hadoop 集群搭建
master 192.168.132.131
slave3 192.168.132.141
slave2 192.168.132.144
slave3 192.168.132.142
master和node节点都要添加到/etc/hosts
192.168.132.144 slave2 192.168.132.131 master 192.168.132.142 slave1 192.168.132.141 slave3
一、配置ssh无秘钥登录
ssh-keygen -t rsa -P '' #关闭防火墙:(centos7) systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动
二、java1.8 安装
环境变量设置
cat /etc/proifile export HADOOP_HOME=/usr/local/hadoop (hadoop 环境变量) export PATH=$PATH:$HADOOP_HOME/bin export JAVA_HOME=/usr/local/java/jdk1.8.0_131/ export JRE_HOME=/usr/local/java/jdk1.8.0_131/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
三 、安装hadoop 2.8.1
解压,放到/usr/local/hadoop目录,配置文件目录
cd /usr/local/hadoop/etc/hadoop mkdir /usr/local/hadoop/{hdfs,tmp} mkdir /usr/local/hadoop/hdfs/{name,tmp,data}
四、配置文件(master服务器)
core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<final>true</final>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.132.131:9000</value> ##master ip
<final>true</final>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
配置hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>2</value> #数据备份的个数
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value> #namenode持久存储名字的额空间、事物日志路径
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value> #datanode数据存储路径
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.132.131:9001</value> #master ip
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
配置mapred-site.xml文件
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.132.131:9001</value> #master ip
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置yarn-site.xml文件
<property> <name>yarn.resourcemanager.address</name> <value>192.168.132.131:18040</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.132.131:18030</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>192.168.132.131:18088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.132.131:18025</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>192.168.132.131:18141</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
配置master文件

配置slaves文件(master节点独有)

五、配置所有slave节点
将master节点的hadoop 以上配置的文件拷贝过去即可(不包括slaves文件)
六、启动服务(master节点)
hadoop namenode –format
启动 /关闭 hadoop ,/usr/local/hadoop/sbin 目录下

