【Python的pip】Python 安装(Win10), pip 设置国内镜像源&升级
首先配置python3环境
1.python源:https://www.python.org/(最好是下载高版本)
2.下载安装脚本启动安装,并点选添加python到PATH(环境变量)
3.验证:管理员启动cmd(Powershell),输入 python --version 或者 python -V
pip安装
1.pip安装脚本下载:https://mirrors.aliyun.com/pypi/get-pip.py
2.执行:python3 get-pip.py
3.验证:pip --version
4.修改pip源到国内
1>管理员启动cmd
2>换源:pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
3>更新源:python -m pip install --upgrade pip
#备选
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple
华中理工大学:http://pypi.hustunique.com
山东理工大学:http://pypi.sdutlinux.org
豆瓣:http://pypi.douban.com/simple
python应用1:将png转换为ico文件
一步一步实现:
1.使用以下cmd安装Pillow库。
2.使用open()方法,加载需要转换为ICO文件的png文件。
3.使用保存方法并将格式设置为ICO,这将转换图像并保存在给定的路径中。
示例 :
将PNG转换为ICO。
from PIL import Image
logo = Image.open("C:\\Users\\pulamolu\\Desktop\\geeks_dir\\gfgLogo.png")
logo.save("C:\\Users\\Desktop\\geeks_dir\\gfgLogoIco.ico",format='ICO')
//也可以添加尺寸
logo.save("C:\\Users\\Desktop\\geeks_dir\\gfgLogoIco.ico",format='ICO',sizes=[(40, 40)]);执行 Python 脚本
要执行Python脚本,您需要有Python解释器安装在您的系统上。如果您已经安装了Python(版本3.x或更高),您可以通过命令行运行Python脚本。以下是如何执行Python脚本的步骤:
1. 打开命令行界面(在Windows上是CMD或PowerShell,在MacOS或Linux上是终端)。
2. 使用cd命令导航到包含您Python脚本的文件夹。
3. 运行脚本,使用以下命令:
python script_name.py
或者,如果您的系统上安装了Python 3,并且同时安装了Python 2,您可能需要使用:
python3 script_name.py
python应用2:将\x 开头编码的数据(utf-8编码)解码成中文
在宾馆让单片机连wifi,可惜不能显示汉字,显示都是utf-8码:
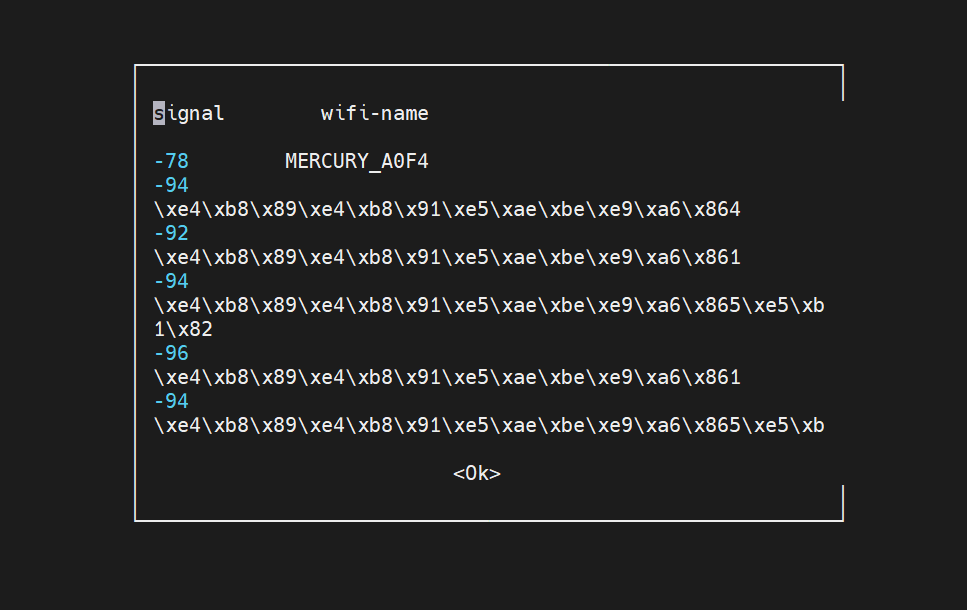
可以用python解读这些 \x开头的字符串,比如第一个\xe4\xb8\x89\xe4\xb8\x91\xe5\xae\xbe\xe9\xa6\x864
可以在python 输入以下命令:
先把错误的方式展示给你:
# 错误的使用方式
s = "你好世界"
decoded_s = s.decode("utf-8") # 这里会抛出错误
'str' object has no attribute 'decode'. Did you mean: 'encode'?这个错误表明你试图在一个字符串('str' object)上调用decode方法,但是字符串类型没有decode方法。decode方法通常用于字节串(byte string),即类型bytes。这个错误提示还建议你可能想要调用的是encode方法,该方法用于将字符串转换为字节串。
解决方法:
-
如果你的目的是将字节串转换为字符串(通常用于解码操作),确保你在一个字节串上调用
decode方法。 -
如果你的目的是将字符串转换为字节串(通常用于编码操作),确保你在一个字符串对象上调用
encode方法。
正确的方式
# 正确的使用方式
# 将字符串转换为字节串
encoded_s = s.encode("utf-8")
# 将字节串解码为字符串
decoded_s = encoded_s.decode("utf-8")所以正确的办法应该是:
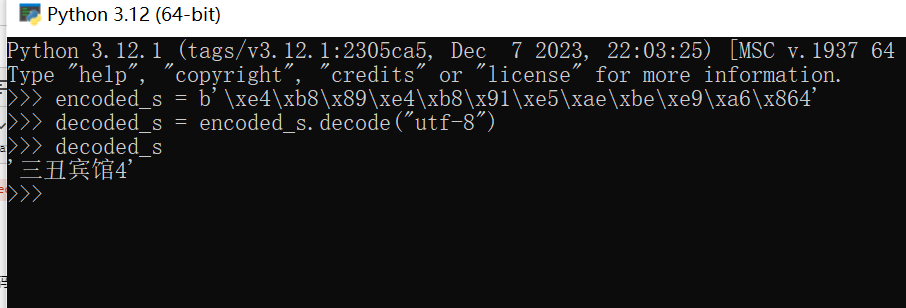
# 以文章的案例,测试
encoded_s = b'\xe4\xb8\x89\xe4\xb8\x91\xe5\xae\xbe\xe9\xa6\x864' #字节串以 b开头
decoded_s = encoded_s.decode("utf-8")结果如下:
参考文章:
1. https://blog.csdn.net/Franciz777/article/details/123383103
2. https://blog.csdn.net/qq_41641505/article/details/136989924
3. 《将\x 开头编码的数据(utf-8编码)解码成中文》https://www.cnblogs.com/xiaoqi/p/5101795.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号