软件工程基础 微软OCR-Form-Tools体验
一点说明
这篇博客是软件工程基础(罗杰、任建)的第三次课程作业(个人项目作业)
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 软件工程基础(罗杰,任建) |
| 这个作业的要求在哪里 | 作业要求的链接 |
| 我在这个课程的目标是 | 提升对软件工程的宏观和微观的全面认识,并加以实践 |
| 作业在哪些方面帮我实现目标 | 当了一把体验官! |
| 我的教学班级 | 006 |
调研、评测
1. 下载与安装
- 网页直接访问:https://fott.azurewebsites.net/
- 本地部署:详细步骤请见博客 OCR-Form-Tools项目试玩记录(一)本地部署
2. 基本功能体验
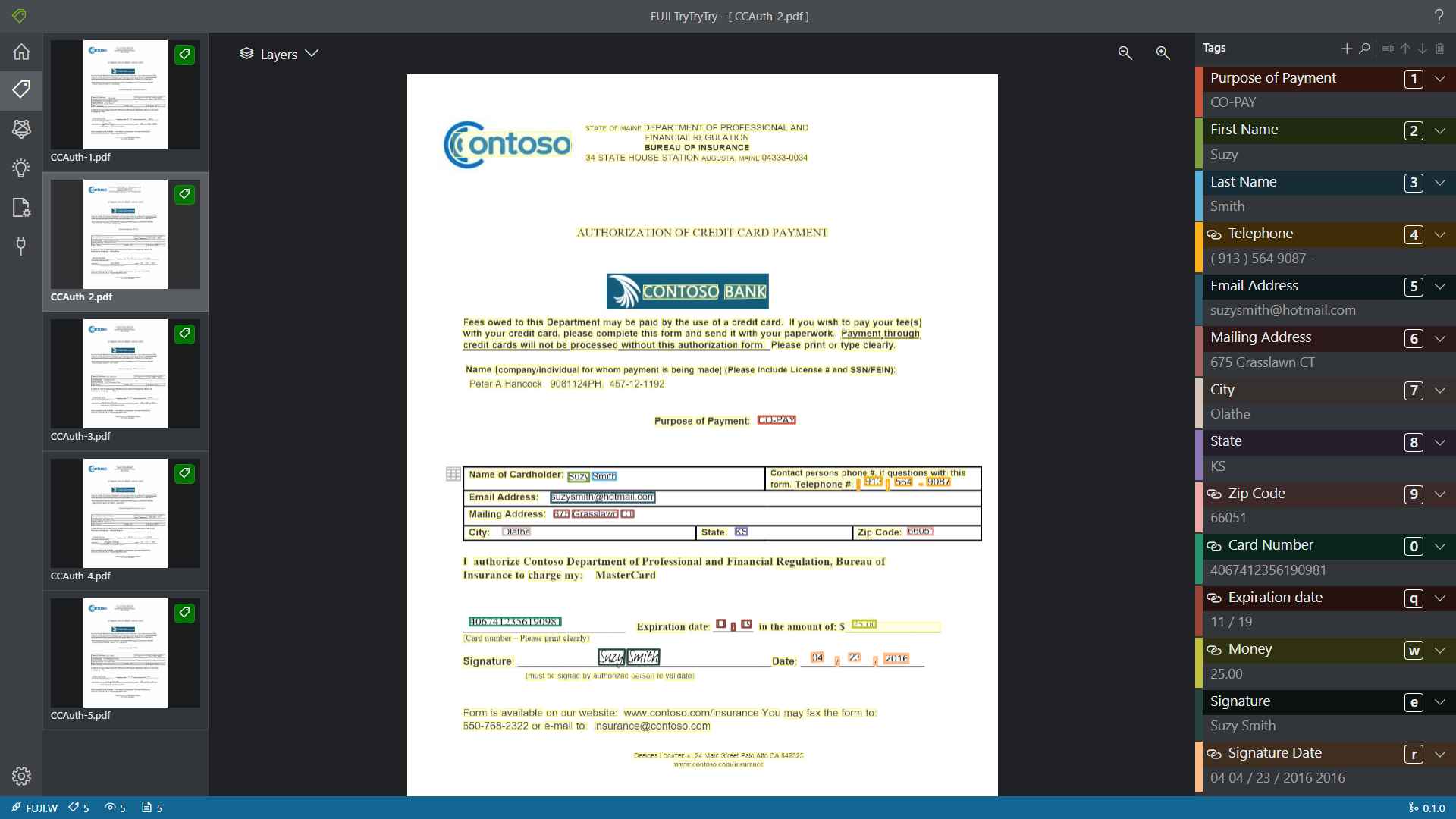
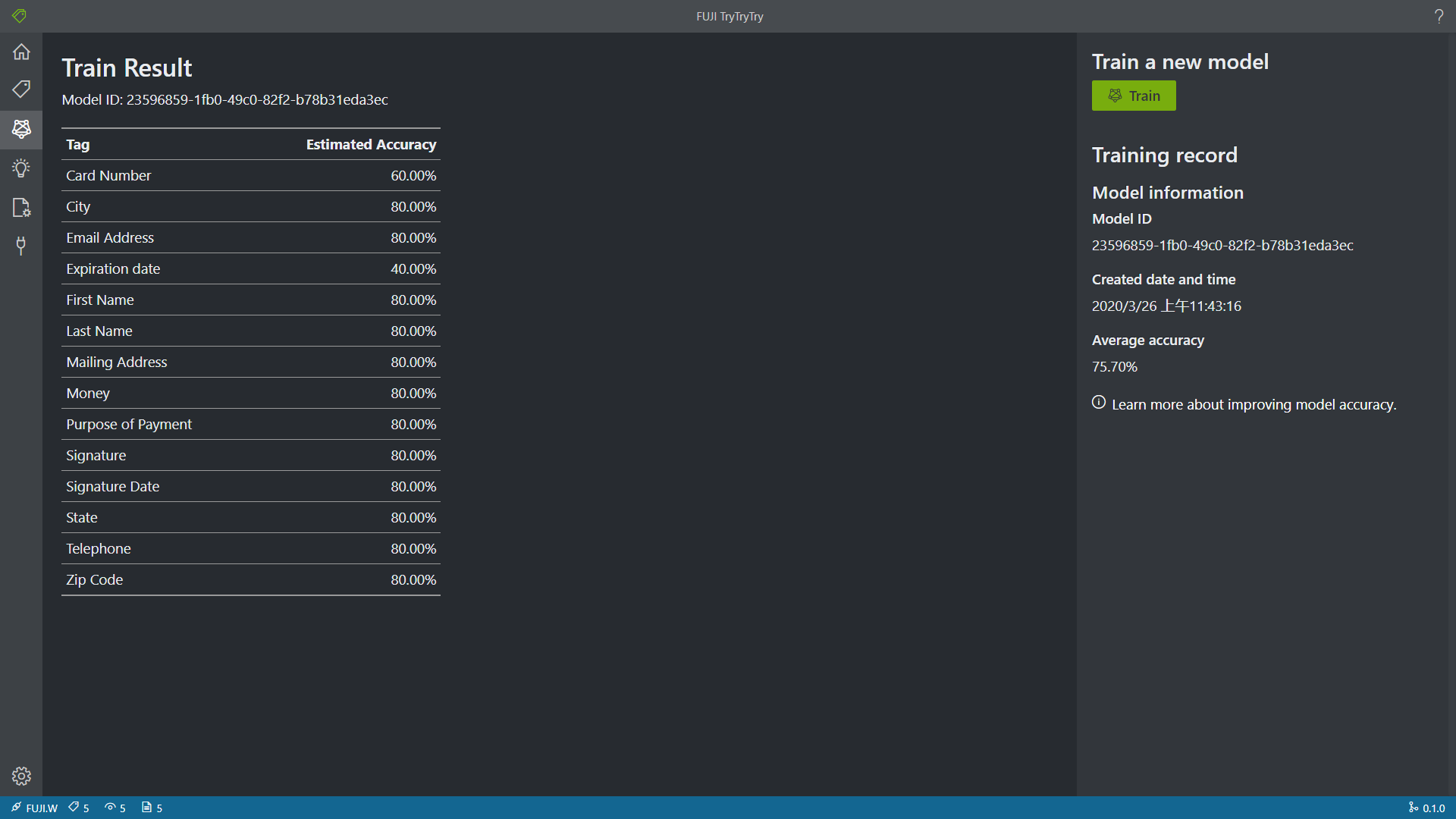
