

贪心题目合集
喵了个喵 题解
磁带存储
有
求最小花费和。
因为两个片段交换,对之后没有影响。 所以可以考虑一个顺序中,如果
换前:
换后:
两个做差,得到:换之前比换之后好的条件是
按这个排序即可。
商店访问
有
与上题同理。邻项交换法:要求
但是我们并不能排了序直接扫过去,因为上面只能说明
所以排了序之后做 DP:
则
但是这是
如果
但题目的
安装 app
有
两个 APP 相邻的交换对后面没影响。
如果
如果
(安装
同理
要
那么有
但是第一种情况是不可能的,因为
所以只有第二种,而
因此只需要
即按照
树的访问
给出一棵树带点权
两个儿子先后访问对之后没影响。(所需时间都是两个子树之和)
比如树 1-2,2-3,2-4,1-5 的欧拉序就是 123242151。(每条边过一次,根结点多过一次)
设两个儿子
如果先走
如果先走
两个
要让
则
而
因此只需
得出
打怪兽
共
交换相邻两个怪兽打完后剩余的血量一样。
看
若
若
要让前一个
-
-
等价于:
-
-
但是这条件看着不太好弄啊?既要和
把怪物分两类:A 类
显然应该先打 A 类怪:打完血还更多了。
对于 A 类内部,按照
对于 B 类内部,按照
这个时候可以搞 DP 了。因为从前往后 DP 不好讨论,所以从后往前 DP。
格式化硬盘
有
两个相邻硬盘交换后对后面没影响。
现在我们要找一个顺序格式化所有硬盘,且不损坏数据。(硬盘格式化后的空间可以用来复制数据)至少需要多少额外空间?
还是考虑
这不就和上题一样了吗?不过这里是要打所有怪,求初始血量最小是多少。
可以二分初始血量,然后扫一遍看看行不行。
(重点) 括号序列
给出
(等价问题:先按照一个顺序拼好,在连接好的字符串里面挑一些删掉)
而一个括号序列中的最长合法子序列,是一个经典贪心问题,用栈可以解决。那现在唯一的问题就是怎么排序。
设
我们发现,
最后我们要让
而我们可以把右括号抽象为
这就变成了 “打怪兽”、“格式化硬盘” 的模型。(前面几题)
agc048b
有 (,),[,]。如果填小括号,得分
假设在
所以
引理:若指定
引理证明:一定有一对相邻的 [,后面的填 ]。因为一奇一偶,中间相隔偶数,那么中间全部 () 交替就行。然后这一段就算填完了,删除这一段,递归处理下一对奇偶相邻的 …… 如此往复,得证。
接下来怎么做?
把所有奇数位置和偶数位置分开成两个数组。分别按照
然后枚举有多少对位置填中括号。如果枚举了
那先排个序,然后扫一遍就行了。
博弈取物:
先手目标是让自己的价值减去对方价值最大。
后手一定优先选
求最后先手和后手拿到了什么物品。
后手拿物品的顺序是既定的,唯一的问题就是先手。
把物品按照后手拿物品的顺序排序,考虑先手拿到的物品集合需要满足什么条件。
条件①:先手在前
(因为交替,后手一定优先选前面的)
考虑满足 ① 的情况下,先手 - 后手最多多少分?
假设一开始物品全都在先手手里,是后手不停从先手手里拿物品。(并且要满足 ①)
后手每拿走一个物品
到这一步,我们知道先手一定会优先选
总结一下:
-
先把所有物品按照
-
物品从头到尾扫一遍,扫到第
-
拓展:如果先手后手的目标都是让(自己价值 - 对手价值)最大,怎么做?
