软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 |
|
| 其他参考文献 | 博客园、CSDN、简书 |
| GitHub项目地址 | PersonalProject-Java |
一、阅读《构建之法》并提问
问题
1、文中第36页提到了PSP的一些特点,
不依赖于考试,而主要靠工程师自己收集数据,实际耗时通过对时间的记录可以得到较为准确的数值,但是预估耗时又该怎么样去估算呢?我觉得这部分的数据不太好得到,甚至会和实际耗时产生很大的偏差,毕竟软件的编程过程中遇到的问题是不可预料的。比如在软件编程中,可能会有需要学习新技术,但在你甚至对一个技术不了解的情况下,又要怎么去估计你要花多长时间去学习并能使用呢?就比如我在这次的编程作业中,发现使用正则表达式可以使用,但是学习过程中确发现这也并不简单(可能是我水平不行的原因/(ㄒoㄒ)/~~)。文中说PSP的目的是记录工程师如何实现需求的效率,那进行这种记录是否可以提高我们的个人水平的呢?如果可以的话又是怎么提高的呢?在搜寻了网上资料和老师的解答后,我觉得是可以的,PSP表格通过任务分解、预估子任务实际、统计实际时间,进而发现哪些子任务存在效率低下情况,加以改进。这样可以帮助我们更有效的发现自己不足的地方,以便有针对性的提升。
2、书中第51页提到了
团队对个人的期望,其中有一点是理性的工作。我对这一点有一些疑问和其他的想法。书中说一个成熟的团队必须从事实和数据出发,按照流程,理性地工作,但软件开发有很多个人的、感情驱动的因素,这些因素说不定能带来意想不到的效果。正如书中在第十二章用户体验中所说的,做产品需要有“同理心”,如果在开发时只是理性的分析数据,而不去用感性的思维将自己代入用户的角度,这样的产品可能就得不到良好的用户体验。再者,如果一味地跟从数据,最后会不会导致软件千篇一律,没有特点?1985年,微软的工程师Steve Hazelrig写Mac Excel打印功能时,如果不是因为感性原因(懒得跑到打印机取打印纸检查打印效果),那可能就不会被发现“打印预览”这一功能。所以我认为,在软件开发时,页不能只想着理性工作,多点感性的分析也许会带来更好的效果。
3、在书中的第53页提到
过早的优化是一切罪恶的根源,这句话其实让我惊讶的,因为我以前在编程的过程中,也是在每一个部分都想着会不会有更好的解决方法,也由此拉长了项目完成的时间,但好像除此之外并没什么什么严重的后果,而且在后文第80则说到了越是项目后期发现的问题,修复的代价越大。这就让我产生了更多的矛盾。是不是我对过早优化的概念理解的有误?文中说工程师在某一个局部问题上陷进去花大量的时间对其进行优化,无视这个模块对全局的重要性。是不是说由于工程师的“钻牛角尖”,在局部问题上思考的太多,甚至偏理了原来的全局,是不是说对于某个局部问题可以在保证全局方向正确的条件下进行合理的优化,是否意味着过早优化中的“过早”,指的不是时间顺序中的早和晚,而是处理这个问题的时机。我的想法是,我们遇到某个局部问题时,还是需要去考虑能否进行优化,但是还是要考虑此时的优化对全局会带来什么样的影响,如果与全局的方向一致且会对全局产生比较大的影响,这样的问题还是要尽早优化,而对于全局影响较小的,可以暂时不考虑,毕竟随着开发过程的进行可能会带来不同的变化。但是我对某个问题到底要什么时候进行优化还是不太清楚,是否有什么可供参考的参数?我的想法是是否进行优化要看这个部分对全局产生的影响是否足够大,如果足够大的话,就尽早就行优化,如果影响不大,可以暂时不理会,在后面的优化阶段可以进一步判断要不要需要优化。
4、文中第85页提到了结对编程的做法以及这种方法可以带来的好处。我认同如果有人可以一起进行分析设计等工作,有利于程序更加完善,但是我对这种模式是否能得到很好的执行还是有些疑问。结对编程模式下,
一对程序员肩并肩、平等地、互补地进行开发工作,说起来简单,但是我认为这样对这一对程序员将会有更高的要求,不仅仅是个人水平方面,对两个人是否“契合”也有很高的要求。每个人的水平都不一样,如果两个人水平差异比较大的话,这样的结对会不会有可能出现“一边倒”的现象;而如果两个人水平很相似的话,结对的方式是否有点浪费资源。在现实工作中,不一定能遇到平等互补的人。文中也提到了结对编程是一个相互学习、互相磨合的渐进过程。开发人员需要时间来适应这种新的开发模式。开始时的结对编程效率也许会不高,而两个人需要多长时间的学习磨合也未知,这样编程效率的稳定性就得不到很好的保证。而一所公司是否愿意或是能有足够的资本去花时间培养好一对平等互补,能够发挥好结对编程模式优势的程序员呢?结对编程的模式真的可以得到很好的执行吗?我认为对于中、小型公司,不会投入太多的精力与成本去培养一对对很好的结对成员,甚至都不会去选择结对编程的模式,或许在签订某种合同(比如签约工作多少年之后才可以选择离开)的情况下会选择培养结对成员。大公司或许资金毕竟充足,选择结对的模式可能性会大一些。