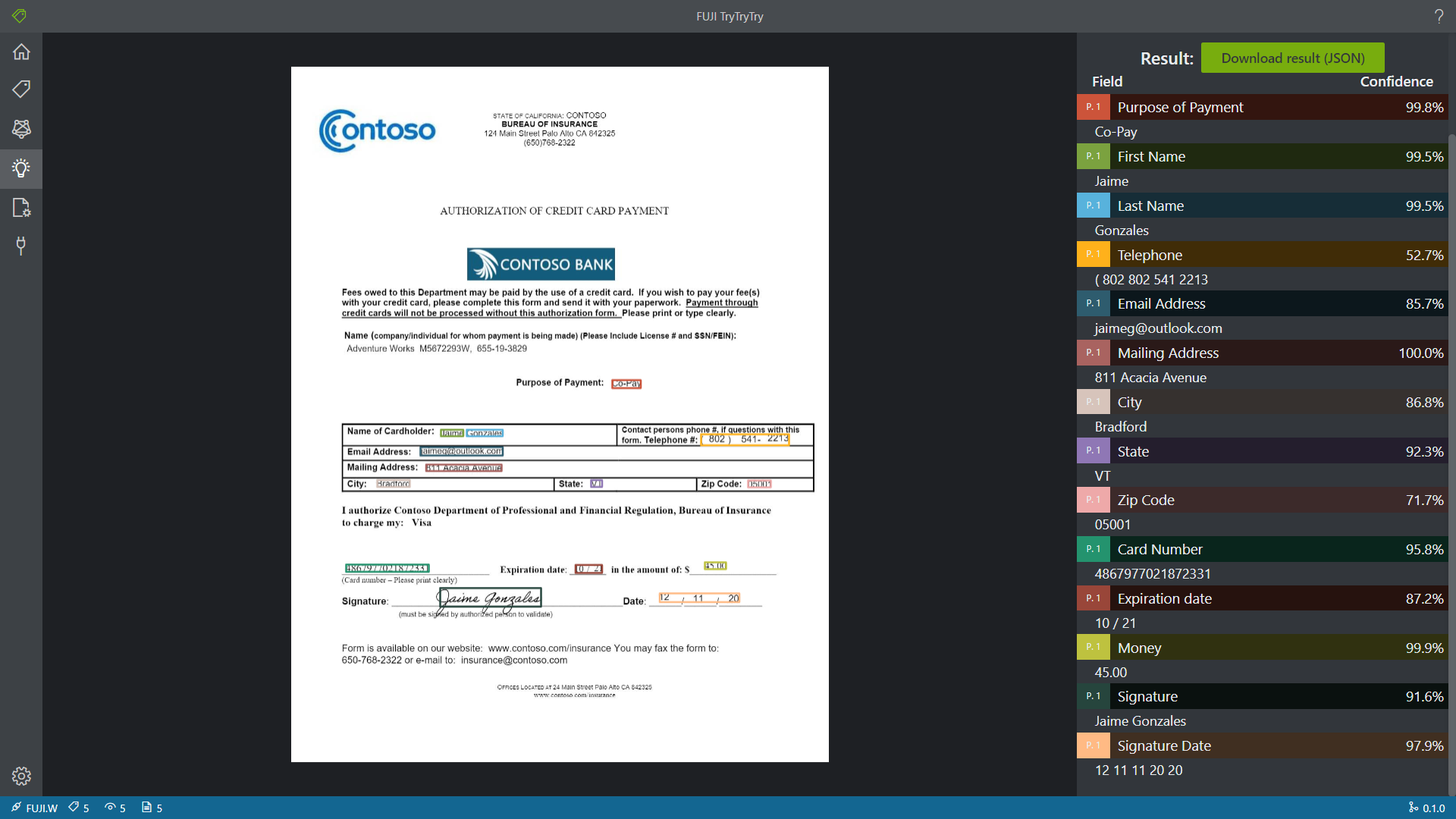
使用10–30分钟这个软件的基本功能(请上传使用软件的照片)
在博客 OCR-Form-Tools项目试玩记录(二)产品评测 中,Mis Tariano详细介绍了软件的完整运行流程,我就不再赘述了,这里仅分享一下本人的一些功能体验。
3. 直击痛点?
解决了用户的问题么?软件在数据量/界面/功能/准确度上各有什么优缺点?用户体验方面有问题么?
