
寒假作业(2/2)
寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 阅读《构建之法》并提问、WordCount编程 |
| 作业正文 | 寒假作业(2/2) |
| 参考文献 | Java NIO:IO与NIO的区别 |
阅读《构建之法》并提问
1.Page53,过早优化的例子,目前我还不能很好体会到过早优化带来的坏处,可能是全局观念不够多,只想着把某个函数优化到极致,好像从目前来看并不会有什么影响;下列的小雨伞的例子我也没有很好的理解,我脑子里的理论是局部都是最优的,全局应该不会受这个部分影响才对
2.Page193 9.2.2开发和测试搞不定的事里头,我个人认为作为程序员不能只能根据PM的给出的需求文档来编写功能,或者说应该要写完功能后站在用户角度自己去测试一下,感觉程序员多站在用户角度考虑,会比只看需求文档忙着编写更好?实际上的程序员会有时间去亲自和用户交流吗
3.Page247 11.5.4 宽严皆误 这边的签入流程有一个是同步服务器最近更新,假如说只有我一个人编写,那么我每次想修改代码的时候是从服务器下pull来比较好还是直接从本地开始编辑?本次作业我是直接从本地编辑了再push上去,没有一次的pull
4.Page253 第四点,关于同时修改代码这一事,上文也有提到对于一个项目的签入签出应当做一些限制,但如果是很重大的错误,只允许一次签出的话会不会对一个程序员压力太大?但保持程序的原子性固然是很重要的,这个方面需要怎么权衡比较好?
5.Page256 对于 “用场景驱动”,是指优先完成这个“场景需求”给用户了解,然后再逐步完善其他功能这样的吗?当遇到场景不符合客户需求时,需求改动是否会小一点?
冷知识
1975年,艾伦和盖茨给Altair 8800计算机写了个BASIC解释器卖给MITS,他们很快完成了解释器,甚至包括自己的IO系统和编辑器,一共只需要4k内存。 不过最后他们发现还需要一个引导程序将这些东西从外存整进去。 Paul Allen在飞机航班上完成了这项工作。这是1975年,没有笔记本。他用的是纸笔。写的是8080机器码
来源:计算机领域的大牛、大神们(包括历史上的以及现在的)有哪些奇闻轶事?
WordCount编程
Github地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 60 | 90 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 100 |
| • Design Spec | • 生成设计文档 | 30 | 20 |
| • Design Review | • 设计复审 | 20 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| • Design | • 具体设计 | 30 | 35 |
| • Coding | • 具体编码 | 360 | 1080 |
| • Code Review | • 代码复审 | 30 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 15 | 15 |
| • Size Measurement | • 计算工作量 | 20 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 15 |
| 合计 | 690 | 1475 |
解题思路
-
统计文件的字符数(对应输出第一行)
-
只需要统计Ascii码,汉字不需考虑
初步思路:1)处理字符串 过滤合法字符以外的字符
2)遍历统计数量
-
空格,水平制表符,换行符,均算字符
ASCII 范围 [32,126]+9+10
实际上当助教确认过不会出现中文时我是觉得有点小崩溃,删了好多判断中文的代码……
最终思路: 由于不会出现合法ASCII以外的字符,直接获取字符串长度即可
-
-
统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写
-
英文字母: A-Z,a-z
-
字母数字符号:A-Z, a-z,0-9
-
分割符:空格,非字母数字符号
-
例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
正则表达式 [a-zA-z]{4}[a-zA-Z0-9]*
