Mobilenet V2
论文: https://arxiv.org/abs/1801.04381
1. 创新点

创新点有两个,分别是:
1. Inverted residuals
通常的residuals block:
- 先经过一个 1x1 Conv layer,把feature map的通道数“压”下来。
- 再经过3x3 Conv layer。
- 最后经过一个1x1 的Conv layer,将feature map 通道数再“扩张”回去。
即先“压缩”,最后“扩张”回去。而 inverted residuals就是 先“扩张”,最后“压缩”。为什么这么做呢?请往下看。
2. Linear bottlenecks
为了避免 Relu 对特征的破坏,在residual block的Eltwise sum之前的那个 1x1 Conv 不再采用Relu,为什么?请往下看。
2. 与Mobilenet-V1以及Resnet主要区别
Mobilenet V2 与 V1区别
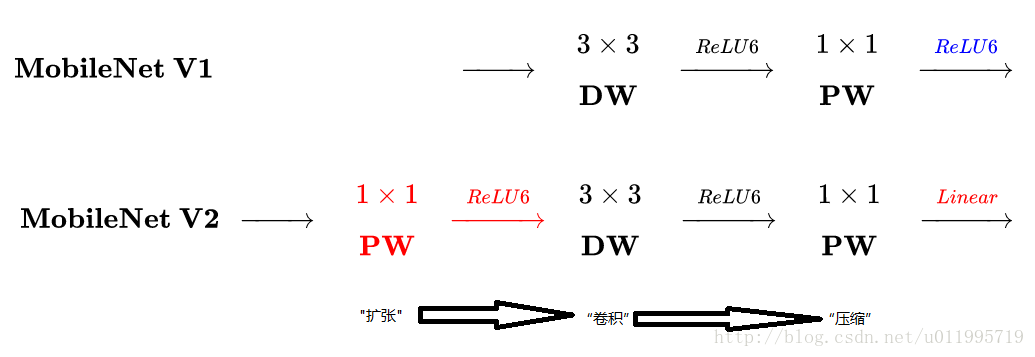
主要是两点:
- Depth-wise convolution之前多了一个1x1的“扩张”层,目的是为了提升通道数,获得更多特征。
- 最后不采用 Relu ,而是Linear,目的是防止Relu破坏特征。
MobileNetV2 与 ResNet 的block区别
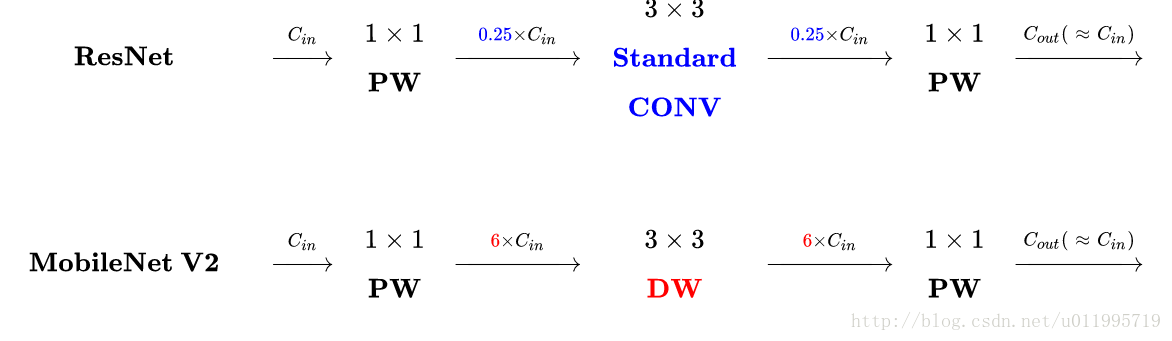
主要区别在于:
- ResNet:压缩”→“卷积提特征”→“扩张”。
- MobileNet-V2则是Inverted residuals,即:“扩张”→“卷积提特征”→ “压缩”。
3. 设计思想
-
MobileNet-V1 最大的特点就是采用 depth-wise separable convolution 来减少运算量以及参数量,而在网络结构上,没有采用shortcut的方式。
-
Resnet及Densenet等一系列采用 shortcut 的网络的成功,表明了shortcut 是个非常好的东西,于是MobileNet-V2就将这个好东西拿来用。
拿来主义,最重要的就是要结合自身的特点,MobileNet的特点就是depth-wise separable convolution,但是直接把 depth-wise separable convolution应用到 residual block中,会碰到如下问题:
-
Depthwise Conv layer层提取得到的特征受限于 输入的通道数。
- 若是采用以往的residual block,先“压缩”,再卷积提特征,那么DWConv layer可提取得特征就太少了
- 因此一开始不“压缩”,MobileNetV2反其道而行,一开始先“扩张”,本文实验“扩张”倍数为6。
通常residual block里面是 “压缩”→“卷积提特征”→“扩张”,MobileNetV2就变成了 “扩张”→“卷积提特征”→ “压缩”,因此称为Inverted residuals。
-
当采用“扩张”→“卷积提特征”→ “压缩”时,在“压缩”之后会碰到一个问题,那就是Relu会破坏特征。为什么这里的Relu会破坏特征呢?
