
【Weekly SQLpassion Newsletter】Understanding the Meltdown exploit – in my own simple words
As you might (hopefully) know, there was a serious CPU exploit(vt. 开拓;剥削;开采;漏洞;) exposed this week (called Meltdown(n. 灾难;彻底垮台;熔化;)), which will cause all Intel CPUs from the past 20 years to misbehave(vi. 作弊;行为不礼貌) and return you critical, private data from other applications or even other VMs in a virtualized environment.
The terrible thing about Meltdown is that the exploit is possible because of the underlying CPU architecture, and can’t be fixed within the CPU itself. It is more or less “By Design”. Therefore the CPU exploit must be fixed in the software layer itself, which could also slow down the throughput for specific workloads. Fortunately Microsoft, Linux, Apple and VMware have already provided necessary patches(n. 补丁;斑;小块) to their Operating Systems to make sure that the Meltdown exploit can’t be used.
In this blog posting I want to give you an overview about how the Meltdown exploit works internally. There is already a really great whitepaper available, which describes the inner workings of Meltdown on a deep technical level. I want to show you in this blog posting in my own simple words how Meltdown works, and how private data can be retrieved with it.
CPU Architectures
Before we talk about the Meltdown exploit itself, we have to know some basic things about how a modern CPU is architected and how a CPU is executing instructions. When you look at a high level at a CPU, it contains 2 very important components:
- Execution Units
- Registers
Execution Units are the brain of a CPU, because they are doing the real work. One example of an Execution Unit is the ALU – the Arithmetic Logic Unit – which performs arithmetical operations like adding and subtracting numbers. Most of the time when you execute an application (like when I’m writing this blog posting), the ALU of your CPU is heavily involved.
In addition to the various Execution Units, the CPU also needs some scratch space where temporarily data is stored. This scratch(n. 擦伤;抓痕;刮擦声;) space are the various CPU Registers. An x64 CPU has a lot of different registers available in which data is temporily stored to be able to perform actual operations on that data.
As soon some data is needed for an operation, the data is moved from the main memory (RAM) into a register, and after the operation the actual register content is written back into main memory. As I have written, the data in a register is only stored temporily during an operation. Imagine now you want to add 2 numbers which are stored in main memory:
int c = a + b;
If you take that simple C statement and assemble it down to some (pseudo(adj. 假的,虚伪的)) assembly code, the CPU has to execute the following instructions:
- LOAD Register1 from MemoryLocationA
- LOAD Register2 from MemoryLocationB
- Register3 = ADD(Register1, Register2)
- STORE Register3 in MemoryLocationC
So far so good. The problem with this simple approach is that accessing main memory introduces high latency(n. 潜伏;潜在因素) times. Main memory is based on DRAM cells, and accessing such DRAM cells takes some time. It can take up to 100 – 200 nanoseconds to access main memory. Each memory access will slow down your program execution.
Imagine accessing main memory has a latency of 100 nanoseconds, and we have a CPU of a clock rate of 1 GHz. In that case each CPU instruction would take 1 nanosecond to execute. But you have to wait for accessing main memory. Our instruction sequence would look like the following:
- Clock Cycle #1
- 1. LOAD Register1 from MemoryLocationA
- 2. // Now we wait 100 Clock Cycles for memory access…
- Clock Cycle #102
- 1. LOAD Register2 from MemoryLocationB
- 2. // Now we wait 100 Clock Cycles for memory access…
- Clock Cycle #203
- 1. Register3 = ADD(Register1, Register2)
- 2. // No memory access, no waits…
- Clock Cycle #204
- 1. STORE Register3 in MemoryLocationC
- 2. // Now we wait 100 Clock Cycles for memory access…
- Clock Cycle #305 3. Next Instruction…
As you can see from this simple example, our 4 assembly instructions took 304 clock cycles for execution. And from these 304 clock cycles we have waited 300 clock cycles – 300 nanoseconds. This approach doesn’t really work quite well from a performance perspective(n. 透镜,望远镜;观点,看法;). A CPU works around this problem in multiple ways:
- CPU Caches
- Pipelining(n. 流水线;管道安装)
- Speculative(adj. 投机的;思考的;推理的,揣摩的) Execution
Let’s have a more detailed look on them.