若将所有字母变为小写后,正则表达式则为[a-z]{4}[a-z0-9]*
最终思路:在统计单词词频时维护一个words变量,则无需词频统计完再去遍历累加
-
-
统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计
最终思路:使用正则表达式"\\s*"来判断是否为空行,维护一个统计空行变量lines,有效行数=文件行数-空行行数
-
统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个
-
频率相同的单词,优先输出字典序靠前的单词。
例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
-
输出的单词统一为小写格式
最终思路:使用HashMap统计词频,全文处理结束后进行按要求排序,并输出Top10
-
代码规范
初步设计与后续改进
类设计
//工具类Lib
public class Lib {
//统计单词数
public static int countWords(String str)
//统计字符数
public static int countChars(String str)
//统计行数
public static int countLines(File file)
/* IO部分 */
//将文件读取至StringBuffer中
public static void readToBuffer(StringBuffer stringBuffer,String filePath)
//将Buffer中的数据读入String
public static String readFile(String filePath)
//输出成文件
public static void outputToFile(int words,int lines,int chars,HashMap<String,Integer>)
}
//WordCount只需调用即可
IO选取与设计
初步选取:BufferedReader
设计:按行处理
try {
is = new FileInputStream(inputPath);
BufferedReader reader = new BufferedReader(new InputStreamReader(is, StandardCharsets.UTF_8));
String line;
while ((line = reader.readLine()) != null) {
//按行读取,处理字符串
}
} catch (IOException e){
e.printStackTrace();
}
但发现数据量一旦增大,IO负担就会很高,下图是我采用读取5e7行数,每行为双单词拼接成的文本的数据集测试时的情况,其中红框为IO+字符串处理时间段,占据了处理程序的近50%,30s左右
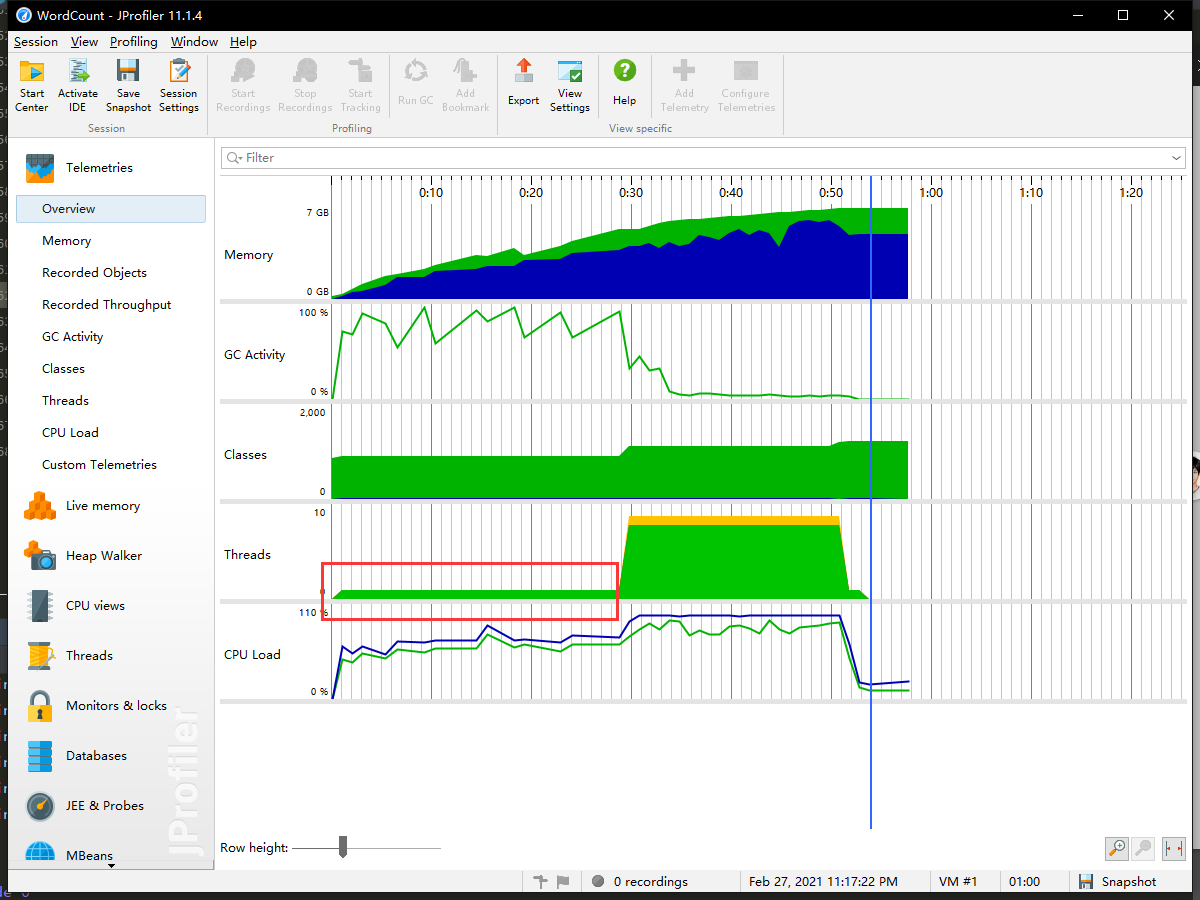
但BufferReader有个缺点按行读取是不能获取\r,于是有了下列改进
改进措施:MappedByteBuffer
| IO | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |
参考资料:Java NIO:IO与NIO的区别
public static String readFileInit() {
FileChannel fileChannel = null;
MappedByteBuffer byteBuffer = null;
try {
File file = new File(inputPath);
fileChannel = new RandomAccessFile(file,"r").getChannel();
byteBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY,0,file.length());
if(byteBuffer != null) {
return StandardCharsets.UTF_8.decode(byteBuffer).toString();
} else {
return "";
}
} catch (IOException e) {
e.printStackTrace();
} finally {
...
