下访问定长内存池需要加锁,在new,delete的地方进行加锁解锁
//单例模式:饿汉
class PageCache
{
public:
std::mutex _pageMutex;
std::mutex _threadMtx; //访问定长内存池的时候加锁
};
三、释放对象的函数优化为不传对象大小
当我们使用malloc函数申请内存时,需要指明申请内存的大小;而当我们使用free函数释放内存时,只需要传入指向这块内存的指针即可。而我们目前实现的内存池,在释放对象时除了需要传入指向该对象的指针,还需要传入该对象的大小。
1、如果释放的是大于256KB的对象,需要根据对象的大小来判断这块内存到底应该还给page cache,还是应该直接还给堆。
2、如果释放的是小于等于256KB的对象,需要根据对象的大小计算出应该还给thread cache的哪一个哈希桶。
因此在释放对象的时候不传入对象的大小,就需要用对象地址通过映射找到对应地span
基于此,修改span结构,增加一个_objSize变量
//管理以页为单位的大块内存
struct Span
{
//给缺省值,可以不用提供构造函数
PAGE_ID _pageId = 0; //大块内存起始页的页号(从堆上分配内存的起始地址
size_t _n = 0; //页的数量
Span* _next = nullptr; //双链表结构
Span* _prev = nullptr;
size_t _objSize = 0; //切好的小对象的大小
size_t _useCount = 0; //切好的小块内存,被分配给thread cache的计数
void* _freeList = nullptr; //切好的小块内存的自由链表
bool _isUse = false; //是否在被使用
};
如果释放的内存大于256KB,直接交给ReleaseSpanToPageCache进行处理,如果小于256KB就释放到thread cache存储小内存对象的自由链表中
//释放_freeList
static void ConcurrentFree(void* ptr)
{
Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);
size_t size = span->_objSize;
if (size > MAX_BYTES)
{
PageCache::GetInstance()->_pageMutex.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMutex.unlock();
}
else
{
//每一个线程都会有一个pTLSThreadCache对象
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
}
大于128页的内存直接释放给堆,小于128页的内存,进行前后合并
//释放空闲的span回到PageCache,并合并相邻的span
void PageCache::ReleaseSpanToPageCache(Span* span)
{
if (span->_n > NPAGES - 1) //大于128页直接释放给堆
{
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
SystemFree(ptr);
delete span;
return;
}
//对span的前后页,尝试进行合并,缓解内存碎片问题