CPU Caches and Pipelining
A modern CPU has a lot of different CPU caches, which are fast and quite small compared to our large main memory (RAM). The following picture gives you a high level overview about the various caches that are part of a modern CPU.

The idea of a CPU cache is that we cache in small, fast SRAM memory cells the most recently used that from main memory. Therefore we don’t need to wait always on main memory access. If you access data, which is not yet cached in a CPU cache, you have a so-called Cache Miss, and the data must be transferred from main memory into the individual CPU caches. And as we now already know this takes some time, and slows down your CPU.
And because of this, a CPU is able to schedule other work in the meantime when you wait on something – like main memory access. A CPU is based internally on so-called Pipelines, which are filled up with CPU instructions(n. 授课;教诲;[计算机科学]指令;) that must be executed. Let’s imagine a very simplified CPU with a simple Three-Stage-Pipeline (in reality a CPU Pipeline has a lot more stages):

In each individual stage the CPU performs something with your instruction. The more stages your CPU has, the more work can be done in parallel. With a Three-Stage Pipeline you can execute 3 Instructions in parallel. Therefore you are speeding up your CPU.
As long as you have serial stream of CPU instructions to execute, a pipelined CPU is great. But the reality is quite different. Imagine your program code has to branch to somewhere else:
if (x > 0) { InstructionStream #1 } else { InstructionStream #2 }
With which instruction stream would you built up your CPU pipeline? Instruction Stream #1 or Instruction Stream #2? The CPU can’t know it ahead of time, because the CPU can’t evaluate(vt. 评价,估价;对…评价;) the if statement ahead of time. Therefore each modern CPU has a so-called Branch Predictor, which just makes an educated (and normally good) guess which Instruction Stream will be executed. With this approach you can avoid a so-called Pipeline Flush. A Pipeline Flush just means that the CPU has mispredicted how the if statement evaluated, and therefore the CPU has to discard work that was already done in the CPU pipeline.
Yes, you have read correct: work that was already speculatively(adv. 思考地,思索地;投机地) executed, is just undone! It’s the same as when you rollback a transaction in a database. Your database end up finally with a consistent state, and the CPU end up also with a consistent state.
This sounds again so far so good. But imagine that the CPU has executed an instruction which has read some memory into a CPU register. In that case, the performed work is undone, and the CPU registers are again in a consistent state. But the data that was retrieved from main memory is still stored in the CPU cache. The CPU cache itself is *NOT* flushed, because that would be too expensive. And that’s now the attack vector of the Meltdown exploit.
Speculative Execution
Let’s have a look at the following high level code:
// Do some work // ... // Access some protected Kernel Memory // This triggers an Access Violation Exception!!! LOAD Register1, [SomeKernelMemoryAddress] // This code is never, ever reached! Is it? LOAD Register2, [BaseArrayAddress + Register1]
The code is quite simpe:
- We perform some general work
- We try to access a protected Kernel Memory Address. This triggers an Access Violation(n. 违反,妨碍,侵犯;违犯,违背;) Exception
- After the Access Violation Exception we do further work…
Let’s concentrate on the first 2 steps. I will cover the last LOAD Register2operation afterwards. With our current knowledge about programming we all have to agree that the last LOAD Register2 operation is never ever executed, because it is *unreachable*. It’s unreachable, because accessing a protected Kernel Memory Address triggers an Access Violation Exception, which finally terminates(vt.& vi. 结束;使终结;解雇;) in the worst case our program. Logically we are all correct, but on the physical level the CPU is doing something else…
As I have said the CPU has to build up the instruction pipeline to be able to execute as many instruction as possible in parallel. Therefore the CPU *also executes* the code path *after* the thrown Exception, because we must keep the CPU pipeline full. And when the exception was thrown, the already done work is undone to leave the CPU in a consistent state.

