

最后一次大作业-4-numpy、scipy、pandas、matplotlib的读书报告
NumPy 数组属性 |
|
| ndarray.ndim() | 用于返回数组的维数,等于秩。 |
| ndarray.shape() | 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim 属性(秩)。比如,一个二维数组,其维度表示"行数"和"列数"。
ndarray.shape 也可以用于调整数组大小。NumPy 也提供了 reshape 函数来调整数组大小。 |
| ndarray.itemsize() | 以字节的形式返回数组中每一个元素的大小。
例如,一个元素类型为 float64 的数组 itemsiz 属性值为 8(float64 占用 64 个 bits,每个字节长度为 8,所以 64/8,占用 8 个字节),又如,一个元素类型为 complex32 的数组 item 属性为 4(32/8)。 |
| ndarray.flags() |
返回 ndarray 对象的内存信息,包含以下属性 C_CONTIGUOUS (C): 数据是在一个单一的C风格的连续段中 F_CONTIGUOUS (F): 数据是在一个单一的Fortran风格的连续段中 OWNDATA (O): 数组拥有它所使用的内存或从另一个对象中借用它 WRITEABLE (W): 数据区域可以被写入,将该值设置为 False,则数据为只读 ALIGNED (A): 数据和所有元素都适当地对齐到硬件上 UPDATEIFCOPY (U): 这个数组是其它数组的一个副本,当这个数组被释放时,原数组的内容将被更新 |
NumPy 创建数组 |
|
| numpy.empty(shape, dtype = float, order = 'C') |
用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组 shape: 数组形状 dtype: 数据类型,可选 order: 有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
| numpy.zeros(shape, dtype = float, order = 'C') |
创建指定大小的数组,数组元素以 0 来填充 shape: 数组形状 dtype: 数据类型,可选 order: 'C' 用于 C 的行数组,或者 'F' 用于 FORTRAN 的列数组 |
| numpy.ones(shape, dtype = None, order = 'C') |
创建指定形状的数组,数组元素以 1 来填充 shape: 数组形状 dtype: 数据类型,可选 order: 'C' 用于 C 的行数组,或者 'F' 用于 FORTRAN 的列数组 |
NumPy 从已有的数组创建数组 |
|
| numpy.asarray(a, dtype = None, order = None) |
类似 numpy.array,但 numpy.asarray 参数只有三个,比 numpy.array 少两个。 a: 任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组 dtype:数据类型,可选 order:可选,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
| numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0) |
用于实现动态数组。接受 buffer 输入参数,以流的形式读入转化成 ndarray 对象。 buffer: 可以是任意对象,会以流的形式读入。 dtype: 返回数组的数据类型,可选 count: 读取的数据数量,默认为-1,读取所有数据。 offset: 读取的起始位置,默认为0。 |
| numpy.fromiter(iterable, dtype, count=-1) |
方法从可迭代对象中建立 ndarray 对象,返回一维数组。. iterable: 可迭代对象 dtype: 返回数组的数据类型 count: 读取的数据数量,默认为-1,读取所有数据 |
NumPy 从数值范围创建数组 |
|
| numpy.arange(start, stop, step, dtype) |
函数创建数值范围并返回 ndarray 对象
|
| numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) |
函数用于创建一个一维数组,数组是一个等差数列构成的
|
| numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None) |
函数用于创建一个于等比数列
|
Numpy 数组操作 |
|
| numpy.reshape(arr, newshape, order='C') |
函数可以在不改变数据的条件下修改形状
order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'k' -- 元素在内存中的出现顺序。 |
