利用HtmlAgilityPack第三方包爬取其他网页的资料
1)HtmlAgilityPack介绍
HtmlAgilityPack是一个基于.Net的、第三方免费开源的微型类库,主要用于在服务器端解析html文档(在B/S结构的程序中客户端可以用Javascript、jquery解析html)。
2)安装使用
新建项目后在NgGet中为项目安装HtmlAgilityPack。
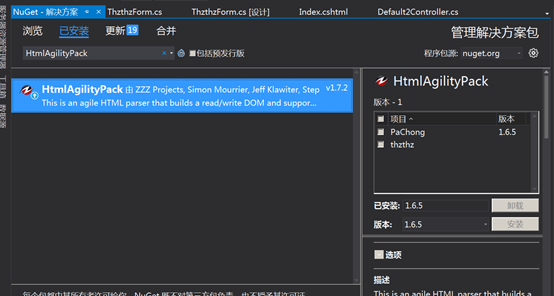
3)开始使用
new一个HtmlWeb和HtmlDocument对象,之后需要使用。
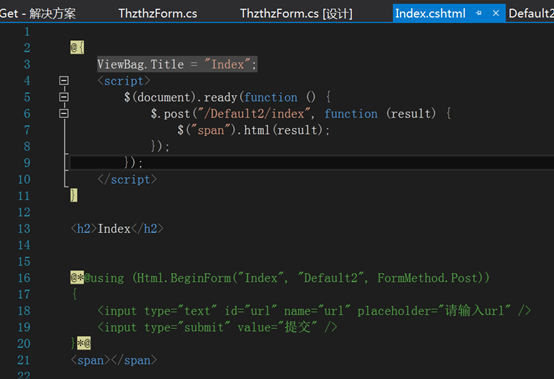
新建index方法,创建视图,用于post提交操作。
Index页面加载完成后异步请求/Default2/index,成功后数据返回到span标签。
新建HttpPost特性的Index方法

doc = webClient.Load("http://www.runoob.com/");把需要解析的网站解析后,放到了HtmlDocument doc对象中
然后根据xpath规则寻找到网页中某些标签。这里是找到标签集合中的前两个a标签。放到了HtmlNodeCollection

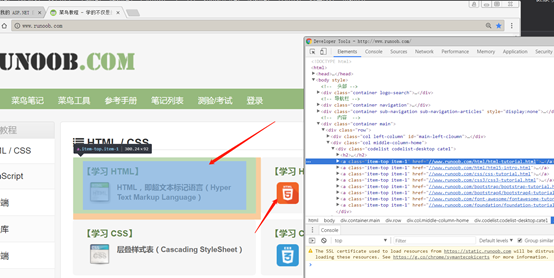
查询出了两条数据。

href.InnerText获取到的数据。
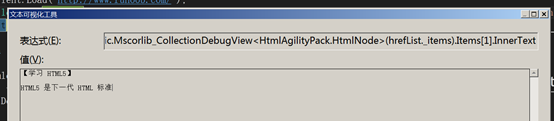
((HtmlAttribute)href.Attributes["href"]).Value可以获取当前标签href属性的值。

对输出的标签进行组装。
然后对当前标签内的详细页面进行详细页面的数据获取。

新建GetDetailed方法
同理取得了详细页面后,分许页面,根据xpath规则寻找到网页中某些标签,这里得到了四行文字,循环叠加到htmldom字符串中。然后返回。
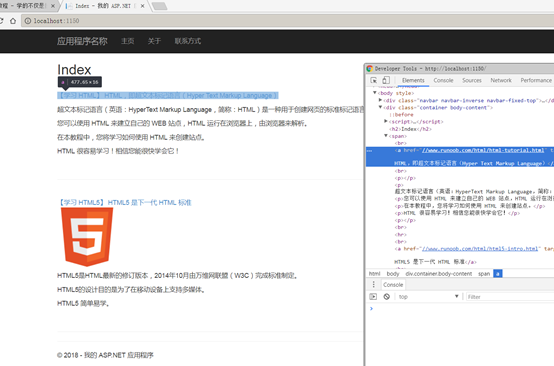
运行程序,稍等片刻后即可获得数据,自动添加到页面。
代码:
namespace PaChong.Controllers
{
public class Default2Controller : Controller
{
HtmlWeb webClient = new HtmlWeb();
HtmlDocument doc = new HtmlDocument();
string htmldom = "";
// GET: Default1
public ActionResult Index()
{
return View();
}
[HttpPost]
public ActionResult Index(string url)
{
//HtmlNode.ElementsFlags.Remove("form"); //执行时删除某些标签
//HtmlNode.ElementsFlags.Remove("option");
//HtmlNode.ElementsFlags.Remove("table");
doc = webClient.Load("http://www.runoob.com/");
HtmlNodeCollection hrefList = doc.DocumentNode.SelectNodes(".//html/body/div[4]/div[1]/div[2]/div[1]/a[@href][position()<3]");
if (hrefList != null)
{
foreach (HtmlNode href in hrefList)
{
htmldom += "<br><a href = '" + ((HtmlAttribute)href.Attributes["href"]).Value
+ "' target = '_blank'>" + href.InnerText + "</a>" + "<br>";
GetDetailed("http:" + ((HtmlAttribute)href.Attributes["href"]).Value);
}
}
return Content(htmldom);
}
private void GetDetailed(string url)
{
doc = webClient.Load(url);
HtmlNodeCollection pList = doc.DocumentNode.SelectNodes(".//html/body/div[3]/div[1]/div[2]/div[1]/div[3]/div[1]/div[1]");//.//html/body/div[3]/div[1]/div[2]/div[1]/div[2]/div[1]/div[1]
foreach (HtmlNode text in pList)
{
htmldom += "<p>" + text.InnerHtml + "</p><br />";
}
htmldom += "<hr />";
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号