//1、向前合并
while (1)
{
PAGE_ID prevId = span->_pageId - 1;
auto ret = _idSpanMap.find(prevId);
//前面的页号没有(还未向系统申请),停止向前合并
if (ret == _idSpanMap.end())
{
break;
}
//前面的页号对应的span正在被使用,停止向前合并
Span* prevSpan = ret->second;
if (prevSpan->_isUse == true)
{
break;
}
//合并出超过128页的span无法进行管理,停止向前合并
if (prevSpan->_n + span->_n > NPAGES - 1)
{
break;
}
//进行向前合并
span->_pageId = prevSpan->_pageId;
span->_n += prevSpan->_n;
//将prevSpan从对应的双链表中移除
_spanLists[prevSpan->_n].Erase(prevSpan);
delete prevSpan;
}
//2、向后合并
while (1)
{
PAGE_ID nextId = span->_pageId + span->_n;
auto ret = _idSpanMap.find(nextId);
//后面的页号没有(还未向系统申请),停止向后合并
if (ret == _idSpanMap.end())
{
break;
}
//后面的页号对应的span正在被使用,停止向后合并
Span* nextSpan = ret->second;
if (nextSpan->_isUse == true)
{
break;
}
//合并出超过128页的span无法进行管理,停止向后合并
if (nextSpan->_n + span->_n > NPAGES - 1)
{
break;
}
//进行向后合并
span->_n += nextSpan->_n;
//将nextSpan从对应的双链表中移除
_spanLists[nextSpan->_n].Erase(nextSpan);
delete nextSpan;
}
//将合并后的span挂到对应的双链表当中
_spanLists[span->_n].PushFront(span);
//建立该span与其首尾页的映射
_idSpanMap[span->_pageId] = span;
_idSpanMap[span->_pageId + span->_n - 1] = span;
//将该span设置为未被使用的状态
span->_isUse = false;
}
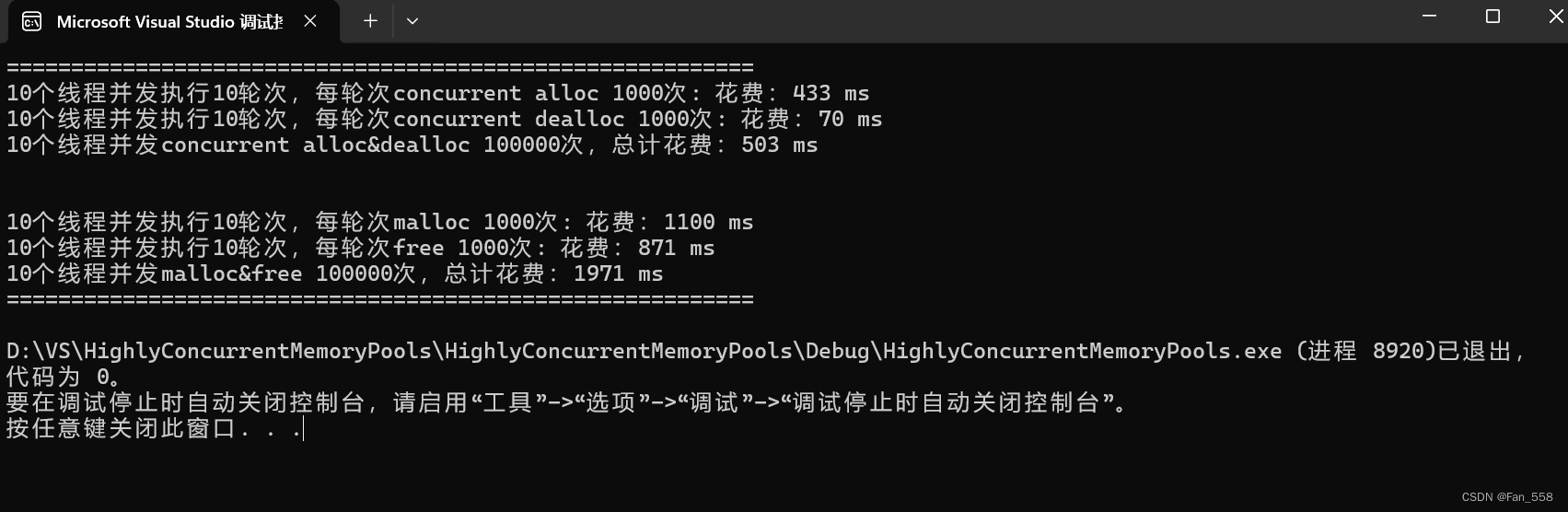
四、多线程环境下对比malloc测试
其中测试函数各个参数的含义如下:
ntimes:单轮次申请和释放内存的次数。
nworks:线程数。
rounds:轮次。
nworks个线程跑rounds轮,每轮申请和释放ntimes次,计算申请所消耗的时间、释放所消耗的时间、申请和释放总共消耗的时间
固定大小内存的申请和释放:
v.push_back(malloc(16));
v.push_back(ConcurrentAlloc(16));
不同大小内存的申请和释放:
v.push_back(malloc((16 + i) % 8192 + 1));
v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
