【Weekly SQLpassion Newsletter】Query Memory Spills
Query Memory Spills
When you sometimes look at Execution Plans, you can see that the SELECT operator has sometimes a so-called Memory Grant assigned. This Memory Grant is specified in kilobytes and is needed for the query execution, when some operators (like Sort/Hash operators) in the Execution Plans need memory for execution – the so called Query Memory.
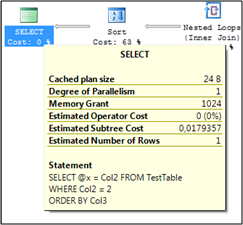
This query memory must be granted by SQL Server before the query is actually executed. The Query Optimizer uses the underlying Statistics to determine how much Query Memory must be acquired for a given query. The problem is now, when the Statistics are out-of-date, and SQL Server underestimates(vt. 低估;看轻) the processed rows. In this case, SQL Server will also request to less Query Memory for the given query. But when the query actually executes, the query can’t resize its granted Query Memory, and can’t just request more. The query must operate within the granted Query Memory. In this case, SQL Server has to spill the Sort/Hash-Operation into TempDb, which means that our very fast in-memory operation becomes a very slow physical On-Disk operation. SQL Server Profiler will report those Query Memory Spills through the events Sort Warnings and Hash Warning.
Unfortunately SQL Server 2008 (R2) provides you no events through Extended Events to track down those Memory Spills. In SQL Server 2012 this will change, and you will have additional events available inside Extended Events for troubleshooting this problem. In this posting I will illustrate you with a simple example how you can reproduce a simple Query Memory Spill because of out-of-date statistics. Let’s create a new database and a simple test table inside it:
SET STATISTICS IO ON SET STATISTICS TIME ON GO -- Create a new database CREATE DATABASE InsufficientMemoryGrants GO USE InsufficientMemoryGrants GO -- Create a test table CREATE TABLE TestTable ( Col1 INT IDENTITY PRIMARY KEY, Col2 INT, Col3 CHAR(4000) ) GO -- Create a Non-Clustered Index on column Col2 CREATE NONCLUSTERED INDEX idxTable1_Column2 ON TestTable(Col2) GO
The table TestTable contains the primary key on the first column, and the second column is indexed through a Non-Clustered Index. The third column is a CHAR(4000) column which isn’t indexed. We will use that column afterwards for an ORDER BY, so that the Query Optimizer must generate an explicit Sort Operator inside the Execution Plan. In the next step I’m just inserting 1500 records, where we have an even data distribution across all the values in the second column – each value exists once in our table.
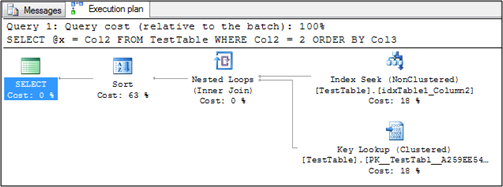
With that test data prepared we can now execute a simple query, which must use a separate Sort operator in the Execution Plan:
DECLARE @x INT SELECT @x = Col2 FROM TestTable WHERE Col2 = 2 ORDER BY Col3 GO
This query uses the following Execution Plan:
When you look into SQL Server Profiler and you have enabled the above mentioned events, nothing happens. You can also use the DMV sys.dm_io_virtual_file_stats and the columns num_of_writes and num_of_bytes_written to find out if there was some activity in TempDb for a given query. This works – of course only – when you are the only person who currently uses the given SQL Server instance:
-- Check the activity in TempDb before we execute the sort operation. SELECT num_of_writes, num_of_bytes_written FROM sys.dm_io_virtual_file_stats(DB_ID('tempdb'), 1) GO -- Select a record through the previous created Non-Clustered Index from the table. -- SQL Server retrieves the record through a Non-Clustered Index Seek operator. -- SQL Server estimates for the sort operator 1 record, which also reflects -- the actual number of rows. -- SQL Server requests a memory grant of 1024kb - the sorting is done inside -- the memory. DECLARE @x INT SELECT @x = Col2 FROM TestTable WHERE Col2 = 2 ORDER BY Col3 GO -- Check the activity in TempDb after the execution of the sort operation. -- There was no activity in TempDb during the previous SELECT statement. SELECT num_of_writes, num_of_bytes_written FROM sys.dm_io_virtual_file_stats(DB_ID('tempdb'), 1) GO
Again you will see no activity in TempDb, which means the output from sys.dm_io_virtual_file_stats is the same before and after executing the query. The query takes on my system around 1ms of execution time.
