Prometheus+grafana配置及监控示例
安装配置prometheus和grafana
Prometheus安装
wget https://github.com/prometheus/prometheus/releases/download/v1.6.2/prometheus-2.3.2.linux-amd64.tar.gz tar zxvf prometheus-2.3.2.linux-amd64.tar.gz cd prometheus-2.3.2.linux-amd64 ./prometheus --version #查看版本 ./prometheus #启动
node-exporter安装
wget https://github.com/prometheus/node_exporter/releases/download/v0.14.0/node_exporter-0.16.0.linux-amd64.tar.gz tar -xvf node_exporter-0.16.0.linux-amd64.tar.gz 后台运行 ./node_exporter &
grafana安装
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.2.2.linux-amd64.tar.gz tar -zxvf grafana-5.2.2.linux-amd64.tar.gz
//启动
${GRAFANA_HOME}/bin/grafana-server start
端口3000 默认密码 admin/admin
配置prometheus监控node
修改prometheus.yml 添加如下信息
- job_name: 'expoter' static_configs: - targets: ['10.10.10.12:9100'] labels: instance: expoter
修改完以后要重启prometheus
设置prometheus连接grafana
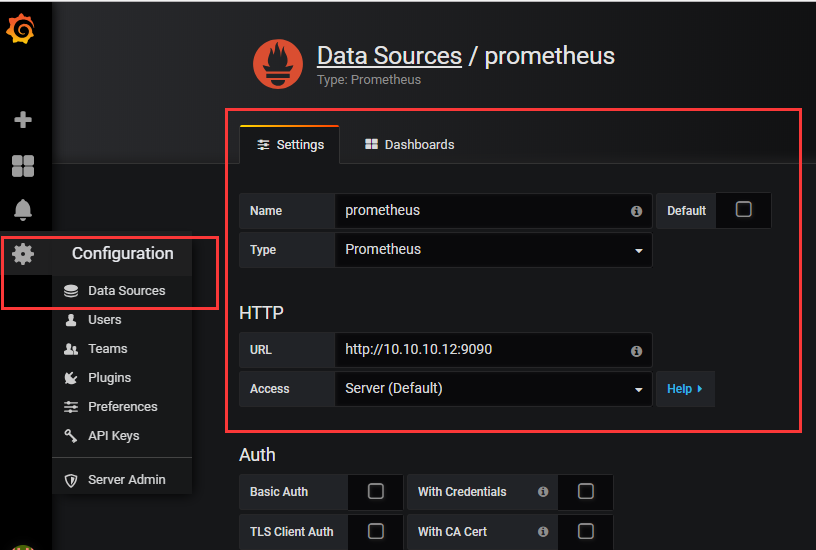
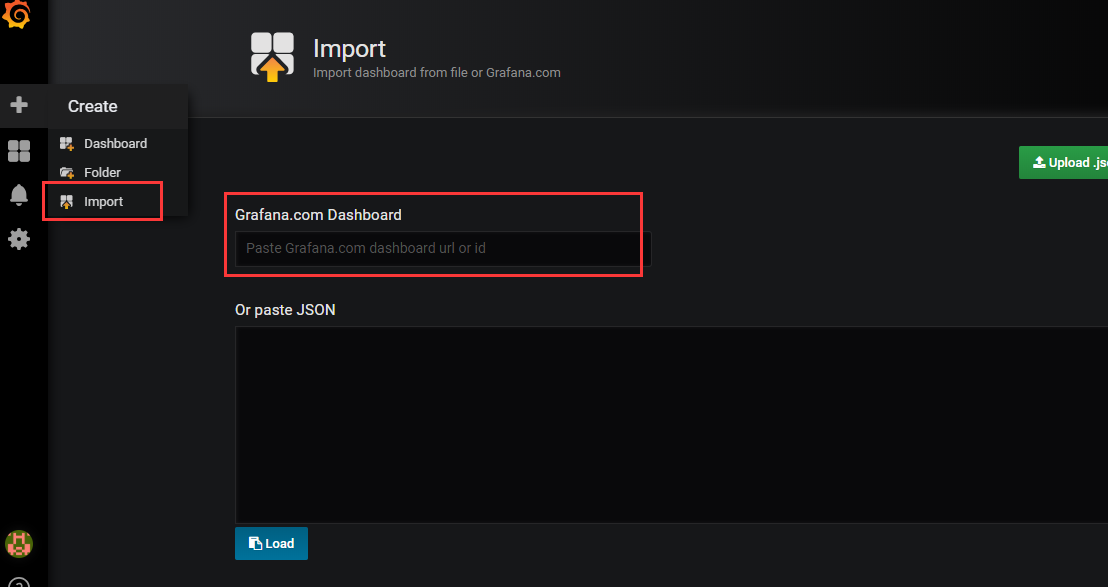
导入仪表盘json模板
从官网获取dashboards id或者json文件内容,在dasshboard 里import菜单导入即可
获取id或者json文件内容
https://grafana.com/dashboards/