这得从Relu的性质说起,Relu对于负的输入,输出全为零;而本来特征就已经被“压缩”,再经过Relu的话,又要“损失”一部分特征。
因此这里不采用Relu,实验结果表明这样做是正确的,这就称为Linear bottlenecks。
4. Network structure

其中:
- t表示“扩张”倍数.
- c表示输出通道数.
- n表示重复次数.
- s表示步长stride.
先说两点有误之处吧:
- 第五行,也就是第7~10个bottleneck,stride=2,分辨率应该从28降低到14;如果不是分辨率出错,那就应该是stride=1。
- 文中提到共计采用19个bottleneck,但是这里只有17个。
Conv2d 和avgpool和传统CNN里的操作一样;最大的特点是bottleneck,一个bottleneck由如下三个部分构成:

对于s=1, 一个inverted residuals结构的Multiply Add:

特别的,针对stride=1 和stride=2,在block上有稍微不同,主要是为了与shortcut的维度匹配,因此,stride=2时,不采用shortcut。 具体如下图:
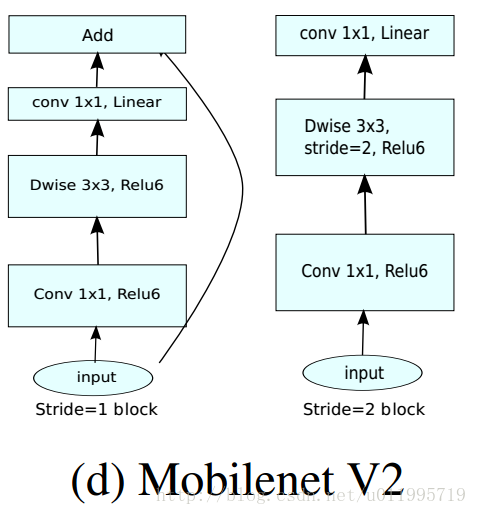
注意
可以发现,除了最后的avgpool,整个网络并没有采用pooling进行下采样,而是利用stride=2来下采样,此法已经成为主流。
5. 代码
根据 keras 官方的 Mobilenetv2 修改而得,去掉了一些参数检查,只写了网络结构部分。有以下几个点是值得注意的:
- stride=2时候的补0操作
- 卷积替代Dense操作
- inverted_res_block
"""MobileNet v2 models for Keras.
MobileNetV2 is a general architecture and can be used for multiple use cases.
Depending on the use case, it can use different input layer size and
different width factors. This allows different width models to reduce
the number of multiply-adds and thereby
reduce inference cost on mobile devices.
MobileNetV2 is very similar to the original MobileNet,
except that it uses inverted residual blocks with
bottlenecking features. It has a drastically lower
parameter count than the original MobileNet.
