
结对作业二
| 这个作业属于哪个课程 | 2021春软件工程实践 | W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次作业——顶会热词统计的实现 |
| 结对学号 | 221801329|221801316 |
| 这个作业的目标 | 1. 学会web项目开发 2.感受结对编程中前后端分离开发 3. 学习前后端开发知识 4. 学会部署项目至云服务器 |
| 其他参考文献 | 无 |
| Github仓库地址 | PairProject |
一、项目链接
项目地址:PaperSearcher
用户:ldy,密码:123456,登录完一定要退出!
Github地址:点这儿
前后端代码规范:别点错了
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 120 |
| • Design Spec | • 生成设计文档 | 20 | 15 |
| • Design Review | • 设计复审 | 10 | 7 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 40 |
| • Design | • 具体设计 | 20 | 15 |
| • Coding | • 具体编码 | 2520 | 3240 |
| • Code Review | • 代码复审 | 30 | 15 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 90 | 120 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 45 |
| • Size Measurement | • 计算工作量 | 10 | 6 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 10 |
| 合计 | 2845 | 3648 |
三、项目介绍
总体介绍
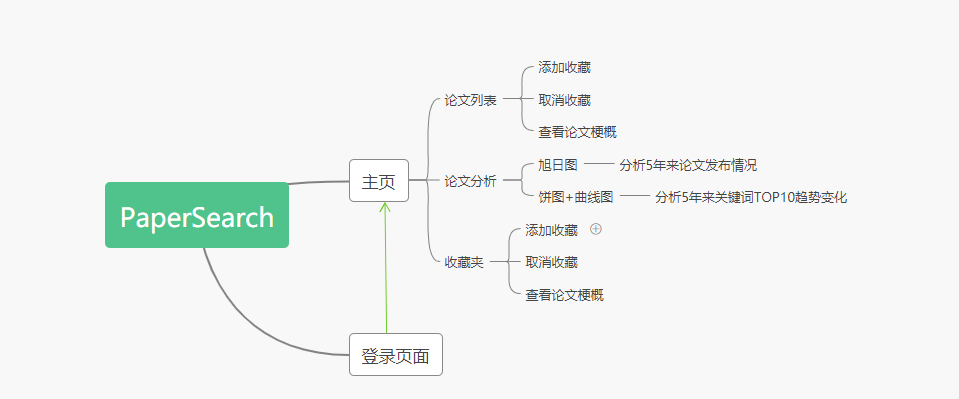
项目分为登录、主页两个页面
- 未登录无法访问主页,并没有设计注册页面
- 登录主页后,左侧边栏是主页、论文列表、论文分析、收藏夹
- 主页右侧边栏为装饰效果,除
收藏夹按钮,登出按钮无其他交互
模块介绍
主页
简单展示论文、只是为了美观
正上方的搜索栏无论点击哪个选项卡都可以使用
论文列表
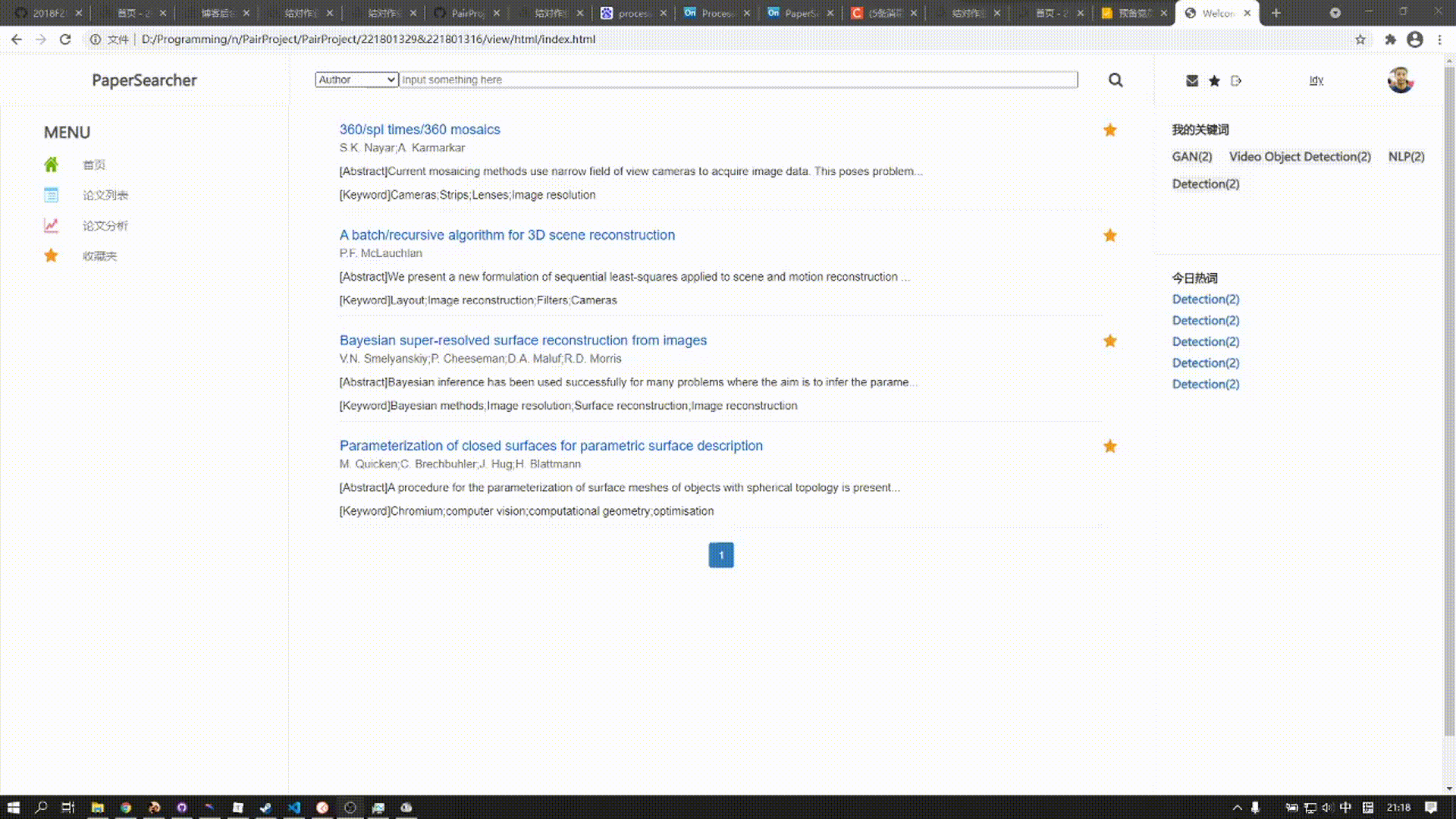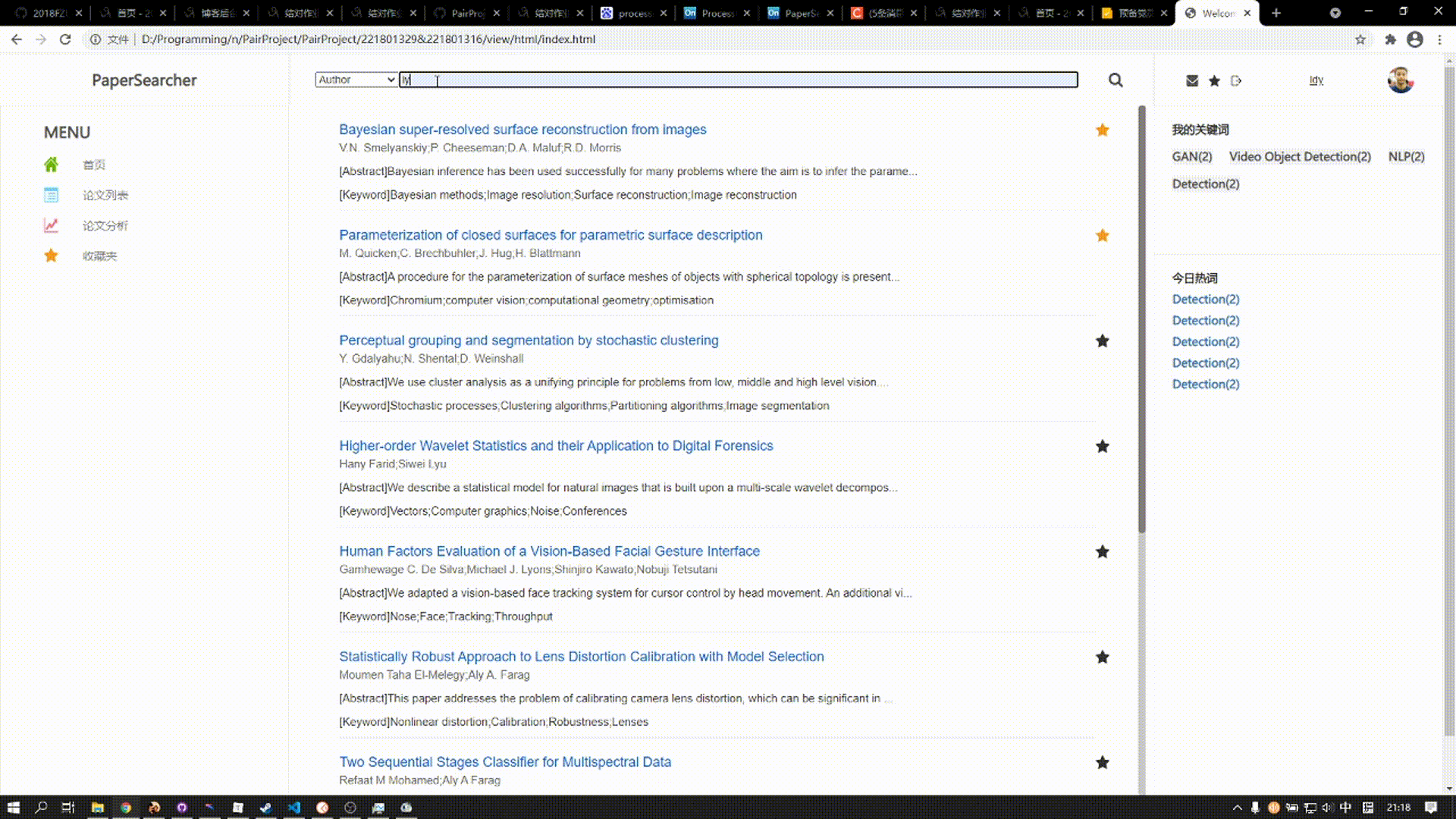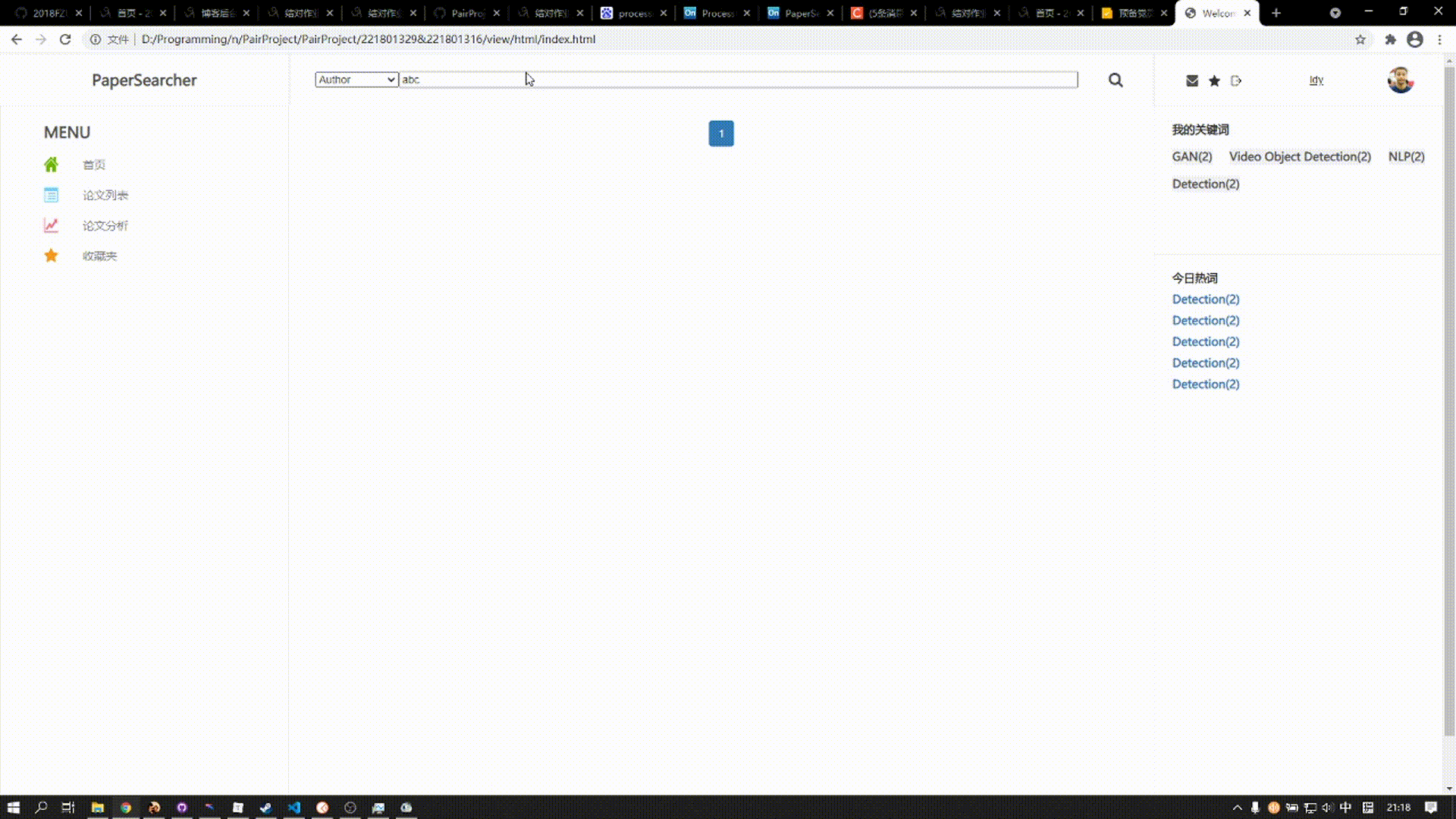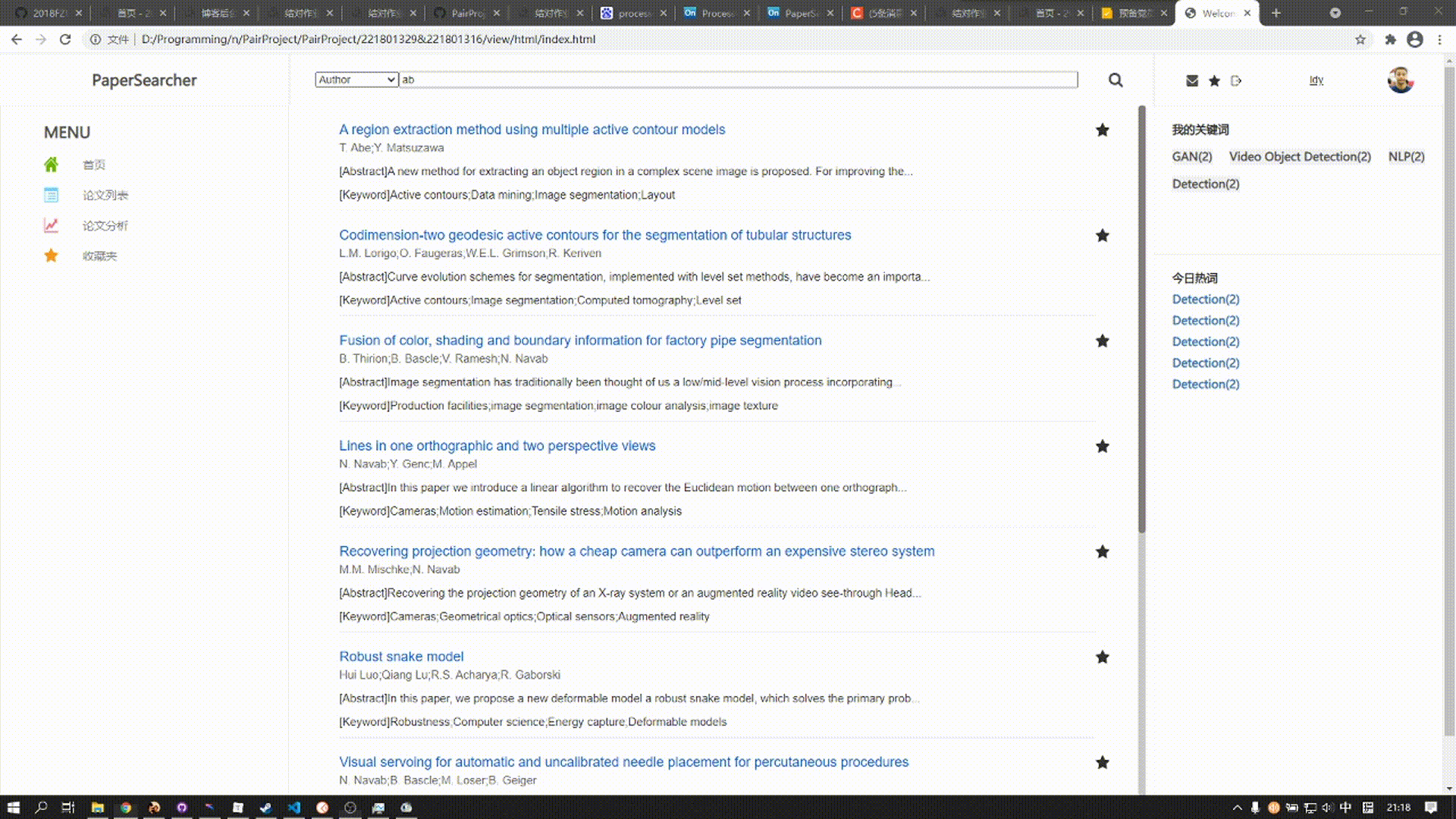
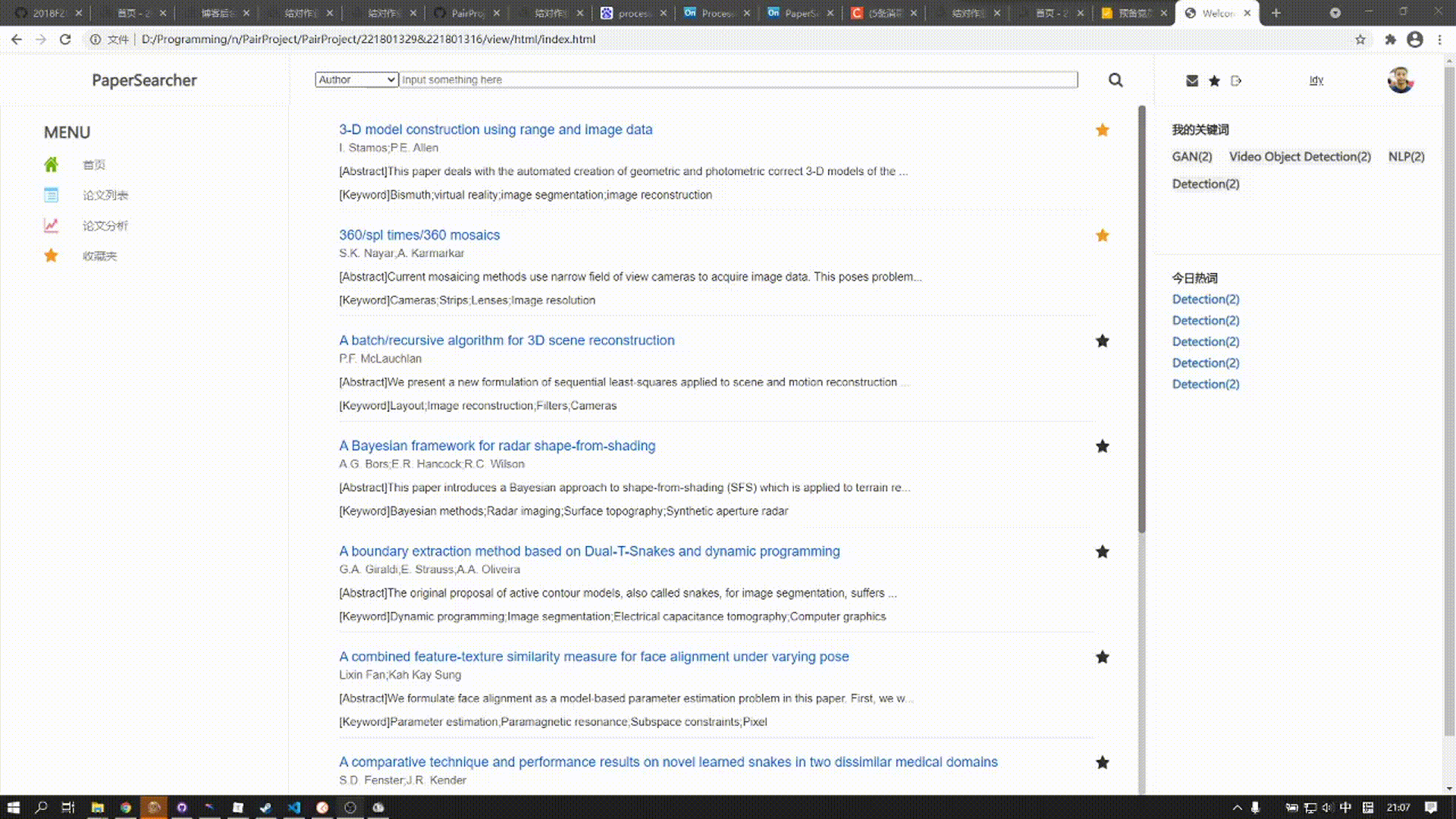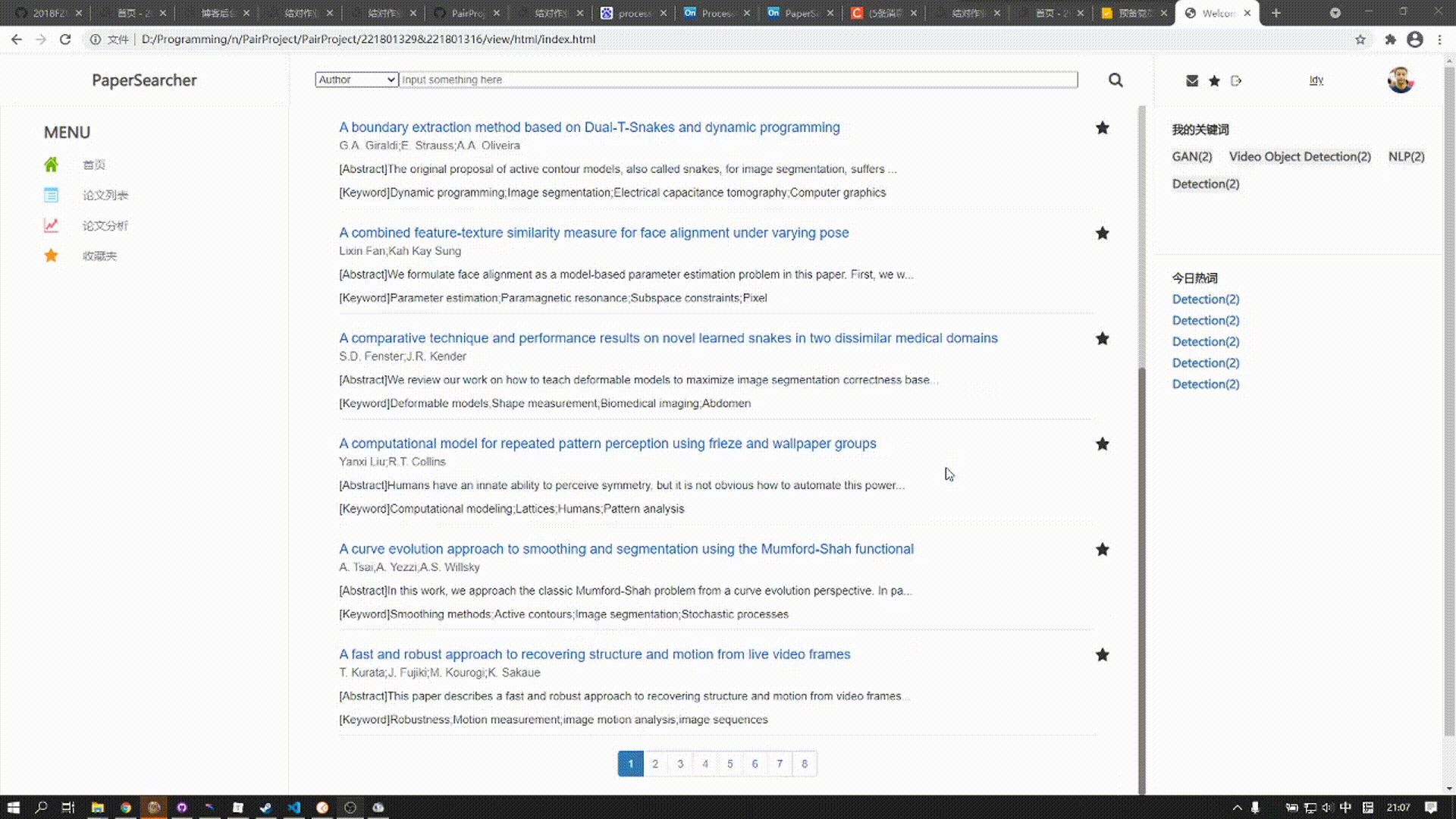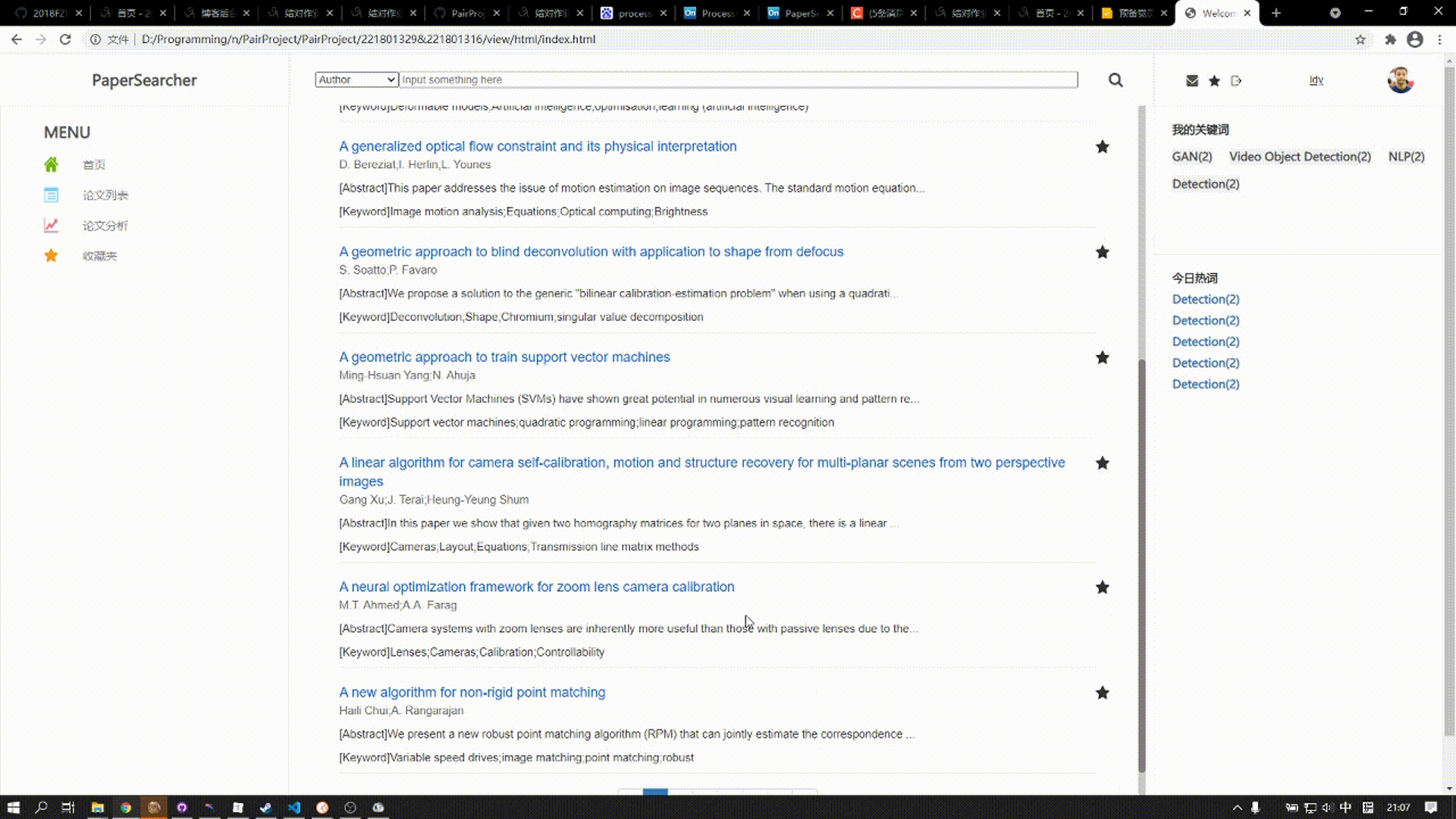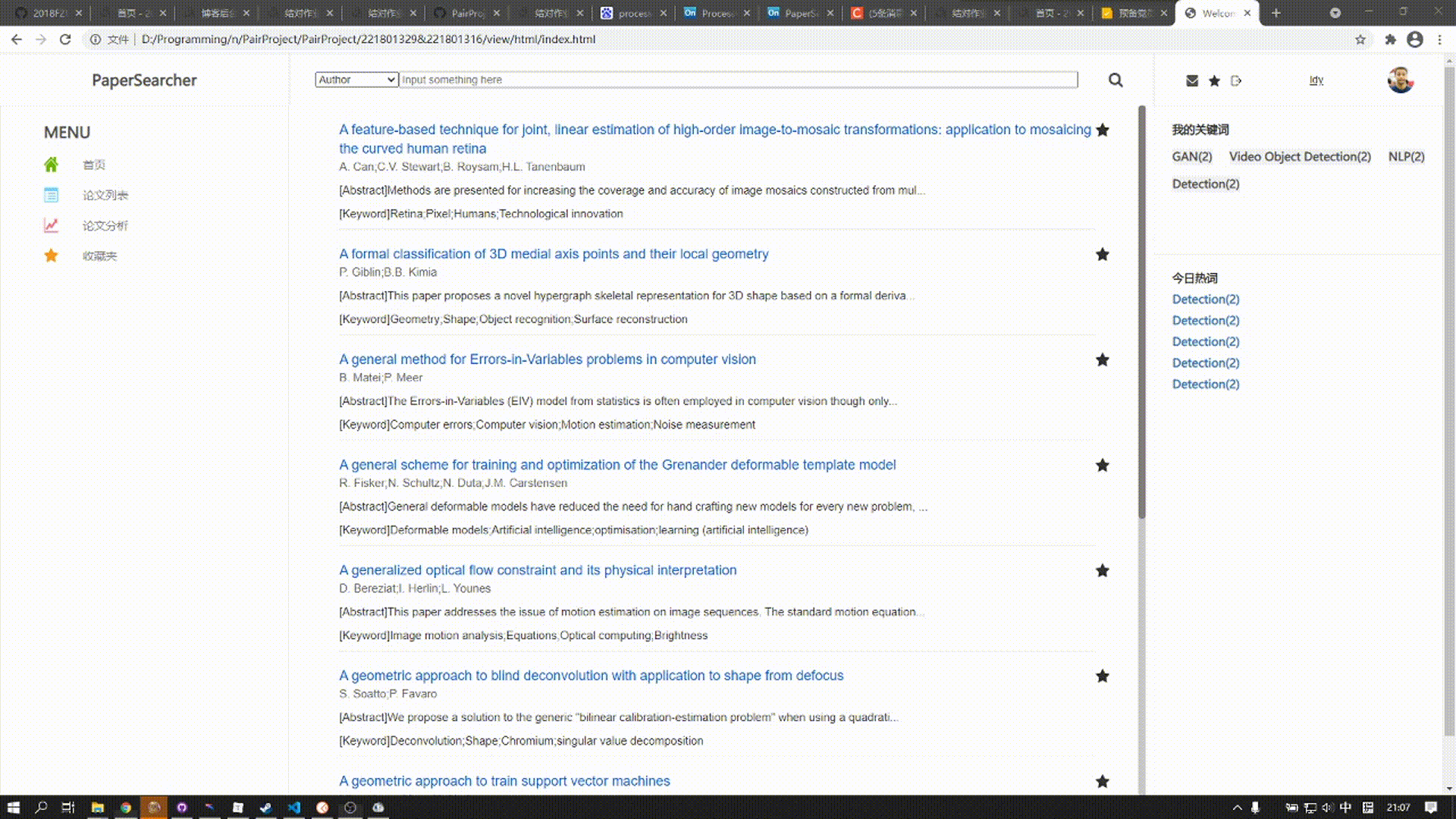
论文列表用于展现查询出来的论文信息,每个论文分为标题、作者、部分摘要、关键词来展示
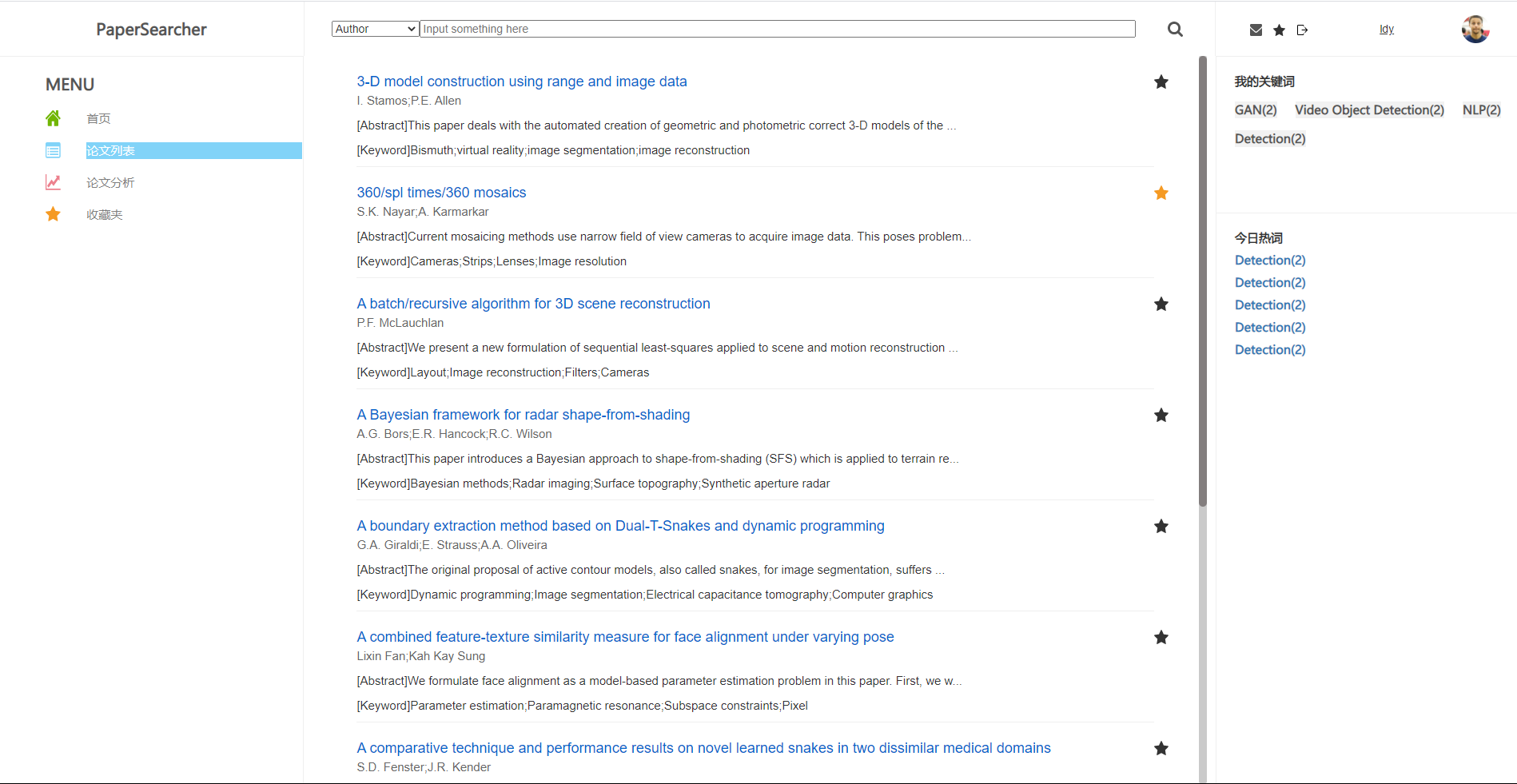
标题的右上角为收藏按钮,用户可以点击自己喜欢的论文添加进收藏夹中方便查阅
下拉到底下为分页块,若查询到的论文数量不足分页只会显示一页;未查询到则显示“No Result”
论文分析
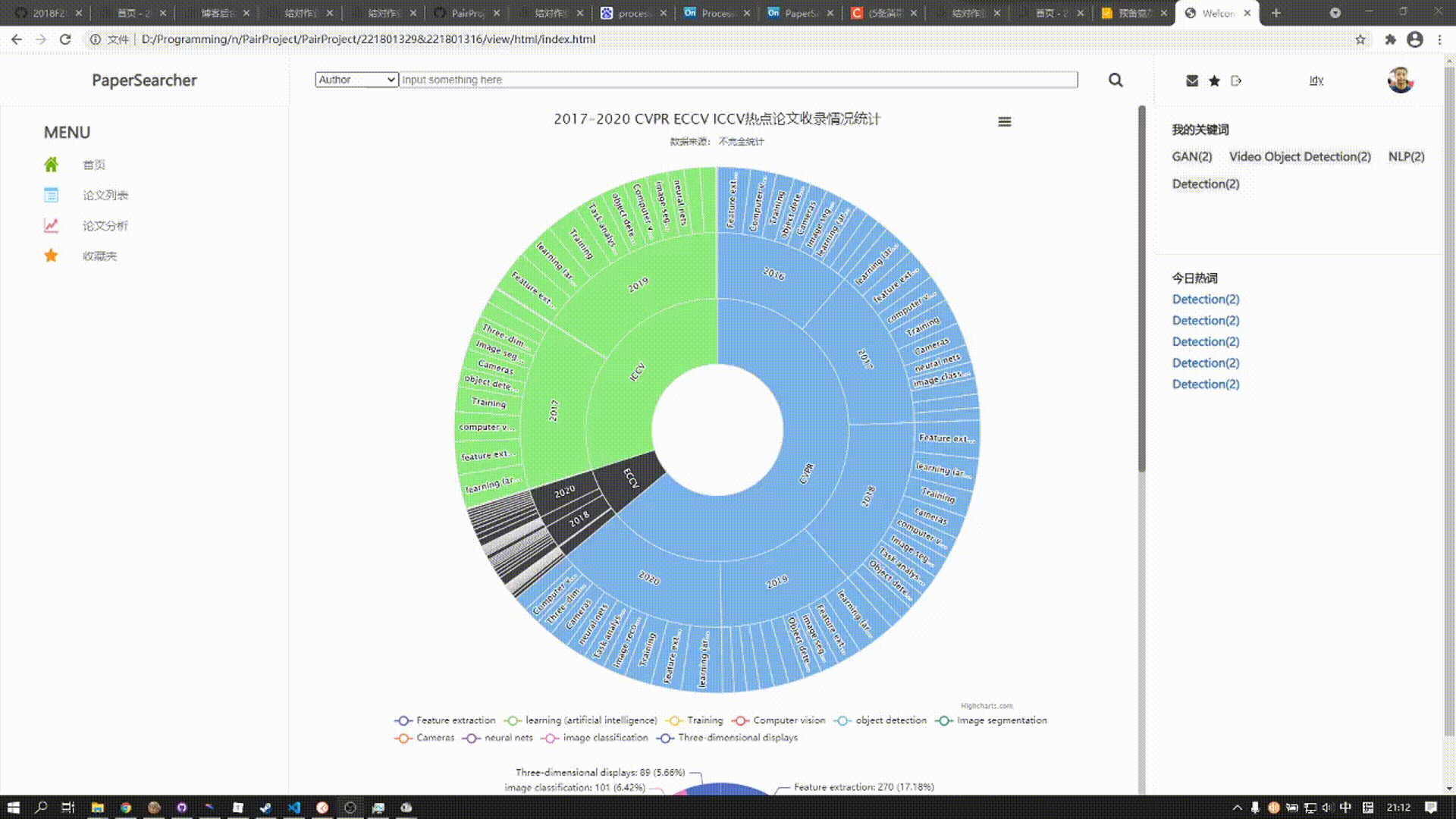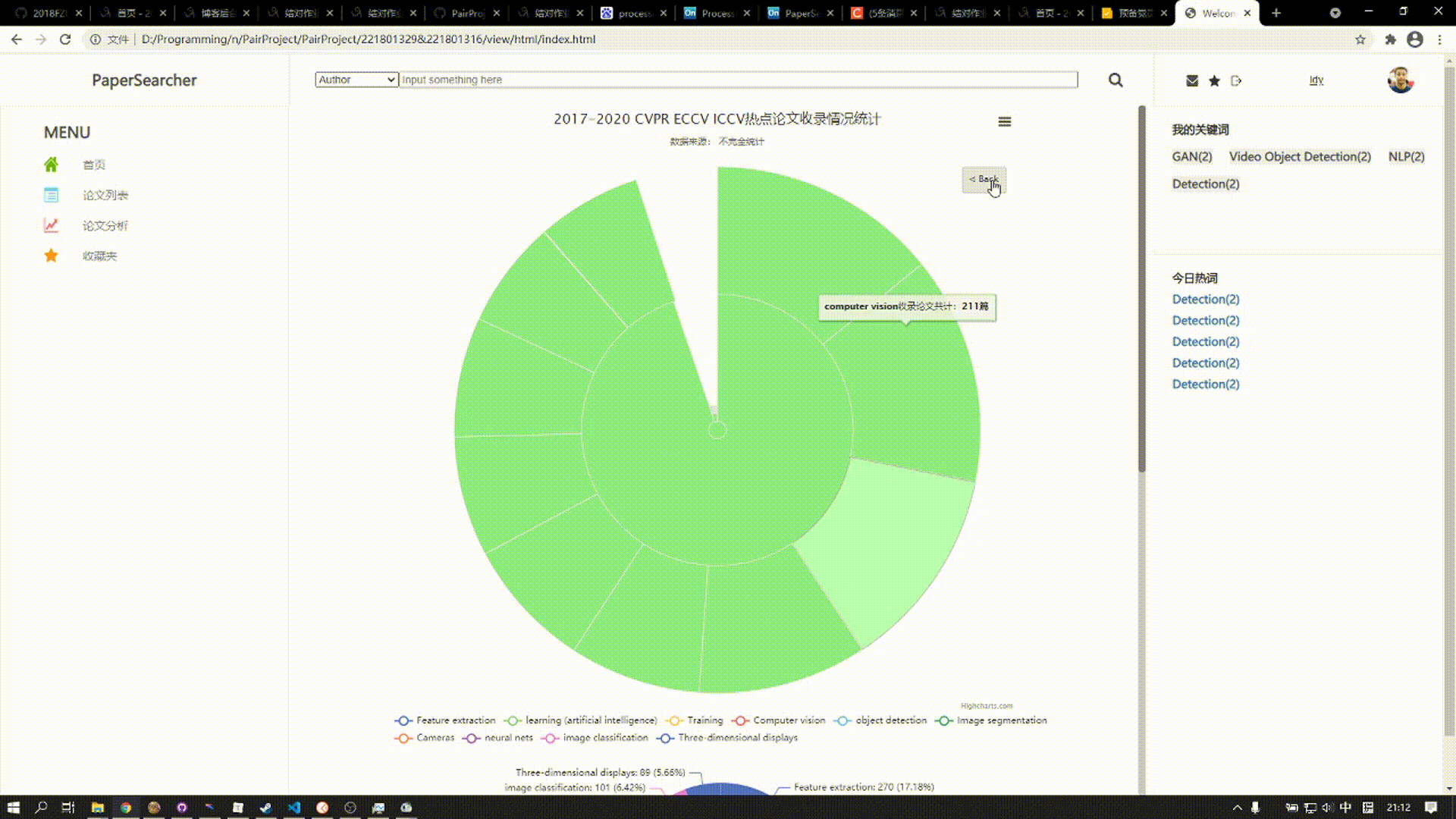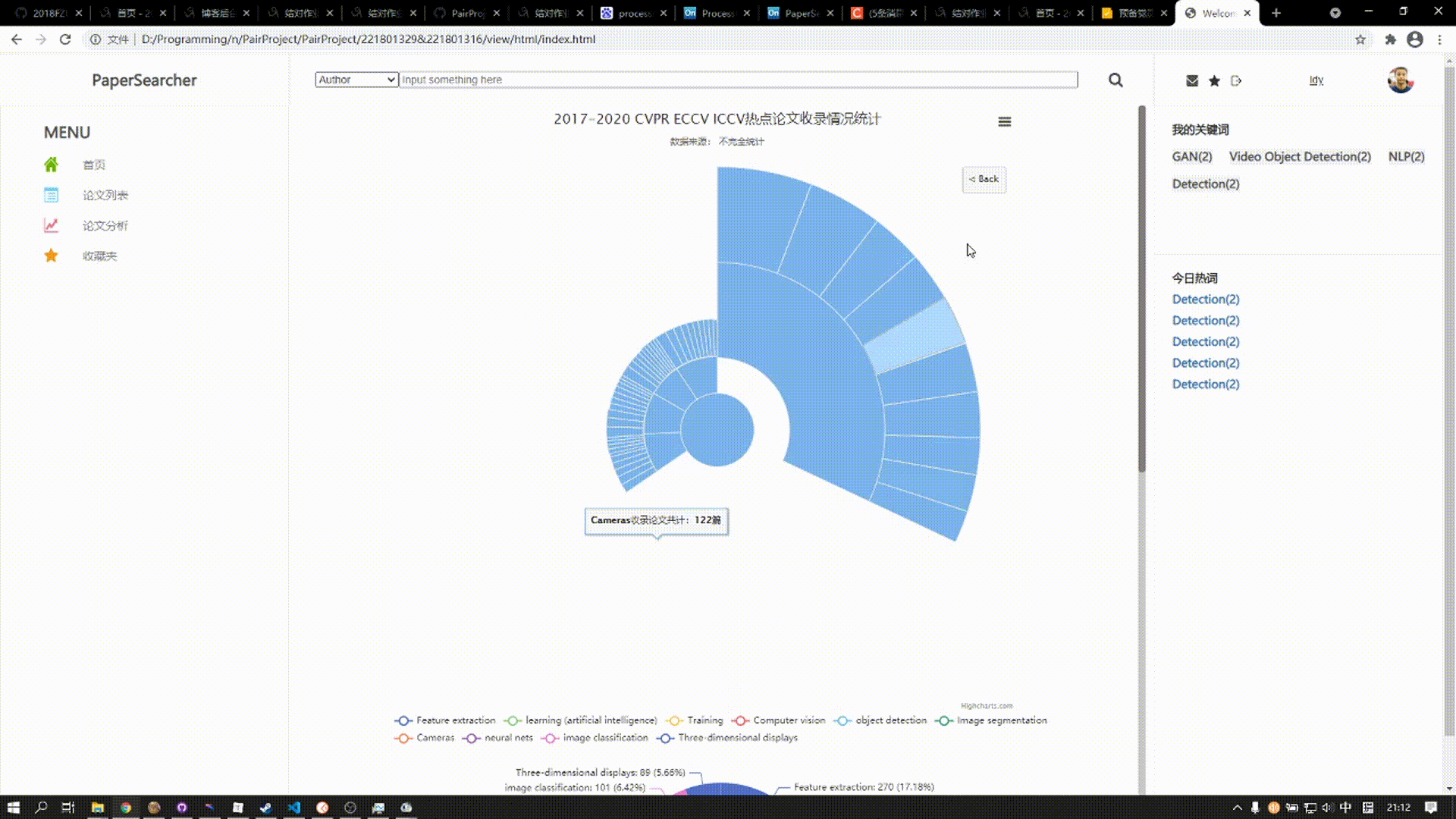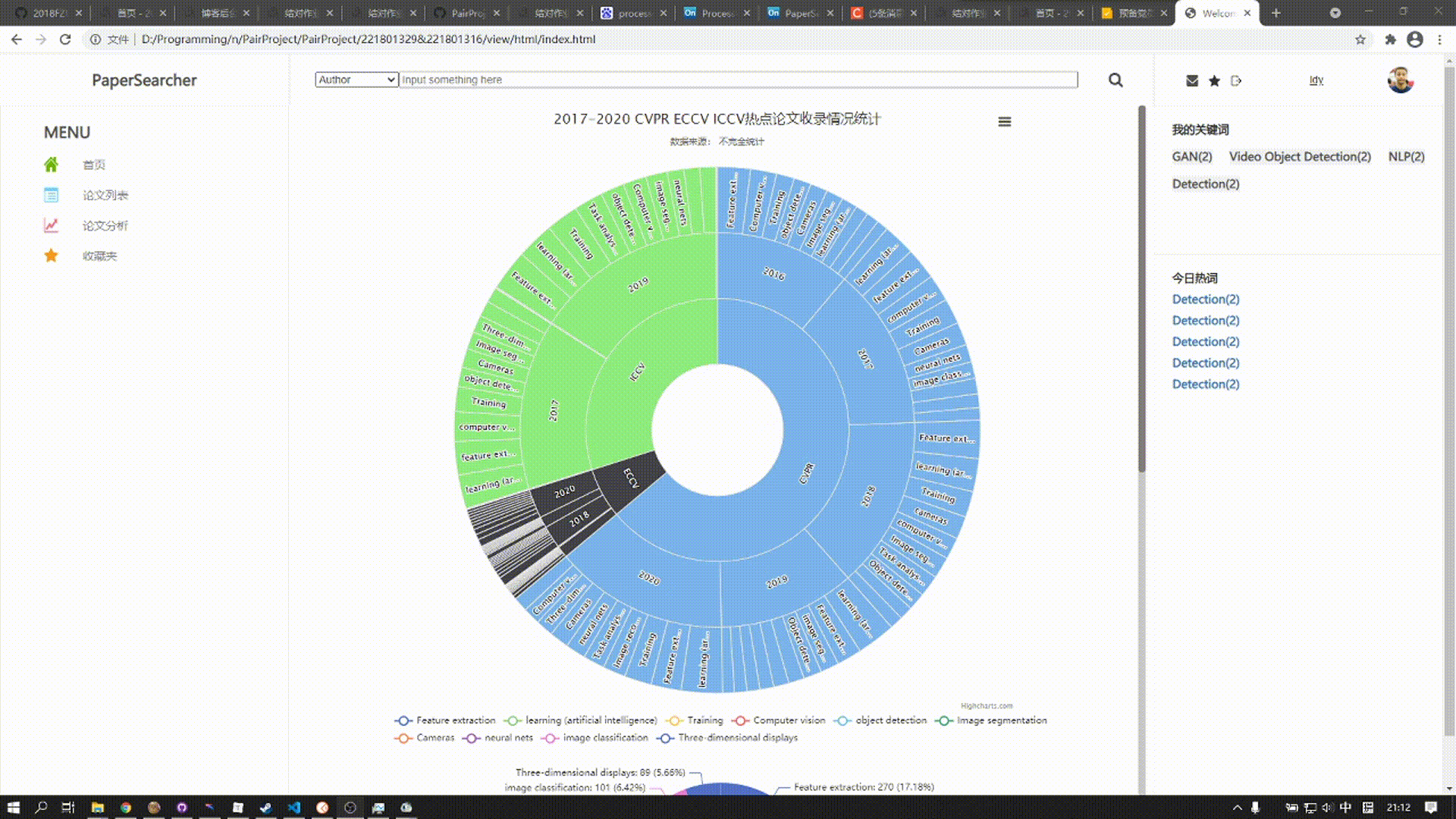
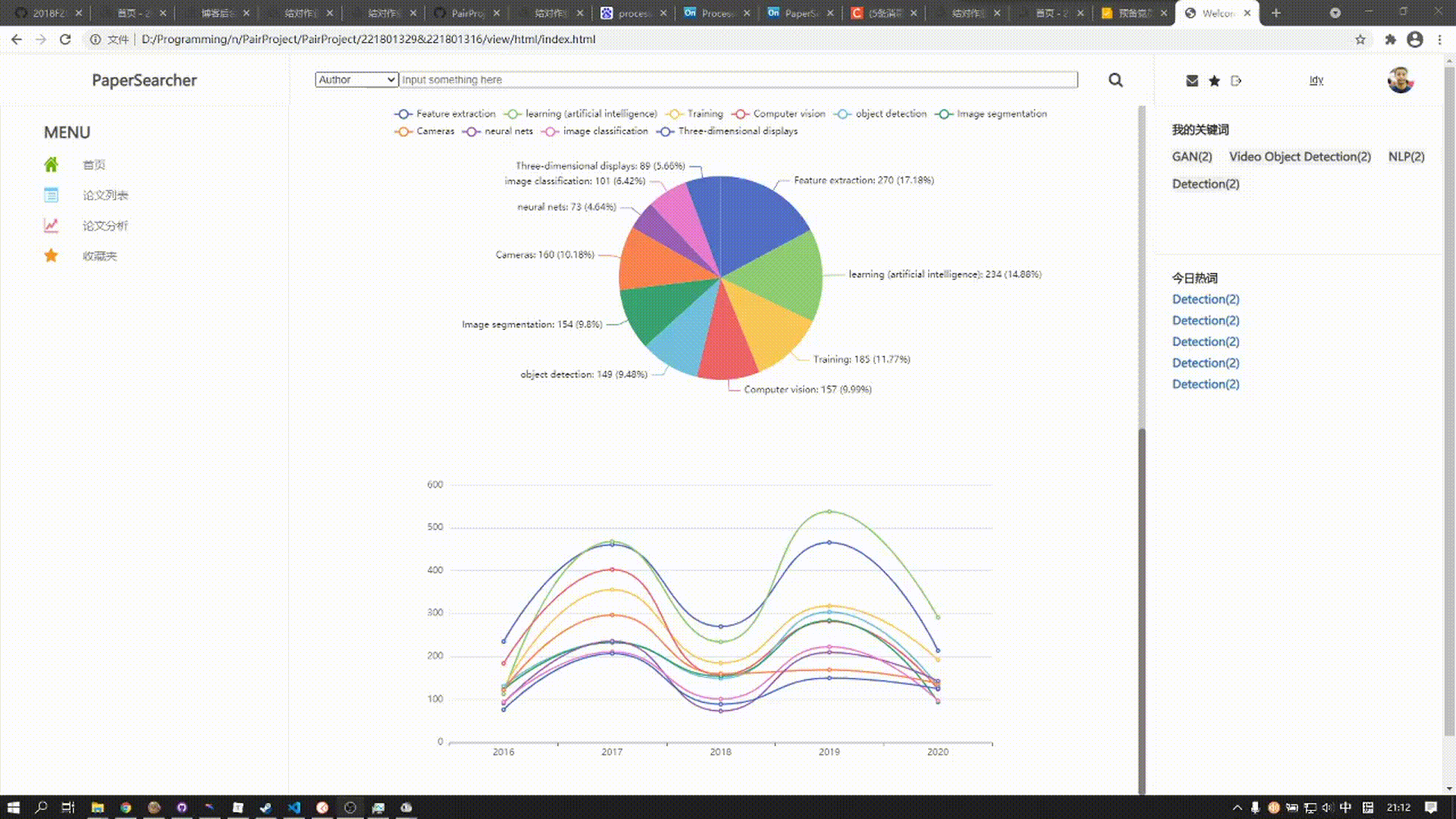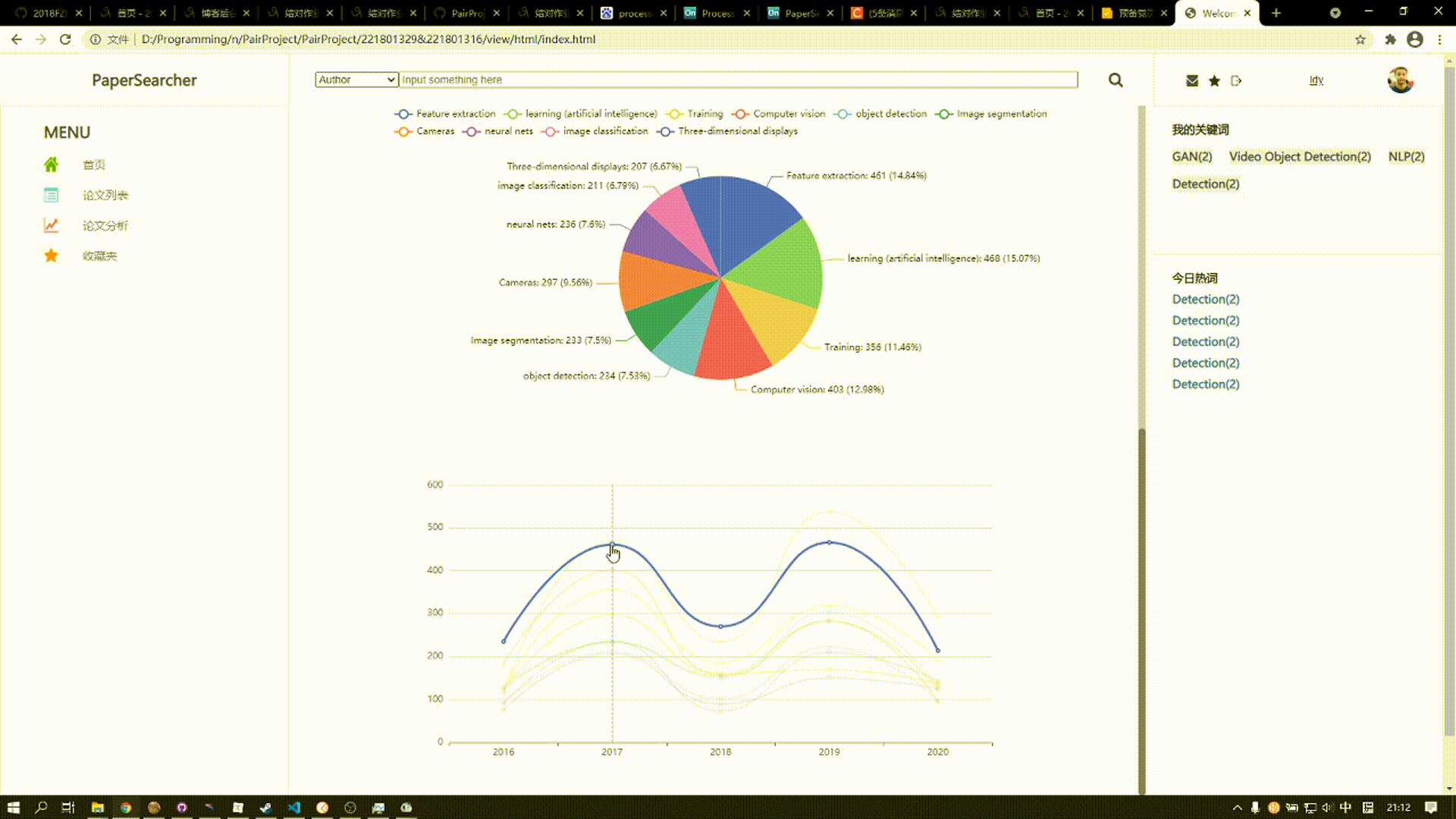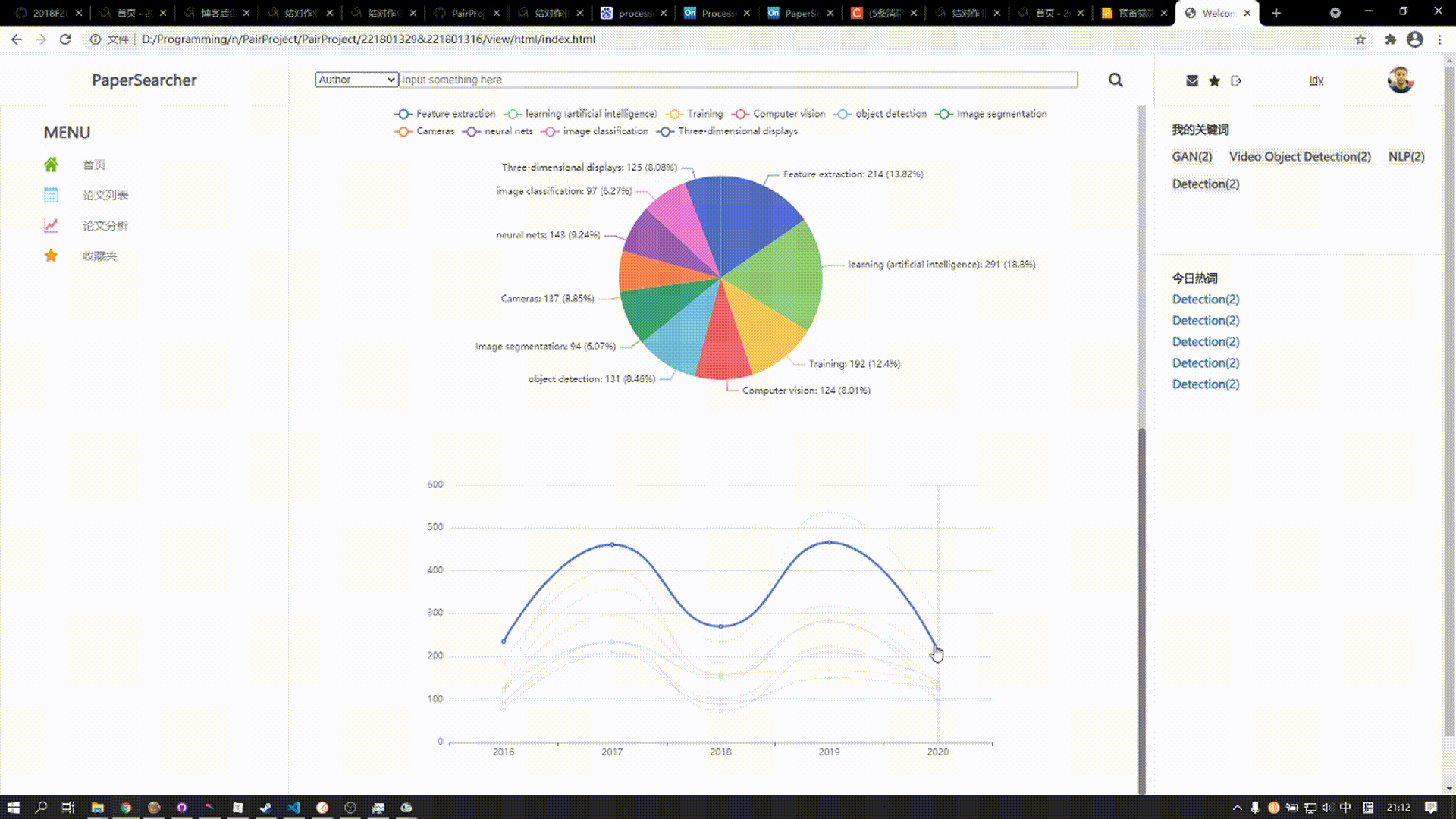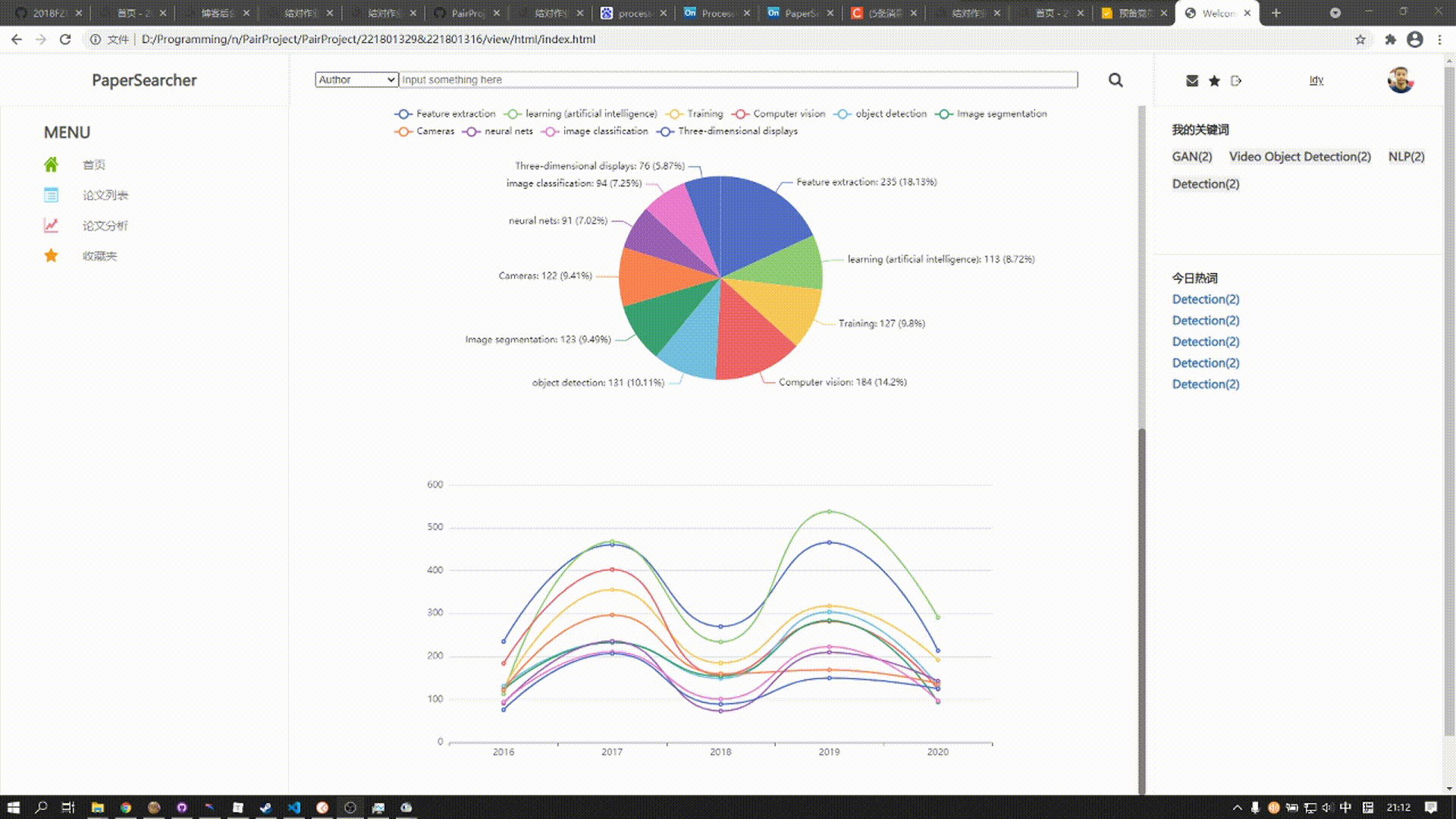