5、书中第五章为我们介绍了一些团队模式,正如文中第97页所说的
基于直觉形成的团队模式未必是最合适的,那我们应该怎么去选择一个团队的模式呢?我的想法是,既然是团队,就需要考虑到每个人的个人水平以及个性等个人因素,比如团队中有个水平比较高的人,那么主治医生模式或者就是个不错的选择,但是这样又需要担心团队之间的任务分配,避免其退化成“一人干活,其他人打酱油”的状况。又比如业余剧团模式,不同的人挑选不同的角色,每个人可以选择自己擅长的部分,但是如果在小团队下,未必恰好每个人的能力刚好互补,这样总会有人会被选到自己不擅长的角色。由此看来,选择团队模式不是想当然的事,那有没有什么方法可以让我们选出适合的团队模式呢?我觉得这需要综合考虑成员的专业水平和性格,比如在主治医生模式中,需要考虑的是有一位成员水平较高,但其他成员也不能太低,与之相差很大的话,就容易导致打酱油的状况,而且成员们的性格方面也不能是那种不积极的,即便是“医生助手”,有时候也可以注意到医生没注意到的问题。或许可以列一张表格,将团队成员的性格以及专业水平列出来,然后对团队模式进行匹配,想要十全十美恐怕是不可能的,但是可以选择契合度较高的团队模式。
软件工程小故事
hello world的起源要追溯到1972年,贝尔实验室著名研究员Brian Kernighan在撰写“B语言教程与指导(Tutorial Introduction to the Language B)”时初次使用(程序),这是目前已知最早的在计算机著作中将hello和world一起使用的记录。之后,在1978年,他在他和Dennis Ritchie合作撰写的C语言圣经“The C Programming Language”中,延用了“hello,world”句式,作为开篇第一个程序。在这个程序里,输出的”hello,world”全部是小写,没有感叹号,逗号后有一空格。虽然之后几乎没能流传下来这个最初的格式,但从此用hello world向世界打招呼成为惯例。
参考链接:“hello, world” 起源及其他
二、WordCount编程
1、Github项目地址
我的Github项目地址PersonalProject-Java
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 500 | 935 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 90 | 180 |
| • Design Spec | • 生成设计文档 | 30 | 35 |
| • Design Review | • 设计复审 | 20 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| • Design | • 具体设计 | 40 | 100 |
| • Coding | • 具体编码 | 180 | 360 |
| • Code Review | • 代码复审 | 20 | 10 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 60 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 510 | 935 |
3、解题思路描述
- 设计一个Lib类,在其中设计所需的方法,WordCount类有一个main()函数,调用Lib的方法实现功能。
- 代码运行流程和思路:
- 打开输入文件并读取内容:看到文件读写首先就在想要用哪种读写方式,后来选择使用BufferedReader,read()方法读取文件内容,并且不读取'\n'
- 统计字符数:因为不考虑中文字符,且任意ASCII码均算做一个字符,所以觉得只要读取读取内容的长度就可以了。
- 统计单词数:刚开始想到split()方法来分割单词,但还在犹豫分割的方式,后来在网上查询到了正则表达式,于是就利用正则表达式将内容分成单词数组并检验单词的合法性,统计数量。
- 统计非空行数:同样利用正则表达式的方法。