}
return "";
}
处理后的IO负载大幅度降低,如下图所示,读取5e7行数,每行为双单词拼接成的文本,由文件读取到交付线程处理耗时3s左右,相比BufferReader+StringBuilder处理,效率提升了很多
更惊喜的是GC的活动率和CPU负载都显著降低了
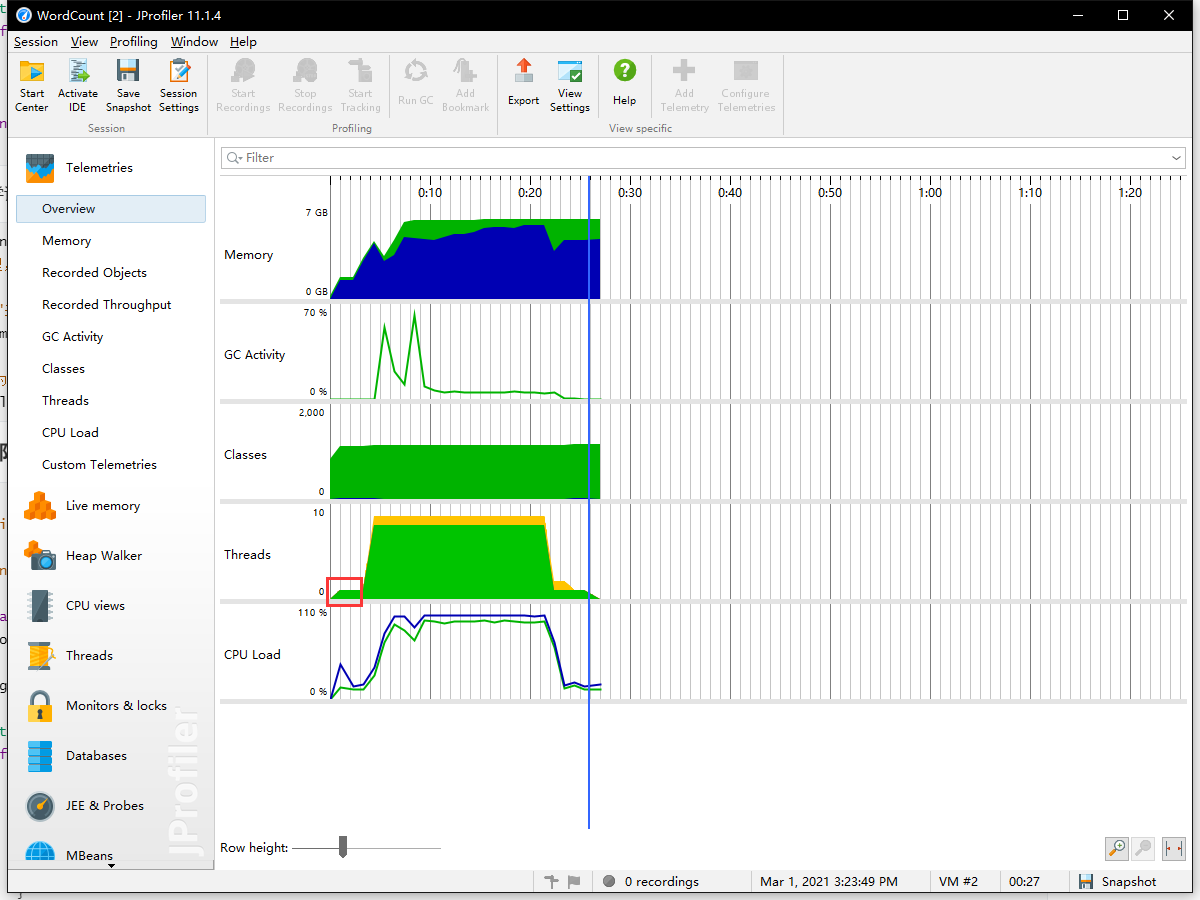
数据处理——初步设计部分
字符处理
遍历累计 改进为 NIO读取后直接获取长度 省时
空行判断
/*
* @description 统计文件行数
* @param file
* @return count
* */
public static int countLines(File file) throws FileNotFoundException {
int count = 0;
Scanner sc = new Scanner(file);
while (sc.hasNextLine()) {
String str = sc.nextLine();
if (!"".equals(str)) {
count++;
}
}
return count;
}
与李星源同学讨论后发现单纯判断不等于""是不可取的,\r\r\t\t\r 同样视为空行,但会被统计进去,改进如下:
String line;
/* 按行处理,以下代码为循环中的核心 */
//用"\\s*"来判断是否为空行 以此维护一个临时变量计算空行数量
if (line.matches(CONTAIN_N_REGEX)) tempLines++;
···
//有效行数为总行数-空行 在思路中也提到了
lines = allLines - lines;
词频统计部分
/*
* @description 将合法单词存入map中,并与单词个数绑定
* @param str
* @return pair
*/
public static Pair<HashMap<String,Integer>,Integer> makeWordPair(String str) {
int count = 0;
str = str.toLowerCase().replaceAll(FLITER_REGEX," ");