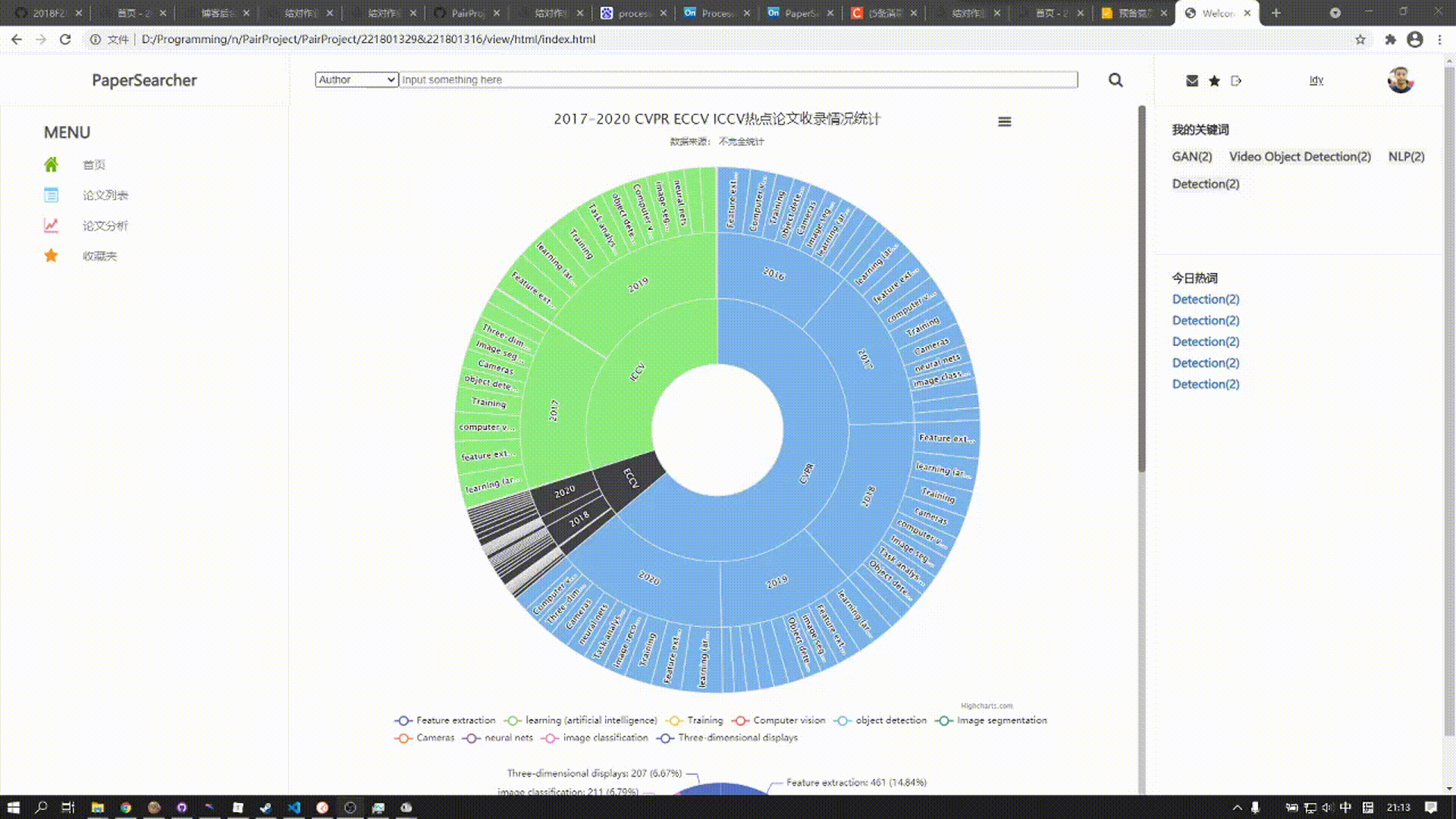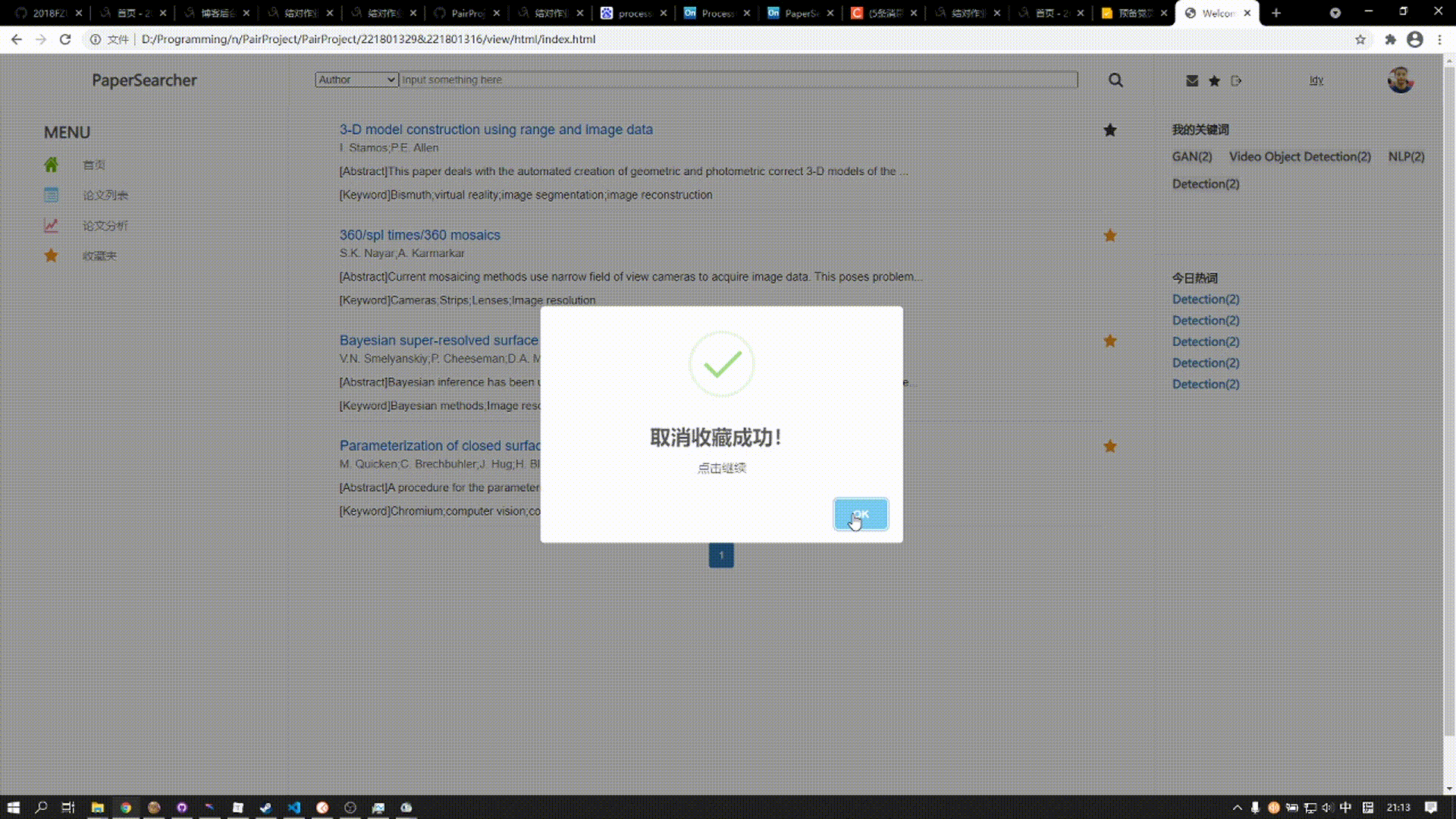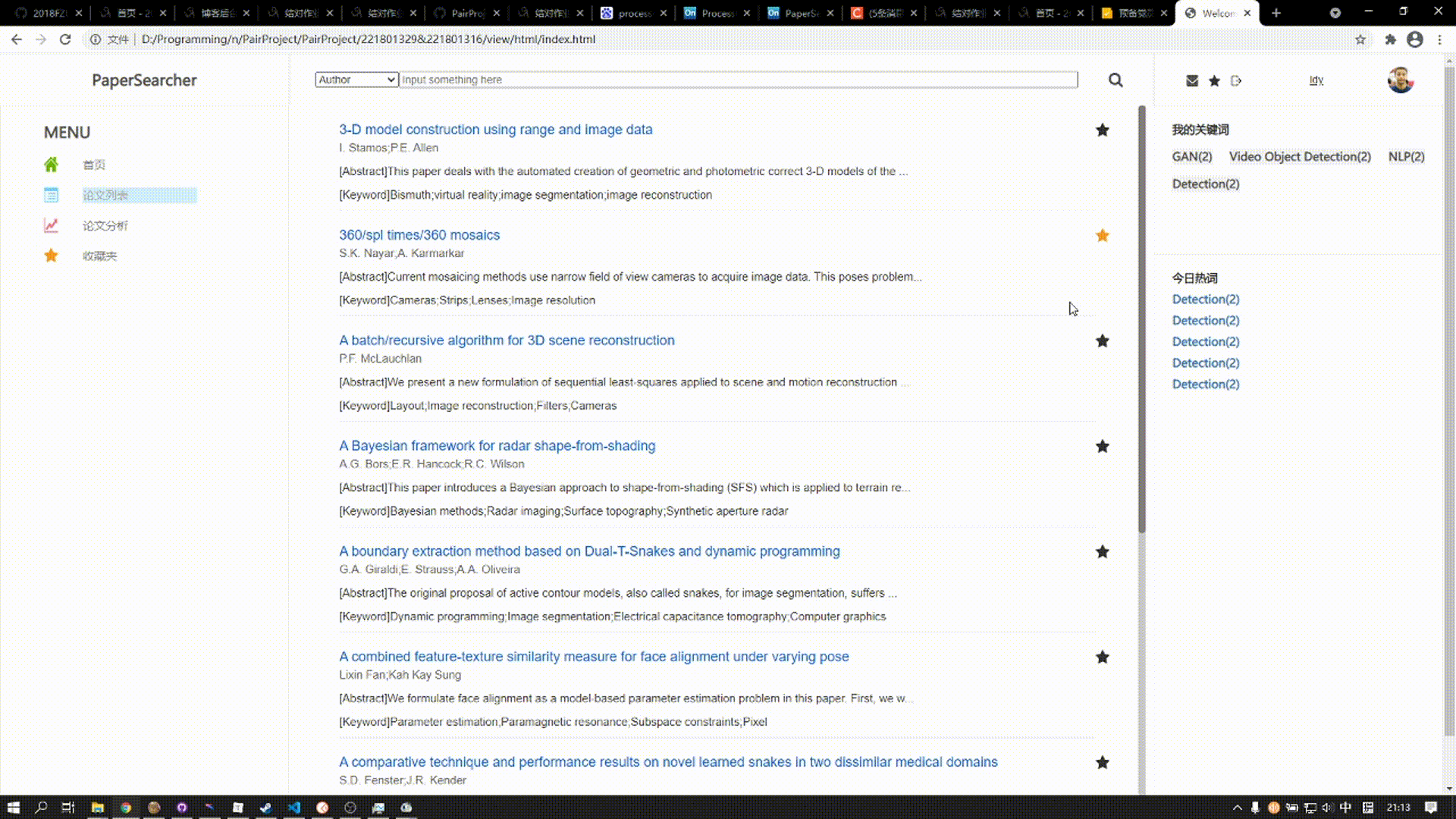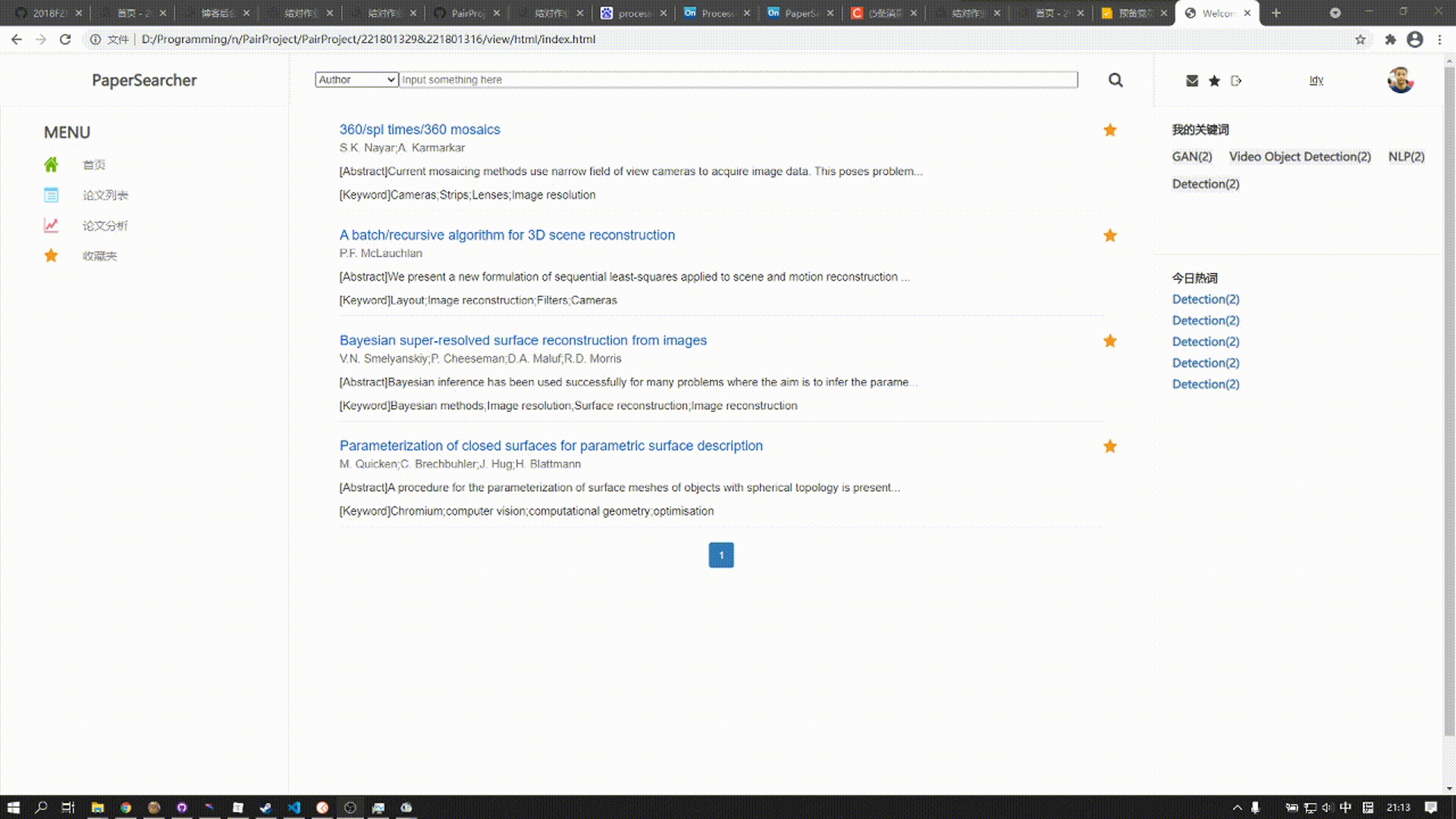
该板块由两张图表组成

上方的图表是涵括近五年来三大顶会热门话题所发表论文数,用户可以点击对应扇形区域展开图表查看详细数据
下方的图表涵括近五年来三大顶会热门关键词发表论文总数趋势,在该图标的上方为饼图,展现了某年10个关键词在总和中的比例,下方的曲线图则展示五年来发表论文数的趋势变化,鼠标悬停在某一结点,上方饼图则会对应显示该年论文比例
收藏夹
收藏夹是为了方便用户查看自己需要保存记录的论文而创立,考虑到用户不能直接对总论文列表进行删改操作,将删除论文弹性划分为取消收藏这一功能,与论文列表结构一致,但只能看到自己所收藏的论文
四、结对过程
YK:这给了数据以后看起来一两天就能做完,后端也就查询,整理格式,收藏,总的来说都是CRUD没啥东西的感觉,前端我写我就尽快写一下和原型长得差不多的吧
DY:ok,但是感觉一两天不够
YK:先试试看
YK:我查了一点资料,主页雏形差不多出来了,你可以给我接口了
DY:???太快了,再等一会(开始摸鱼)
小故事到这里结束!!!
我们两个人是前后端分离开发,有需要的时候向对方请求接口/数据验证/结果验证;
YK负责前端,也不会vue也不会js,都是从0手撸html和css,一边学一边找资料,实际上发现写的效率还是挺高的,就是没有及时和后端对接,让DY偷偷摸了几天的鱼
DY在随后的一两天是进行数据库设计,并对助教打包好的json数据进行解析,制定代码规范;在json解析的过程中遇到了很多坑,比如json末尾居然是分号,关键词、摘要太长,摘要、作者是空的,于是我们决定把含有空字段的数据做了一定处理:摘要太长→字符串截取,做一定非空判断
因为我们是舍友,在宿舍讨论比较方便,转头就可以疯狂提问/要接口
图为在宿舍讨论

YK平时在实验室,就采用线上QQ联系来对接,遇到问题的时候我们会把具体出错的地方告诉对方
图为线上讨论

五、实现过程
最终我们是确定了如下结构
前端设计
分为登录、主页两个页面
登录
登录页面就与平时见到的差不多,没什么技术性在里头
主页
主页最基本的功能就是要获取论文信息、收藏夹、热点趋势等
想尝试一下选项卡式的布局,在左侧边栏设置了四个选项卡,其中的切换都是依靠js完成的(从后台获取数据添加到innerHTML中),直到团队作业我学了vue以后才知道全靠js是很不规范的一种方案
论文列表、收藏夹
论文列表展现的是用户所可以看到的信息,我参考了百度搜索的布局样式,设计了白底蓝灰字色的样式,一篇论文对应一个block,看起来比较简洁美观,信息依靠模板样式展现,查询则是根据用户输入、选择字段来向后端发起不同路由的请求
论文分析
论文分析页面展现的是一些热点关键词的趋势变化,需要直截了当,旭日图能较好的看到全局的数量分布情况,其可交互性很强,用户可以直接选择自己需要了解的方向去查看,我很喜欢这样的设计,所以就用上了
另一个图是表达热点趋势变化的图,我和DY挑了很久才挑出这个饼图+曲线图的样式,它的可交互性也很强
图中所有数据都是向后端请求后所生成的,数据格式的规定是参考了echarts和highcharts的格式
交互弹窗
交互弹窗我是用了以前在西二后端考核时候接触到的swal,个人感觉他的风格比较简洁
后端设计
数据库设计
本次项目中,主要是对论文数据进行存储和操作。首先设计了一张论文表,里面存储论文的字段信息,如标题,摘要,链接等等。
由于一篇论文对应着多个关键词,多个作者,一个关键词或者作者也对应着多篇论文,它们之间存在着多对多的关系,因此还需设计两张论文-关键词、论文-作者的关联表。
我们还对项目进行了功能拓展,增加了用户模块和收藏夹模块,因此设计了用户表和用户-论文关联表,从而达到注册登录以及增加/移除收藏的功能。
具体表结构见如下ER图
代码设计
本次项目采用了MVC模式,使用了springboot框架,Controller层负责提供接口与前端交互,Service层负责业务逻辑处理,Dao层负责数据持久化,参与数据库的交互,Pojo下存放着实体类