-
直击痛点:自主的Tag选择与训练、手写体的良好识别、Json格式的导出,我相信是目前为止PDF表单处理的最好解决方案之一;
-
数据量:邹欣老师给出的示例中,仅用5例训练就可以得到较好的模型,非常nice;
-
界面:微软家软件近几年来一贯的扁平风,舒适简约又不失设计感,整个流程体验下来非常丝滑;
-
准确度:在我有限的测试中,除去一些小的数字重复的BUG(详见下文),没有发现其他的正确性问题,其对于表格中各项内容的识别拥有极细的颗粒度,没有出现其他OCR工具常出现的词语粘连的问题;
4. BUG在哪里
下载, 部署并体验软件的功能,按照描述的bug定义,找出至少2个功能性bug。用专业的语言描述(每个bug不少于40字),如有必要,可以配图。
-
功能性BUG
-
(Chrome浏览器)在 Tags Editor界面,使用 F11 快捷键进行全屏显示时,会弹出 “Type Error”的提示框。将提示框关闭后,发现其实可以正常全屏显示。(多次尝试,可复现)
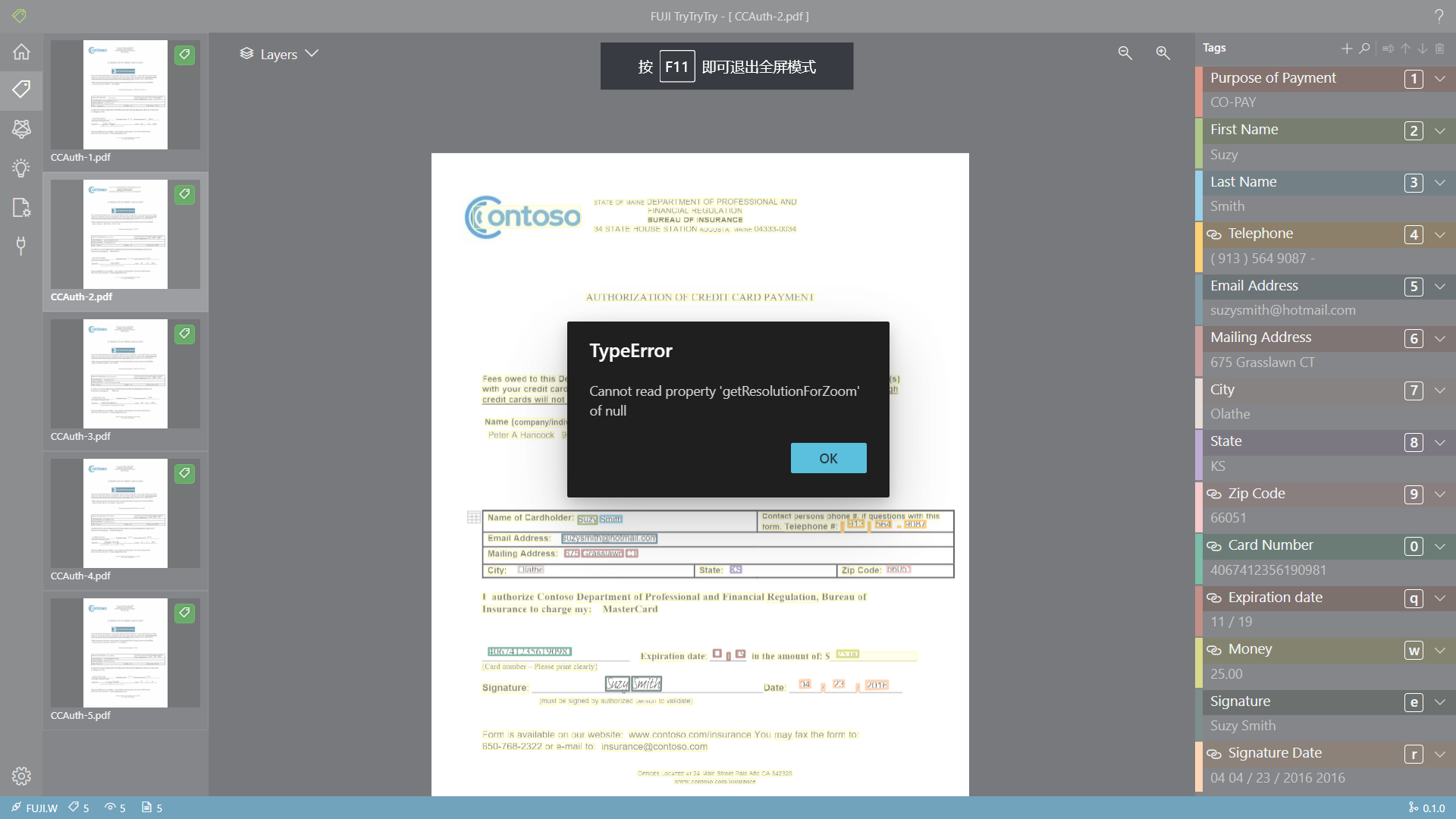
使用F11快捷键,弹出错误提示
点击OK后,发现界面其实成功地全屏显示 -
侧边浏览区域不能拖拽缩放,但是有拖拽提示
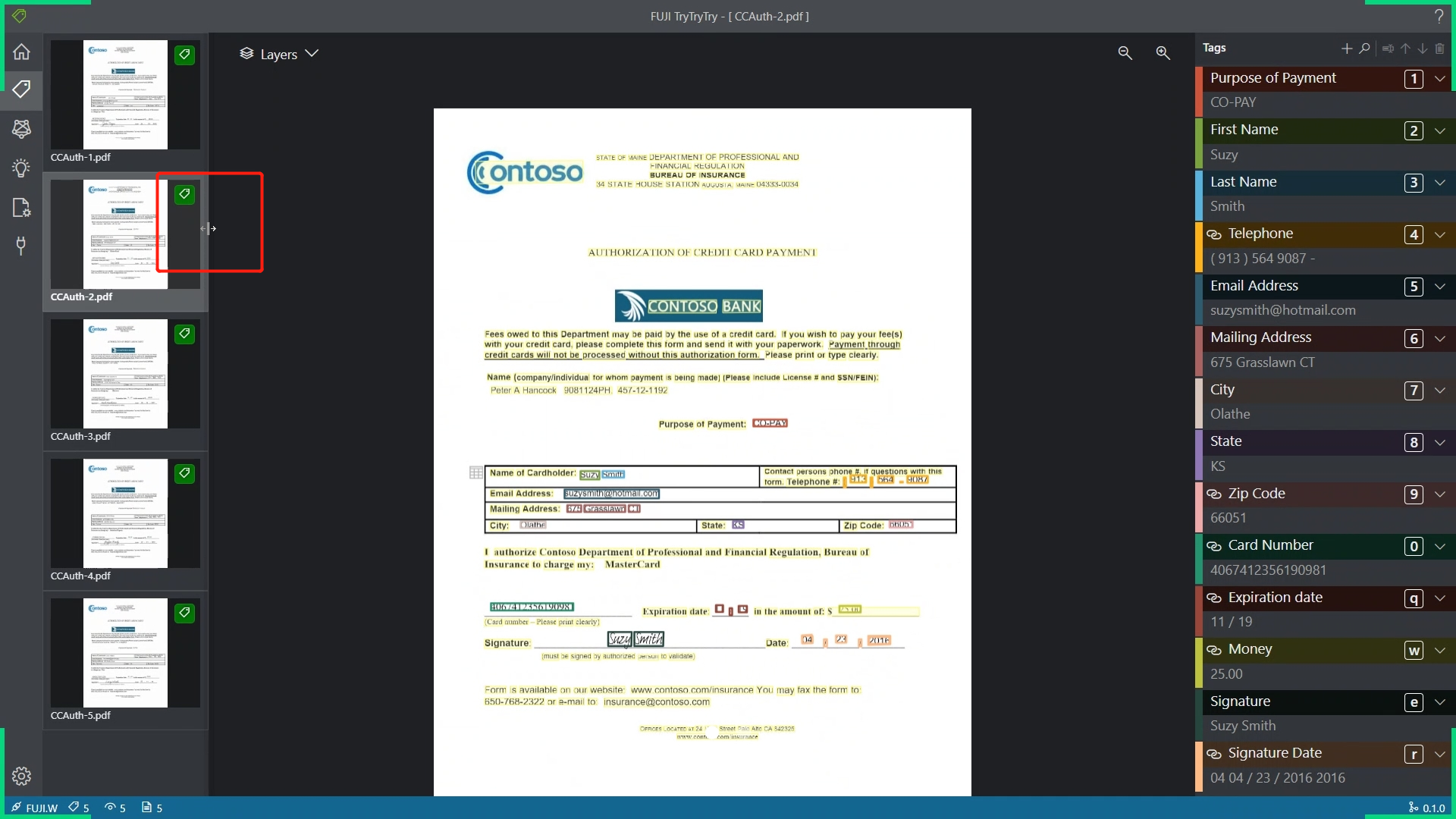
当鼠标放置在边框处,会变成拖拽样式,但是根本无法对边框进行拖拽缩放 -
对于number类型,偶尔出现的重复问题,这个重复似乎是随机的
