DASCTF X SU RE方向 stargate easyre
解出情况:
年轻人的第一个一血()
easyre
跑一下 提示wrong
ida32打开函数很少 没有wrong字符
但是有
vmp壳
scyllahide插件调一下
x32dbg动调 一路run到输入
然后暂停 然后alt+f9运行到用户代码
scylla
点dump
ida32分析dump出文件 字符串定位到right
finger插件分析一下里面的函数(或者肉眼看
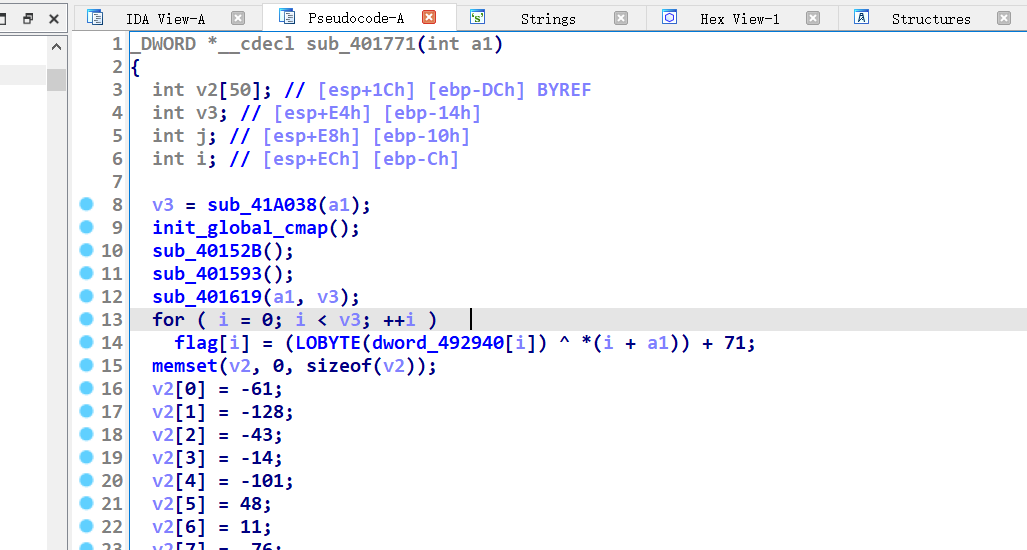
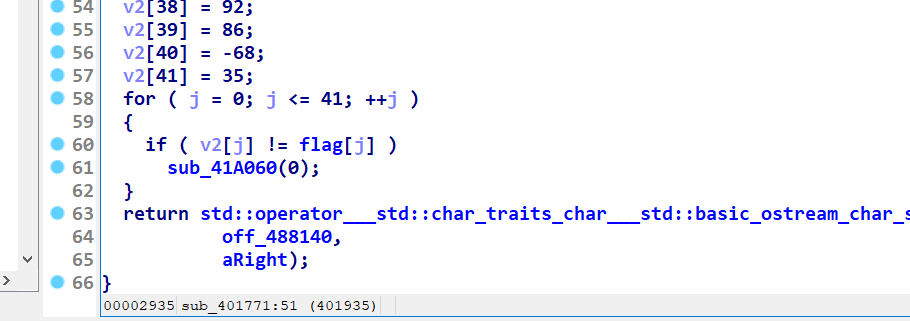
拿到dword_492940即可
一个异或加法 比对
构造DASCTF{aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa}
让x32dbg断在004017CA 并打印ecx的值
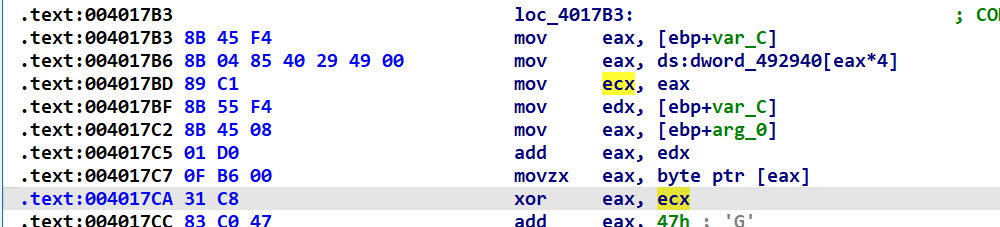

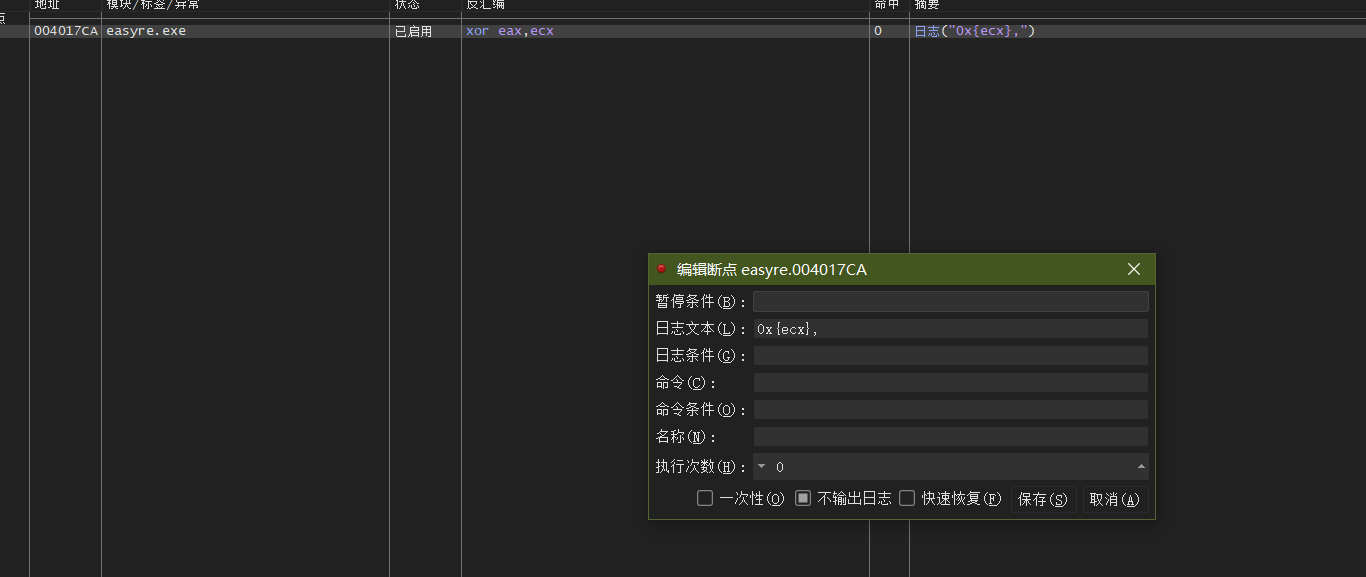
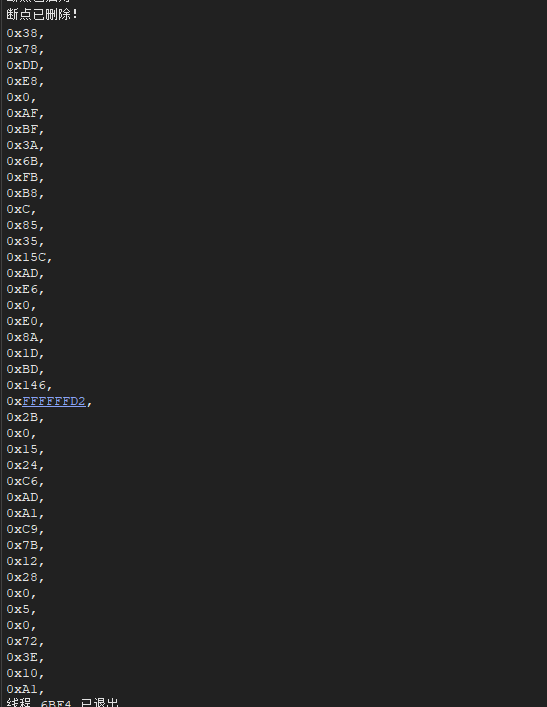
最后脚本
enc = [0] * 42
enc[0] = 0xFFFFFFC3;
enc[1] = 0xFFFFFF80;
enc[2] = 0xFFFFFFD5;
enc[3] = 0xFFFFFFF2;
enc[4] = 0xFFFFFF9B;
enc[5] = 0x30;
enc[6] = 0xB;
enc[7] = 0xFFFFFFB4;
enc[8] = 0x55;
enc[9] = 0xFFFFFFDE;
enc[10] = 0x22;
enc[11] = 0xFFFFFF83;
enc[12] = 0x2F;
enc[13] = 0xFFFFFF97;
enc[14] = 0xFFFFFFB8;
enc[15] = 0x20;
enc[16] = 0x1D;
enc[17] = 0x74;
enc[18] = 0xFFFFFFD1;
enc[19] = 1;