| numpy.ndarray.flat() | 一个数组元素迭代器 |
| ndarray.flatten(order='C') |
返回一份数组拷贝,对拷贝所做的修改不会影响原始数组 order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'K' -- 元素在内存中的出现顺序。 |
| numpy.ravel(a, order='C') |
展平的数组元素,顺序通常是"C风格",返回的是数组视图(view,有点类似 C/C++引用reference的意味),修改会影响原始数组。 order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'K' -- 元素在内存中的出现顺序。 |
| numpy.transpose(arr, axes) |
函数用于对换数组的维度
|
| numpy.ndarray.T() 类似 numpy.transpose() |
函数用于对换数组的维度 |
| numpy.rollaxis(arr, axis, start) |
numpy.rollaxis(arr, axis, start)
|
| numpy.swapaxes(arr, axis1, axis2) |
函数用于交换数组的两个轴
|
| numpy.broadcast() | 用于模仿广播的对象,它返回一个对象,该对象封装了将一个数组广播到另一个数组的结果。 该函数使用两个数组作为输入参数 |
| numpy.broadcast_to(array, shape, subok) | 函数将数组广播到新形状。它在原始数组上返回只读视图。 它通常不连续。 如果新形状不符合 NumPy 的广播规则,该函数可能会抛出ValueError。 |
| numpy.expand_dims(arr, axis) |
函数通过在指定位置插入新的轴来扩展数组形状
|
| numpy.squeeze(arr, axis) |
函数从给定数组的形状中删除一维的条目
|
| numpy.concatenate((a1, a2, ...), axis) |
函数用于沿指定轴连接相同形状的两个或多个数组
|
| numpy.stack(arrays, axis) |
函数用于沿新轴连接数组序列
|
| numpy.hstack() | 是 numpy.stack() 函数的变体,它通过水平堆叠来生成数组。 |
| numpy.vstack() | 是 numpy.stack() 函数的变体,它通过垂直堆叠来生成数组。 |
| numpy.split(ary, indices_or_sections, axis) |
函数沿特定的轴将数组分割为子数组 ary:被分割的数组 indices_or_sections:果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭) axis:沿着哪个维度进行切向,默认为0,横向切分。为1时,纵向切分 |
| numpy.hsplit() | 函数用于水平分割数组,通过指定要返回的相同形状的数组数量来拆分原数组。 |
| numpy.vsplit() | 沿着垂直轴分割,其分割方式与hsplit用法相同。 |
| numpy.resize(arr, shape) | 函数返回指定大小的新数组。
如果新数组大小大于原始大小,则包含原始数组中的元素的副本。 arr:要修改大小的数组 shape:返回数组的新形状 |
| numpy.append(arr, values, axis=None) | 函数在数组的末尾添加值。 追加操作会分配整个数组,并把原来的数组复制到新数组中。 此外,输入数组的维度必须匹配否则将生成ValueError。
append 函数返回的始终是一个一维数组。 arr:输入数组 values:要向arr添加的值,需要和arr形状相同(除了要添加的轴) axis:默认为 None。当axis无定义时,是横向加成,返回总是为一维数组!当axis有定义的时候,分别为0和1的时候。当axis有定义的时候,分别为0和1的时候(列数要相同)。当axis为1时,数组是加在右边(行数要相同)。 |
| numpy.insert(arr, obj, values, axis) | 函数在给定索引之前,沿给定轴在输入数组中插入值。
如果值的类型转换为要插入,则它与输入数组不同。 插入没有原地的,函数会返回一个新数组。 此外,如果未提供轴,则输入数组会被展开。 arr:输入数组 obj:在其之前插入值的索引 values:要插入的值 axis:沿着它插入的轴,如果未提供,则输入数组会被展开 |
| numpy.delete(arr, obj, axis) |
函数返回从输入数组中删除指定子数组的新数组。 与 insert() 函数的情况一样,如果未提供轴参数,则输入数组将展开。 arr:输入数组 obj:可以被切片,整数或者整数数组,表明要从输入数组删除的子数组 axis:沿着它删除给定子数组的轴,如果未提供,则输入数组会被展开 |
| numpy.unique(arr, return_index, return_inverse, return_counts) |
函数用于去除数组中的重复元素。
|
NumPy 字符串函数 |