Now we have a table with 1500 records, means that our table needs 20% + 500 rows of data changes so that SQL Server will update the statistics. If you’re doing the math, we need 800 data modifications in that table (500 + 300). So let’s just insert 799 additional rows where the value of the second column is 2. We are just changing the data distribution and SQL Server WILL NOT update the statistics, because one additional data change is still missing, until Update Statistics is triggered automatically inside SQL Server!
-- Insert 799 records into table TestTable SELECT TOP 799 IDENTITY(INT, 1, 1) AS n INTO #Nums FROM master.dbo.syscolumns sc1 INSERT INTO TestTable (Col2, Col3) SELECT 2, REPLICATE('x', 4000) FROM #nums DROP TABLE #nums GO
When you now execute the same query again, SQL Server will now spill the Sort operation to TempDb, because SQL Server will only request a Query Memory Grant of 1024 kilobytes, which is estimated for just 1 record – the memory grant has the same size as before:
-- Check the activity in TempDb before we execute the sort operation. SELECT num_of_writes, num_of_bytes_written FROM sys.dm_io_virtual_file_stats(DB_ID('tempdb'), 1) GO -- SQL Server estimates now 1 record for the sort operation and requests a memory grant of 1.024kb for the query. -- This is too less, because actually we are sorting 800 rows! -- SQL Server has to spill the sort operation into TempDb, which now becomes a physical I/O operation!!! DECLARE @x INT SELECT @x = Col2 FROM TestTable WHERE Col2 = 2 ORDER BY Col3 GO -- Check the activity in TempDb after the execution of the sort operation. -- There is now activity in TempDb during the previous SELECT statement. SELECT num_of_writes, num_of_bytes_written FROM sys.dm_io_virtual_file_stats(DB_ID('tempdb'), 1) GO
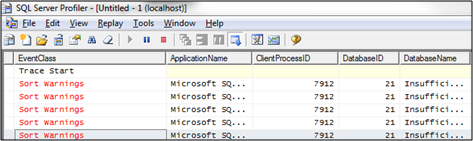
If you check the Estimated Number of Rows in the Execution Plan, they are differing completely from the Actual Number of Rows:
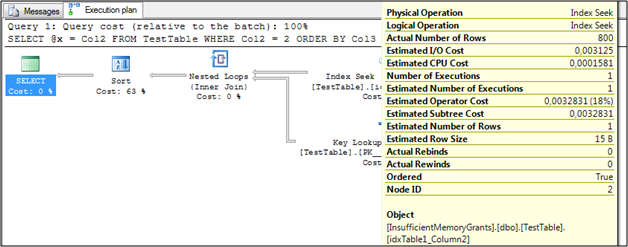
When you track the query execution time you will also see that the execution time increased – in my case it increased up to 200ms, which is a huge difference to the earlier execution time of just 1ms! The DMV sys.dm_io_virtual_file_stats will also report some activity inside TempDb, which is also the evidence that SQL Server spilled the Sort operation into TempDb! SQL Server Profiler will also show you a Sort Warning event.
If you now insert one additional record, and you run the query again, everything is fine, because SQL Server will trigger the Statistics Update and estimate the Query Memory Grant correctly:
-- Insert 1 records into table TestTable SELECT TOP 1 IDENTITY(INT, 1, 1) AS n INTO #Nums FROM master.dbo.syscolumns sc1 INSERT INTO TestTable (Col2, Col3) SELECT 2, REPLICATE(‘x’, 2000) FROM #nums DROP TABLE #nums GO -- Check the activity in TempDb before we execute the sort operation. SELECT num_of_writes, num_of_bytes_written FROM sys.dm_io_virtual_file_stats(DB_ID(‘tempdb’), 1) GO -- SQL Server has now accurate statistics and estimates 801 rows for the sort operator. -- SQL Server requests a memory grant of 6.656kb, which is now enough. -- SQL Server now spills the sort operation not to TempDb. -- Logical reads: 577 DECLARE @x INT SELECT @x = Col2 FROM TestTable WHERE Col2 = 2 ORDER BY Col3 GO -- Check the activity in TempDb after the execution of the sort operation. -- There is now no activity in TempDb during the previous SELECT statement. SELECT num_of_writes, num_of_bytes_written FROM sys.dm_io_virtual_file_stats(DB_ID(‘tempdb’), 1) GO
So this is a very basic example which shows you how you can reproduce Sort Warnings inside SQL Server – not really a magic. Adam Machanic (http://sqlblog.com/blogs/adam_machanic) has done last week at the SQLPASS Summit in Seattle a whole session about Query Memory at a 500 level, where he went into more details on this complicated topic, especially in combination with Parallel Execution Plans.
Thanks for reading!
-Klaus

 浙公网安备 33010602011771号
浙公网安备 33010602011771号