pythonUI自动化之POM底层框架
1. pythonUI自动化之组成结构
python+pytest+allure+POM
python:编程语言
pytest:单元测试框架
allure:测试报告
POM:页面对象模型
2. pythonUI自动化之POM测试框架目录
1. base文件夹:基类,用于配置元素操作,如获取元素、输入、点击、等待等函数 2. pages_object文件夹:页面对象类,用于存放每个页面的操作对象,这也是POM框架的核心内容 3. test_cases文件夹:测试用例。每个测试用例应该单独成为一个py文件,并按照逻辑进行组织。可以根据项目需求创建不同的子文件夹来分类管理测试用例。 4. utils文件夹:用于存放工具函数或者公共方法。在编写测试时,可能会使到一些重复性高且与特定页面无关的功能,可以将其提取为工具函数并放入此文件夹中。 5. data文件夹:测试数据存放目录 6. configs文件夹:用于存放配置文件。如果需要修改测试运行参数或者设置全局变量,可以将其保存在配置文件中,然后在测试过程中引用。 7. reports文件夹:用于生成测试报告。当测试完成后,可以将测试结果输出为HTML格式的报告,并保存在此文件夹中。 8. main.py文件:主程序入口点。所有的测试任务从此处开始执行,可以选择指定要运行的测试用例集合或者整个测试模块。 9. requirements.txt文件:记录了项目所需的第三方库及版本号。可以使用pip命令安装所列出的库。 10. .gitignore文件:Git版本控制系统的忽略文件,用于指定哪些文件/文件夹不被添加到版本控制中。 11. README.md文件:项目说明文档,介绍项目名称、目录结构、使用方法等内容。
1. base文件夹:基类,用于配置元素操作,如获取元素、输入、点击、等待等函数
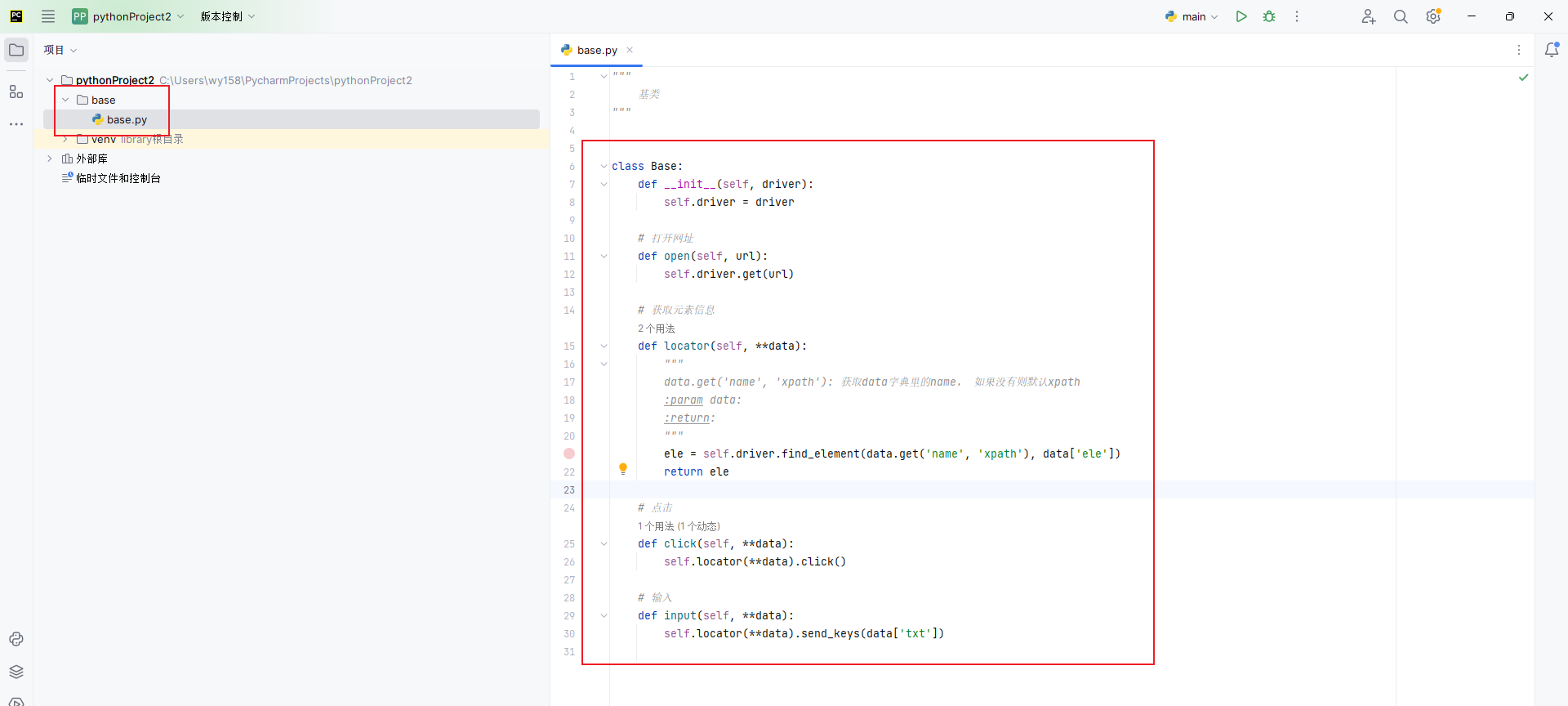