- 数据解析
对文件进行读取,遍历每一个.json文件,利用JSONObject解析json,指定所需要的数据的key值,将得到的数据分装入实体类中,最终存入数据库。
当然,本次不同会议的.json文件中key值不完全一致,既存在英文也存在中文,需要写分支对其按不同情况处理 - 论文搜索
与前端协商好交互的数据格式,根据传入的参数不同,实现不同搜索功能。如按关键词模糊查询,按作者模糊查询...实现方式主要是sql语句的编写
在查询的时候前端提供偏移量和页面大小,后端根据两个参数查询指定的内容并且返回总条目数和数据,从而实现分页功能 - 论文分析
主要编写sql语句,对近五年的三大会议的Top10关键词进行统计。与前端确定所需要展示的图表并且分析图表中data数据的结构,按照结构将后端查询的数据整合,返回给前端。
主要使用的是JSONObject和JSONArray,两者嵌套使用,可以灵活地向前端提供数据。 - 用户模块和收藏夹模块
该模块为我们本次项目的拓展功能,用户根据用户名和密码,实现简单的注册和登录,由于时间比较紧迫,没有考虑安全和加密等方面的功能。用户登录后在论文搜索的结果页面中,可以点击收藏按钮,对喜欢的论文进行收藏。
前端将该论文的id和该用户的id传给后端,后端对其进行存储,建立用户与论文的管理。在收藏夹页面,联合查询论文表和用户-收藏表,可以查看该用户收藏的论文列表。
六、关键代码说明
前端
登录、登录状态检测、登出
//login.js
function login() {
let username = document.getElementById('username').value;
let password = document.getElementById('password').value;
//采用axios来进行网络连接,操作比ajax方便
instance.post('/login', {
username: username,
password: password
})
.then(res => {
if (res.data.userId !== -1) {
//采用session存储登录信息,为随后的判定登录做准备
window.sessionStorage.setItem('username', username);
window.sessionStorage.setItem('isLogin', true);
window.sessionStorage.setItem('userId', res.data.userId);
swal("登录成功!", "即将为您跳转至主页……", "success");
window.setTimeout(3000);
window.location.href = 'index.html';
} else {
swal("用户名或密码错误!", "请重新登录", "error")
}
})
}
//paperList.js
//获取session判断用户是否登录,若未登录则返回登录界面
let isLogin = window.sessionStorage.getItem('isLogin');
if (!isLogin) window.location.href = 'login.html';
//登出为清除session并跳转至登陆界面
function logout() {
sessionStorage.clear();
window.location.href = 'login.html';
}
论文列表实现
//因为是论文列表和收藏夹用同一套代码,就封装成函数了
function setList(data, pageNum, type) {
if (data.length === 0) {
panel.innerHTML = panel.innerHTML + "<p style=\"text-align:center;color: rgb(127, 127, 127);\">No result</p>";
} else {
let list = data.paper;
for (let k in list) {
//定义一个临时变量方便操作