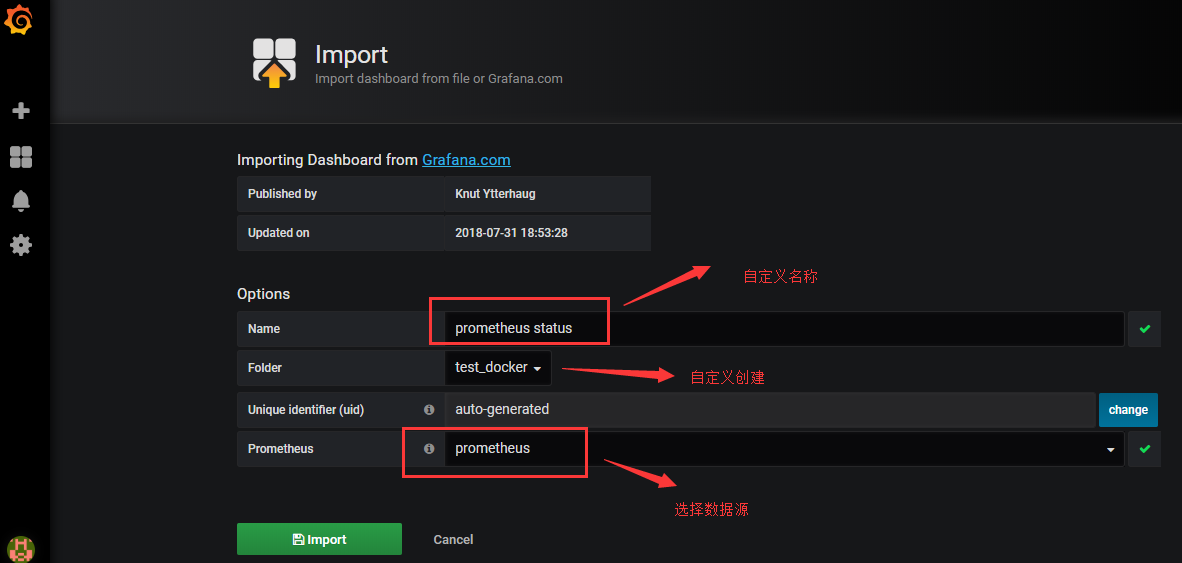
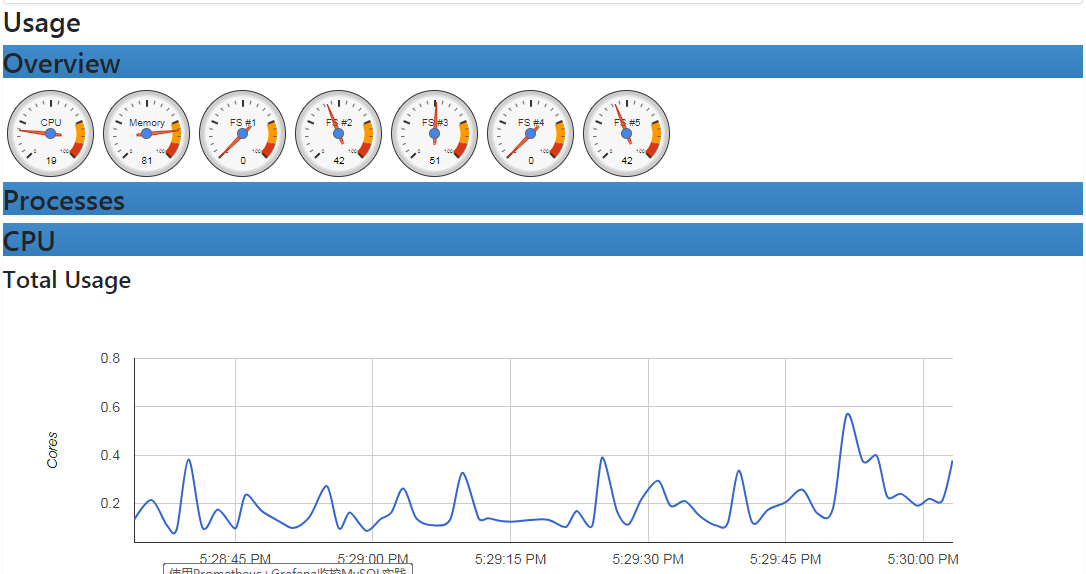
配置好以后如图所示
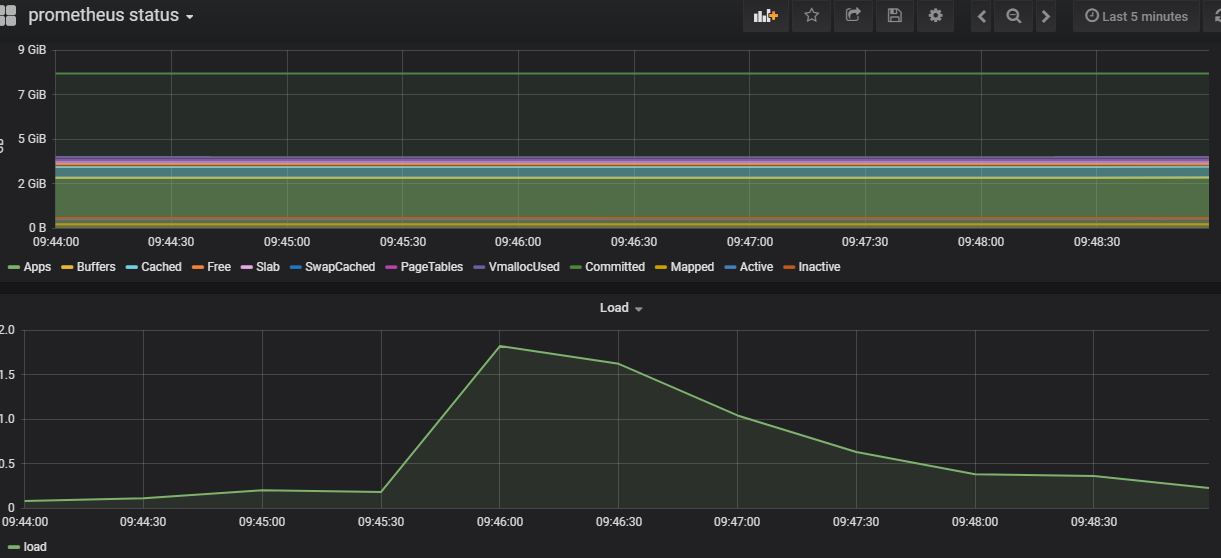
实例之监控docker
Prometheus支持深度监控Docker容器的资源和运行特性,多维度查询,聚合Docker监控数据
在 Prometheus 中负责数据汇报的程序统一叫做 Exporter, 而不同的 Exporter 负责不同的业务。 它们具有统一命名格式,即 xx_exporter, 例如负责主机信息收集的 node_exporter。Prometheus 社区已经提供了很多 exporter,地址为:https://prometheus.io/docs/instrumenting/exporters/,并且通过浏览器可以获取 目标机器的指标(mertics)信息(http://x.x.x.x:port/mertics)
同样,监控docker contianer的exporter也可以从这里查找,通常使用cAdvisor,并以容器的方式启动。
从官方提供的exporter中设置exporter并启动(注意端口别冲突)
//地址(从官网跳转得到) https://github.com/google/cadvisor sudo docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:ro \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ google/cadvisor:latest
注:由于最新版的cAdvisor存在bug,启动的时候会报如下错误
1 cadvisor.go:156] Failed to start container manager: inotify_add_watch /sys/fs/cgroup/cpuacct,cpu: no such file or directory
解决办法
ount -o remount,rw /sys/fs/cgroup/;ln -sf /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
启动以后,访问宿主机的8080端口
获取容器的指标信息(http://ip:8080/mertics)