假设物品都在先手手里,先手一定会先锁定
CF632C
可以发现交换两个相邻的字符串,对于前面和后面都没有影响。
因此对于两个字符串
P2878
邻项交换法知,按照
P1842
邻项交换法,
AT_dp_x
先用贪心得知
然后
三元组构造(BZ2943)
给定三个数
-
第
-
三元组的元素
-
所有三元组不可有重复元素。
-
数
一个粗略的想法是:找到最小的还没出现过的
那我们优先取
不对,手玩一个数据 n=5, p=3, q=2 就不对了。
但是,我们如果令
假设已经按照上面的贪心标准选了一些三元组
首先,
如果
如果
-
如果
如果
-
则
综上所述,当
区间移位
贪心:覆盖到点
证明用调整法,让右端点小的去覆盖一定不差。
那就可以用堆来维护。
镜子(BZ1380)
一个
有一些光从左边和下面进入,给出它们从右边和上面出去的位置,求镜子的摆放方式。(保证光线出口各不相同)
首先如果一束光从同一个位置出去,这一行(列)肯定不能有镜子,可以把这一行(列)删去。
发现一个性质:一束光的出口必然比这束光的入口更右上,这是因为镜子是一个格子的右上-左下对角线。
更有趣的性质:上面这个条件不仅是必要条件,还是充分的。也就是说,只要满足上面的性质,就一定有解。(*)
首先
下面证明当
考虑第
这时,我们在第
这样第
其实就是第
这样就形成了一个
因此性质(*)成立。(我们也可以按照上面的递归方法构造)
但是这里再提出一种新的构造方法:贪心。
首先第
然后其他的光线出去的时候都 “尽量往右走”。比如第
但是我们贪心地让它尽量借助其他镜子往右。(当然,不能干扰其他光线)例如如果
正确性:尽量往右走,可以减小对其他镜子的干扰。(感性理解一下)其实我觉得还不如上面证明(*)的时候用的方法好
工序安排
有
A 类有
第一问很简单,可以二分(也可枚举),然后看每台机器可以加工多少半成品。
第二问在第一问的基础上:有
最短时间变成成品。
不妨假设所有 B 都是同时结束的:因为如果不同时结束,我们可以把先结束的机器开始时间后移,也不会影响最终答案。(重点)
设第
在所有的
我们就在这些时刻给机器加工。
设这
而假设半成品完成时刻为
这说明:
读书(CSES1631)
有
不妨
答案就是
如果最后一本书的时间
巧克力
有
问能不能把所有巧克力放入盒子。
把盒子也视为巧克力,第一关键字长,第二关键字宽,降序排序。然后遍历,如果遍历到一块巧克力,从之前的所有盒子里挑一个宽最小的但是能装下的盒子(长是降序一定都可以)装它。
这个贪心的关键点在于一个盒子只能装一块巧克力。也就是说不管盒子里装的是哪一块巧克力,贡献都只有
田忌赛马
贪心,如果最大值大于国王最大值,就直接比。
如果最大值小于国王最大值,就用最小值和国王最大值比。
如果相等,看最小值:
如果最小值大于国王最小值,直接比;
否则用最小值和国王最大值比。
HUR-Warehouse Store
反悔式贪心
来一批就尽量满足一批,如果无法满足,看看所有已满足的客户中所需商品最多的客户是否比这个客户多。如果是,就用这个客户替换掉,可以让库存变多。
乌鸦喝水
我们只需要每个水缸还能喝多少次。把所有水缸按照次数从小到大排序,相同的按序号从大到小排序。
性质:能喝次数比
我们次数从小到大枚举水缸,定义一个位置变量
注意区分三个东西:当前水缸(这个枚举的),当前位置。
先判断当前水缸剩余次数够不够从当前位置走到第
-
如果能走到第
如果此时发现转圈的圈数大于
否则此时就是当前位置为第一个水缸,无法走到第
-
不能走到第
Free Goodies
先取的人每次取价值最大的,后取的人每次取能让自己最后的价值最大的。求最后两个人取到多少价值。
不如假设是 Jan 先取,如果是 Pet 先取就让他取了 p 最大的变成 Jan 先取。
先按照
注意
在求 DP 数组的同时同步更新一个数组
序列合并
思路:找一个界,证明所有解都
正解:
每次找到最小的数,和左右两边较小的合并,答案为
而因为每对相邻元素都必然会合并一次,所以答案
BANK:
有
有四种货币
银行希望初始持有极小的资金做成所有投资(投资过程中可以收入),即任何一种货币减少,都会使得无法做完所有投资。
解:
先考虑只有一种货币(一维)的情况。
把所有货币按照所需本金从小到大排序,如果当前投资需要的本金大于自己当前持有钱,就在开始时加上缺的部分。最后扫完了初始本金也就加好了。
再考虑二维的情况:
发现:最后两种货币的数量必然为
然后同理,三维答案为
但此时还有一个问题:已知
令
我们要在所有没选的投资集合
然后再在
如果最小的
等处理完了,
现在的问题又变成了:如何快速找出满足要求的项目?