start-all.sh //此命令会启动集群所有节点
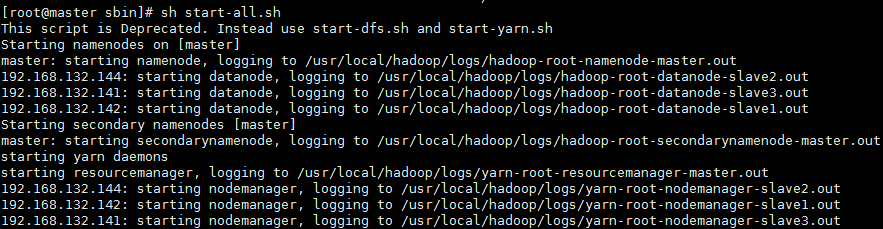
stop-all.sh //此命令会启动集群所有节点
启动单个节点命令,单个namenode,datanode,ResourceManager ,nodemanager的命令
hadoop namenode -format hadoop-daemon.sh start namenode hadoop-daemons.sh start datanode yarn-daemon.sh start resourcemanager yarn-daemons.sh start nodemanager
测试:
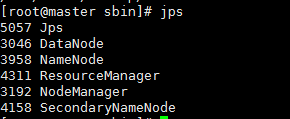
master节点
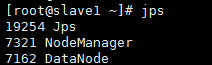
slave节点
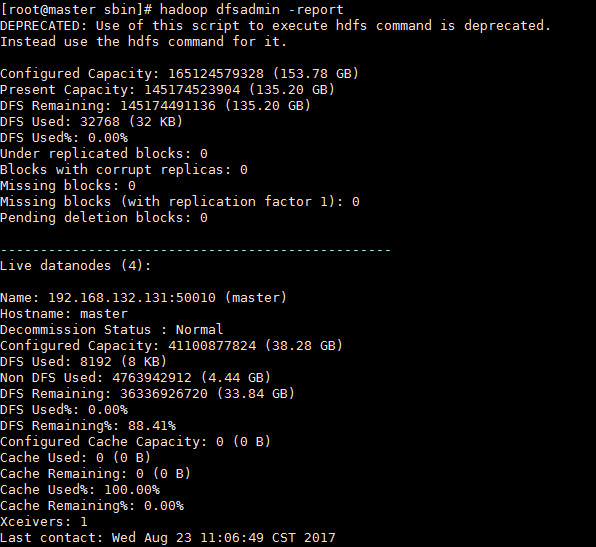
查看集群状态: hadoop dfsadmin -report
通过网页查看集群 masterip:50070
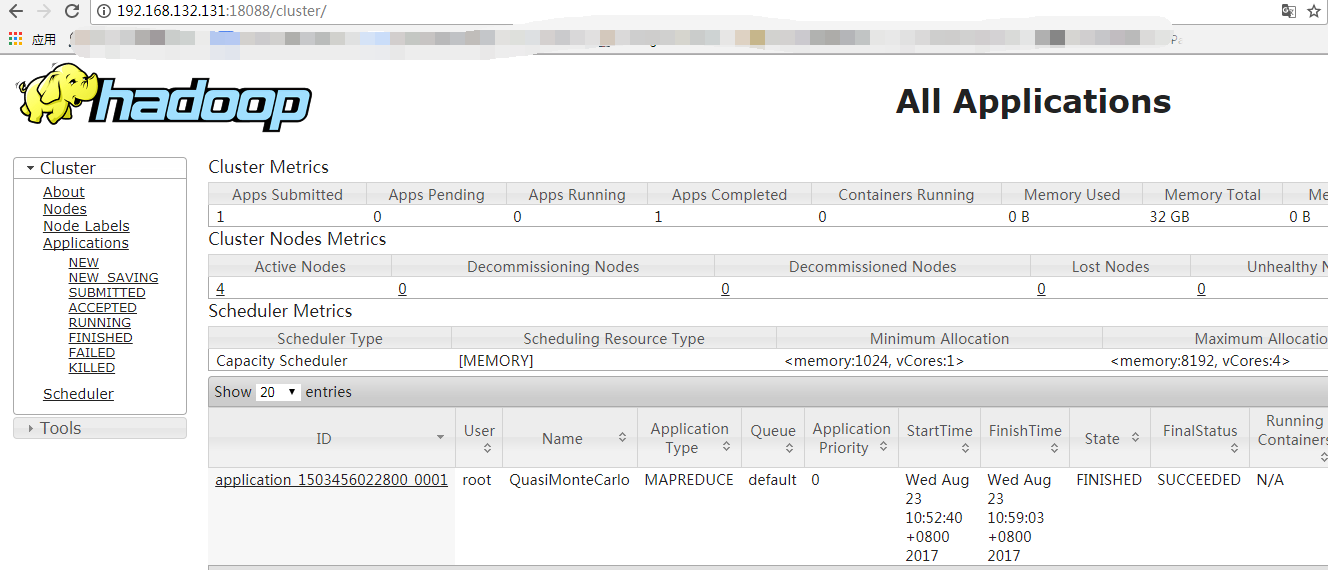
http://192.168.132.131:18088/cluster
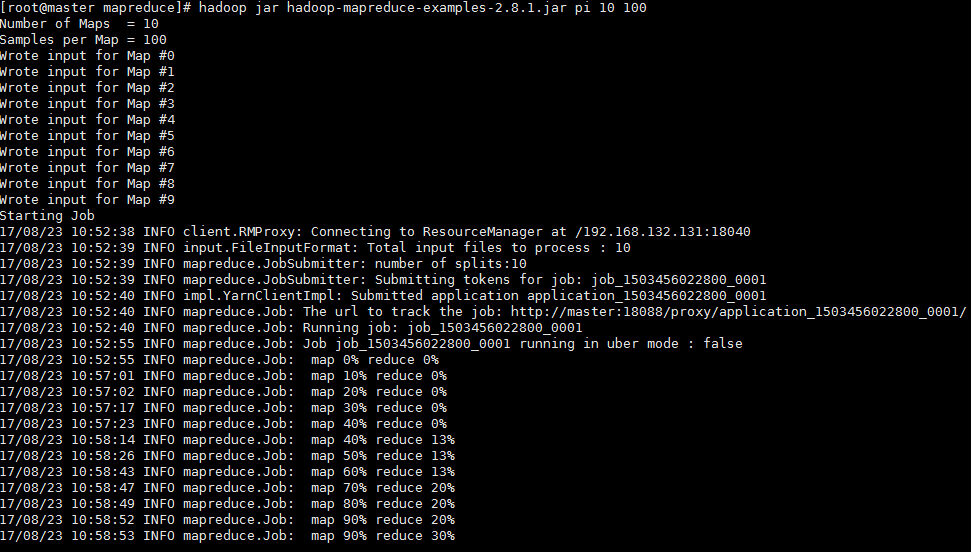
MapReduce测试
[root@master mapreduce]# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar pi 10 100

 浙公网安备 33010602011771号
浙公网安备 33010602011771号