StringTokenizer words = new StringTokenizer(str);
while (words.hasMoreTokens()) {
String word = words.nextToken();
if (Pattern.matches(WORD_REGEX, word)) {
count++;
if (wordMap.containsKey(word)) {
wordMap.put(word, wordMap.get(word) + 1);
} else {
wordMap.put(word, 1);
}
}
}
return new Pair<>(wordMap,count);
}
/*
* @description 将map中的单词按value大小,key字典序排序,
* @param
* @return list
*/
public static List<HashMap.Entry<String, Integer>> getSortedList() {
List<HashMap.Entry<String, Integer>> wordList = new ArrayList<>();
wordList.addAll(wordMap.entrySet());
Comparator<Map.Entry<String, Integer>> cmp = (o1, o2) -> {
if(o1.getValue().equals(o2.getValue()))
return o1.getKey().compareTo(o2.getKey());
return o2.getValue()-o1.getValue();
};
wordList.sort(cmp);
return wordList;
}
现在回想起来用pair去把单词总数和词频映射绑定在一起是真的蠢……于是将代码进行了改进处理,重构了80%+……(为了效率必须牺牲自己)
数据处理——改进部分(程序精华)
思路
既然是按行读取并计算,每一行的文本与计算都应该是独立的,便可以拆分成多个子问题来解决——分而治之,多线程启动!