The CPU just assumes (yes, it’s just an assumption!) that the Access Violation Exception is not thrown and builds up the CPU pipeline for further execution. The CPU wants to keep the pipeline as full as possible. This is more or less a Branch Misprediction. And therefore the CPU has executed speculatively a CPU instruction which was not necessary (LOAD Register2). But the CPU is still in a consistent state, because the work that was speculatively done, is just undone. So the CPU registers have their initial, correct values, and there is no indication that the LOAD Register2 operation ever happened. Everything is fine. NO!
The real problem lies in the underlying CPU caches. The Access Violation Exception is not triggered immediately, because it has to go through the CPU pipeline for execution. And in parallel the CPU is again building up the pipeline and just schedules and execute the LOAD Register2operation.
The CPU just assumes that we *can* access the protected Kernel Memory Address (it’s just an assumption, nothing else), and based on that assumption the CPU pipeline is filled up with the next instruction (LOAD Register2). And this next instruction is finally executed – and afterwards undone. But there is now a problem: the data that we have speculatively read into Register2, is still in the CPU caches! When the CPU is undoing some work, the CPU caches are *not flushed*, because this would be a huge overhead for all subsequent instructions. Because they have to read the data again from main memory, and as we know this takes some time…
The Meltdown Exploit
And that’s now the attack vector of the Meltdown exploit. The CPU can read some data from a protected Kernel Memory Address, and still stores the data in the CPU caches after the speculative work was undone. But how can you use that “behavior” to transfer protected Kernel Data into an application? You have to be creative and use the fact that CPU cache access is fast, and main memory access is slow.
Imagine you want to leak(vt. 使渗漏,泄露) some protected Kernel Memory Data into a user application. To make things quite easy I assume that our Kernel Memory region only consists of 5 bytes that we want to leak:
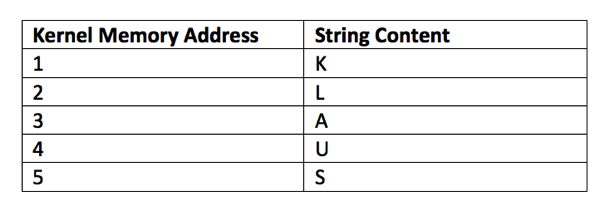
As you can see we are storing the string value of KLAUS in the Kernel Memory Addresses 1, 2, 3, 4, 5. These values are just ASCII Codes in memory. When you do a lookup of these ASCII codes to their corresponding(adj. 相当的,对应的; 通信的; 符合的,符合) decimal values, you get the following data in the Kernel Memory region:
// Do some work // ... // Access some protected Kernel Memory // This triggers an Access Violation Exception!!! LOAD Register1, [SomeKernelMemoryAddress] // This code is never, ever reached! Is it? LOAD Register2, [BaseArrayAddress + Register1]
The brackets(n. 支架;括号;) around [SomeKernelMemoryAddress] just mean that we want to perform an Indirect Memory Addressing operation. We tell the CPU to read the data into Register1 which is stored at the memory location [SomeKernelMemoryAddress]. Let’s substitute(vi. 替代 | vt. 代替) [SomeKernelMemoryAddress] with a real Kernel Space memory address from our example:
// Access some protected Kernel Memory // This triggers an Access Violation Exception!!! LOAD Register1, [1]
In our case we want to load from the memory location 1 the decimal value 75 into Register1. This will trigger the Access Violation Exception – but not immediately (because of the Pipelining), because the CPU speculatively executes the following next instruction:
// This code is never, ever reached! Is it? LOAD Register2, [BaseArrayAddress + Register1]
As you can see here, we perform again an Indirect Memory Addressingoperation to load Register2. We have here some array declared – at the *User Space* memory address BaseArrayAddress. Let’s assume BaseArrayAddress is stored at the User Space memory address 100. Let’s look again at the code with substituted values:
// This code is never, ever reached! Is it? LOAD Register2, [100 + 75]
If we do the math, we get the following code:
// This code is never, ever reached! Is it? LOAD Register2, [175]
We just load the memory content from the User Space memory address 175 into Register2. This is a completely different memory content and has nothing in common with the content from the Kernel Memory space. We have never, ever read any data from Kernel Memory, because the CPU protects it with the Access Violation Exception. We are still in *User Space Land*! This is very important!