我们令
那
01比例:
给出一个 01串,找一个子串,使其中 1 的占比最接近实数
令
则
令
化简为
这个玩意需要满足三个大小关系,找三维偏序
P7840
建立一个表格,第
题目等价于在表格中选
这不就是这题吗?用
Sail:
有
对于每一个高度,这个高度下最靠右的旗损失为
要求在第
首先发现旗杆可以按高度排序,因为每一行(高度)上旗数量不变。现在
从低到高依次考虑每个旗杆的放置方式,设
贪心:从
证明:假设第
考虑之后的旗杆在
如果有旗杆
否则以后的旗杆在这两行必为都放、都不放或者
如果都放或者都不放,不管;如果是
证毕。
那我们每次要找出最小的
我们希望每次增加后每行的数量能保持单调不增。(有序好处理)
那我们先利用有序的条件,
(例如
注意,我们不是增加这
那我们把这些
原因是有一个
找到第
而找好增加的区间后,只需要用线段树维护就行了。二分也在线段树上二分。
答案就每个高度查询一下,
LEXICO GRAPHIC 定理(只是开阔一下眼界):
给定
左半边每个点表示 从
右半边是选
如果一个点包含另一个点代表的集合,就连边。
求一个二分图完备匹配。
贪心构造:按照字典序枚举左半边的所有点,在所有没匹配的右半边点中,找代表集合字典序最小的点匹配。
LEXICODE:
找长度为
贪心构造:按照字典序从小到大看左右长度为
CF1682C
考虑出现次数
对于剩下的数,为了使
用 map 存次数即可。
CF1304D
猜一个界,然后构造。
先做最短 LIS。LIS 最短肯定是所有连续 < 段的长度的最小值。
考虑构造一组解使得答案为这个。
先令初始数组为 < 段,翻转在数组的对应段。这样就得出了构造。
受这个构造的启发,我们令初始数组为 > 段,翻转对应数组。这样可以使 LIS 最长。
一次切割的代价:(与自己方向不同的已经切了的个数 + 1)乘自己原本的代价。
一个非常裸的想法:每次挑代价最大的切,而事实上这也是正确的想法。
考虑同一种方向的切,谁先切都一样。
而对于不同方向的切,后切的会多花费一个初始代价,那么初始代价大的应该先切。
P2983
很显然的贪心,按照巧克力价格从小到大满足,直到没钱。
注意数据范围
P3411 序列变换以及写的题解
乘积:给定
先考虑
我们可以先在
此时
首先我们发现
然后我们有贪心构造法:假设我们可以使用的数构成集合
为什么正确呢?我们先证明
假设在
我们假设最优解中
发现调整后变小了。矛盾,又因为
假设
我们在
假设
贪心结论得证。
注意:这仅仅是
其实差不多:有
A + B problem 及其题解(QOJ 1289)
P4331
首先每个
观察:
引理:
假设
-
当
-
当
暂时不提引理证明,先考虑有了引理怎么求答案。
首先初始
这里的 “所在段” 其实就对应上面引理中的
给个例子:1 4 3 2 5 7 6。规定中位数是删掉一半最大的数(个数下取整)后留下的最大数。
首先
遍历到
遍历到
遍历到
遍历到
遍历到
结束,最后得出
如何快速求出两个段合并后的中位数?我们需要一个支持删除(删除一半数)、求根(查找最大值)、合并(两个段合并)的数据结构,这是可并堆,可以用左偏树实现,也许也能用Treap,FHQ-Treap实现。