刚开始写多线程的时候,没有采取临时变量统计+总和的做法,于是就有一个线程霸占属性算完了全程的结果……
多线程计算返回数据至Map时,普通的HashMap是非线程安全的,但ConcurrentHashMap是线程安全的,但是他的get方法不是返回实时数据的,具有非一致性
所以我们需要对他的put,get方法进行重写,来保证我们获取的数据是正确的
/**
* @description 保证添加到ConcurrentHashMap中的数据正确
* @param word
*/
private static void add(String word) {
//value的类型根据声明时的value一致 此处换为int会获取到NULL 则无法判断
Integer value;
while (true) {
value = wordMap.get(word);
if (null == value) {
if (wordMap.putIfAbsent(word, 1) == null) break;
} else {
if (wordMap.replace(word, value, value + 1)) break;
}
}
}
处理数据函数
/**
* @description 计算空白行数
*/
private static void countLine() {
while(strArr.hasMoreTokens()) {
String line = strArr.nextToken();
if (line.matches(CONTAIN_N_REGEX)) lines++;
}
}
/**
* @description 统计[begin,end]区间内的词频
* @param begin
* @param end
*/
public static void countMap(int begin, int end) {
String tempStr = str.substring(begin,end);
//使用StringTokenizer分割字符串会比str.split()省时间还省空间
StringTokenizer tempSt = new StringTokenizer(tempStr);
while (tempSt.hasMoreTokens()) {
String line = tempSt.nextToken();
line = line.toLowerCase().replaceAll(FLITER_REGEX," ");
StringTokenizer tmpWords = new StringTokenizer(line);
int cnt = 0;
while (tmpWords.hasMoreTokens()) {
String word = tmpWords.nextToken();
if (Pattern.matches(WORD_REGEX, word)) {
//采用临时变量来统计,减少原子操作
cnt++;
//采用ConcurrentHashMap时一定要注意他的非一致性
if (wordMap.containsKey(word)) {
add(word);
} else {
add(word);
}
}
}
//数据归一的时候采用原子方法,保证数值的一致性
words.getAndAdd(cnt);