enc[20] = 0x73;
enc[21] = 0x1A;
enc[22] = 0xFFFFFFB2;
enc[23] = 0xFFFFFFC8;
enc[24] = 0xFFFFFFC5;
enc[25] = 0x74;
enc[26] = 0xFFFFFFC0;
enc[27] = 0x5B;
enc[28] = 0xFFFFFFF7;
enc[29] = 0xF;
enc[30] = 0xFFFFFFD3;
enc[31] = 1;
enc[32] = 0x55;
enc[33] = 0xFFFFFFB2;
enc[34] = 0xFFFFFFA4;
enc[35] = 0xFFFFFFAE;
enc[36] = 0x7B;
enc[37] = 0xFFFFFFAC;
enc[38] = 0x5C;
enc[39] = 0x56;
enc[40] = 0xFFFFFFBC;
enc[41] = 0x23;
d = [0x38,
0x78,
0xDD,
0xE8,
0x0,
0xAF,
0xBF,
0x3A,
0x6B,
0xFB,
0xB8,
0xC,
0x85,
0x35,
0x15C,
0xAD,
0xE6,
0x0,
0xE0,
0x8A,
0x1D,
0xBD,
0x146,
0xFFFFFFD2,
0x2B,
0x0,
0x15,
0x24,
0xC6,
0xAD,
0xA1,
0xC9,
0x7B,
0x12,
0x28,
0x0,
0x5,
0x0,
0x72,
0x3E,
0x10,
0xA1, ]
for index in range(42):
print(chr(((enc[index] - 71) ^ (d[index])) & 0xff), end="")
stargate
一血!
真恶心啊( 每次连上靶机的文件 地址 字符串 路径都不一样 而且只有两分钟时间解
nc连上靶机之后给一个base64字符串 解密dump下来
ida64分析
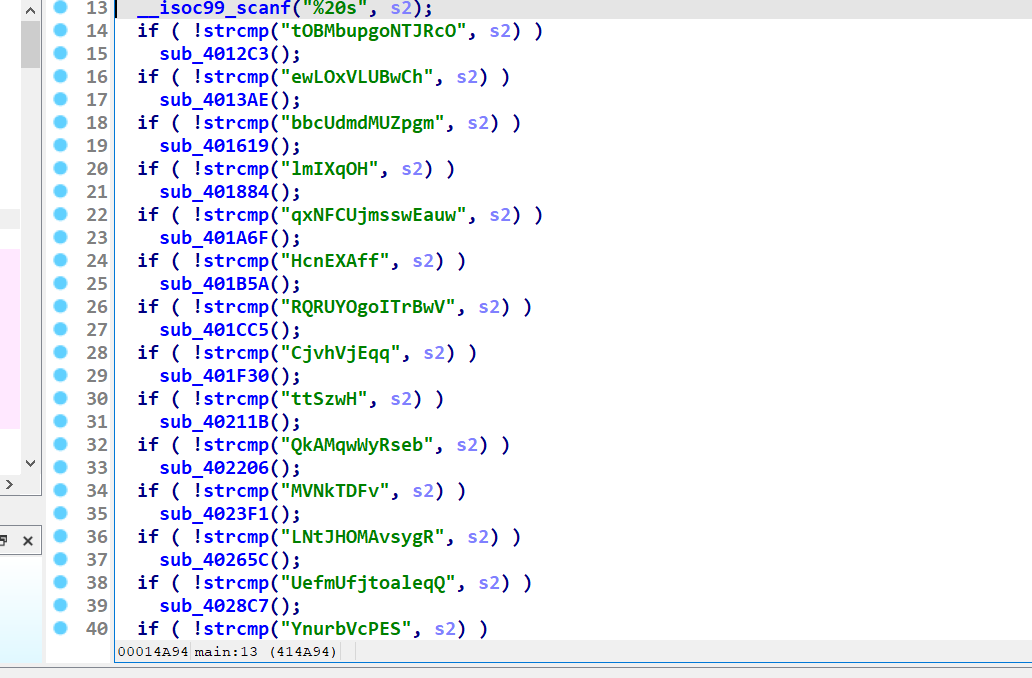
main函数这样
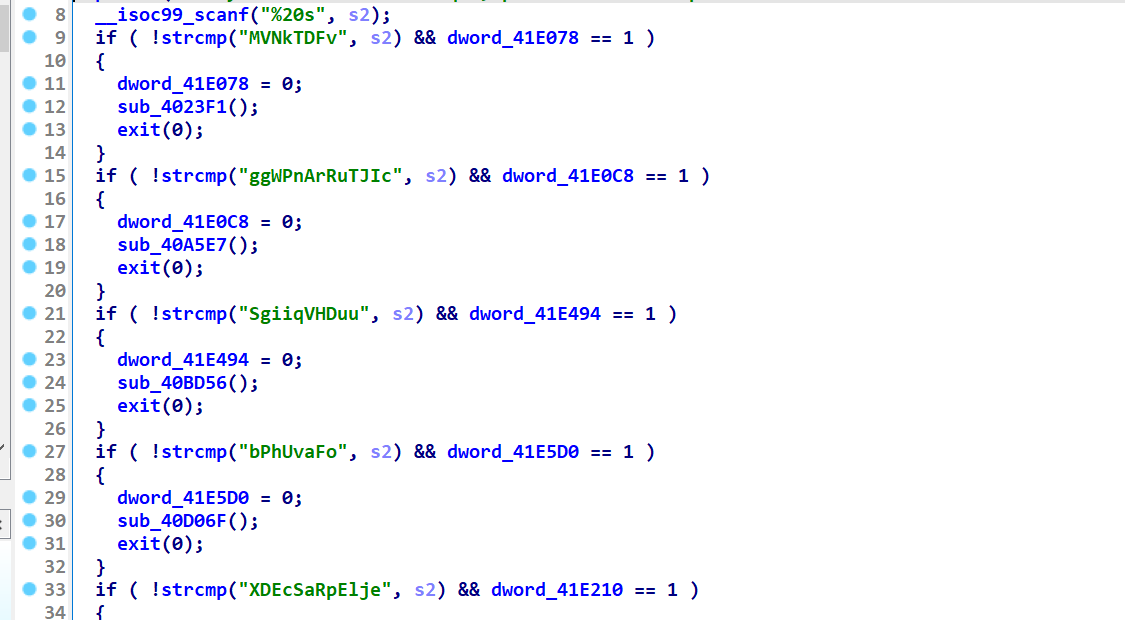