以下是测试代码,了解即可
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)//ntime一轮申请和释放内存的次数,round是跑多少轮,nworks是线程数
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]()
{
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(malloc(16));
v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(ConcurrentAlloc(16));
v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
int main()
{
size_t n = 1000;
cout << "==========================================================" << endl;
BenchmarkConcurrentMalloc(n, 10, 10);
cout << endl << endl;
BenchmarkMalloc(n, 10, 10);
cout << "==========================================================" << endl;
return 0;
}
你可以看到该项目的设计的申请释放内存的接口效率依旧是比不上malloc与free的
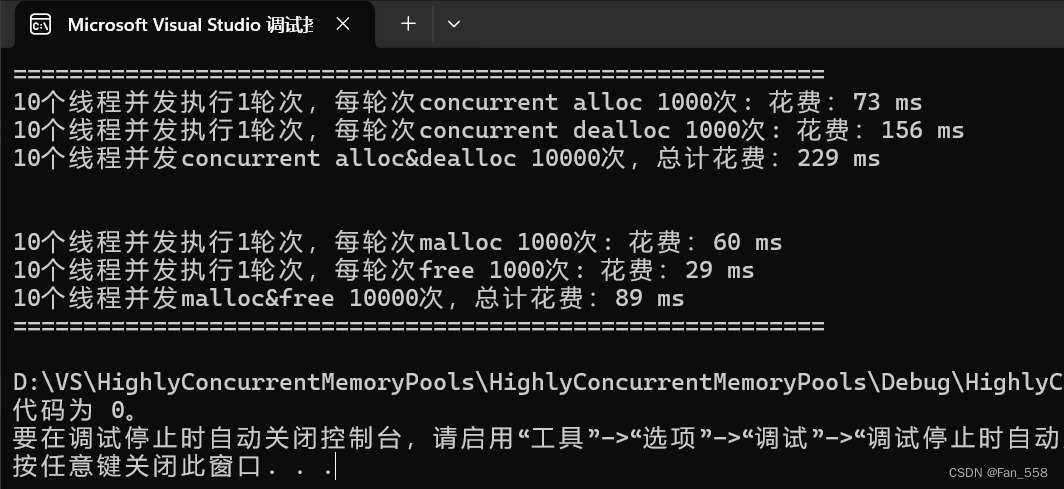
实际上,我们还需要对此项目进行最后的优化
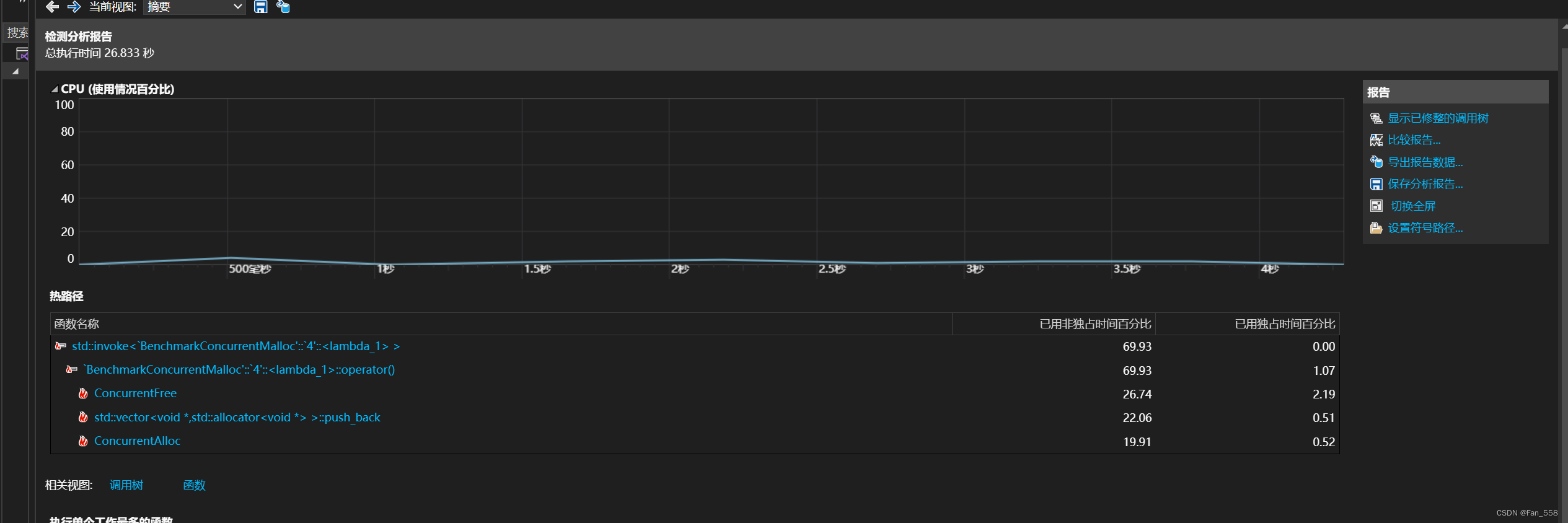
五、性能瓶颈分析
在debug模式下打开性能探查器
你会观察到,在释放内存逻辑里,是需要频繁调用MapObjectToSpan函数访问span与页号的映射关系的,而在访问映射的过程中,为了线程安全,我们给其加锁,频繁地加锁解锁耗时严重,导致我们这个项目的申请与释放的效率比malloc,free要差,在源项目tcmalloc中针对访问映射加锁问题,采用了基数树进行优化,使得在读取映射关系的时候可以做到不加锁
六、使用基数树解决性能瓶颈
为什么读取基数树映射关系的时候不需要加锁呢
当线程一正在读取映射关系时,可能线程二正在建立其页号与span的映射关系,我们采用C++中的map和unordered_map都是需要加锁的。
map的底层数据结构是红黑树,unordered_map的底层数据结构是哈希表,无论是哈希表还是红黑树在插入数据的时候整体结构都可能会发生变化,比如红黑树在插入数据可能会引起旋转,哈希表插入数据可能会扩容。
因此不能让插入操作和读取操作同时进行
基数树的空间一旦开辟好了就不会再发生变化,什么时候去读取某个页的映射,都是对应在一个固定的位置进行读取的,并且我们不会同时对一个页进行读取与建立映射(本质上是插入),因为只有在释放对象的时候才需要读取映射,建立映射的操作都是在pagecache中进行的,读取映射的span都是_usecount不为0的页,建立映射都是在申请一个span时建立映射,_usecount是等于0的,所以不会同时对一个页进行读取和建立映射的操作
基数树,不需要完全掌握
//单例模式
class PageCache
{
public:
//...