}
}
线程池装载
李星源同学给出的思路:直接按\n分段处理原字符串,就不需要再去分解或者拆行
这里还得多多感谢星源和我一起debug
/*
* @description 创建线程池求解
* @return
*/
public void poolSolve() {
//使用线程池求解 文本分为8块
...
pool.execute(() -> countLine());
//此处可自行采用新属性声明来实现控制分段数量
int MAX_LEN = chars >> 3;
//下列为星源提供的思路的实现
for (int i = 0;i<chars;i+=MAX_LEN) {
if (i > begin) {
for (j = i;j<chars;j++) {
if(str.charAt(j)=='\n') {
break;
}
}
int finalBegin = begin;
int finalEnd = j;
pool.execute(() -> countMap(finalBegin,finalEnd));
begin = j + 1;
}
}
//要注意begin小于总长度的情况
if (begin < chars) {
....再添加线程池中
}
...
}
本文的测试数据均由程序随机生成,项目地址:wordnet-random-name,感谢林浩然同学的项目资源提供
由于没有对文件进行很好的分割,导致读取文件时内存很大,测试前提是提供JVM8G以上的内存空间
测试数据规模:49,999,346行 平均每行字符大于10个 总计710mb
改进前的程序:运行耗时74271ms
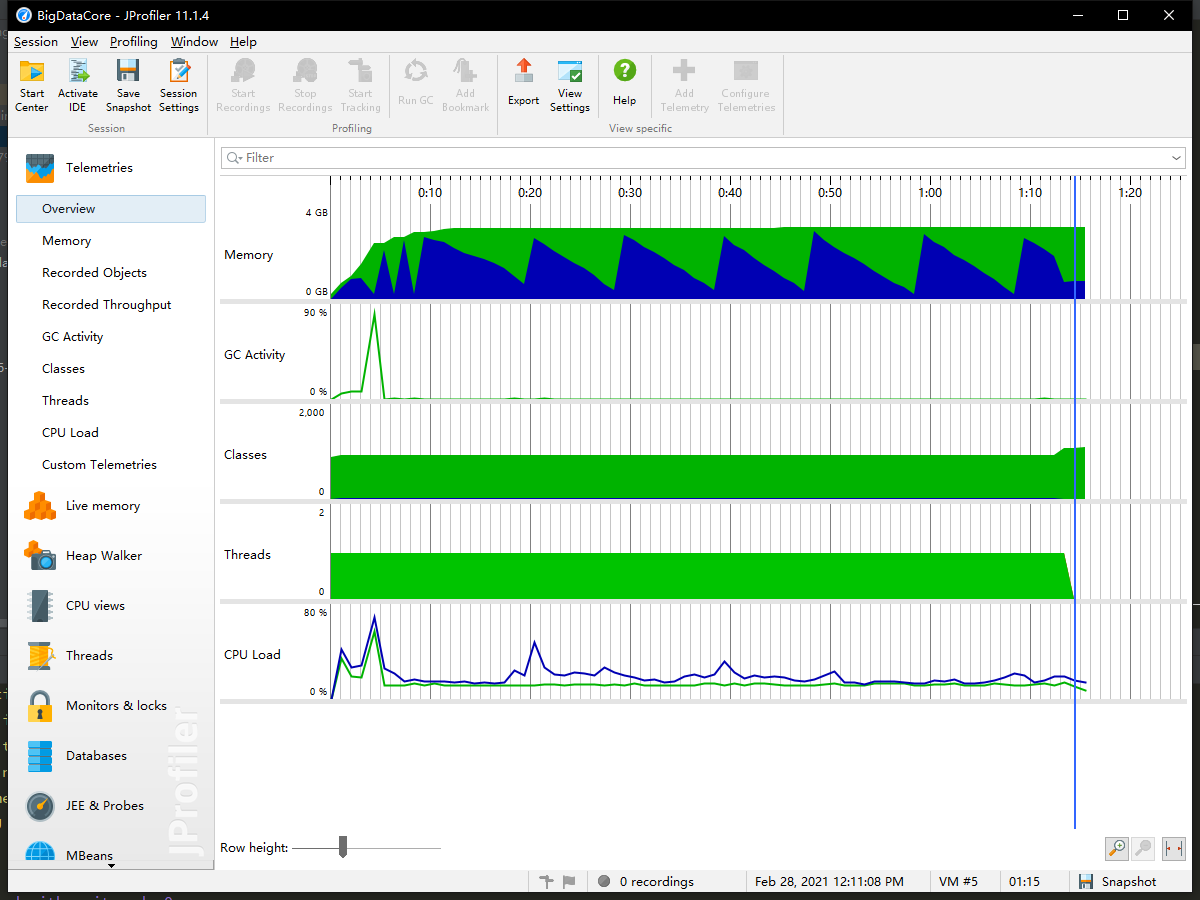
改进后的程序:运行耗时25058ms、26923ms,多次测试后稳定在25-27s,相比于改进前的程序,效率显著提升
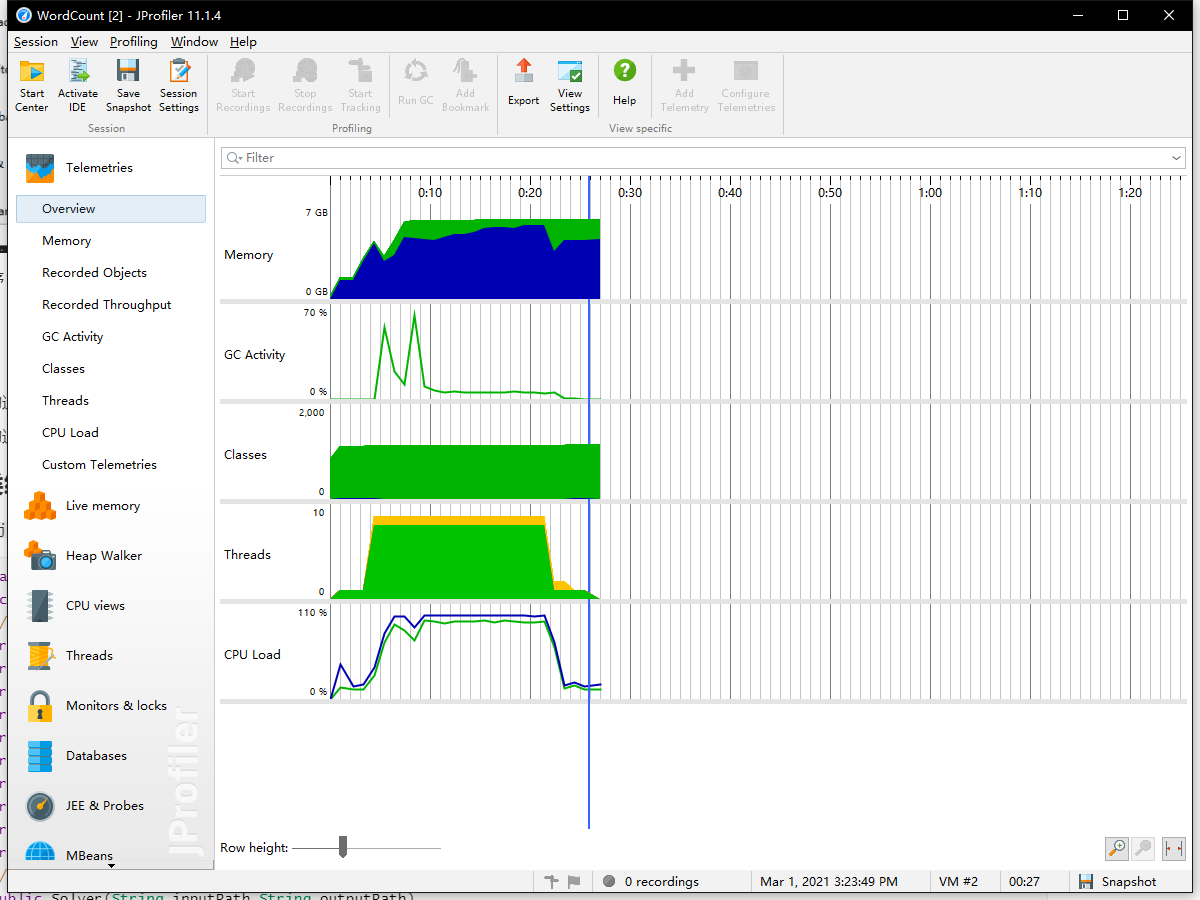
性能分析
- 改进前的运行效率较低,但是
CPU、GC两个方面较低,与运算效率有很大关系 - 改进后的运行效率高,IO负载小、
GC压力降低,但计算时CPU负载较大,内存占用较多
最终的类结构
WordCount.java
public class WordCount {
public Solver {
//属性声明
private static int lines;
private static int chars;
private static int allLines;
private static String str;
private static String inputPath;
private static String outputPath;
private static AtomicInteger words;
private static StringTokenizer strArr;
private static ConcurrentHashMap<String,Integer> wordMap;
private static ExecutorService pool;
//函数声明
public Solver(String inputPath,String outputPath)
public static String readFileInit()