let element = list[k].data;
//有的摘要太多了,砍掉一些内容
let abstractStr = element['abstractContent'].slice(0, 100) + "...";
let authorStr = "";
let keywordStr = "";
//拼接作者信息,最多只显示5个
for (let t in element.author) {
authorStr += element.author[t] + ';';
if (t >= 3) {
break;
}
}
//去除最后的分号
authorStr = authorStr.slice(0, -1);
//拼接关键词信息,最多只显示5个
for (let t in element.keywords) {
keywordStr += element.keywords[t] + ';';
if (t >= 3) {
break;
}
}
//同样的去分号
keywordStr = keywordStr.slice(0, -1);
//标记是否收藏
let sytle = "like";
let src = '../img/gary-star.svg'
//若该条论文被收藏,则收藏图标亮起
if (list[k].isLike === 1) {
src = '../img/orange-star.svg'
}
//写入页面
panel.innerHTML = panel.innerHTML +
"<div class=\"paper-list\" id=" +
element.id +
"><a href=" +
element.link +
" class=\"paper-title\">" +
element.title +
"</a>" +
"<p class=\"paper-author\">" +
authorStr +
"</p> <p> <span class=\"paper-abstract-title\">[Abstract]</span>" +
"<span class=\"paper-abstract-detial\">" +
abstractStr +
"</span></p>" +
"<p><span class=\"paper-keyword\">[Keyword]</span>" +
"<span class=\"paper-keyword-list\">" +
keywordStr +
"</span></p>" +
"<img src=" + src + ' onclick=like(' +
element.id + ')' + ' id=Like' +
element.id + ' class=' + sytle + '>' +
'</div>'
}
//分页部分
initPagination(pageNum, Math.floor(data.total / 10) + 1, type);
}
}
分页实现
//分页框部分实现
function initPagination(currentPage, totalPage, type) {
console.log(totalPage)
panel = document.getElementById('main-panel');
let start;
let end;
//将页数控制在8页以内
if (totalPage < 8) {
start = 1;
end = totalPage;
} else {
start = currentPage - 4;
end = currentPage + 3;
if (start < 1) {
start = 1;
end = start + 7;
}
if (end > totalPage) {
end = totalPage;
start = end - 7;
}
}
//添加分页栏
let str = '<nav aria-label="Page navigation">' +
'<ul class="pagination">';
//判断是列表还是收藏夹,在li中添加不同函数
if (type === 'like') {
for (let i = start; i <= end; i++) {
