scrapy基础二
应对反爬虫机制
①、禁止cookie :有的网站会通过用户的cookie信息对用户进行识别和分析,此时可以通过禁用本地cookies信息让对方网站无法识别我们的会话信息
settings.py里开启禁用cookie
# Disable cookies (enabled by default) COOKIES_ENABLED = False
②、设置下载延时:有的网站会对网页的访问频率进行分析,如果爬取过快,会被判断为自动爬取行为
settings.py里设置下载延时
#DOWNLOAD_DELAY = 3 #去掉注释,3代表3秒
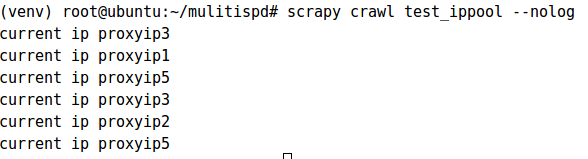
③、使用ip池: 有的网站会对用户的ip进行判断,所以需要多个ip地址。这些地址组成一个ip池,爬虫每次爬取会从ip池中随机选择一个ip,此时可以为爬虫项目建立一个中间件文件,定义ip使用规则
#1、创建项目略过 #2、settings.py 设置代理ip地址池 IPPOOL=[ {"ipaddr":"proxyip1"}, {"ipaddr":"proxyip2"}, {"ipaddr":"proxyip3"}, {"ipaddr":"proxyip4"}, {"ipaddr":"proxyip5"}, {"ipaddr":"proxyip6"}, {"ipaddr":"proxyip7"} ] #3、创建一个中间件文件 middle_download_wares.py #-*-coding:utf-8-*- import random from mulitispd.settings import IPPOOL from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware class IPPOOLS(HttpProxyMiddleware): def __init__(self,ip=''): self.ip = ip def process_request(self, request, spider): thisip = random.choice(IPPOOL) print ("current ip "+thisip["ipaddr"]) request.meta['proxy'] = "http://"+thisip['ipaddr'] #4设置settings.py注册为项目中间件,格式:中间件所在目录.中间件文件名.中间件内部要使用的类 DOWNLOADER_MIDDLEWARES = { #'mulitispd.middlewares.MulitispdDownloaderMiddleware': 543, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':123, 'mulitispd.middle_download_wares.IPPOOLS':125 }
测试结果:
④、使用用户代理池: User-Agent变换使用,方法流程与使用ippool方法一样
#1、设置settings.py 里User-agent UAPOOL=[ "MOzilla/5.0 ...", "Chrom/49.0.2623.22 ....." ] #2、新建中间件文件 #-*-coding:utf-8-*- import random from mulitispd.settings import UAPOOL from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware class UAPOOLS(UserAgentMiddleware): def __init__(self,useragent=''): self.useragent = useragent def process_request(self, request, spider): thisua = random.choice(UAPOOL) print ("current useragent "+thisua) request.headers.setdefault("User-Agent",thisua) #3、settings.py注册中间件 DOWNLOADER_MIDDLEWARES = { #'mulitispd.middlewares.MulitispdDownloaderMiddleware': 543, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':123, 'mulitispd.middle_download_wares.IPPOOLS':125, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':2, 'mulitispd.middle_useragent_wares.UAPOOLS':1 }
Scrapy核心架构
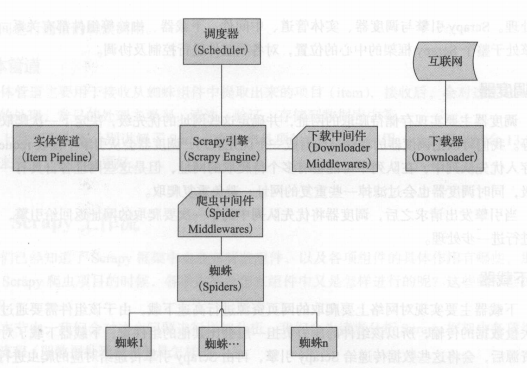
说明:





工作流
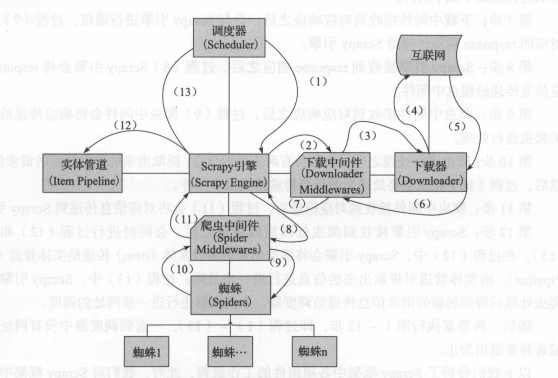


总结:

简单示例
爬取网页内容爬虫(爬取当当网特产)
创建项目及爬虫文件
scrapy startproject autopro
scrapy genspider -t basic autospd dangdang.com
编写items.py
import scrapy class AutoproItem(scrapy.Item): name = scrapy.Field() #商品名称 price = scrapy.Field() #商品价格 link = scrapy.Field() #商品链接 comnum = scrapy.Field() #商品评论数量
编写爬虫文件autospd.py
# -*- coding: utf-8 -*- import scrapy from autopro.items import AutoproItem from scrapy.http import Request class AutospdSpider(scrapy.Spider): name = 'autospd' allowed_domains = ['dangdang.com'] start_urls = ['http://dangdang.com/'] def parse(self, response): item = AutoproItem() item['name'] = response.xpath("//a[@class='pic']/@title").extract() #xpath分析结果,@title表示获取titile属性的值 item['price'] =response.xpath("//span[@class='price_n']/text()").extract() item['link'] = response.xpath("//a[@class='pic']/@href").extract() item['comnum'] = response.xpath("//a[@dd_name='单品评论']/text()").extract() yield item for i in range(1,10): url="http://category.dangdang.com/pg"+str(i)+"-cid4011029.html" yield Request(url,callback=self.parse)
编写pipelines.py
import codecs #导入codecs模块直接进行解码 import json class AutoproPipeline(object): def __init__(self): self.file = codecs.open("/root/mydata.json",'wb',encoding="utf-8") #表示将爬取结果写到json文件里 def process_item(self, item, spider): #process_item为pipelines中的主要处理方法,默认会自动调用 for i in range(0,len(item["name"])): name = item['name'][i] price = item['price'][i] comnum = item['comnum'][i] link = item['link'][i] goods = {"name":name,"price":price,"comnum":comnum,"link":link} i = json.dumps(dict(goods),ensure_ascii=False) line = i+'\n' self.file.write(line) return item def close_spider(self,spider): self.file.close()
设置settings.py
ROBOTSTXT_OBEY = False #表示不遵循robots协议 COOKIES_ENABLED = False #禁止cookie
#开启pipelines ITEM_PIPELINES = { 'autopro.pipelines.AutoproPipeline': 300, }
结果:

CrawlSpider
crawlspider是scrapy框架自带爬取网页的爬虫,可以实现网页的自动爬取
创建crawlspider 爬虫文件
crapy genspider -t crawl test_crawl jd.com
test_crawl.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class TestCrawlSpider(CrawlSpider): name = 'test_crawl' allowed_domains = ['jd.com'] start_urls = ['http://jd.com/'] #链接提取器 ,allow 为自定义设置的爬行规则,follow表示跟进爬取。即发现新的链接继续爬行,allow_domains表示允许爬行的连接 rules = ( Rule(LinkExtractor(allow=r'Items/'),allow_domains=(aa.com) callback='parse_item', follow=True), ) def parse_item(self, response): i = {} #i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract() #i['name'] = response.xpath('//div[@id="name"]').extract() #i['description'] = response.xpath('//div[@id="description"]').extract() return i