public void setList()
private static void countLine()
private static void countMap(int begin, int end)
private static void add(String word)
public void poolSolve()
public static void outputToFile()
}
}
Lib.java
public class Lib {
//作为测试功能的工具类构建 只包含必要计算函数
public static int countChars(String str)
public static int countWords(String line,HashMap<String,Integer> wordMap)
public static List<HashMap.Entry<String, Integer>> getSortedList(HashMap<String,Integer> wordMap, boolean isPrint)
}
性能改进思路
- 分块由固定大小改成升序大小,增加随机性,线程在运行时不容易接近同时计算完毕,减少竞争等待,也有尝试过,但是数据太小随机性能并不是很好,若数据量到达一定规模可能会起到比较好的效果
- 优化行数处理,多分配线程去运算
测试与总结
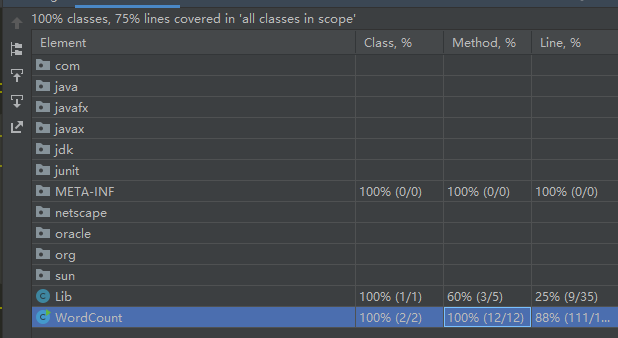
代码覆盖率
如下图,总覆盖率75%,其中Lib有2个函数分别是统计单词数量和统计字符数,在改进下已经不需要利用Lib中的两个函数,仅是作为接口进行测试使用,实际覆盖率应比结果高
代码覆盖率的优化:
- 构建一个异常类,在主程序用命令行接收时进行异常判断
- 删除重复代码,剔除不进入统计的代码
- 简化逻辑,少写复杂处理,尽量简洁
单元测试
1、字符统计
@Test
public void testCountChar() throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("MyTest1.txt"));
//构造一个包含字母、数字、符号、换行符的字符串
String str = "yiuyiuy3123[]asd\ns";
for (int i = 0;i<100;i++) {
bw.write(str);
}
bw.close();
int cnt = Lib.countChars("MyTest1.txt");
Assert.assertEquals(cnt,str.length()*100);
}
2、单词统计
@Test
public void testCountWords() throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("MyTest2.txt"));
//合法单词有300个 test1 200 check2 100
String str = "test1 check2 num \n test1\tyes te[st";
for (int i = 0;i<100;i++) {
bw.write(str);
}
bw.close();
/*文件读取*/
line = reader.readLine();
...