- 统计频率最高的单词:在统计单词数时将单词信息存放到Map<String, Integer>中,然后对Map内容进行排序。
- 将内容写入输出文件:使用BufferedWrite,write()方法,分别将所需内容写入文件。
4、代码规范制定链接
5、设计与实现过程
类设计
- Lib类和WordCount类:
其中Lib封装了具体功能的实现方法,WordCount只有一个main函数,调用Lib类封装的方法。
Lib类主要属性和方法有:
private String inputFile;
private String outputFile;
private String content;
private int charsNum;
private int wordsNum;
private int linesNum;
private Map<String, Integer> wordsMap;
/**
* 读取文件内容
*/
public void readFile() throws IOException
/**
* 写入文件
*/
public void writeFile() throws IOException
/**
* 统计字符数
*/
public void countCharsNum()
/**
* 统计单词数,以及每个单词出现的次数
*/
public void countWordsNum()
/**
* 统计非空行数
*/
public void countLinesNum()
/**
* 根据单词频率进行排序
*/
public List<Map.Entry<String, Integer>> sortWordsMap()
函数关系图:
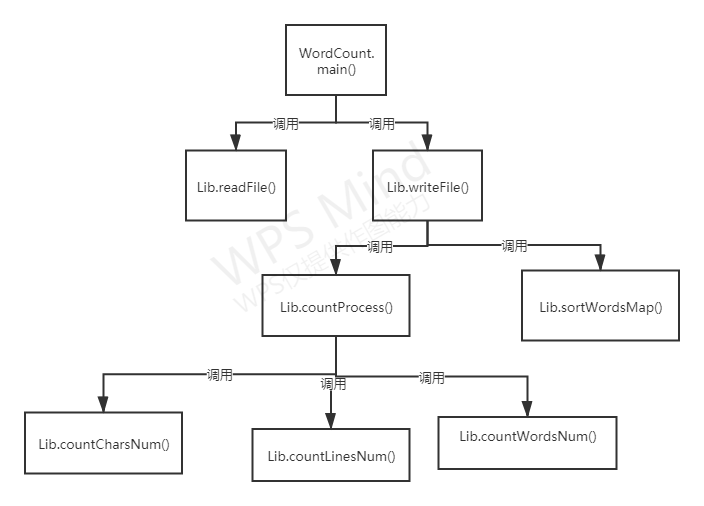
功能实现
- 统计字符数
由于不考虑中文字符,且任意ASCII码均算做一个字符,在文件读入时就除去了'\n',所以直接获取字符串长度即可charsNum = content.length(); - 统计单词数,在统计单词数的同时,可以一起记录单词以及出现的次数
使用正则表达式和split()方法,将读取的字符串内容以空格,非字母数字符号分割,且使用toLowerCase()全部转化为小写
使用正则表达式,来验证分割后的字符串是否符合单词的定义(至少以4个英文字母开头,跟上字母数字符号)String[] words = content.split("[^a-zA-Z0-9]+");
使用Map<String, Interger>存放单词与次数if (words[i].matches("[a-zA-Z]{4,}[a-zA-Z0-9]*")) { wordsNum++;word = words[i].toLowerCase(); if (wordsMap.containsKey(word)){ num = wordsMap.get(word); num++; wordsMap.put(word, num); } else { wordsMap.put(word, 1); } - 统计有效行数
任何包含非空白字符的行,都需要统计,所以使用正则表达式来匹配linesNum = 0; Pattern linePattern = Pattern.compile("(^|\n)\\s*\\S+"); Matcher matcher = linePattern.matcher(content); while (matcher.find()){ linesNum++; } - 因为结果要输出频率最高的10个单词,所以对单词Map进行排序
频率相同的单词,优先输出字典序靠前的单词。List<Map.Entry<String, Integer>> wordsList = new ArrayList<Map.Entry<String, Integer>>(wordsMap.entrySet()); Collections.sort(wordsList, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> word1, Map.Entry<String, Integer> word2) { if(word1.getValue().equals(word2.getValue())) { return word1.getKey().compareTo(word2.getKey()); } else { return word2.getValue() - word1.getValue(); } } }); - 读文件选择使用BufferedReader、read()方法,使用StringBuilder来合并每次读到的字符,提高性能,并且不读取'\n'