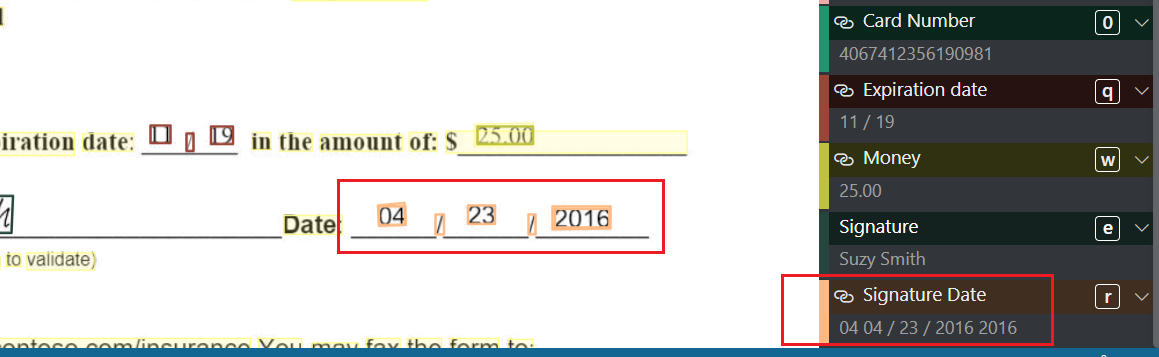
tag标注时,可以看到,日期的部分数字出现了重复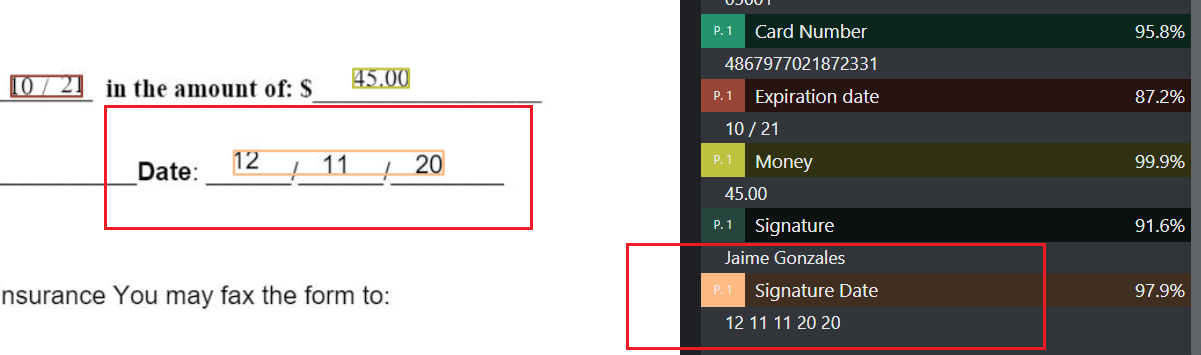
对训练出来的模型进行测试时,日期同样出现了重复
-
-
广义的BUG(如果非得找出几个的话……)
-
逻辑问题:鼠标放在Tag上,会显示出Tag的名字,这……本来就可以看到Tag的名字呀!我认为这里应该显示出更加有用的信息。
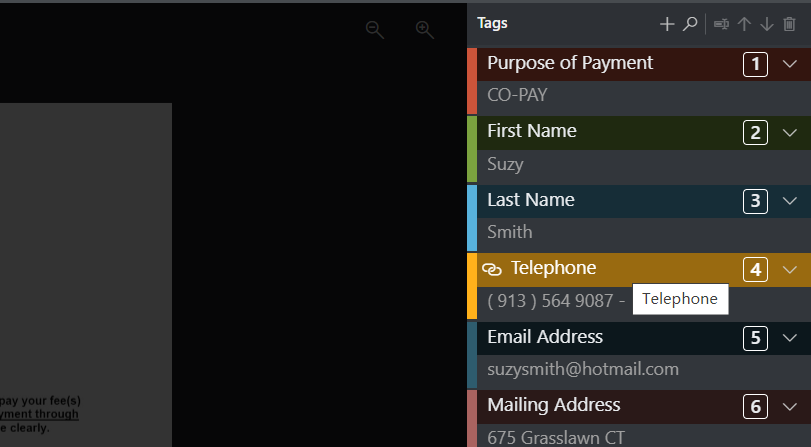
建议这里弹出有用的信息,如Tag的类型等 -
缩放问题:在编辑窗口,鼠标滚轮滚动一下缩放的比例与点击一下缩放按钮缩放的比例不同,前者是后者的3倍。这使得最便捷的鼠标滚轮缩放的跳动太大,变得不是很方便。