while (line != null) {
cnt += Lib.countWords(line,map);
line = reader.readLine();
}
Assert.assertEquals(cnt,300);
}
3、词频统计
@Test
public void testTop10() throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("MyTest3.txt"));
//构造一个包含字母、数字的字符串
String str = "yes test iiii 23qwe 666 zhenbuchuo ceshiceshi wuhu wuhu qifei Java PrOgRaM yeAh\n";
for (int i = 0;i<1000;i++) {
bw.write(str);
}
bw.close();
int cnt = 0;
/*文件读取*/
line = reader.readLine();
while (line != null) {
cnt += Lib.countWords(line,map);
line = reader.readLine();
}
cnt = 0;
StringBuilder str1 = new StringBuilder();
/*排序单词并构建字符串*/
String result = "wuhu: 2000\nceshiceshi: 1000\niiii: 1000\njava: 1000\nprogram: 1000\nqifei: 1000\ntest: 1000\n"
+ "yeah: 1000\nzhenbuchuo: 1000\n";
Assert.assertEquals(str1.toString(),result);
}
三个函数测试均正确
计算部分异常
- IO异常
- 线程中断异常
- 这次作业大部分异常都不属于计算异常,主要是文件处理方面的
心路历程
- 刚开始看这道题的时候,感觉就是很普通的算法入门题,本以为直接按题意直白编写就结束了,没想到其中的细节还有很多;和计算机的好朋友讨论了很多东西,最后选择了尝试改进IO与多线程处理
- 本来是2月28号就可以结束这次作业,但是在测试的时候发现了部分答案有误,于是就开始了紧张刺激的调试阶段,发现v2版本(也忘了有没有push到git)中采用NIO读取的数据分割有误,在班级群询问了助教以后确实有
\r\n\r\n这类数据的出现,也和吴铠嘉同学讨论了不少例子,最后是用了NIO中的mmap读取,效果十分显著 - 最重大的问题还是在多线程的处理上,刚开始我的多线程计算5e7规模的数据差不多是30s左右,但是感觉效果还不是很理想,于是就找到李星源同学一起讨论如何改进,他也是很辛苦,我从下午三点改到晚上十二点,他一直在解答我的疑惑,还给我提供思路,非常感谢他的支持
- 经过这一次作业的磨练,我体会到了严谨的重要性,如果没有很好的测试自己的程序,觉得大部分情况都尝试了就觉得算法正确的话很容易会得不偿失,就和之前在ACM训练赛时候一样,没有全方位的验证自己的算法,就不要随意尝试submit,很容易吃到罚时。严谨对于程序员来说真的是很重要的词条
- 同时我还巩固了课程中学的不怎么好的多线程,也学会了不断推翻自己的想法,用理论上更好的算法去实现,重构的过程是很痛苦的,最惨的一次是我把整个文件都删了重写,听到同学那边的效率更高,我就想能不能继续优化自己的代码,现在的结果已经让我比较满意了
- 单元测试的时候也是比较痛苦的,如何使得接口更加实用,更加简洁,也是我一直在想的问题,日后的单元测试我还得好好学学
收获与不足
- 本次作业最大的收获就是学会了如何更好的审查自己的代码,以及多线程中线程算法的优化处理
- 终于明白了Test类的重要作用,单元测试确实是一个很好检验代码正确性的途径,但是单元测试做的还不够仔细,希望在日后的学习中我可以更好的利用这项技术
- 对PSP表的时间估计有比较大的偏差,我也没想到我最后换思路改代码改了这么久