MobileNets support any input size greater
than 32 x 32, with larger image sizes
offering better performance.
The number of parameters and number of multiply-adds
can be modified by using the `alpha` parameter,
which increases/decreases the number of filters in each layer.
By altering the image size and `alpha` parameter,
all 22 models from the paper can be built, with ImageNet weights provided.
The paper demonstrates the performance of MobileNets using `alpha` values of
1.0 (also called 100 % MobileNet), 0.35, 0.5, 0.75, 1.0, 1.3, and 1.4
For each of these `alpha` values, weights for 5 different input image sizes
are provided (224, 192, 160, 128, and 96).
The following table describes the performance of
MobileNet on various input sizes:
------------------------------------------------------------------------
MACs stands for Multiply Adds
Classification Checkpoint| MACs (M) | Parameters (M)| Top 1 Accuracy| Top 5 Accuracy
--------------------------|------------|---------------|---------|----|-------------
| [mobilenet_v2_1.4_224] | 582 | 6.06 | 75.0 | 92.5 |
| [mobilenet_v2_1.3_224] | 509 | 5.34 | 74.4 | 92.1 |
| [mobilenet_v2_1.0_224] | 300 | 3.47 | 71.8 | 91.0 |
| [mobilenet_v2_1.0_192] | 221 | 3.47 | 70.7 | 90.1 |
| [mobilenet_v2_1.0_160] | 154 | 3.47 | 68.8 | 89.0 |
| [mobilenet_v2_1.0_128] | 99 | 3.47 | 65.3 | 86.9 |
| [mobilenet_v2_1.0_96] | 56 | 3.47 | 60.3 | 83.2 |
| [mobilenet_v2_0.75_224] | 209 | 2.61 | 69.8 | 89.6 |
| [mobilenet_v2_0.75_192] | 153 | 2.61 | 68.7 | 88.9 |
| [mobilenet_v2_0.75_160] | 107 | 2.61 | 66.4 | 87.3 |
| [mobilenet_v2_0.75_128] | 69 | 2.61 | 63.2 | 85.3 |
| [mobilenet_v2_0.75_96] | 39 | 2.61 | 58.8 | 81.6 |
| [mobilenet_v2_0.5_224] | 97 | 1.95 | 65.4 | 86.4 |
| [mobilenet_v2_0.5_192] | 71 | 1.95 | 63.9 | 85.4 |
| [mobilenet_v2_0.5_160] | 50 | 1.95 | 61.0 | 83.2 |
| [mobilenet_v2_0.5_128] | 32 | 1.95 | 57.7 | 80.8 |
| [mobilenet_v2_0.5_96] | 18 | 1.95 | 51.2 | 75.8 |
| [mobilenet_v2_0.35_224] | 59 | 1.66 | 60.3 | 82.9 |
| [mobilenet_v2_0.35_192] | 43 | 1.66 | 58.2 | 81.2 |
| [mobilenet_v2_0.35_160] | 30 | 1.66 | 55.7 | 79.1 |
| [mobilenet_v2_0.35_128] | 20 | 1.66 | 50.8 | 75.0 |
| [mobilenet_v2_0.35_96] | 11 | 1.66 | 45.5 | 70.4 |
The weights for all 16 models are obtained and
translated from the Tensorflow checkpoints
from TensorFlow checkpoints found [here]
(https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/README.md).
# Reference
This file contains building code for MobileNetV2, based on
[MobileNetV2: Inverted Residuals and Linear Bottlenecks]
(https://arxiv.org/abs/1801.04381)
Tests comparing this model to the existing Tensorflow model can be
found at [mobilenet_v2_keras]
(https://github.com/JonathanCMitchell/mobilenet_v2_keras)
"""
import numpy as np
from keras.models import Model
from keras.layers import Input, GlobalAveragePooling2D, Dropout, ZeroPadding2D
from keras.layers import Activation, BatchNormalization, add, Reshape, ReLU
from keras.layers import DepthwiseConv2D, Conv2D
from keras.utils import plot_model
from keras import backend as K
class MobilenetV2(object):
def __init__(self,
input_shape,
alpha,
depth_multiplier=1,
classes=1000,
dropout=0.1
):
self.alpha = alpha
self.input_shape = input_shape
self.depth_multiplier = depth_multiplier
self.classes = classes
self.dropout = dropout
@property
def _first_conv_filters_number(self):
return self._make_divisiable(32 * self.alpha, 8)
@staticmethod
def _make_divisiable(v, divisor=8, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
# 现在都不用池化层,而是采用stride=2来降采样
@staticmethod
def _correct_pad(x_input, kernel_size):
"""Returns a tuple for zero-padding for 2D convolution with downsampling.