每段我们都只保留小的一半,每次合并我们也同样只需要保留两段中各自小的一半。因为这两个小的一半合并后就形成了整体的小的一半,不可能有大的合并后反而变到小的一半。
过桥问题
过桥问题题解
P6193
如果原序列中奶牛
找环上花费最小的点交换。
例如 6 <= 7 <= 9 <= 8 <= 6,交换 6,7,7 到了想要的位置,图变成 6 <= 9 <= 8 <= 6,再交换 6,8,以此类推,直到环上每个点就位。
显然这种花费已经最小了。但是这是不使用环外点交换的最小。
如果可以用环外的点帮忙,上面的方法就不对了。
而如果用环外的点,我们肯定是用全局最小值帮忙,让它和环内最小值交换,然后让环内其他点归位,再把它和环内最小值换回来。
这两种方法取
反向考虑,是一些儿子合并到父亲身上。父结点显然是排在最前面,要注意的就是儿子的顺序。
假设第
则第
所以若
在实现上:每次找一个非根结点
重点:可以考虑中间的一步,子结点与父结点合并。
序列变换及题解
树上排序:给出一棵树,每个结点有两个参数
结论:若
否则
Escape
给出一棵树,初始血量
给
法一:
若一个结点
这转化为了 “打怪兽” 那题,在贪心合集一里面。但是要求父结点在子结点前打。如果没有父结点在前这个限制,记这种排序为 “打怪兽” 序。
我们可以不断取出非根结点
法二:
其实每次挑权值最大的点和父结点合并即可。
分裂(BZ2064):
初始有
有两种操作,第一种可以把任意两块区域合并为一块,新区域面积为两块区域面积之和;第二种可以把一块区域分成两块,新区域面积之和等于旧区域。
目标状态有 3 1 2 目标 1 2 3 也算达成目标)
解:
在最终方案中,若目标状态中
若图已经连好了,则操作次数为图中每个点的(度数减一)之和。(画张图手玩一下)
那如何建图呢?我们要一张图,边权之和等于总面积之和(称这个条件为合法),且总边数最小。(度数和 => 总边数)
观察到如果合法图中有环,一定不优。
证明:如果有环,因为图是二分图,所以必是偶环。考虑环中边权最小的边
因为
推论:最优解是森林。
而我们发现森林中树越多,总边数就越少。所以我们要找尽可能多的树,且每棵树都是合法的。(合法:边权和等于点权和)
注意到一棵树合法有一个必要条件:上部分点权和 = 下部分点权和。
结论:把图分成尽量多个子集,要求每个子集上下部分点权和相等。假设能分成
证明:首先
接下来就是证明每一个上下点权和相等的子集,都能构造出一棵树。这可以贪心构造。
假设子集上面
让下面第一个点和上面第一个点连边。
如果下面第一个结点点权比上面第一个大,让下面第一个的点权减去上面第一个。然后处理上面
下面第一个点权小也类似处理。总之最后能建出一棵树。得证。
有了这个结论,我们就可以做状压 DP 了。
P5912 及题解
P2949
反悔贪心
记结束时间为
按照
正确性证明:
假设贪心算法依次会删除(替换)掉
要证明:存在最优解,没有选
假设存在最优解
设贪心算法枚举到任务
定义
则
此时考虑
同时:若
当
这代表
再根据归纳法,存在最优解删掉
证毕。
P4053
这题和上题相反,价值为
同样反悔贪心,按照结束时间排序,尽量选,如果选不了了尝试替换花时间最多的任务。