|
| numpy.char.add() | 函数依次对两个数组的元素进行字符串连接。 |
| numpy.char.multiply() | 函数执行多重连接。 |
| numpy.char.center() | 函数用于将字符串居中,并使用指定字符在左侧和右侧进行填充。 |
| numpy.char.capitalize() | 函数将字符串的第一个字母转换为大写 |
| numpy.char.title() | 函数将字符串的每个单词的第一个字母转换为大写 |
| numpy.char.lower() | 函数对数组的每个元素转换为小写。它对每个元素调用 str.lower。 |
| numpy.char.upper() | 函数对数组的每个元素转换为大写。它对每个元素调用 str.upper。 |
| numpy.char.split() | 通过指定分隔符对字符串进行分割,并返回数组。默认情况下,分隔符为空格。 |
| numpy.char.splitlines() | 函数以换行符作为分隔符来分割字符串,并返回数组。 |
| numpy.char.strip() | 函数用于移除开头或结尾处的特定字符。 |
| numpy.char.join() | 函数通过指定分隔符来连接数组中的元素或字符串 |
| numpy.char.replace() | 函数使用新字符串替换字符串中的所有子字符串。 |
| numpy.char.encode() | 函数对数组中的每个元素调用 str.encode 函数。 默认编码是 utf-8,可以使用标准 Python 库中的编解码器。 |
| numpy.char.decode() | 函数对编码的元素进行 str.decode() 解码。 |
NumPy 数学函数 |
|
| numpy.sin() | 函数获得正弦 |
| numpy.cos() | 函数获得余弦 |
| numpy.tan() | 函数获得正切 |
| numpy.arcsin() | 函数获得反正弦 |
| numpy.arccos() | 函数获得反余弦 |
| numpy.arctan() | 函数获得反正切 |
| numpy.degrees() | 函数将弧度转换为角度。 |
| numpy.around(a,decimals) | 函数返回指定数字的四舍五入值。a: 数组, decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置 |
| numpy.floor() | 返回小于或者等于指定表达式的最大整数,即向下取整。 |
| numpy.ceil() | 返回大于或者等于指定表达式的最小整数,即向上取整。 |
NumPy 算术函数 |
|
| numpy.add() | 算术加 |
| numpy.subtract() | 算术减 |
| numpy.multiply() | 算术乘 |
| numpy.divide() | 算术除 |
| numpy.reciprocal() | 函数返回参数逐元素的倒数。如 1/4 倒数为 4/1。 |
| numpy.power() | 函数将第一个输入数组中的元素作为底数,计算它与第二个输入数组中相应元素的幂。 |
| numpy.mod() | 计算输入数组中相应元素的相除后的余数。 函数 numpy.remainder() 也产生相同的结果。 |
NumPy 统计函数 |
|
| numpy.amin() | 用于计算数组中的元素沿指定轴的最小值。 |
| numpy.amax() | 用于计算数组中的元素沿指定轴的最大值。 |
| numpy.ptp() | 函数计算数组中元素最大值与最小值的差(最大值 - 最小值)。 |
| numpy.percentile(a, q, axis) | 百分位数是统计中使用的度量,表示小于这个值的观察值的百分比。 函数numpy.percentile()接受以下参数。a: 输入数组,q: 要计算的百分位数,在 0 ~ 100 之间,axis: 沿着它计算百分位数的轴 |
| numpy.median() | 函数用于计算数组 a 中元素的中位数(中值) |
| numpy.mean() | 函数返回数组中元素的算术平均值。 如果提供了轴,则沿其计算。算术平均值是沿轴的元素的总和除以元素的数量。 |
| numpy.average() | 函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。该函数可以接受一个轴参数。 如果没有指定轴,则数组会被展开。加权平均值即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。考虑数组[1,2,3,4]和相应的权重[4,3,2,1],通过将相应元素的乘积相加,并将和除以权重的和,来计算加权平均值。 |
| numpy.std([x1,x2,x3,x4]) | 函数返回标准差 |
| numpy.var([x1,x2,x3,x4]) | 函数返回方差 |
NumPy 排序、条件刷选函数 |
|
| numpy.sort(a, axis, kind, order) |