if (currentPage == i - 1) {
var li = "<li class=\"active\"><a onclick=getLikeList(" + (i - 1) + ")>" + i + "</a></li>";
} else {
var li = "<li><a onclick=getLikeList(" + (i - 1) + ")>" + i + "</a></li>";
}
str += li;
}
} else if (type === 'list') {
for (let i = start; i <= end; i++) {
if (currentPage == i - 1) {
var li = "<li class=\"active\"><a onclick=getPaperList(" + (i - 1) + ")>" + i + "</a></li>";
} else {
var li = "<li><a onclick=getPaperList(" + (i - 1) + ")>" + i + "</a></li>";
}
str += li;
}
}
str += '</ul></nav>'
panel.innerHTML = panel.innerHTML + str;
收藏实现
function like(data) {
//根据id获取元素
let ID = 'Like' + data;
let star = document.getElementById(ID);
let src = star.getAttribute('src');
let router = '';
//根据收藏图标判断收藏/取消收藏路由
if (src === '../img/gary-star.svg') {
router = '/addLike'
} else {
router = '/deleteLike'
}
//请求部分
instance.get(router, { params: { userId: sessionStorage.getItem('userId'), paperId: data } })
.then(res => {
if (router == '/addLike') {
swal("收藏成功!", "点击继续", 'success')
} else {
swal("取消收藏成功!", "点击继续", 'success')
}
//请求结束以后需要修改按钮状态
star.setAttribute('src', (src == '../img/gary-star.svg') ? '../img/orange-star.svg' : '../img/gary-star.svg');
})
}
后端
service层关键代码——旭日图实现
@Override
public List<JSONObject> queryTop10ByYear() {
String []meets=new String[]{"CVPR","ECCV","ICCV"};
Integer []years=new Integer[]{2016,2017,2018,2019,2020};
List<JSONObject> data=new ArrayList<>();
//0级数据
Map<String,String> param0=new HashMap<>();
JSONObject jsonObject0 =new JSONObject();
jsonObject0.put("id","0.0");
jsonObject0.put("parent","");
jsonObject0.put("name","顶会五年总计");
data.add(jsonObject0);
//一级数据
for(int i=0;i<3;i++){
JSONObject jsonObject1=new JSONObject();
jsonObject1.put("id","1."+i);
jsonObject1.put("parent","0.0");
jsonObject1.put("name",meets[i]);
data.add(jsonObject1);
}
//二级数据
int k=0;