Buy low Sell high:
贪心:
定义两个集合
到某天
-
-
当然,获得价值的前提是
同时这题还能费用流。
抽象出
从源点
从
题目等价于在这张图上跑最大费用流(不限制流量)。假设我们考虑了
此时应当会出现增广路,增广路类型只有两种:
-
-
我们的贪心算法就是模拟了这种费用流的解法,所以贪心正确。
贪心模拟费用流的关键,在于每次的增广路变化情况不多。用堆、集合可以模拟。
买卖股票
这里讲贪心做法。
我们把手续费在买入的时候算,也就是说,如果我们在第
我们定义
接下来我们枚举
-
如果
-
如果
-
如果
但是这里有一个问题:我们如果现在就卖出,可能后面会遇到利润更高的选项,并非全局最优。我们考虑一个反悔的操作,在我们第
-
如果先在后面遇到
-
如果先遇到
因为如果我们用 第
而如果我们留着因为我们的前提:
-
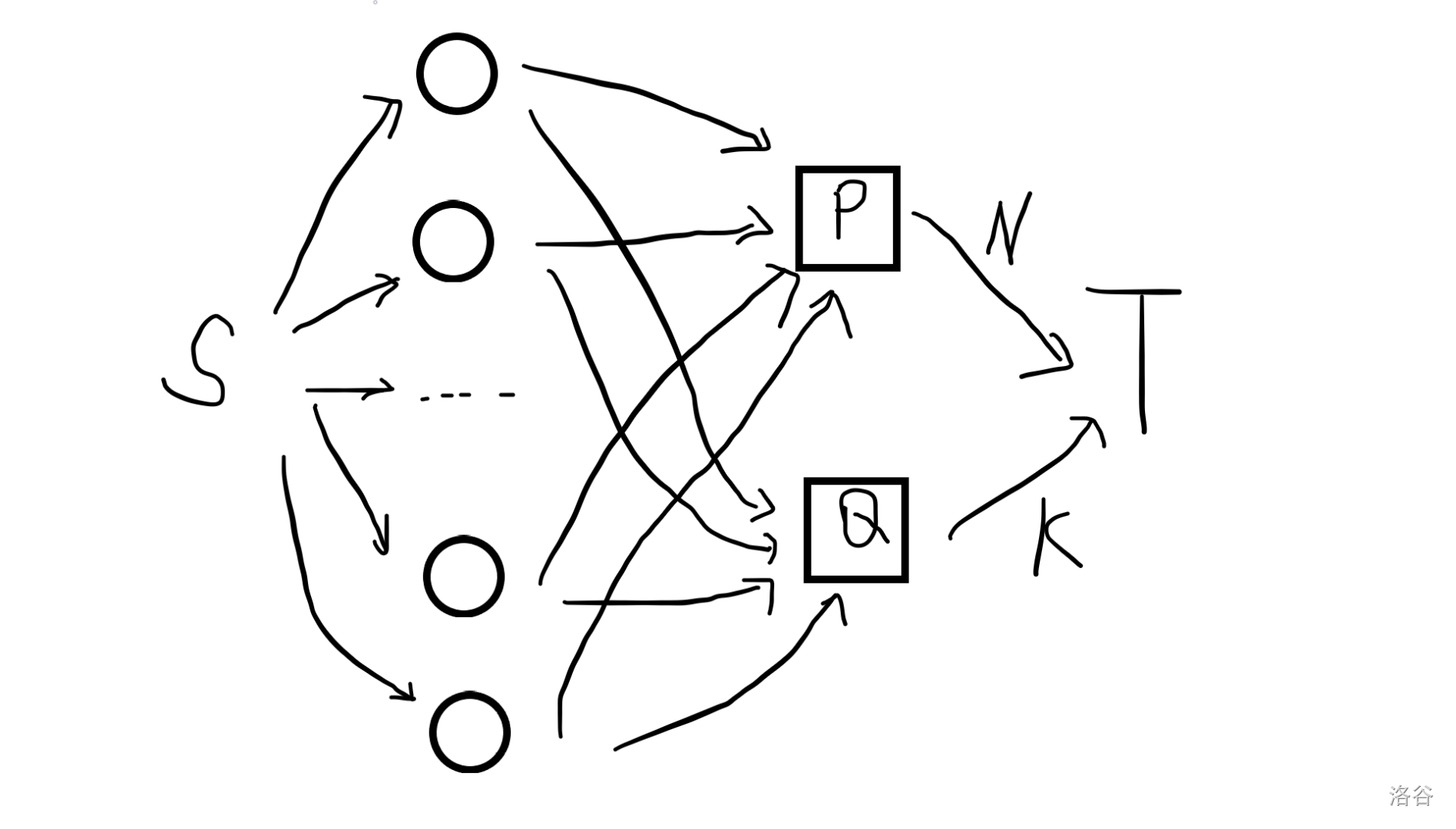
种树:有
模拟费用流,建图类似这样:
中间两层结点之间有
在上面的图里找增广路的时候,我们发现增广路上每条边的流量有特征:源点流出和汇点流入的边流量都是 0 1 0 1 0 就是一种可能的情况。
对应到原问题里,初始每个坑位都是
可见一开始每个坑位都对应一个区间,也对应一个增广路。
而更新一条增广路,会使路径上的
发现将区间翻转后,因为规定了一个区间左边一个右边一个为
那我们可以用链表来维护这些区间。同时搞一个堆,这个堆用来每次找最大价值的区间。一个区间的价值定义为其中
每次挑出一个价值最大的且未被标记为不可选的区间
一直挑,挑到够了
Cow Coupons
建成最小费用流模型。
圆形点共
走点
走
题目限定了总费用上界,其实可以转化为 “流量为
问题等价于在这张图上找最小费用流。
这题可以模拟费用流,如何模拟,主要考虑增广路长啥样。
显然当
那现在就看
增广路有两种情况:
-
-
现在要找出上面两种增广路中费用较小的,然后应用那条增广路。
-
形如 1 的增广路费用最小就是剩下所有没买的牛中不用优惠券价格最低的。
搞一个小根堆,记录所有没买的牛中
-
形如 2 的增广路费用最小就是 (
搞一个小根堆,记录所有用优惠券买的牛中
这样就用贪心模拟了费用流。
Coins
其实和上一题 cow coupons 类似,只不过右边不再是
但是我们可以先让所有人给出金币,然后让每个人的银币数量变成
这样增广路的种类只有四种:
-
-
-
-
弄四个堆,每次找出四种增广路中费用最大的选了。
取硬币问题
有
观察:一定不会有两堆硬币都只取了上面的一个,否则把一次机会用来取价值更大的下层硬币,价值更大。
所以最终的方案一定是取了
要么是取出两个硬币和最大的
P4694 = CF802O
线段树模拟费用流。
和 Buy low sell high 相似。
网络流构图是类似的,费用变了一下。
要求的是流量为
差别主要在于固定流量这个条件。
给出一个观察:
我们把
依次考虑 (;再看看 )。
一个合法解必然对应着一个可行流,而一个可行流对应着一个合法括号序列。(这其实很好理解,卖出必须先买入,对应右括号前必有左括号,然后删去第一次买入卖出,又可以递归证明)
把左括号视作
重新回到费用流的图里面。考虑图里面的一条增广路,要么是
