福州大学软件工程实践第二次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | <学会如何简单分析和处理数据,提高解决陌生问题的能力> |
| 学号 | <041801516> |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 70 | 120 |
| Design Spec | 生成设计文档 | 25 | 20 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 30 |
| Design | 具体设计 | 60 | 65 |
| Coding | 具体编码 | 300 | 420 |
| Code Review | 代码复审 | 50 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 210 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 50 | 40 |
| Size Measurement | 计算工作量 | 30 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 180 |
| 合计 | 875 | 1175 |

解题思路
刚开始看题的时候,第一反应就是这真的是题目吗?这有人能看懂?(实在不行就放弃吧,挣扎是没用的)。
咳咳,随着 deadline 的逼近,不得不逼自己认真看题。原来打算用比较熟悉的 cpp 来完成作业,当看到示例程序和文件格式之后,果断使用 Python 。
但是由于不常使用 Python,俗话说:工欲善其事,必先利其器。所以第一步就是简单地复习语法,以及关于 json 模块的常见使用方法。之后再重复读了好几遍题目和示例程序,看懂了一些大概意思,就是让我们写的程序,能够统计一些要求的信息数量,并且给出查询接口。
由于对 Python 的应用不太熟悉,所以只能参考示例程序和其他同学的代码。但完全复制并没有任何作用,所以我尽可能的在了解每一句的作用之后,尝试用自己的编程风格和思路进行编码,期间也出现了很多问题,经过百度之后,有些解决了,有些还未解决。对于未解决的问题,我会直到解决为止。