函数返回输入数组的排序副本。 a: 要排序的数组 axis: 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序, axis=0 按列排序,axis=1 按行排序 kind: 默认为'quicksort'(快速排序) order: 如果数组包含字段,则是要排序的字段 |
| numpy.argsort() | 函数返回的是数组值从小到大的索引值。 |
| numpy.lexsort() | 用于对多个序列进行排序。把它想象成对电子表格进行排序,每一列代表一个序列,排序时优先照顾靠后的列。 |
| numpy.msort(a) | 数组按第一个轴排序,返回排序后的数组副本。np.msort(a) 相等于 np.sort(a, axis=0)。 |
| numpy.sort_complex(a) | 对复数按照先实部后虚部的顺序进行排序。 |
| numpy.partition(a, kth[, axis, kind, order]) | 指定一个数,对数组进行分区 |
| numpy.argpartition(a, kth[, axis, kind, order]) | 可以通过关键字 kind 指定算法沿着指定轴对数组进行分区 |
| numpy.argmax() | 函数分别沿给定轴返回最大元素的索引 |
| numpy.argmin() | 函数分别沿给定轴返回最小元素的索引 |
| numpy.nonzero() | 函数返回输入数组中非零元素的索引 |
| numpy.where() | 函数返回输入数组中满足给定条件的元素的索引。 |
| numpy.extract() | 函数根据某个条件从数组中抽取元素,返回满条件的元素。 |
NumPy 字节交换 |
|
| numpy.ndarray.byteswap() | 函数将 ndarray 中每个元素中的字节进行大小端转换。 |
NumPy 矩阵库(Matrix) |
|
| numpy.transpose () | 函数来对换数组的维度 |
| numpy.matlib.empty(shape, dtype, order) | 函数返回一个新的矩阵,shape: 定义新矩阵形状的整数或整数元组Dtype: 可选,数据类型order: C(行序优先) 或者 F(列序优先) |
| numpy.matlib.zeros() | 函数创建一个以 0 填充的矩阵。 |
| numpy.matlib.ones() | 函数创建一个以 1 填充的矩阵。 |
| numpy.matlib.eye(n, M,k, dtype) |
函数返回一个矩阵,对角线元素为 1,其他位置为零。 n: 返回矩阵的行数 M: 返回矩阵的列数,默认为 n k: 对角线的索引 dtype: 数据类型 |
| numpy.matlib.identity() | 函数返回给定大小的单位矩阵。单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为 1,除此以外全都为 0。 |
| numpy.matlib.rand() | 函数创建一个给定大小的矩阵,数据是随机填充的。 |
NumPy 线性代数 |
|
| numpy.dot(a, b, out=None) |
对于两个一维的数组,计算的是这两个数组对应下标元素的乘积和(数学上称之为内积); 对于二维数组,计算的是两个数组的矩阵乘积; 对于多维数组,它的通用计算公式如下,即结果数组中的每个元素都是:数组a的最后一维上的所有元素与数组b的倒数第二位上的所有元素的乘积和: dot(a, b)[i,j,k,m] = sum(a[i,j,:] * b[k,:,m])。 a : ndarray 数组 b : ndarray 数组 out : ndarray, 可选,用来保存dot()的计算结果 |
| numpy.vdot() | 函数是两个向量的点积。 如果第一个参数是复数,那么它的共轭复数会用于计算。 如果参数是多维数组,它会被展开。 |
| numpy.inner() | 函数返回一维数组的向量内积。对于更高的维度,它返回最后一个轴上的和的乘积。 |
| numpy.matmul() |
函数返回两个数组的矩阵乘积。 虽然它返回二维数组的正常乘积,但如果任一参数的维数大于2,则将其视为存在于最后两个索引的矩阵的栈,并进行相应广播。另一方面,如果任一参数是一维数组,则通过在其维度上附加 1 来将其提升为矩阵,并在乘法之后被去除。对于二维数组,它就是矩阵乘法 |
| numpy.linalg.det() | 函数计算输入矩阵的行列式。
行列式在线性代数中是非常有用的值。 它从方阵的对角元素计算。 对于 2×2 矩阵,它是左上和右下元素的乘积与其他两个的乘积的差。 换句话说,对于矩阵[[a,b],[c,d]],行列式计算为 ad-bc。 较大的方阵被认为是 2×2 矩阵的组合。 |
| numpy.linalg.solve() | 函数给出了矩阵形式的线性方程的解。 |
| numpy.linalg.inv() | 函数计算矩阵的乘法逆矩阵。 |
NumPy IO |
|
| numpy.save(file, arr, allow_pickle=True, fix_imports=True) |