配置prometheus监控容器信息
修改prometheus.yml,添加如下信息
- job_name: 'cadvisor-container' static_configs: - targets: ['ip:8080'] #这里就写上面cAdvisor的地址 labels: instance: cadvisor-container
配置完以后重启prometheus,打开prometheus web界面
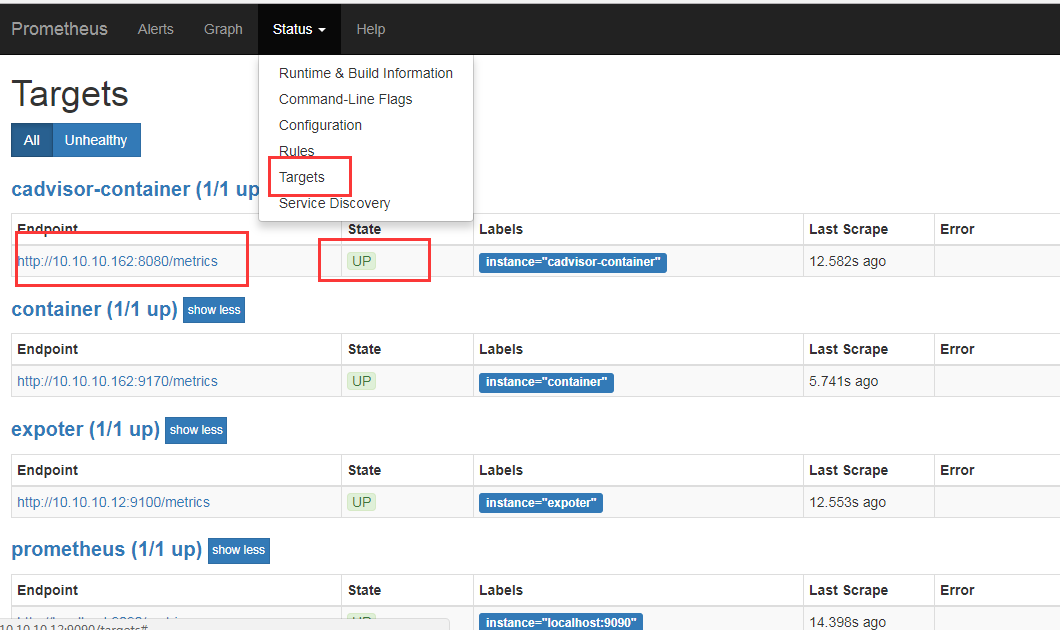
设置grafana显示图像信息
首先导入Docker Container dashboard 模板(官网搜索)
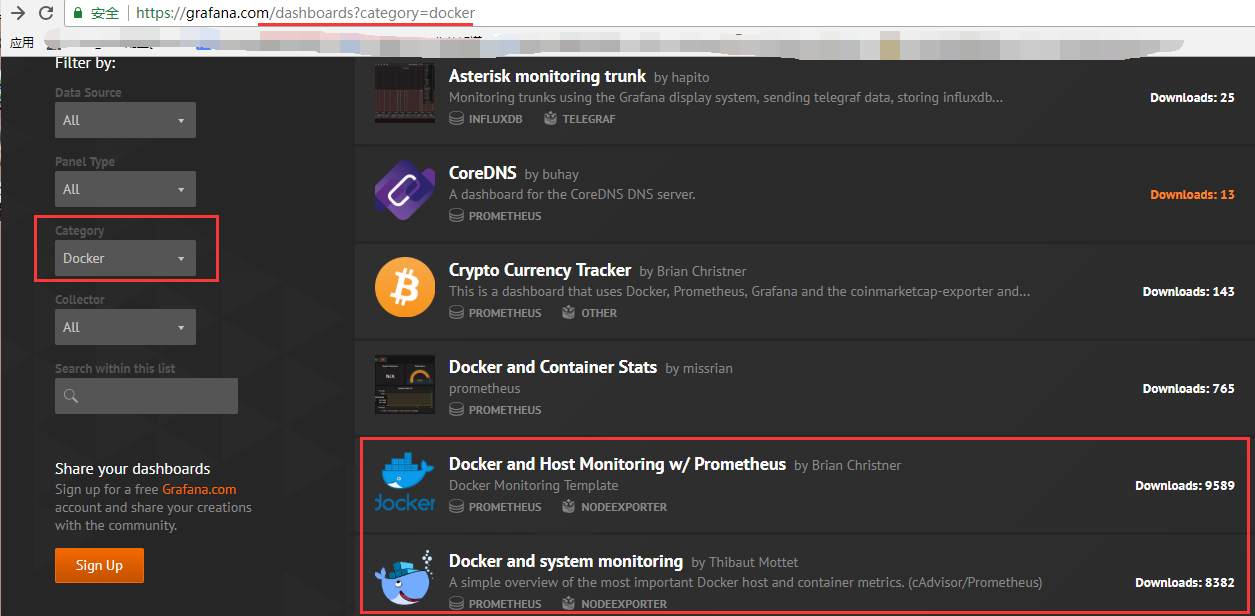
导入以后如果无法获取数据,需要从新设置一下数据源,随便点开一个监控项
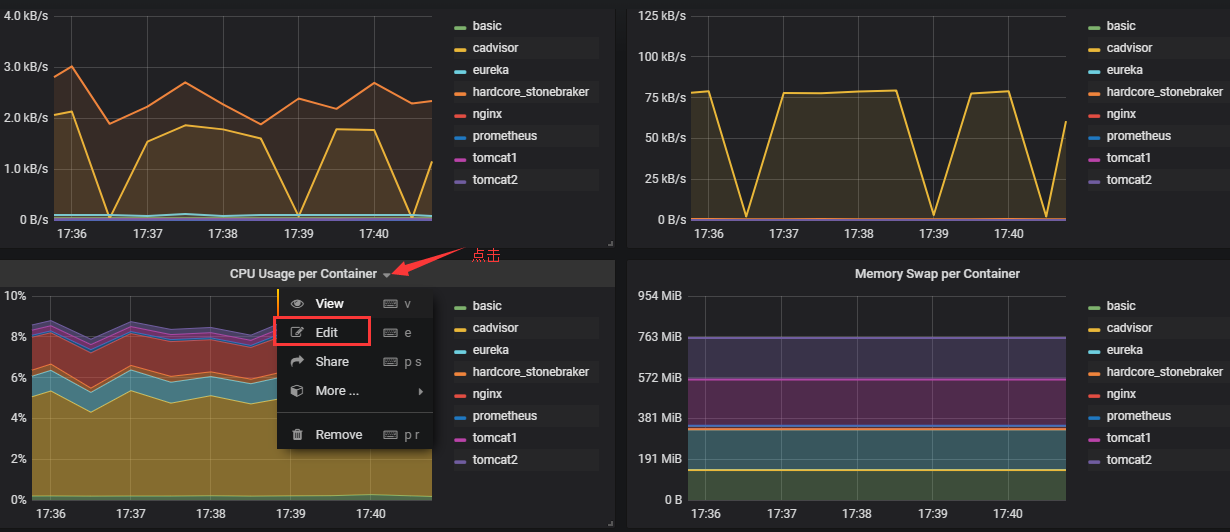
画框中选择数据源返回即可
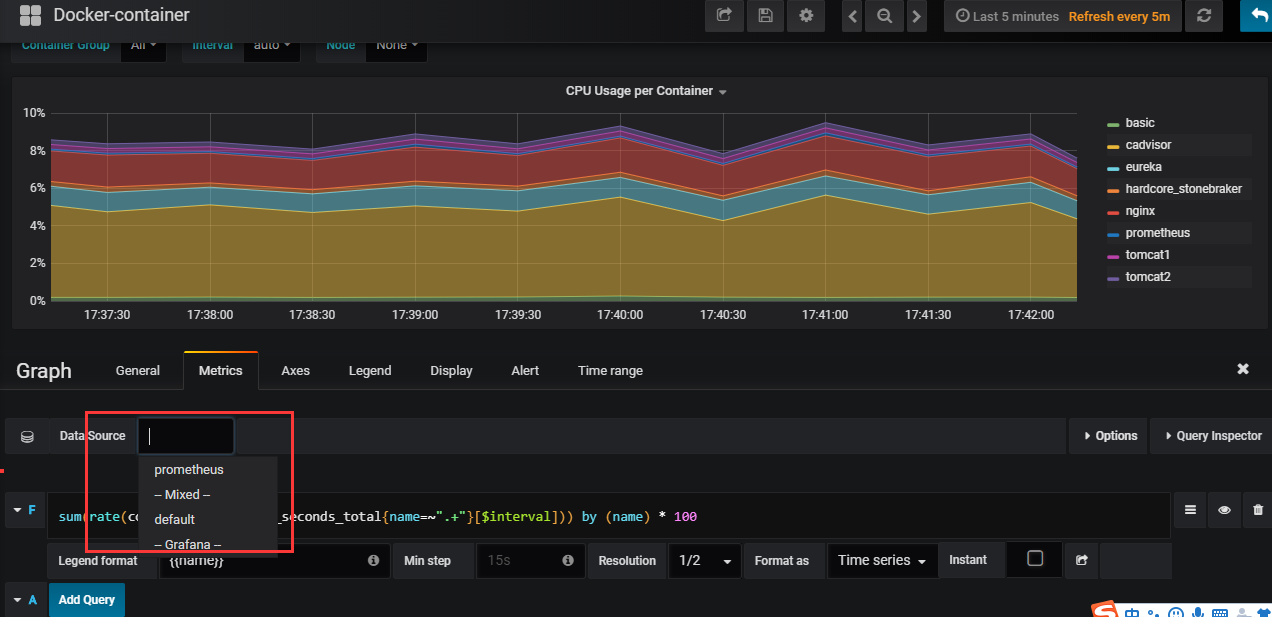
默认会显示一周的数据,自定义设置时间即可
实例之监控elasticsearch并定义报警规则
prometheus监控es,需要使用对应版本的监控插件(exporter),我使用的是elasticsearch版本5.5.2,github下载对应版本的插件
https://github.com/vvanholl/elasticsearch-prometheus-exporter/releases
安装监控插件
#安装
sh ${elasticsearch_HOME}/bin/elasticsearch-plugin install file:///opt/elasticsearch-prometheus-exporter-5.5.2.0.zip
#安装完成重启es(非root用户)后访问下面地址:
http://es_ip:9200/_prometheus/metrics,看到监控指标如下,说明安装成功

通过prometheus监控es,配置文件如下