写文件选择了BUfferedWrite、write()方法while ((num = reader.read()) != -1) { // UTF-8中'\n'对应编码int值为13 if (num != 13) { ch = (char) num; builder.append(ch); } }
6、性能改进
- 文件读取的方式使用了带缓冲的BufferedReader和BufferedWrite,提高了读写效率。
- 对于求出频率最高的10个的单词的问题上,原先是使用TreeMap存放单词及其出现次数,因为TreeMap是有序的,但是发现如果是在大数据的情况下,插入的次数很多,所以改成了使用HashMap。
7、单元测试
以下展示代码均为关键代码,省略了构造字符串、文件读写等内容
- 测试统计字符数
需要考虑Ascii码,空格、水平制表符、换行符等都需要考虑在内,比如:"aaaa b8 c\t\r\n "
String testStr = "aaaa b8 c\\t\\r\\n ";
// 省略构造字符串、字符串写入文件等代码
......
assertEquals(testStr.length(), lib.getCharsNum());
- 测试统计单词数
需要考虑单词至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。比如:"windows95 windows98\n file,123file\t File\rwindows2000\n"
String str = "windows95 windows98\n file,123file\t File\rwindows2000\n";
int num = 4
int loopTimes = 200;
// 可使用循环增加测试量
......
assertEquals(num * loopTimes, lib.getWordsNum());
- 测试统计有效行数
任何包含非空白字符的行,都需要统计,比如:"hello]w666 word\n file1file\n \t \n"
String str = "hello]w666 word\n file1file\n \t \n";
int num = 2;
int loopTimes = 100;
// 数据处理
......
assertEquals(num * loopTimes, lib.getLinesNum());
- 测试统计频率前十的单词
输出的单词统一为小写格式,频率相同的单词,优先输出字典序靠前的单词。
final String[] words = {"aaaa1","bbbb2","cccc3","dddd4","eeee5",
"ffff6", "gggg7", "HHHH8", "OoOo9", "pPpP10", "qqqq11"};
// 数据处理
......
int i = 10;
for(Map.Entry<String, Integer> map : topWords) {
assertEquals(map.getKey(), words[i]);
i--;
}
- 测试频率前十单词的排序
final String[] words = {"aaaa10","aaaa13","aaaa23","aaaa4","bbbb5",
"bbbb6", "bbbb66", "cccc", "cccc3", "cccc38", "cccc4"};
// 数据处理
......
int i = 0;
for(Map.Entry<String, Integer> map : topWords) {
assertEquals(map.getKey(), words[i]);
i++;
}
- 测试覆盖率

因为Lib中有个get函数测试时没有用上,还有一些ctach语句块里的异常处理语句,所以Method和Line的覆盖率不是100%
8、异常处理说明
- Lib中的异常都是I/O异常。
- WordCount类中,对文件传入参数个数进行了异常处理
if (args.length < 2){
System.out.println("Insufficient parameters");
}
else {
......