Args:
x_input: An integer or tuple/list of 2 integers.
kernel_size: An integer or tuple/list of 2 integers.
Returns:
A tuple.
"""
img_dim = 1
# 获取张量的shape,取出
input_size = K.int_shape(x_input)[img_dim: img_dim + 2]
# 检查输入是单个数字还是元祖,并且进行参数检查
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
if input_size[0] is None:
adjust = (1, 1)
else:
# % 取余数, // 取整
adjust = (1 - input_size[0] % 2, 1 - input_size[1] % 2)
correct = (kernel_size[0] // 2, kernel_size[1] // 2)
return ((correct[0] - adjust[0], correct[0]),
(correct[1] - adjust[1], correct[1]))
def _first_conv_block(self, x_input):
with K.name_scope('first_conv_block'):
# 对2D输入(如图片)的边界填充0,以控制卷积以后特征图的大小
x = ZeroPadding2D(padding=self._correct_pad(x_input, kernel_size=(3, 3)),
name='Conv1_pad')(x_input)
x = Conv2D(filters=self._first_conv_filters_number,
kernel_size=3,
strides=(2, 2),
padding='valid',
use_bias=False,
name='Conv1')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999, name='Bn_Conv1')(x)
x = ReLU(max_value=6, name='Conv1_Relu')(x)
return x
def _inverted_res_block(self, x_input, filters, alpha, stride, expansion=1, block_id=0):
"""inverted residual block.
Args:
x_input: Tensor, Input tensor
filters: the original filters of projected
alpha: controls the width of the network. width multiplier.
stride: the stride of depthwise convolution
expansion: expand factor
block_id: ID
Returns:
A tensor.
"""
in_channels = K.int_shape(x_input)[-1]
x = x_input
prefix = 'block_{}_'.format(block_id)
with K.name_scope("inverted_res_" + prefix):
with K.name_scope("expand_block"):
# 1. 利用 1x1 卷积扩张 从 filters--> expandsion x filters
if block_id: # 0为False,其余均为True
expandsion_channels = expansion * in_channels # 扩张卷积的数量
x = Conv2D(filters=expandsion_channels,
kernel_size=(1, 1),
padding='same',
use_bias=False,
name=prefix + 'expand_Conv')(x)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999,
name=prefix + 'expand_BN')(x)
x = ReLU(max_value=6, name=prefix + 'expand_Relu')(x)
else:
prefix = 'expanded_conv_'
with K.name_scope("depthwise_block"):
# 2. Depthwise
# 池化类型
if stride == 2:
x = ZeroPadding2D(padding=self._correct_pad(x, (3, 3)),
name=prefix + 'pad')(x)
_padding = 'same' if stride == 1 else 'valid'
x = DepthwiseConv2D(kernel_size=(3, 3),
strides=stride,
use_bias=False,
padding=_padding,
name=prefix + 'depthwise_Conv')(x)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999,
name=prefix + 'depthwise_Relu')(x)
with K.name_scope("prpject_block"):
# 3. Projected back to low-dimensional
# 缩减的数量,output shape = _make_divisiable(int(filters * alpha))
pointwise_conv_filters = self._make_divisiable(int(filters * alpha))
x = Conv2D(filters=pointwise_conv_filters,
kernel_size=(1, 1),
padding='same',
use_bias=False,
name=prefix + 'project_Conv')(x)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999,
name=prefix +
'project_BN')(x)
# 4. shortcut
if in_channels == pointwise_conv_filters and stride == 1:
# alpha=1,stride=1,这样才能够使用使用shortcut
x = add([x_input, x], name=prefix + 'add')