[root@master conf]# cat conf/prometheus.yml |grep -v "^#\|^$" global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 #alertmansger的ip及端口 rule_files: #如果没有规则时可以不用指定 - "rules/*" #自定义conf目录下的rules目录存放报警规则,与prometheus同级目录 scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['xxxx:9090'] - job_name: elasticsearch scrape_interval: 10s metrics_path: "/_prometheus/metrics" file_sd_configs: - files: - es.yml #这里 表示引用文件 [root@master conf]# cat conf/es.yml |grep -v "^#\|^$" - targets: - 192.168.177.142:9200 - 192.168.177.134:9200 - 192.168.177.206:9200 labels: server: dev-es - targets: - 192.168.177.11:9200 - 192.168.177.208:9200 - 192.168.177.226:9200 - 192.168.177.236:9200 - 192.168.177.237:9200 labels: server: test-es - targets: - 172.21.0.22:9200 - 172.21.0.42:9200 - 172.21.0.19:9200 labels: server: pre-es
启动时要指定配置文件
#启动之前先检查一下配置文件是否正确
./promtool check config conf/prometheus.yml
#启动 ./prometheus --config.file=/opt/prometheus-2.5.0.linux-amd64/conf/prometheus.yml
查看prometheus

然后去grafana配置,首先去grafana官网去找es的dashboard模板,266,导入模板,完成后监控如下所示:

配置报警规则
根据prometheus监控ElasticSearch指标进行相应的监控
报警规则编写
打开prometheus,ip:9090, Esecute下拉框里会显示es监控相关的查询语句的索引,如下图所示
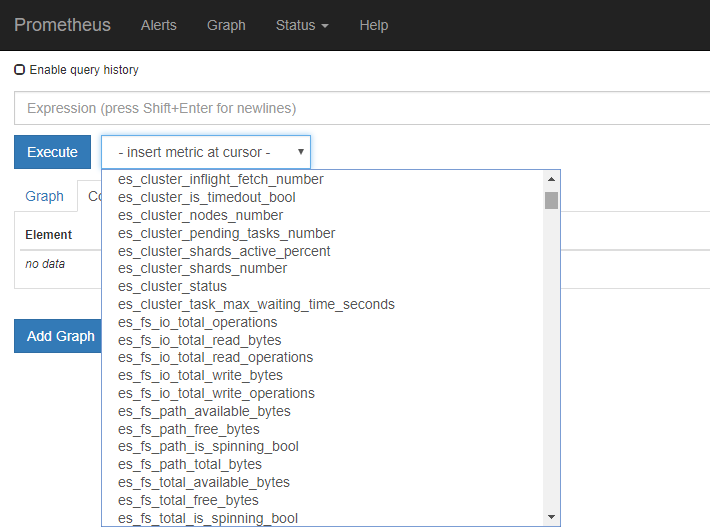