函数将数组保存到以 .npy 为扩展名的文件中。 file:要保存的文件,扩展名为 .npy,如果文件路径末尾没有扩展名 .npy,该扩展名会被自动加上 arr: 要保存的数组 allow_pickle: 可选,布尔值,允许使用 Python pickles 保存对象数组,Python 中的 pickle 用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化 fix_imports: 可选,为了方便 Pyhton2 中读取 Python3 保存的数据。 |
| numpy.savez(file, *args, **kwds) |
函数将多个数组保存到以 npz 为扩展名的文件中。 file:要保存的文件,扩展名为 .npz,如果文件路径末尾没有扩展名 .npz,该扩展名会被自动加上。 args: 要保存的数组,可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为 arr_0, arr_1, … 。 kwds: 要保存的数组使用关键字名称。 |
| numpy.loadtxt(FILENAME, dtype=int, delimiter=' ') |
函数是以简单的文本文件格式获取数据。 参数 delimiter 可以指定各种分隔符、针对特定列的转换器函数、需要跳过的行数等。 |
| numpy.savetxt(FILENAME, a, fmt="%d", delimiter=",") |
函数是以简单的文本文件格式存储数据参数 delimiter 可以指定各种分隔符、针对特定列的转换器函数、需要跳过的行数等。 |
SciPy:基于 Numpy,汇集了一系列的数学算法和便捷的函数。它可以向开发者提供用于数据操作与可视化的高级命令和类,是构建交互式 Python 会话的强大工具。
| scipy.cluster() | 向量计算/Kmeans |
| scipy.constants() | 物理和数学常量 |
| scipy.fftpack() | 傅立叶变换 |
| scipy.integrate() | 积分程序 |
| scipy.interpolate() | 插值 |
| scipy.io() | 数据输入输出 |
| scipy.linalg() | 线性代数程序 |
| scipy.ndimage() | n维图像包 |
| scipy.odr() | 正交距离回归 |
| scipy.optimize() | 优化 |
| scipy.signal() | 信号处理 |
| scipy.sparse() | 稀疏矩阵 |
| scipy.spatial() | 空间数据结构和算法 |
| scipy.special() | 一些特殊的数学函数 |
| scipy.stats() | 统计 |
| scipy.linalg.det() | 计算方阵的行列式 |
| scipy.linalg.inv() | 计算方阵的逆 |
| scipy.linalg.svd() | 奇异值分解 |
| scipy.fftpack.fftfreq() | 生成样本序列 |
| scipy.fftpack.fft() | 计算快速傅立叶变换 |
| scipy.optimize | 模块提供了函数最值、曲线拟合和求根的算法。在optimize中一般使用bfgs算法 |
函数最值:以寻找函数f(x)=x²+10sin(x)的最小值为例进行说明:
首先绘制目标函数的图形:

from scipy import optimize import numpy as np import matplotlib.pyplot as plt #定义目标函数 def f(x): return x**2+10*np.sin(x) #绘制目标函数的图形 plt.figure(figsize=(10,5)) x = np.arange(-10,10,0.1) plt.xlabel('x') plt.ylabel('y') plt.title('optimize') plt.plot(x,f(x),'r-',label='$f(x)=x^2+10sin(x)$') #图像中的最低点函数值 a = f(-1.3) plt.annotate('min',xy=(-1.3,a),xytext=(3,40),arrowprops=dict(facecolor='black',shrink=0.05)) plt.legend() plt.show()
图形输出如下:
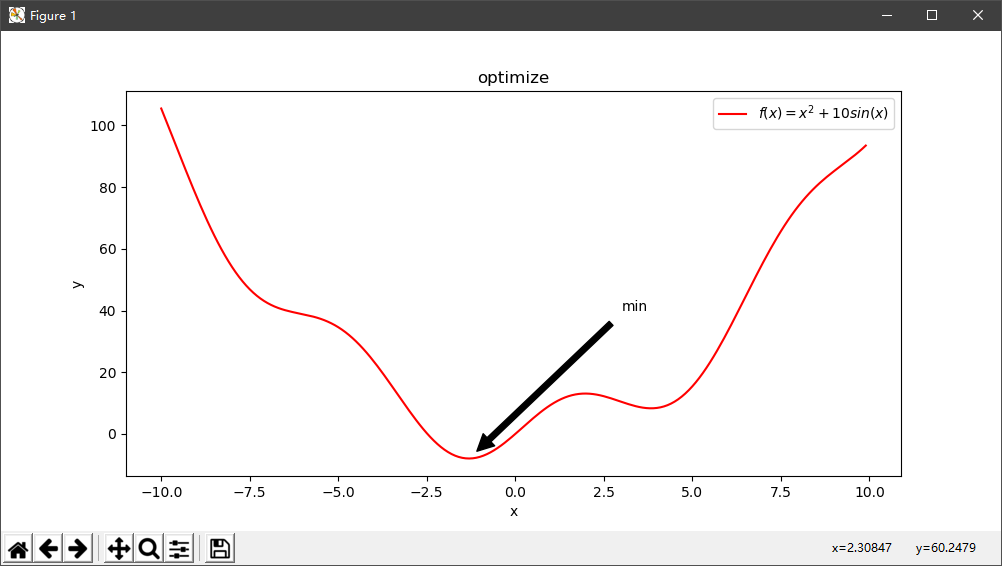
显然这是一个非凸优化问题,对于这类函数得最小值问题一般是从给定的初始值开始进行一个梯度下降,在optimize中一般使用bfgs算法。
1 | optimize.fmin_bfgs(f,0) |
运行结果:

结果显示在经过五次迭代之后找到了一个局部最低点-7.945823,显然这并不是函数的全局最小值,只是该函数的一个局部最小值,这也是拟牛顿算法(BFGS)的局限性,如果一个函数有多个局部最小值,拟牛顿算法可能找到这些局部最小值而不是全局最小值,这取决与初始点的选取。在我们不知道全局最低点,并且使用一些临近点作为初始点,那将需要花费大量的时间来获得全局最优。此时可以采用暴力搜寻算法,它会评估范围网格内的每一个点。对于本例,如下:
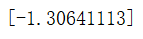
可以使用scipy.optimize.fminbound(function,a,b)得到指定范围([a,b])内的局部最低点。
Pandas:面向数据操作和分析的 Python 库,提供用于处理数字图表和时序数据的数据结构和操作功能。
pandas有两个主要数据结构:Series和DataFrame。
Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
Series的创建
pd.Series(list,index=[ ]),第二个参数是Series中数据的索引,可以省略。
Matplotlib:Python 中常用的绘图库,能在跨平台的交互式环境生成高质量图形。后来在它的基础上又衍生了更为高级的绘图库 Seaborn。
import numpy as np from matplotlib import pyplot as plt x = np.arange(1,11) y = 2 * x + 5 plt.title("Matplotlib demo") plt.xlabel("x axis caption") plt.ylabel("y axis caption") plt.plot(x,y) plt.show()
以上实例中,np.arange() 函数创建 x 轴上的值。y 轴上的对应值存储在另一个数组对象 y 中。 这些值使用 matplotlib 软件包的 pyplot 子模块的 plot() 函数绘制。
图形由 show() 函数显示。
以上实例中,np.arange() 函数创建 x 轴上的值。y 轴上的对应值存储在另一个数组对象 y 中。 这些值使用 matplotlib 软件包的 pyplot 子模块的 plot() 函数绘制。
图形由 show() 函数显示。
import numpy as np from matplotlib import pyplot as plt x = np.arange(1,11) y = 2 * x + 5 plt.title("Matplotlib demo") plt.xlabel("x axis caption") plt.ylabel("y axis caption") plt.plot(x,y,"ob") plt.show()
import numpy as np import matplotlib.pyplot as plt # 计算正弦曲线上点的 x 和 y 坐标 x = np.arange(0, 3 * np.pi, 0.1) y = np.sin(x) plt.title("sine wave form") # 使用 matplotlib 来绘制点 plt.plot(x, y) plt.show()
import numpy as np import matplotlib.pyplot as plt # 计算正弦和余弦曲线上的点的 x 和 y 坐标 x = np.arange(0, 3 * np.pi, 0.1) y_sin = np.sin(x) y_cos = np.cos(x) # 建立 subplot 网格,高为 2,宽为 1 # 激活第一个 subplot plt.subplot(2, 1, 1) # 绘制第一个图像 plt.plot(x, y_sin) plt.title('Sine') # 将第二个 subplot 激活,并绘制第二个图像 plt.subplot(2, 1, 2) plt.plot(x, y_cos) plt.title('Cosine') # 展示图像 plt.show()
from matplotlib import pyplot as plt x = [5,8,10] y = [12,16,6] x2 = [6,9,11] y2 = [6,15,7] plt.bar(x, y, align = 'center') plt.bar(x2, y2, color = 'g', align = 'center') plt.title('Bar graph') plt.ylabel('Y axis') plt.xlabel('X axis') plt.show()
import numpy as np a = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27]) np.histogram(a,bins = [0,20,40,60,80,100]) hist,bins = np.histogram(a,bins = [0,20,40,60,80,100]) print (hist) print (bins)

from matplotlib import pyplot as plt import numpy as np a = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27]) plt.hist(a, bins = [0,20,40,60,80,100]) plt.title("histogram") plt.show()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具