设计实现过程
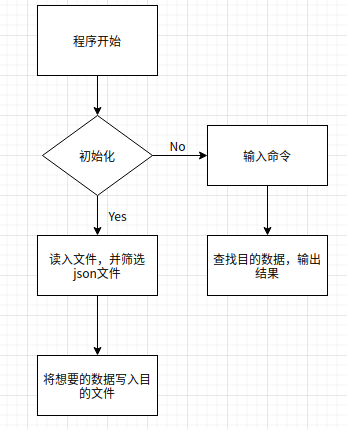
参考示例程序和其他同学的代码,很容易得到流程图,明确了步骤之后,就可以开始编码了。
代码
Data的初始化
# 初始化函数
def __init__(self, dict_address: str = '', initialization : int = 0):
if initialization == 1:
self.loadData(dict_address)
# 如果未找到文件则报错
if dict_address is '' and not os.path.exists("user_event.json") and not os.path.exit("repo_event.json") and not os.path.exists("user_repo_event.path"):
raise RuntimeError("Error: Init Failed, Please check your file")
关键的数据写入文件的函数
# 装载数据,将数据写入到事先建立好的三个json文件中
def loadData(self, dict_address: str):
user_event = {}
repo_event = {}
user_repo_event = {}
need_event = ["PushEvent","IssueCommentEvent","IssuesEvent","PullRequestEvent"]
# 找json文件
for root, dirs, files in os.walk(dict_address):
for file in files:
if file[-5 : ] == ".json":
json_path = file
# 打开json文件,逐行读取
json_file = open(dict_address + '/' + json_path, 'r', encoding='UTF-8').readlines()
for line in json_file:
line = json.loads(line)
# 如果是我们要的类型,进行统计、写入操作
if line["type"] in need_event:
self.addUserEvent(line, user_event)
self.addRepoEvent(line, repo_event)
self.addUserRepoEvent(line, user_repo_event)
# 将文件转为json格式存储
with open("user_event.json", 'a') as file:
json.dump(user_event, file)
with open("repo_event.json", 'a') as file:
json.dump(repo_event, file)
with open("user_repo_event.json", 'a') as file:
json.dump(user_repo_event, file)
同样关键的事件数量统计
# 按要求统计,新出现的就新建
def addUserEvent(self, dict, user_event):
user_id = dict['actor']['login']
event = dict['type']
if user_id not in user_event:
user_event[user_id] = {'PushEvent':0, 'IssueCommentEvent':0, 'IssuesEvent':0, 'PullRequestEvent':0}
user_event[user_id][event] += 1
def addRepoEvent(self, dict, repo_event):
repo = dict['repo']['name']
event = dict['type']
if repo not in repo_event:
repo_event[repo] = {'PushEvent':0, 'IssueCommentEvent':0, 'IssuesEvent':0, 'PullRequestEvent':0}
repo_event[repo][event] += 1
def addUserRepoEvent(self, dict, user_repo_event):
user_id = dict['actor']['login']
repo = dict['repo']['name']
event = dict['type']
if user_id not in user_repo_event:
user_repo_event[user_id] = {}
user_repo_event[user_id][repo] = {'PushEvent':0, 'IssueCommentEvent':0, 'IssuesEvent':0, 'PullRequestEvent':0}
if repo not in user_repo_event[user_id]:
user_repo_event[user_id][repo] = {'PushEvent':0, 'IssueCommentEvent':0, 'IssuesEvent':0, 'PullRequestEvent':0}
user_repo_event[user_id][repo][event] += 1
查询接口
# 返回要查询的参数
def getUserEvent(self, user, event):
x = open("user_event.json", 'r', encoding='utf-8').read()
data = json.loads(x)
return data[user][event]
def getRepoEvent(self, repo, event):
x = open("repo_event.json", "r", encoding="utf-8").read()
data = json.loads(x)
return data[repo][event]
def getUserRepoEvent(self, user, repo, event):
x = open("user_repo_event.json", "r", encoding="utf-8").read()
data = json.loads(x)
return data[user][repo][event]
由于之前没有接触过用命令行运行程序的例子,所以只能老老实实的先用,再摸索,学习
# 命令行参数设置
class Run:
def __init__(self):
self.parser = argparse.ArgumentParser()
self.parser.add_argument('-i', '--init')
self.parser.add_argument('-u', '--user', type=str)
self.parser.add_argument('-r', '--repo', type=str)
self.parser.add_argument('-e', '--event', type=str)
self.Working()
def Working(self):
args = self.parser.parse_args()
if args.init:
data = Data(args.init, 1)
elif args.user and args.event and not args.repo:
data = Data()
print(data.getUserEvent(args.user, args.event))
elif args.repo and args.event and not args.user:
data = Data()
print(data.getRepoEvent(args.repo, args.event))
elif args.user and args.repo and args.event:
data = Data()
print(data.getUserRepoEvent(args.user, args.repo, args.event))
if __name__ == '__main__':
function = Run()
单元测试
测试代码
import pytest
import GHAnalysis
def test_init():
data = GHAnalysis.Data("/media/liwei-change/学习/Code/Ubuntu_Code/Python/软工实践", 1)
assert 1
def test_user_event():
data = GHAnalysis.Data()
res = data.getUserEvent("greatfire", "PushEvent")
assert res == 24
def test_repo_event():
data = GHAnalysis.Data()
res = data.getRepoEvent("katzer/cordova-plugin-background-mode", "PushEvent")
assert res == 0
def test_user_repo_event():
data = GHAnalysis.Data()
res = data.getUserRepoEvent("greatfire", "greatfire/wiki", "PushEvent")
结果

关于优化
代码覆盖(英语:Code coverage)是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。
--百度百科
通过百度之后,利用 pytest-cov 进行覆盖率测试

目前还不太了解代码覆盖率,对于优化也束手无策,希望通过今后的学习,把这些问题搞懂,而不是得过且过。

代码规范
个人代码规范
总结
对我而言,这次作业收获很大。在仔细读题和阅读他人代码之后,才知道此次的实验任务并不是很困难,只是自己缺少耐心和对探索新东西的渴望。
在编程过程中遇到了一些困难,比如在初始化之后再次初始化会报错, json 文件和字典的互相转化。也正是这些困难,推动着我们一次次地去查资料,去看别人的代码,我觉得这也是一种很好的学习方法,在刚涉足一个不太熟悉的领域时,模仿他人的成功是很重要的,但是这不意味着自己完成了任务,只有在模仿他人的过程中,自己能够从中学会解决问题的方法和思路,并且能够提出新的想法和疑问,这才是真正学习。
同时在这次的作业完成过程中,深感自己的能力还远远不足,学习之路还长,希望自己加快脚步追上那些优秀的同学们。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号