别的函数都形如这样 输入一个字符串进入下一个函数 并将一个dword置零
你能通过字符串cat flag找到一个形如这样的特殊函数
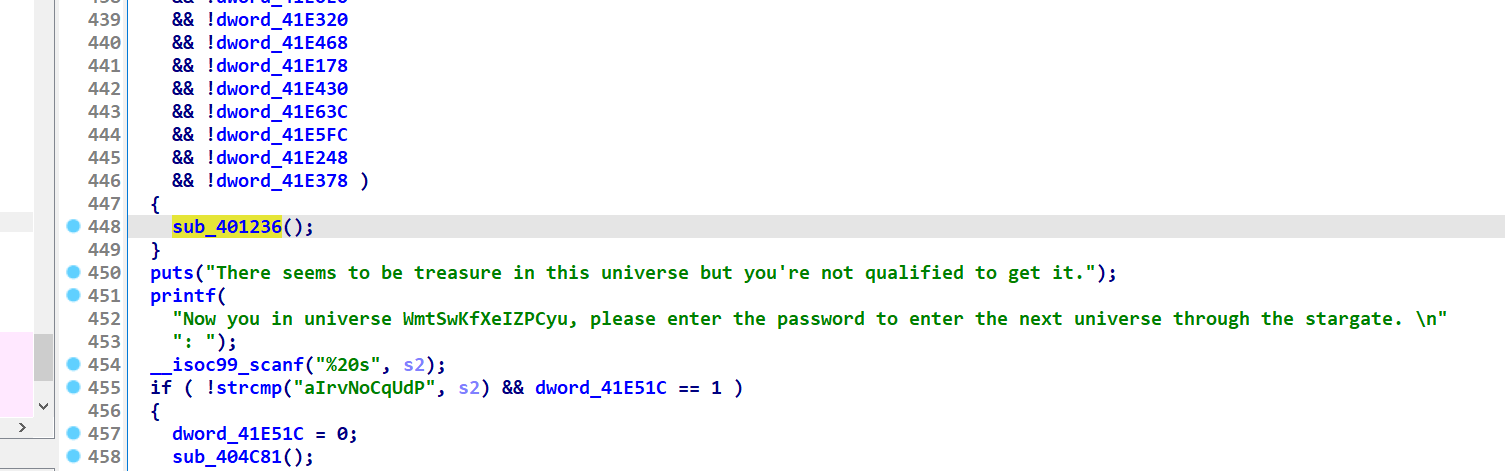
易知道这是个图 是个一笔画问题 寻找欧拉路径即可
每个函数是点
上面的dword 随便交叉应用一个会发现是边
有几个难点
1.2分钟靶机时间 复制base64字符串再dump太慢 所以上pwntool
2.每次生成的文件不一样 所以必须能解析所有形式 所以决定用ida dump c 再拿正则表达式匹配
3.点有几百个 边有512条 (大概 所以只能自动化提交
4.因为大一还没学到欧拉路径算法 所以网上偷一个相关脚本(
#autosolve.py
from pwn import *
import work
import base64
context(log_level="DEBUG")
io=remote("node4.buuoj.cn",27463)
io.recvuntil("Gate")
code=io.recvuntil("==end==")
with open("stargate",'wb') as f:
f.write(base64.b64decode(code[:-8]))
print("when ready, press enter to continue.")
raw_input()
work.work()
with open("res.txt") as f:
#因为找出来的路径可能首尾顺序不对
print("select mode: 1.normal 2.reverse")
mode=raw_input()
res=f.readlines()
if mode=='2':res=res[::-1]
for line in res:
io.sendline(line.strip())
io.recvuntil(":")
io.interactive()
#work.py
import re
from copy import copy
def is_connected(G):
start_node = list(G)[0]
