Python基础概念_1.字符&编码&语言特性
引子
基础不牢,地动山摇,从头捋知识点,简明扼要。在记录字符和编码前,需要先明确两个名词,字节和字符分别是什么?
字节(Byte)是计量单位,用于计算机信息技术计量存储容量,八个二进制位是一个字节
字符,是指计算机中使用的文字和符号,比如 1、2、A、B、C、~!·#¥%……—*()——+、等等。
说清楚这两点就好办了,字符是我们能看到的;字符要存储,在某种刻度下,是以字节为单位保存的。
字符集和编码规则
进入正题,字符以字节为单位存储,字符集和编码规则定义存储模式。通过utf8和unicode的对比,切入和阐述。
unicode是"字符集",为每一个"字符"分配唯一的ID(学名为码位/码点/Code Point),理解为编号。
utf-8是"编码规则",将"字符集"转换为"字节"序列的数据(编码/解码可理解为加密/解密过程,具体在后边说)
广义上unicode是个标准,定义了一个"字符集"和一系列"编码规则",即Unicode"字符集"和utf-8"编码规则"
而utf-8是一套以八位为一个编码单位的,可变长编码。变长指的是会将一个码位,编码为1到4个字节。
综上,"字符"转为"字符集","字符集"按"编码规则"编译成1到4"字节"的二进制位。unicode和utf8不平级
编码详解
python、unicode、utf8,以及ascii、gbk、utf16...的关系在后边,这里说的是编码的规则
unicode为每个字符分配了一个唯一的数字编号,一般写成16进制(0x000000 到 0x10FFFF),前面加上U+
utf-8是使用变长字节表示,顾名思义,字节数可变。这个变化是根据unicode编号的大小有关.
单字节符号,如英文字母,字节(00000000)的第一位是0,后7位是符号的unicode 码;其他长度规则见图
另,unicode吸纳了ascii码(就1个字节,表示英文), 因此对于英文字母,utf-8编码和ascii码是相同的.
unicode每个符号用多个字节(目前最大4字节),对于英文字母,只占用1字节,对存储空间来说是极大的浪费
而unicode只规定了每个字符的数字编号是多少,并没规定这个编号如何存储,可以是utf8、ascii、gbk....
下图展示,unicode如何以utf8形式进行存储的,简单说,通过0、10、110、1110占位区分长度
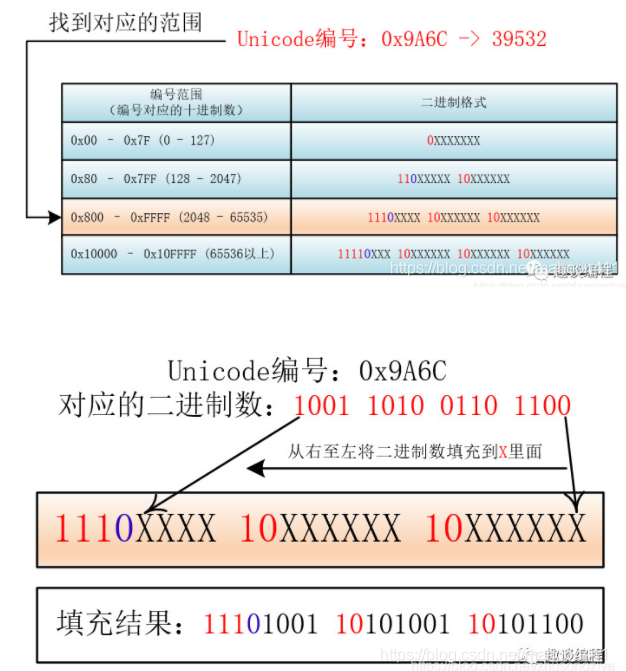
"编码"方式
- ascii 只能编码英文和特殊符号;1个字节,8位
- unicode 初始2字节,16位;中文不够,新符号不够,扩展到4字节,32位;
- utf8(..) 可变长编码;1字节表示英文;2字节欧洲;3字节亚洲
- gbk 国产编码,只用于中文和ascii中的文字;英文1个字节,中文2个字节
我之前把unicode和各种编码方式混为一谈,多年来,看似懂了,回头就忘了、懵了,这次算彻底整理出来了。还不急总结,继续...