return x
def _last_conv_block(self, x_input):
with K.name_scope("last_conv_block"):
if self.alpha > 1.0:
last_block_filters_number = self._make_divisiable(1280 * self.alpha, 8)
else:
last_block_filters_number = 1280
x = Conv2D(last_block_filters_number,
kernel_size=(1, 1),
use_bias=False,
name='Conv_last')(x_input)
x = BatchNormalization(epsilon=1e-3, momentum=0.999, name='Conv_last_bn')(x)
return ReLU(max_value=6, name='out_relu')(x)
def _conv_replace_dense(self, x_input):
# 用卷积替代Dense
# shape变为了x_input的通道数,即前一层的filters数量
with K.name_scope('conv_dense'):
x = GlobalAveragePooling2D()(x_input)
x = Reshape(target_shape=(1, 1, -1), name='reshape_1')(x)
x = Dropout(self.dropout, name='dropout')(x)
x = Conv2D(filters=self.classes, kernel_size=(1, 1),
padding='same', name='convolution')(x)
x = Activation('softmax')(x)
x = Reshape(target_shape=(self.classes,), name='reshape_2')(x)
return x
def block_bone(self):
x_input = Input(shape=self.input_shape, name='Input')
x = self._first_conv_block(x_input=x_input)
x = self._inverted_res_block(x_input=x, filters=16, alpha=self.alpha,
stride=1, expansion=1, block_id=0)
x = self._inverted_res_block(x, 24, alpha=self.alpha, stride=2,
expansion=6, block_id=1)
x = self._inverted_res_block(x, 24, alpha=self.alpha, stride=1,
expansion=6, block_id=2)
x = self._inverted_res_block(x, 32, alpha=self.alpha, stride=2,
expansion=6, block_id=3)
x = self._inverted_res_block(x, 32, alpha=self.alpha, stride=1,
expansion=6, block_id=4)
x = self._inverted_res_block(x, 32, alpha=self.alpha, stride=1,
expansion=6, block_id=5)
x = self._inverted_res_block(x, 64, alpha=self.alpha, stride=2,
expansion=6, block_id=6)
x = self._inverted_res_block(x, 64, alpha=self.alpha, stride=1,
expansion=6, block_id=7)
x = self._inverted_res_block(x, 64, alpha=self.alpha, stride=1,
expansion=6, block_id=8)
x = self._inverted_res_block(x, 64, alpha=self.alpha, stride=1,
expansion=6, block_id=9)
x = self._inverted_res_block(x, 96, alpha=self.alpha, stride=1,
expansion=6, block_id=10)
x = self._inverted_res_block(x, 96, alpha=self.alpha, stride=1,
expansion=6, block_id=11)
x = self._inverted_res_block(x, 96, alpha=self.alpha, stride=1,
expansion=6, block_id=12)
x = self._inverted_res_block(x, 160, alpha=self.alpha, stride=2,
expansion=6, block_id=13)
x = self._inverted_res_block(x, 160, alpha=self.alpha, stride=1,
expansion=6, block_id=14)
x = self._inverted_res_block(x, 160, alpha=self.alpha, stride=1,
expansion=6, block_id=15)
x = self._inverted_res_block(x, 320, alpha=self.alpha, stride=1,
expansion=6, block_id=16)
x = self._last_conv_block(x)
x = self._conv_replace_dense(x)
return Model(inputs=x_input, outputs=x)
if __name__ == '__main__':
Mobilenet_V2_Model = MobilenetV2(input_shape=(224, 224, 3), alpha=1, classes=1000).block_bone()
Mobilenet_V2_Model.summary()
plot_model(Mobilenet_V2_Model, show_shapes=True, to_file='mobilenetv2.png')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号