color = {v: 'white' for v in G}
color[start_node] = 'gray'
S = [start_node]
while len(S) != 0:
u = S.pop()
for v in G[u]:
if color[v] == 'white':
color[v] = 'gray'
S.append(v)
color[u] = 'black'
return list(color.values()).count('black') == len(G)
def odd_degree_nodes(G):
odd_degree_nodes = []
for u in G:
if len(G[u]) % 2 != 0:
odd_degree_nodes.append(u)
return odd_degree_nodes
def from_dict(G):
links = []
for u in G:
for v in G[u]:
links.append((u, v))
return links
def fleury(G):
'''
checks if G has eulerian cycle or trail
'''
odn = odd_degree_nodes(G)
if len(odn) > 2 or len(odn) == 1:
return 'Not Eulerian Graph'
else:
g = copy(G)
trail = []
if len(odn) == 2:
u = odn[0]
else:
u = list(g)[0]
while len(from_dict(g)) > 0:
current_vertex = u
for u in g[current_vertex]:
g[current_vertex].remove(u)
g[u].remove(current_vertex)
bridge = not is_connected(g)
if bridge:
g[current_vertex].append(u)
g[u].append(current_vertex)
else:
break
if bridge:
g[current_vertex].remove(u)
g[u].remove(current_vertex)
g.pop(current_vertex)
trail.append((current_vertex, u))
return trail
def work():
with open("stargate.c", "r") as f:
t = f.read()
a___AAAA = re.findall(' if \( !strcmp\(".*?", s2\) \)\n sub_[0123456789abcdefABCDEF]{6}\(\);', t)
for index in range(len(a___AAAA)):
a___AAAA[index] = a___AAAA[index].replace(" ", "")
a___AAAA[index] = a___AAAA[index].replace(r'",s2))', "")
a___AAAA[index] = a___AAAA[index].replace(r'if(!strcmp("', "")
a___AAAA[index] = a___AAAA[index].replace(r'();', "")
a = []
for x in a___AAAA:
x = x.split()
a.append(x[0])
a.append(x[1])
# 这俩字典都是找函数名字和输入字符串对应的
func_dic0 = {}
func_dic1 = {}
for index in range(0, len(a), 2):
func_dic0[a[index]] = a[index + 1]
func_dic1[a[index + 1]] = a[index]
func_name = []
for x in func_dic1:
func_name.append(x)
with open("stargate.c", "r") as f:
t = f.read()
func_dots = {}
funcs = re.findall(