要么是
显然
因为图中边权均为正,所以无论怎么搞都不会出现负环,这和 buy low sell high 不同。
现在的问题就很明确了,每次找出数对
-
-
这可以用线段树维护。不过要搞很多东西。对于一个区间
-
-
Easy Climb
基础的
这个状态数太多了。但是观察到每一座山最后的高度
证明:
显然
假设一个最优解
设
考虑
因为这一段都不属于
那我们一直这么操作,直到出现这一段里某个
但是这个证明似乎有缺陷:整体加减是否会导致开头结尾和
综上,结论得证,状态数量优化到
数据备份
显然只可能相邻的楼房连电缆,问题变为:有一些数,要选
这个问题有点像上面的 种树,每次选最小的,然后加入一个权值等于 左边+右边-本身 的数,同时左边、右边、本身合并为一个大结点。
用链表。
Ants in Leaves
显然根结点的各个子树相互独立,每颗子树的答案取 max 即可。
显然我们希望每一次行动,都是所有蚂蚁都往上走。但是有可能多个蚂蚁的目的地都是一个结点,这个时候就会卡住。
什么样的蚂蚁之间会矛盾?初始深度相同的蚂蚁会,而且可以发现一定会。(至少在子树的根那里卡住一次)
这个时候我们就要让一些蚂蚁停留一回合,可以视作深度加一。
在这么把所有初始深度相同的蚂蚁都加好了之后,最大深度就是最终答案。
具体操作:把子树里的所有深度从小到大排序得到数组
荷马史诗
如果没有要求编码的最长长度最短,就是哈夫曼树的板子题。
普通哈夫曼编码拿一个普通的优先队列就行了。而对于还要求最长长度的哈夫曼编码,优先队列的元素要有二维属性:一维记录出现次数/频率,一维记录目前的长度。
每次取出
最小式(无题号)
给定
多了一个
其实贪心方法和普通哈夫曼树一样,都是不断取两个最小的替换为结果。
我们只需要证明:权值最小的两个
用调整法,如果更高层的有比最低层还小的,可以调整。新旧两种方案的权值一比较,证毕。
(证明的式子是
Color a tree
题意: 一棵树要染色,每次可以挑一个没有被染的但是父节点被染的结点染了。每个结点有权值,贡献为(被染的时刻)*(权值)。求贡献最小。
贪心:权值最大的父节点被选了之后,它就立刻会在下一个被选。
我们希望可以合并结点,同时合并后的结点可以等价代替原本的两个结点。
比如
-
先
-
先
因为我们只关心大小关系。(我们不在乎具体数值,因为如果通过大小关系找出染色顺序,就可以重新倒回去算具体数值)
给
这相当于
所以合并操作就是把
Security System
题意: 一个
的方格图里面有一个正方形区域的格子内放了传感器。你在 ,目标 。
每次可以向右或向上,如果走完到达,对于每个传感器,其数值减少 与它的曼哈顿距离。
要求走过去每个传感器非负,而每个传感器的初值都是。问是否可以达成。
观察1:只需要关注正方形四个角上的传感器。不妨记它们为
这四个传感器把方格图分成九个部分,对于四周一圈的八个部分,怎么走要么贡献都一样,要么方向总有一个最小的容易求。
对于中间部分,移动会同时影响
注意到穿越中间部分的路径的起讫点是确定的。则我们可以找到相对


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!