for(int i=0;i<3;i++){
for(int j=0;j<5;j++){
JSONObject jsonObject2=new JSONObject();
jsonObject2.put("id","2."+k);
jsonObject2.put("parent","0.0");
jsonObject2.put("parent","1."+i);
jsonObject2.put("name",String.valueOf(years[j]));
data.add(jsonObject2);
k++;
}
}
//三级数据
k=0;
int n=0;
for(int i=0;i<3;i++){
for(int j=0;j<5;j++){
//获得第i个会议,第j年的前10关键词及其数量
List<Keyword> keywordMapList=paperMapper.queryTop10ByYear(years[j],meets[i]);
//如果查询不到记录
if(keywordMapList.size()==0){
for(int m=0;m<10;m++){
JSONObject jsonObject3=new JSONObject();
jsonObject3.put("id","3."+n);
jsonObject3.put("parent","2."+k);
jsonObject3.put("name", "nothing");
jsonObject3.put("value",1);
data.add(jsonObject3);
n++;
}
}else{
//查询得到记录
for (Keyword keyword : keywordMapList) {
JSONObject jsonObject3=new JSONObject();
jsonObject3.put("id","3."+n);
jsonObject3.put("parent","2."+k);
jsonObject3.put("name", keyword.getName());
jsonObject3.put("value",keyword.getCount());
data.add(jsonObject3);
n++;
}
}
k++;
}
}
return data;
public List<Paper> cvprJsonParse() {
List<Paper> paperList=new ArrayList<>();
String dir=System.getProperty("user.dir");
System.out.println(dir);
File file=new File(dir+"c/main/resources/论文数据/1");
if(file.exists()){
File []child=file.listFiles();
for(int i=0;i<child.length;i++){
Paper paper=new Paper();
String json=jsonRead(child[i]);
json=json.replace(";","");
JSONObject jsonObject=JSONObject.parseObject(json);
String title=jsonObject.getString("title");
String abstractContent=jsonObject.getString("abstract");
if (abstractContent==null)abstractContent="暂无";
if(abstractContent.length()>=150){
abstractContent=abstractContent.substring(0,150);
}
String link=jsonObject.getString("doiLink");
String meet="CVPR";
Integer year=Integer.valueOf(jsonObject.getString("publicationYear"));
List<String> keywordList=new ArrayList<>();