}
当传入参数不足时:

当传入的要读的文件不存在时:

当要写入的文件不存在时,会自动创建文件。
当程序运行成功时:

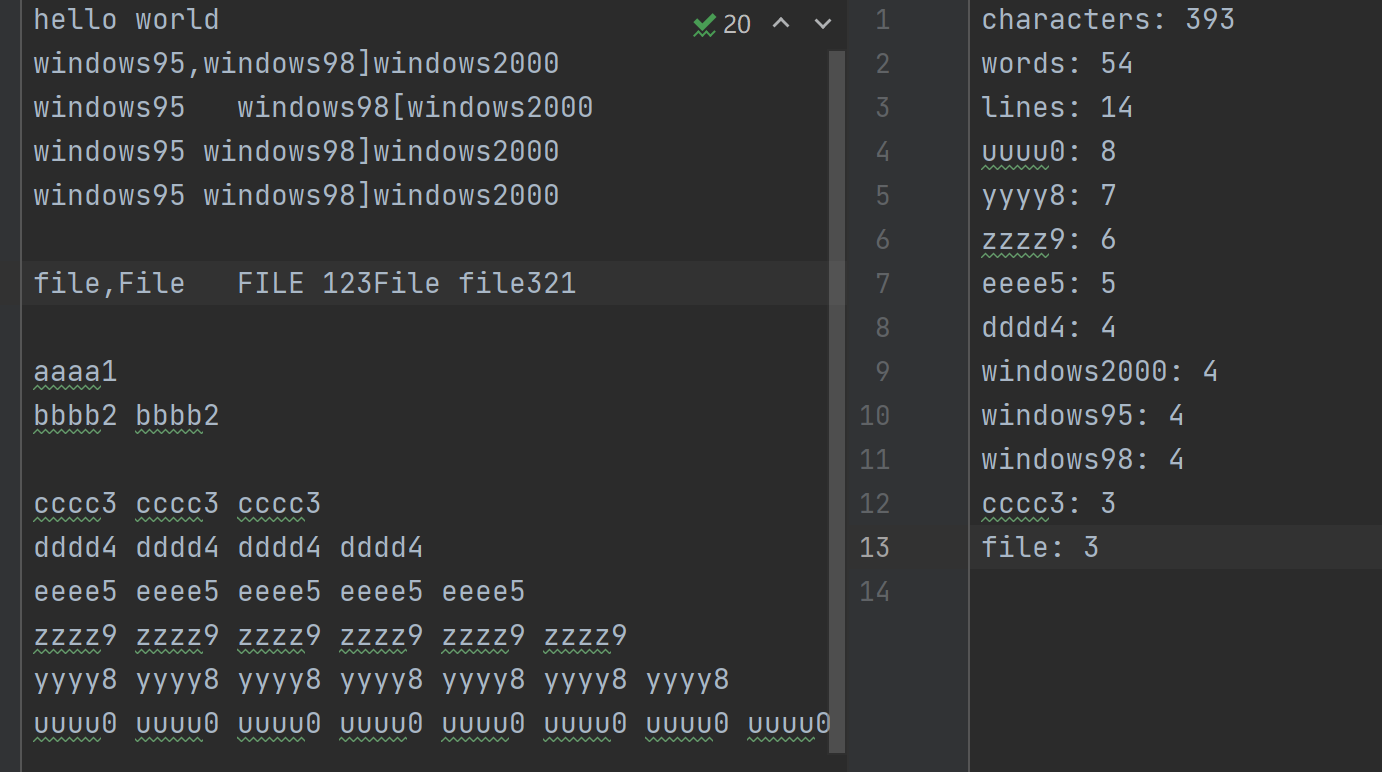
9、心路历程与收获
- 此次作业第一次接触使用了git和GitHub,学习了如何使用,也感受到了用git工具管理代码的优越性。
- 初步学会如何进行单元测试,之前的测试方法都是直接运行程序,十分不便,但是使用单元测试,可以更加方便地对特定代码进行测试。但是在使用过程中也不是一帆风顺的,有时候写错单元测试的代码,导致也无法找到错误。
- 初步学习了正则表达式,它的规则挺多的,而且也需要比较清晰的逻辑思维才可以使用好,还需要多加练习。
- 重温了文件读写的方法,以前虽然有学过,但是使用的比较少,这次使用也遇到了一些问题。比如BufferedWrite的使用中,没有及时flush()或是close(),有时候导致文件写入出了问题。
- PSP的使用。以前从来没有使用过PSP。第一次使用还是觉得有点不习惯,尤其是在预估耗时的方面,不知道要怎么衡量,结果也是相差很大(╥﹏╥...)。