选中一个进行查询,例如,查询cpu的使用率,查看grafana里的查询语句
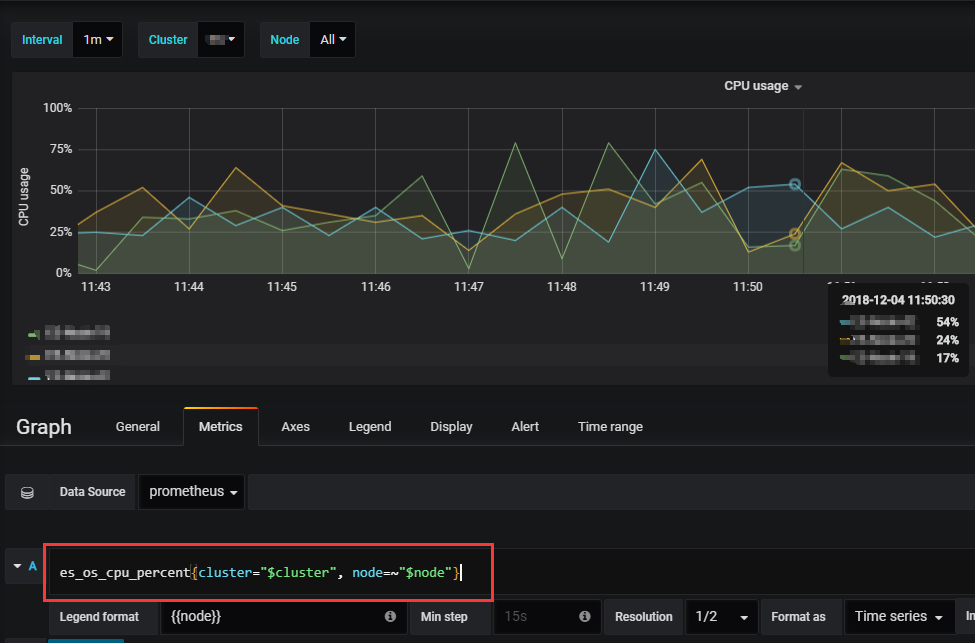
然后在prometheus进行查询
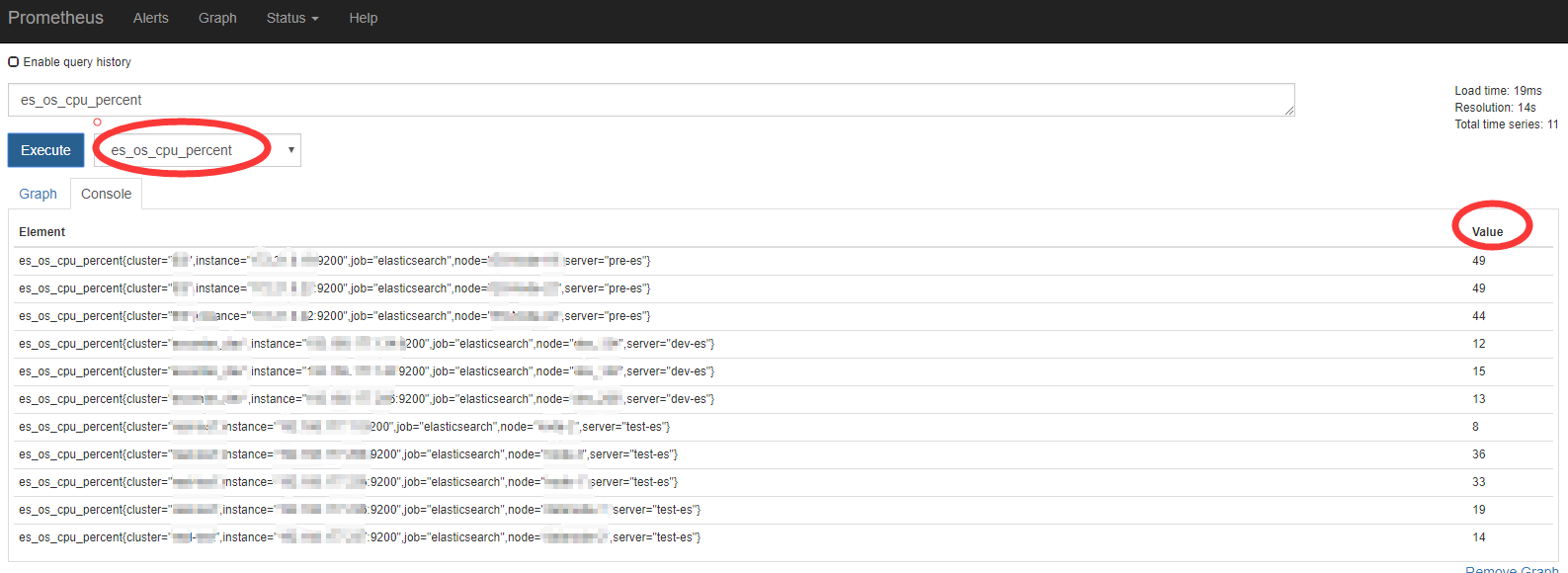
此时可写报警规则如下
- alert: EsCpuUsed expr: es_os_cpu_percent > 80 for: 5m labels: severity: warning annotations: description: "elasticsearch in {{$labels.server}}-{{$labels.node}} cpu used is above 80% current {{$value}}%" #这里为自定义报警信息,{{$labels.server}}server 为lables里的键
例如查询JVM Heap堆栈使用率,Element可以理解为查询语句,value为查询到的值,percent代表百分比

然后看一下grafan里JVM HEAP监控里如何定义的,


这里只是记录了jvm Heap使用的内存大小,es_jvm_mem_heap_max_bytes为设定的jvm的大小,进而可以手动查出堆栈使用率,如下所示

所以rules里定义规则就可以写成
- alert: EsJvmHeapMemUsed expr: es_jvm_mem_heap_used_percent > 75 #大于百分之75就报警 for: 10m labels: severity: warnning annotations: description: "elasticsearch node {{$labels.node}} Jvm Heap mem used is above 75% current {{$value}}%" #描述,自定义,{{$label.node}}表示在element里出的标签(label)和相应的键(node)
在例如下所示,监控cluster状态有三个颜色,三个值:
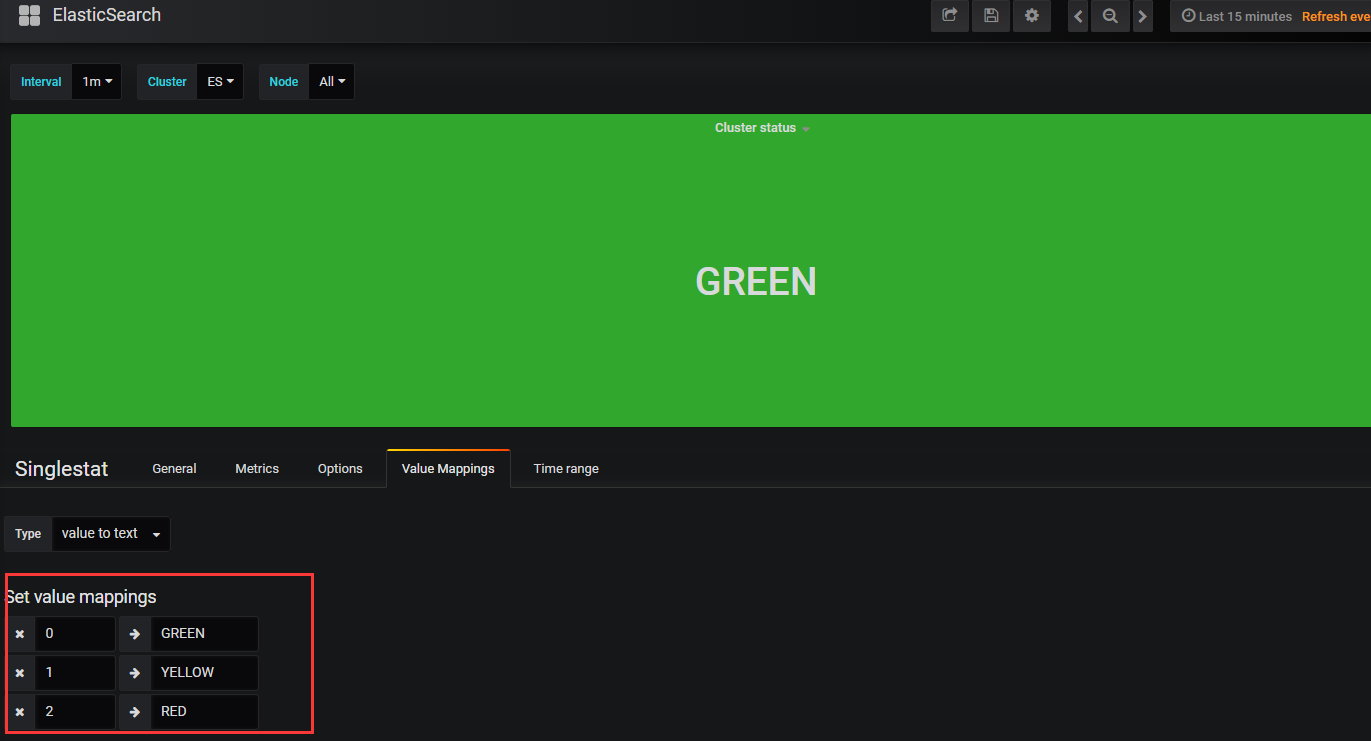
根据监控指标可知集群状态,green( 所有的主分片和副本分片都正常运行)、yellow(所有的主分片都正常运行,但不是所有的副本分片都正常运行)red(有主分片没能正常运行)
所以规则可写成如下(值不为0的都视为有问题):