private:
//std::unordered_map<PAGE_ID, Span*> _idSpanMap;
TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap;
};
当需要建立页号与span的映射时,调用基数树当中的set函数。
修改对应代码
_idSpanMap.set(span->_pageId, span);
当需要读取某一页号对应的span时,调用基数树当中的get函数。
修改对应代码
Span* ret = (Span*)_idSpanMap.get(id);
// Single-level array
template <int BITS>
class TCMalloc_PageMap1 {
private:
static const int LENGTH = 1 << BITS;
void** array_;
public:
typedef uintptr_t Number;
//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {
explicit TCMalloc_PageMap1() {
//array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS));
size_t size = sizeof(void*) << BITS;
size_t alignSize = AlignmentRules::_AlignUp(size, 1 << PAGE_SHIFT);
array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);
memset(array_, 0, sizeof(void*) << BITS);
}
// Return the current value for KEY. Returns NULL if not yet set,
// or if k is out of range.
void* get(Number k) const {
if ((k >> BITS) > 0) {
return NULL;
}
return array_[k];
}
// REQUIRES "k" is in range "[0,2^BITS-1]".
// REQUIRES "k" has been ensured before.
//
// Sets the value 'v' for key 'k'.
void set(Number k, void* v) {
array_[k] = v;
}
};
// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:
// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.
static const int ROOT_BITS = 5;
static const int ROOT_LENGTH = 1 << ROOT_BITS;
static const int LEAF_BITS = BITS - ROOT_BITS;
static const int LEAF_LENGTH = 1 << LEAF_BITS;
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodes
void* (*allocator_)(size_t); // Memory allocator
public:
typedef uintptr_t Number;
//explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {
explicit TCMalloc_PageMap2() {
//allocator_ = allocator;
memset(root_, 0, sizeof(root_));
PreallocateMoreMemory();
}
void* get(Number k) const {
const Number i1 = k >> LEAF_BITS;
const Number i2 = k & (LEAF_LENGTH - 1);
if ((k >> BITS) > 0 || root_[i1] == NULL) {
return NULL;
}
return root_[i1]->values[i2];
}
void set(Number k, void* v) {
const Number i1 = k >> LEAF_BITS;
const Number i2 = k & (LEAF_LENGTH - 1);
ASSERT(i1 < ROOT_LENGTH);
root_[i1]->values[i2] = v;
}
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> LEAF_BITS;
// Check for overflow
if (i1 >= ROOT_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_[i1] == NULL) {
//Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));
//if (leaf == NULL) return false;
static ObjectPool<Leaf> leafPool;
Leaf* leaf = (Leaf*)leafPool.New();
memset(leaf, 0, sizeof(*leaf));
root_[i1] = leaf;
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
// Allocate enough to keep track of all possible pages
Ensure(0, 1 << BITS);
}
};
// Three-level radix tree
template <int BITS>
class TCMalloc_PageMap3 {
private:
// How many bits should we consume at each interior level
static const int INTERIOR_BITS = (BITS + 2) / 3; // Round-up
static const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;
// How many bits should we consume at leaf level
static const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;
static const int LEAF_LENGTH = 1 << LEAF_BITS;
// Interior node
struct Node {
Node* ptrs[INTERIOR_LENGTH];
};
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Node* root_; // Root of radix tree
void* (*allocator_)(size_t); // Memory allocator
Node* NewNode() {
Node* result = reinterpret_cast<Node*>((*allocator_)(sizeof(Node)));
if (result != NULL) {
memset(result, 0, sizeof(*result));
}
return result;
}
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap3(void* (*allocator)(size_t)) {
allocator_ = allocator;
root_ = NewNode();
}
void* get(Number k) const {
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
if ((k >> BITS) > 0 ||
root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL) {
return NULL;
}
return reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3];
}
void set(Number k, void* v) {
ASSERT(k >> BITS == 0);
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v;
}
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
// Check for overflow
if (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_->ptrs[i1] == NULL) {
Node* n = NewNode();
if (n == NULL) return false;
root_->ptrs[i1] = n;
}
// Make leaf node if necessary
if (root_->ptrs[i1]->ptrs[i2] == NULL) {
Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));
if (leaf == NULL) return false;
memset(leaf, 0, sizeof(*leaf));
root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node*>(leaf);
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
}
};
这时项目设计的申请释放内存函数就比malloc,free快了
小结
项目就到这里结束了,写完项目后一定要及时记得梳理哦~ 如果本文存在疏漏或错误的地方还请您能够指出,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号