JSONArray keywords= jsonObject.getJSONArray("keywords");
if(keywords!=null){
for(int j=0;j<keywords.size();j++){
JSONObject keyword=keywords.getJSONObject(j);
JSONArray jsonArray=keyword.getJSONArray("kwd");
for(int k=0;k<jsonArray.size();k++){
keywordList.add(jsonArray.getString(k));
}
}
}
else {
keywordList.add(" ");
}
List<String> authorList=new ArrayList<>();
JSONArray authors=jsonObject.getJSONArray("authors");
if(authors!=null){
for(int j=0;j<authors.size();j++){
JSONObject author=authors.getJSONObject(j);
authorList.add(author.getString("name"));
}
}
else{
authorList.add(" ");
}
paper.setTitle(title);
paper.setAbstractContent(abstractContent);
paper.setAuthor(authorList);
paper.setKeywords(keywordList);
paper.setLink(link);
paper.setMeet(meet);
paper.setYear(year);
paperList.add(paper);
System.out.println(paper.toString());
}
}
else{
System.out.println("文件不存在");
}
return paperList;
}
Dao层主要代码
<select id="queryPaper" resultType="com.fzu.pojo.Paper">
select id,title,abstract_content as "abstractContent",meet,`year`,link from paper_search.paper limit #{start},#{rows}
</select>
<select id="countAll" resultType="java.lang.Integer">
select distinct count(*) from paper_search.paper
</select>
<select id="queryKeywords" resultType="java.lang.String">
select keyword from paper_search.paper_keyword where paper_id=#{paperId}
</select>
<select id="queryAuthors" resultType="java.lang.String">
select author from paper_search.paper_author where paper_id=#{paperId}
</select>
<select id="queryPaperByKeyword" resultType="com.fzu.pojo.Paper">
select distinct a.id,a.title,a.abstract_content as "abstractContent",a.meet,a.year,a.link from paper a,paper_keyword b
where b.keyword like '%${keyword}%' and a.id=b.paper_id limit #{start},#{rows}
</select>
<select id="queryByTitle" resultType="com.fzu.pojo.Paper">