- alert: esclusterwrong expr: es_cluster_status != 0 for: 5m labels: severity: critical annotations: description: "elasticsearch cluster {{$labels.server}} had primary shared not normal runningworking"
整体规则如下
[root@master rules]# cat conf/rules/es.yml groups: - name: es.rules rules: - alert: esclusterwrong expr: es_cluster_status != 0 for: 5m labels: severity: critical annotations: description: "elasticsearch cluster {{$labels.server}} had primary shared not normal runningworking" - alert: esDown expr: up{job="elasticsearch"} == 0 for: 5m labels: severity: critical annotations: description: "elasticsearch service {{$labels.instance}} down" - alert: EsUnassignedTotal expr: es_cluster_shards_number{type="unassigned"} > 0 for: 5m labels: severity: critical annotations: description: "elasticsearch cluster {{$labels.server}} had shares lost" - alert: EsCpuUsed expr: es_os_cpu_percent > 80 for: 5m labels: severity: warning annotations: description: "elasticsearch in {{$labels.server}}-{{$labels.node}} cpu used is above 80% current {{$value}}%" - alert: EsJvmHeapMemUsed expr: es_jvm_mem_heap_used_percent > 75 for: 10m labels: severity: warnning annotations: description: "elasticsearch node {{$labels.node}} Jvm Heap mem used is above 75% current {{$value}}%" - alert: EsDiskUsed expr: ceil((1 - es_fs_path_available_bytes / es_fs_path_total_bytes) * 100 ) > 90 for: 5m labels: severity: warnning annotations: description: "{{$labels.node}} elasticsearch DiskUsage Used is above 90% current {{$value}}%"
此时可以再prometheus界面查看报警和rules
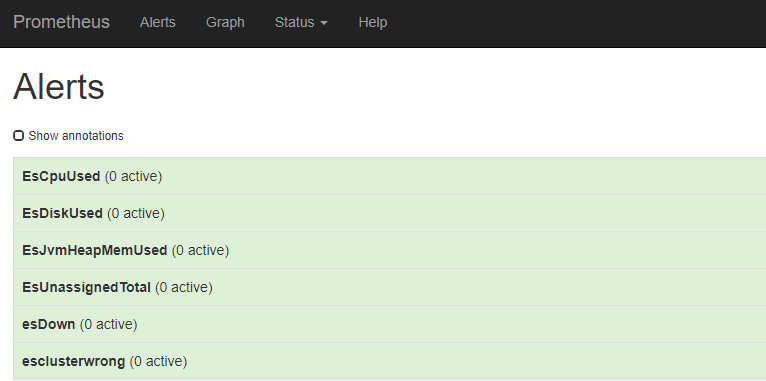
AlertManager报警
-
安装alertmanager
Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组,策略路由,是一款前卫的告警通知系统。
#安装go 1.11 $ wget https://studygolang.com/dl/golang/go1.11.linux-amd64.tar.gz $ tar zxvf go1.11.linux-amd64.tar.gz && mv go1.11 /opt/go $ vi /etc/profile 添加 export GOROOT=/opt/go export PATH=$GOROOT/bin:$PATH export GOPATH=/opt/go-project export PATH=$PATH:$GOPATH/bin $ source /etc/profile $ go version #安装alertmanager $ git clone https://github.com/prometheus/alertmanager.git $ cd alertmanager/ $ make build 安装成功以后,便可编辑报警配置文件了
基本配置模板:
global: resolve_timeout: 2h route: group_by: ['alertname'] group_wait: 5s group_interval: 10s repeat_interval: 1h receiver: 'webhook' receivers: - name: 'webhook' webhook_configs: #通过webhook报警 - url: 'http://example.com/xxxx' send_resolved: true
启动alertmanager时需要指定配置文件
./alertmanager --config.file=/opt/prometheus-2.5.0.linux-amd64/conf/alertmanager.yml #这个文件是自己自定义的,位置随便放
-
通过email报警
修改alertmanager配置文件
global: smtp_smarthost: 'smtp.qq.com:587' smtp_from: 'xxx@qq.com' smtp_auth_username: 'xxx@qq.com' smtp_auth_password: 'your_email_password' route: # 重复报警时间,默认10秒 repeat_interval: 10s # 接收者 receiver: team-X-mails receivers: - name: 'team-X-mails' #与上面receiver对应 email_configs: - to: 'team-X+alerts@example.org'
在prometheus指定好报警规则后启动alertmanger即可
-
企业微信告警
②、访问app创建应用(自建应用)
③、alertmanager.yml配置
route:
group_by: ['alertname']
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'xxx' #企业微信账号唯一 ID, 可以在我的企业中查看。
to_party: '1' #需要发送的组。
agent_id: '1000002' #第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看。
api_secret: 'xxxx' #第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号