We have just used the data from the Kernel Space Memory Address as an index pointer into an array which is stored in the User Space memory.
When you now try to read 1 byte (8 bits) from protected Kernel Memory space, you can end up with 256 possible index pointers (2 ^ 8), and therefore with 256 possible LOAD Register2 operations depending on which content was stored at the protected Kernel Memory space.
LOAD Register2, [100 + 0] LOAD Register2, [100 + 1] LOAD Register2, [100 + 3] ... ... ... LOAD Register2, [100 + 253] LOAD Register2, [100 + 254] LOAD Register2, [100 + 255]
Again, the LOAD Register2 operation will be later discarded by the CPU, because of the Branch Misprediction. But the data is still in the CPU caches. But you can’t access the data from the CPU caches, because this is technically not possible.
But there is a “work-around” for this technical limitation: we can measure in a separate thread how long the memory access for all 256 possible array entries takes. If the access is slow, the data is fetched from main memory, if the access is fast, the data is fetched from the CPU caches. Let’s try this:
LOAD AnotherRegister, [100 + 0] SLOW LOAD AnotherRegister, [100 + 1] SLOW LOAD AnotherRegister, [100 + 3] SLOW ... ... ... LOAD AnotherRegister, [100 + 73] SLOW LOAD AnotherRegister, [100 + 74] SLOW LOAD AnotherRegister, [100 + 75] FAST! LOAD AnotherRegister, [100 + 76] SLOW LOAD AnotherRegister, [100 + 77] SLOW ... ... ... LOAD AnotherRegister, [100 + 253] SLOW LOAD AnotherRegister, [100 + 254] SLOW LOAD AnotherRegister, [100 + 255] SLOW
When you probe all 256 possible array entries, and measure the latency time you can see exactly which entry was cached by the previous code. In our case it was the entry 175. If we subtract(vt. 减去;扣掉) the base memory address of our array (in our case 100), we get the value 75. And the value 75 is the ASCII code for the character ‘K’. Congratulations, you have just leaked a byte value from the protected Kernel Memory space into a User application. That’s Meltdown!
If you try to access *every* possible Kernel Memory Address (which generates an Access Violation Exception), and do for each possible Kernel Memory Address the needed 256 probe operations, you can ultimately(adv. 最后;根本;基本上) dump the *whole* Kernel Memory into your User application. This is a really serious threat. As you have seen, you don’t need to do anything in Kernel Mode, because the whole exploit is done within the User Mode.
Summary
I hope that this blog posting gave you a better understanding about how Meltdown is working on technical level. As I have said in the beginning of this blog posting, I have generalized here a lot of different things, and this blog posting is in no way an accurate description how a CPU works internally. In addition the exploit is much harder to accomplish(vt. 完成;达到(目的);), because you have to ensure that no data is cached in the CPU caches (besides the leaked array entry) when you probe the array. Everything in this blog posting was just heavily simplified to make it possible to describe Meltdown on an easier level.
If you want a more technical accurate description of Meltdown, I highly suggest to read the official whitepaper, which was also my source of information (in addition to the Wikipedia article). I also want to thank Moritz Lipp, Michael Schwarz, and Daniel Gruss from the TU Graz, who have encountered(v. 遭遇;遇到) Meltdown (and also Spectre(n. 幽灵;鬼怪;)). You have done here a really amazing work. These days I’m really proud to be an Austrian

 浙公网安备 33010602011771号
浙公网安备 33010602011771号