'__int64 sub_[0123456789abcdefABCDEF]{6}\(\)\n{\n char s2\[40\]; // \[rsp\+0h\] \[rbp\-30h\] BYREF\n unsigned __int64 v2; // \[rsp\+28h\] \[rbp\-8h\].*?Wrong password!',
t, re.DOTALL)
ttttt = {}
for func in funcs:
tname = re.findall("sub_[0123456789abcdefABCDEF]{6}", func)[0]
tid = func_name.index(tname)
# 用ttttt来表示点与点的联通关系
ttttt[tid] = []
tinfo = re.findall(" dword_[0123456789abcdefABCDEF]{6} = 0;\n sub_[0123456789abcdefABCDEF]{6}\(\);", func)
for x in tinfo:
tsub = re.findall("sub_[0123456789abcdefABCDEF]{6}", x)[0]
tttid = func_name.index(tsub)
ttttt[tid].append(tttid)
# fleury只接受这样的参数 {0: [1, 6], 1: [0, 2, 9, 45, 58, 100, 136, 142]...} 表示从第几个点到第几个点
r = fleury(ttttt)
with open("res.txt", "w")as f:
for x in r:
f.write(func_dic1[func_name[x[0]]])
f.write("\n")
f.write(func_dic1[func_name[r[-1][1]]])d
先连上靶机 然后等文件夹下出现stargate文件
然后ida64分析
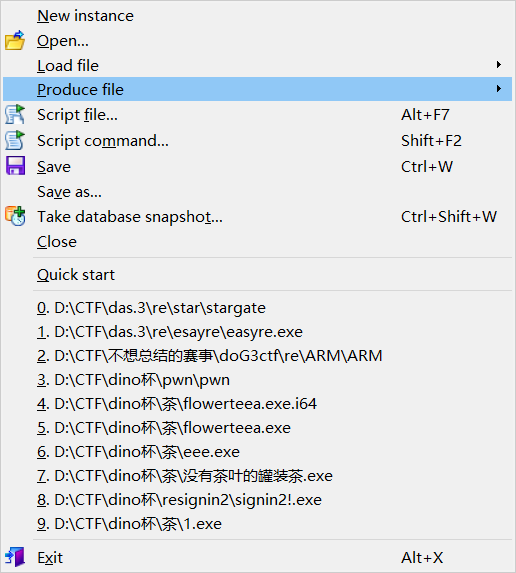
选择creat c file
然后回车脚本继续运行
会生成res.txt
手动看一眼头尾顺序对不对
然后再自动提交
getflag!