-
还是缩放问题:无论我怎么调整,文档都无法刚好填满编辑窗口……(强迫症患者退出直播间)
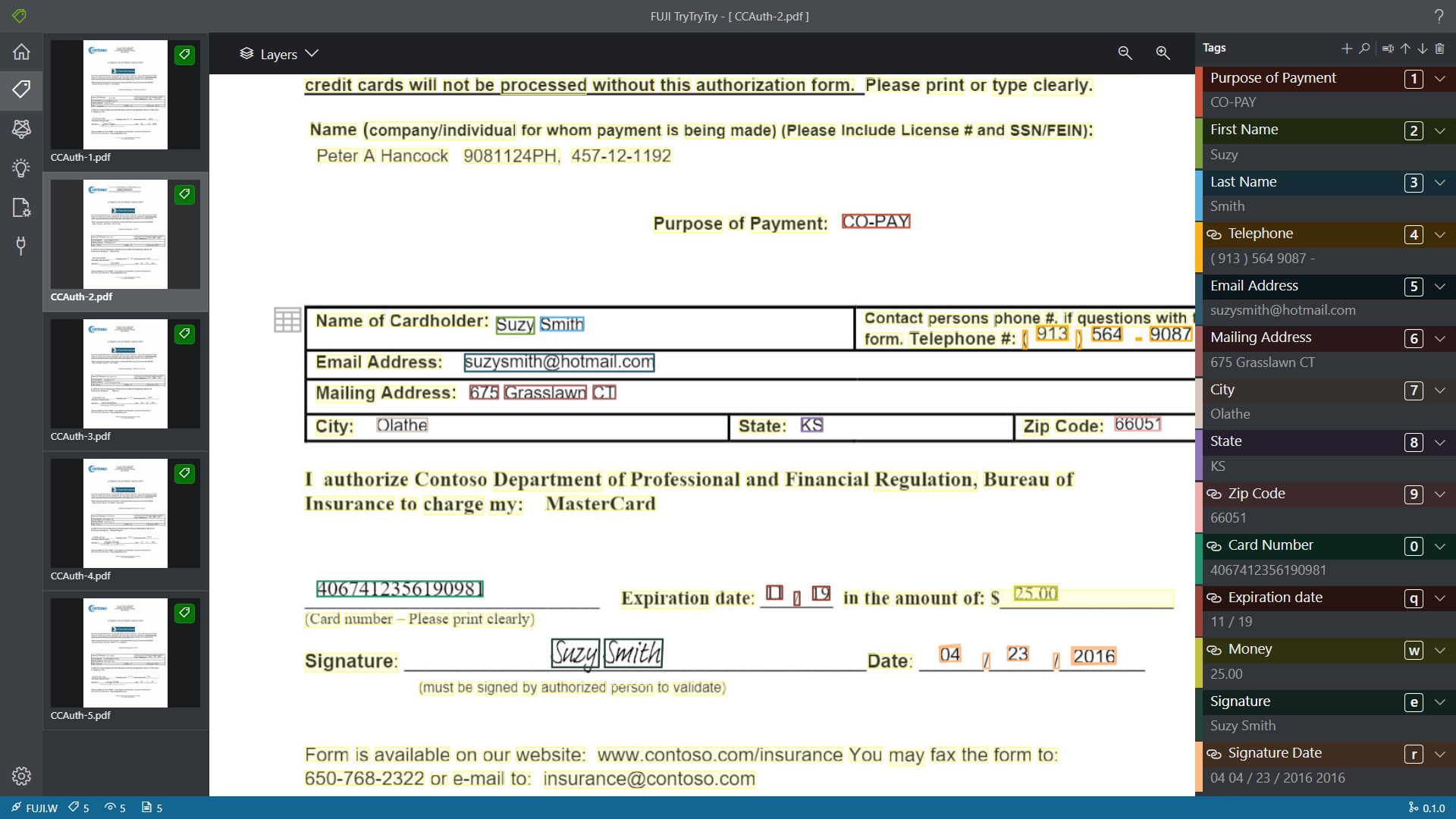
反复试探,都无法完美填满编辑窗口 :(
-
5. 结论(评价与意见)
总的来看,我给这个工具的评价为 “非常推荐”。
分析
1. 开发时间估计
使用此服务的所有功能,估计这个软件/网站/服务做到这个程度大约需要多少时间(团队人数6人左右,计算机专业的大学毕业生,并有专业UI支持)。
将一个项目打磨到现在这么精良,虽然功能专一,但是可以看出整个操作流程的细心考量,我估计需要2个月左右的时间。
2. 宇宙第一OCR?