select distinct a.id,a.title,a.abstract_content as "abstractContent",a.meet,a.year,a.link from paper a
where a.title like '%${title}%' limit #{start},#{rows}
</select>
<select id="queryPaperByAuthor" resultType="com.fzu.pojo.Paper">
select distinct a.id,a.title,a.abstract_content as "abstractContent",a.meet,a.year,a.link from paper a,paper_author b
where b.author like '%${author}%' and a.id=b.paper_id limit #{start},#{rows}
</select>
<select id="countAllByKeyword" resultType="java.lang.Integer">
select distinct count(*) from paper a,paper_keyword b
where b.keyword like '%${keyword}%' and a.id=b.paper_id
</select>
<select id="queryTop10ByYear" resultType="com.fzu.pojo.Keyword">
select keyword as name,count(*) as `count` from(select b.keyword from paper a,paper_keyword b where
a.id=b.paper_id and a.year=#{year} and a.meet =#{meet}) as tmp group by keyword order by count(*) desc limit 10
</select>
七、心路历程和收获
221801329(LYK)的收获
不用框架写前端还是挺吃力的,也只能用用课内知识去还原自己的原型,自己原型写的多牛逼,实现的时候就哭的有多惨,这次我没有遇到很大的问题,主要是和后端交互的时候需要规划好返回数据的结构,不然每次调试起来都要花费很多时间
221801316(LDY)的收获
本次结对使我对springboot有了进一步的学习,也对MVC模式有了更深刻的理解。在这次项目中,我使用了之前未使用过的MyBatis框架,相比于之前的项目中直接使用的JDBC,代码量减少了不少,并且它提供了数据映射功能,支持对象与数据库字段的关系映射,方便了不少。
本次结对所需要实现的功能其实并不复杂,整体的逻辑思路还算清晰,但是许多细节的地方却仍然需要注意。在完成了整个项目后,我也对本次编程过程进行了回顾和思考,其实大部分的时间并不是花在代码的编写,而是花在代码bug的修改,可能是某一处无意的变量名写错,或者是
特殊情况如null时应该进行的处理,这些都是我们在专注的同时也可能忽略的东西,希望自己以后编程能够更加严谨,并且要养成每个功能模块完成后进行单元测试的习惯。除此之外对我还认识到了项目架构和需求分析的重要性,在实践的过程中,由于前期对收藏夹功能保持着非必选的态度,因此
设计时没有考虑到用户模块,在多数接口定义及实现完成之后,才想到需要添加用户和收藏夹的功能,进而引发对已有的接口进行修改。总的来说,本次项目使我认识到了自己仍存在着许多不足,虽然基本的功能都能轻松实现,但是对功能结构的规划和代码的优化,还有很大进步的空间。
希望接下来的阶段里,自己能够学习更多技术,积累更多的经验,提高自己编程的效率!
八、队友互评
221801329(LYK)对221801316(LDY)的评价
DY认真的时候效率还是很高的,就是摸鱼的时候是真的摸,前期我主页列表都写好了他一个接口还没放出来,把我急死了,不过后期两个人一起认真写确实能很快解决很多问题,下次还会和他合作,不过我想写后端了,这次是因为两个人都是后端我选了前端QWQ
221801316(LDY)对221801329(LYK)的评价
YK态度非常积极,执行力强,总是能在我松懈的时候提醒我要跟紧进度,希望在接下来的阶段中能够增强沟通交流,更加契合。