python编码
铺垫差不多了,该把python放进来了。python保存数据,字符转字符集,字符集选一种编码保存;简单?实则:
python2默认编码是ascii,python3默认是utf8;过程遇到乱码需要在文件头加 # -- coding:utf-8 --
当然,还可以写成 # coding:utf-8 ;这就完了? 还没,继续继续
在python2中,字符序列严格是有4种,大体说两种,str和unicode;python3中有两种,bytes和str
干嘛的?简单说,数据的保存和传输,需要用二进制格式。也就是说,呈现给我们看的,是另一种形式的数据。
python2比较混乱,str字面意思是字符串,实际在2中是python3中的bytes,是用来传输和保存数据的。
而在2中,unicode对应的是3中的str,展示给用户看的。有点乱,2乱,我写着都快乱了。还是用3说:
python3理清除了,把str和bytes彻底分开了。bytes用来存储传输,用哪种(utf、gbk)编码? bytes不关心。
感觉可以总结了,在3中,字符以str形式展示,它以unicode字符集进入内存,而存储和传输以某一种编码方式编成bytes传输、存储
默认情况,3中是以utf-8形式编码和解码;而2中是以ascii默认编码解码;至于2中其他细节,就先不写了,反正也很难用到了
关于utf-8,utf8,utf8mb4,utf16,utf32,gbk...简要整理;而对于python语言的特性,也是简要说明
补充:python2存数据的时候,在字符串前加u
python2中使用 sys.setdefaultencoding('utf-8') 解决 UnicodeDecodeError
bytes数据类型操作和使用,甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象
python2可通过 --enable-unicode=ucs2或ucs4,指定2字节或4字节; sys.maxunicode 结果 65535
python3在编译安装时,默认指定4个字节表示1个unicode字符,ucs4;sys.maxunicode 结果 1114111
decode和encode
# decode的作用是将二进制数据解码成unicode编码,如str1.decode('utf-8')
# encode是将unicode编码的字符串编码成二进制数据,如str2.encode('utf-8')
编码和解码
1、对于英文
str 表现形式 s = "sm" 编码方式 01000010 unicode
bytes 表现形式 s = b"sm" 编码方式 01010000 utf-8 gbk...
2、对于中文
str 表现形式 s = "哈" 编码方式 00100001 unicode
bytes 表现形式 s = b"x\e81\e01" 编码方式 01000101 utf-8,gbk
* \中间 一个代表一字节 3字节是utf-8 2字节是gbk
3、bytes的表现形式
s = "sm"
s = b"sm"
s = "什么"
s = b"什么" # 这里会报错
print(s, type(s))
s = "sm"
s = s.encode("utf-8") 编码,将str转换成bytes
s = s.encode("gbk")
s = "什么"
s = s.encode("utf-8")
s = s.encode("gbk")
print(s, type(s))
b = b"" #创建空的bytes
b = bytes() #创建空的bytes
b = b"hello" #指定这个hello为bytes类型
b = bytes("str", encoding="编码类型") #利用内置的bytes方法,将字符串转换为指定编码的bytes
b = str.encode(”编码类型“) #利用字符串的encode方法编码成bytes,默认为utf-8类型
b = bytes.decode("编码类型") #将bytes对象解码成字符串,默认使用utf-8进行解码
utf8mb4补充
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。
utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需做其他转换。为了节省空间,一般情况使用utf8也就够了
utf8是utf-8的简写,window和mysql都能正常识别;而utf8每次传1个字节,16传2个字节,类推;utf8可变长
语言类型
python是动态强类型解释性语言
-
动态:执行期间检查数据类型的语言
-
强类:强制数据类型的语言
-
解释:边执行边编译
python之禅
>>> import this
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
堆和栈
python传值都是指向内存地址,有人说python的传递都是引用传递,与其他语言不同。
栈区存放的是变量名与内存地址的对应关系,简单理解为存放变量名;堆区存放的是变量值
违背禅宗的提示信息
def a(name:'提示信息')->int:
print(name)
a('wg')
print(a.__annotations__)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号