分析这个软件目前的优劣(和类似软件相比),这个产品的质量在同类产品中估计名列第几?
类似的软件大都是面向企业用户的,如智慧云识-智能表单识别,我无法获得使用权限,所以就拿这个工具与我做笔记时常常用到的天若OCR比较一下:
-
微软OCR部署在网站上,是通过网页进行交互的,而天若OCR有客户端,可以通过快捷键随时呼出,即时地进行识别;
-
微软OCR是开源项目,免费使用;天若OCR的商用是需要收费的,而个人用户要使用表格分列等功能则需要充值VIP;
-
微软OCR目前的功能专一而强大,专注于PDF表单的识别;天若OCR支持更多的格式如图片,但是其识别出来的信息缺乏规范;
天若OCR的表单功能需要充值,日后一定补上 :)
3. 冷静分析.jpg
你在第一部分发现的bug,为何软件团队不能在发布前修复?他们是不知道,还是有意不修复?你觉得是什么原因?
我发现的都是一些小Bug,而且大都属于见仁见智的问题吧,我猜测是因为对该工具的定位不同,作为核心用户为企业而非个人的开源项目,这些小瑕疵是很容易被忽略的。
建议、规划
1. 市场分析
市场有多大?潜在的用户有多少?
每个公司或政府单位都要有财务,都要有各种报表、考勤表等等表格的处理,在大数据时代,将纸质数据信息化已经成了必然趋势。传统的效率低、易出错、成本高的人工数据录入方式必然被时代所淘汰,当各种表格“上网”以后,对于这些表格的进一步处理就成了亟待有效解决的问题。还是那句话,我认为微软表单OCR是当前最好的解决方案之一,市场空间巨大。
2. 用户分析
作为新的项目经理,这个产品的核心用户群是什么样的人,典型用户长什么样?学历,年龄,专业,爱好,收入,表面需求,潜在需求都是什么?
本开源项目的核心用户群应该是公司或事业单位,主要用于商业用途而且个人使用,整个使用逻辑都是为商业使用行方便的,比如项目完全上Azure云(应该也有基于扶持微软自家云服务的考量),个人使用起来是非常麻烦的。那么对于商业用于来说,他们的潜在需求就是更高的性价比了,或许学习成本并不十分重要。
3. 新的功能
功能:你要设计什么样的功能?为何要做这个功能,而不是其他功能?为什么用户会用你的产品/功能?你的创新在哪里?
我认为该开源项目切中了大量表单数据处理的痛点,拥有强大的深度学习内核,如果再拥有更加“傻瓜”的操作逻辑,一定会成为新的爆款应用。
- Excel导出:其实这个功能可以非常简单地实现,毕竟即使将Json格式的数据导入Excel进行人工规范也是非常轻松的。但是如果有直接导出为Excel的功能,我想会让该工具适用更广泛的用户和使用环境,现在的使用门槛还是有一些高的;
- 自动生成Tag:这个其实是“锦上添花”的功能吧,如果添加该功能,必须保证极高的正确性,否则自动生成所节约的时间全部又浪费在Tag的纠正上去了。
写在最后
第一次做一个软件的体验与测评,十分忐忑,写完以后,不禁长舒了一口气……如有(一定有)纰漏,望指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号