""" 基类 """ class Base: def __init__(self, driver): self.driver = driver # 打开网址 def open(self, url): self.driver.get(url) # 获取元素信息 def locator(self, **data): """ data.get('name', 'xpath'): 获取data字典里的name, 如果没有则默认xpath :param data: :return: """ ele = self.driver.find_element(data.get('name', 'xpath'), data['ele']) return ele # 点击 def click(self, **data): self.locator(**data).click() # 输入 def input(self, **data): self.locator(**data).send_keys(data['txt'])
2. pages_object文件夹:页面对象类,用于存放每个页面的操作对象,这也是POM框架的核心内容。自动化是否做的好,全看页面是否维护的好
假设整个系统只有(登录)和(用户)两个模块, 而(用户)模块的核心功能是(新增用户)和(删除用户), 而你想设计两条用户, 一条新增用户, 一条删除用户,那么页面对象你就可以这么设计
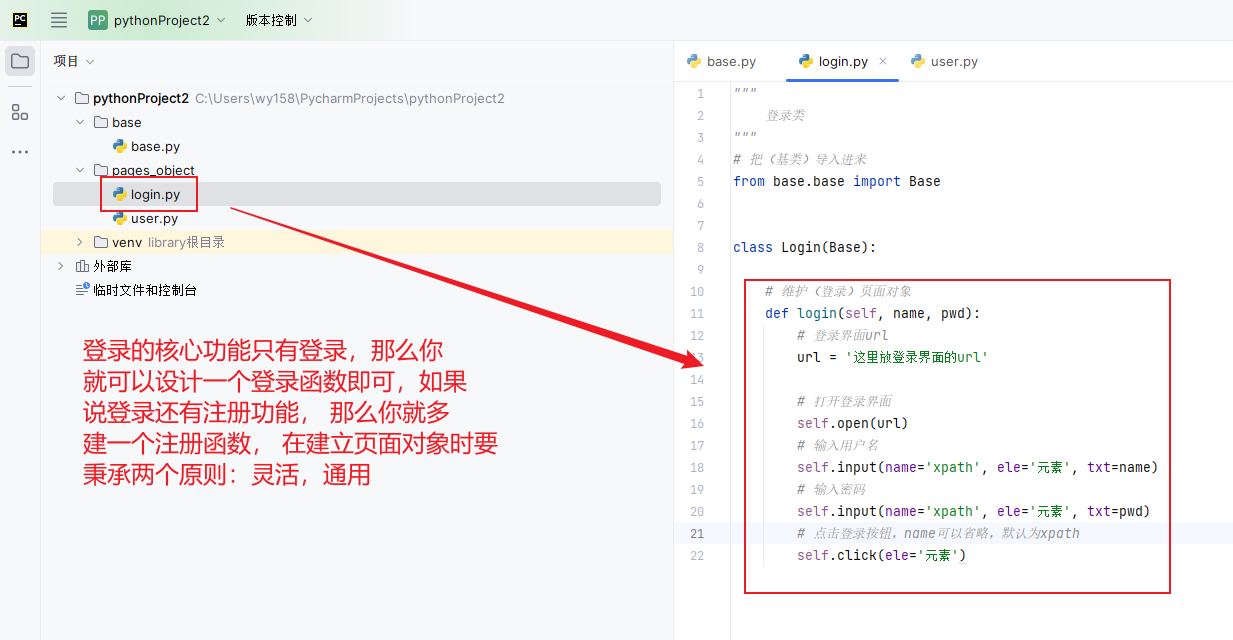
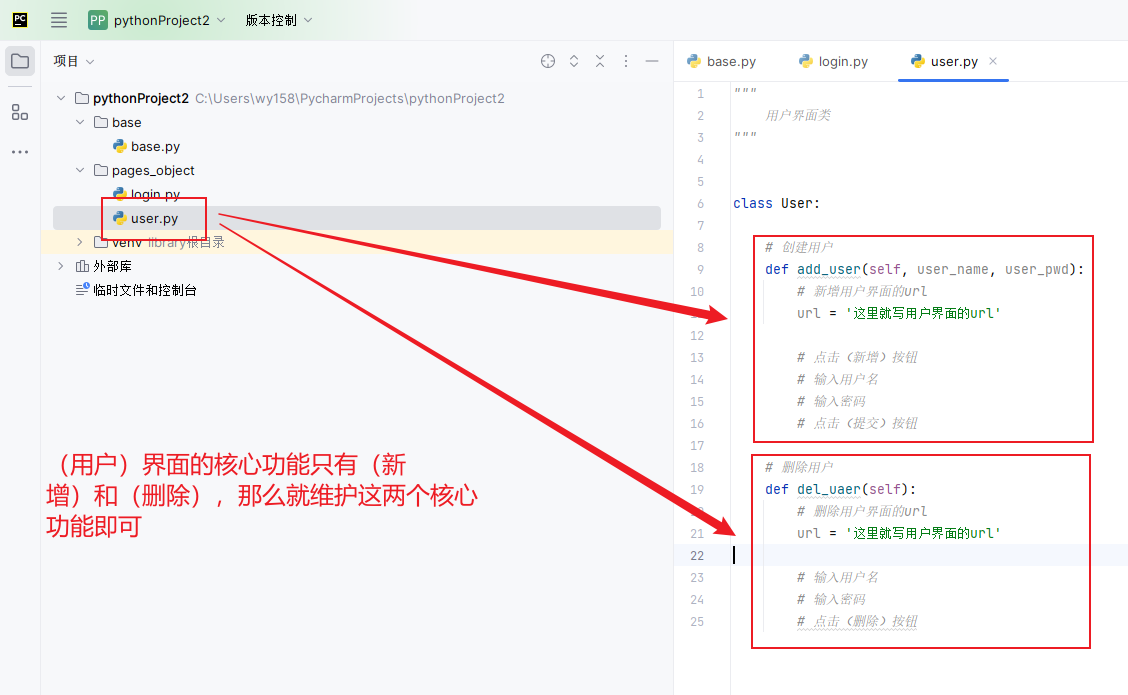
接下来就可以设计我们的用例了:
用例1:新增用户
用户2:删除用户
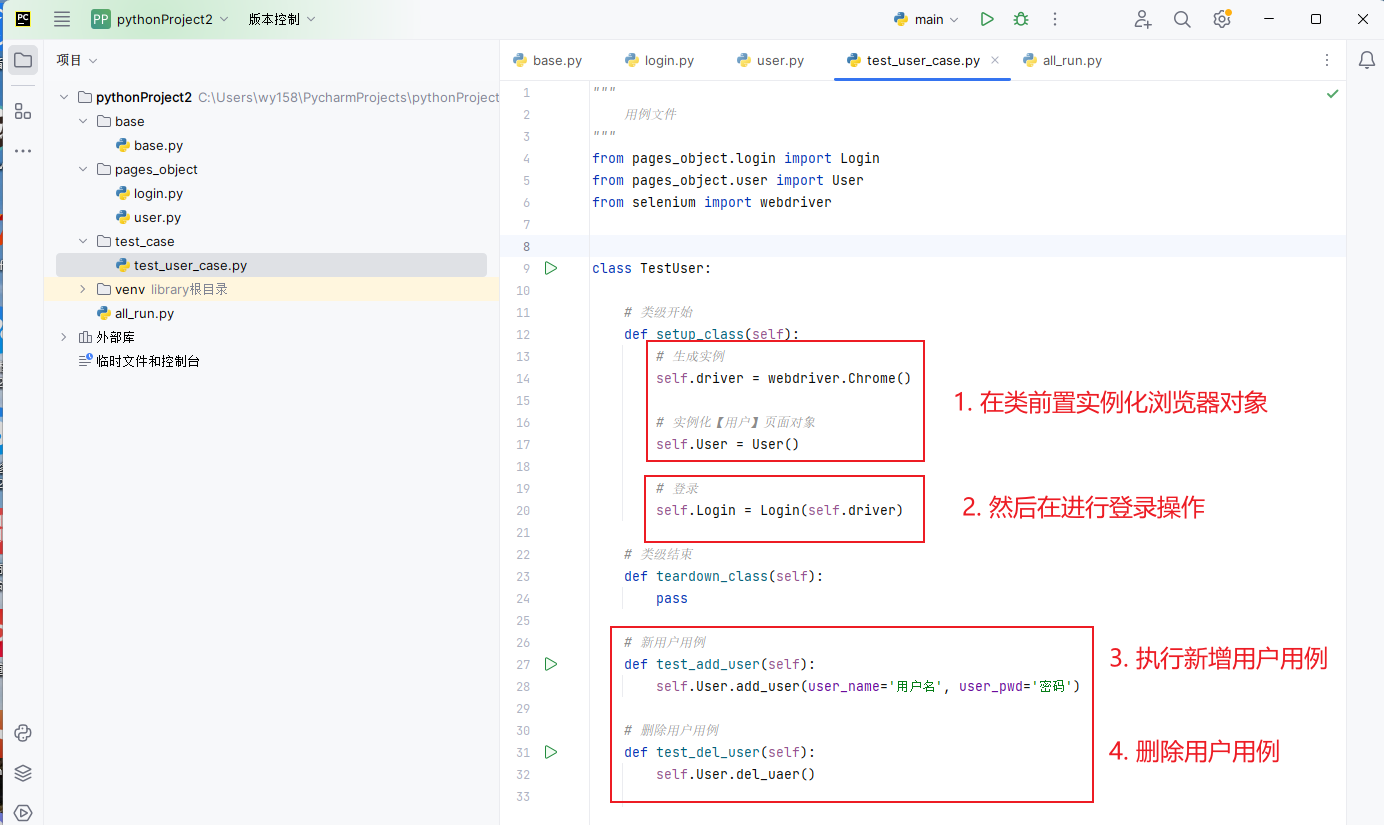
3. test_cases文件夹:测试用例。每个测试用例应该单独成为一个py文件,并按照逻辑进行组织。可以根据项目需求创建不同的子文件夹来分类管理测试用例。
4. configs文件夹:配置文件。可以将浏览器启动配置,数据库启动配置等其他配置都放到这个文件中
假如在以上用例中,我想让浏览器启动时就开启无痕模式,该怎么做?
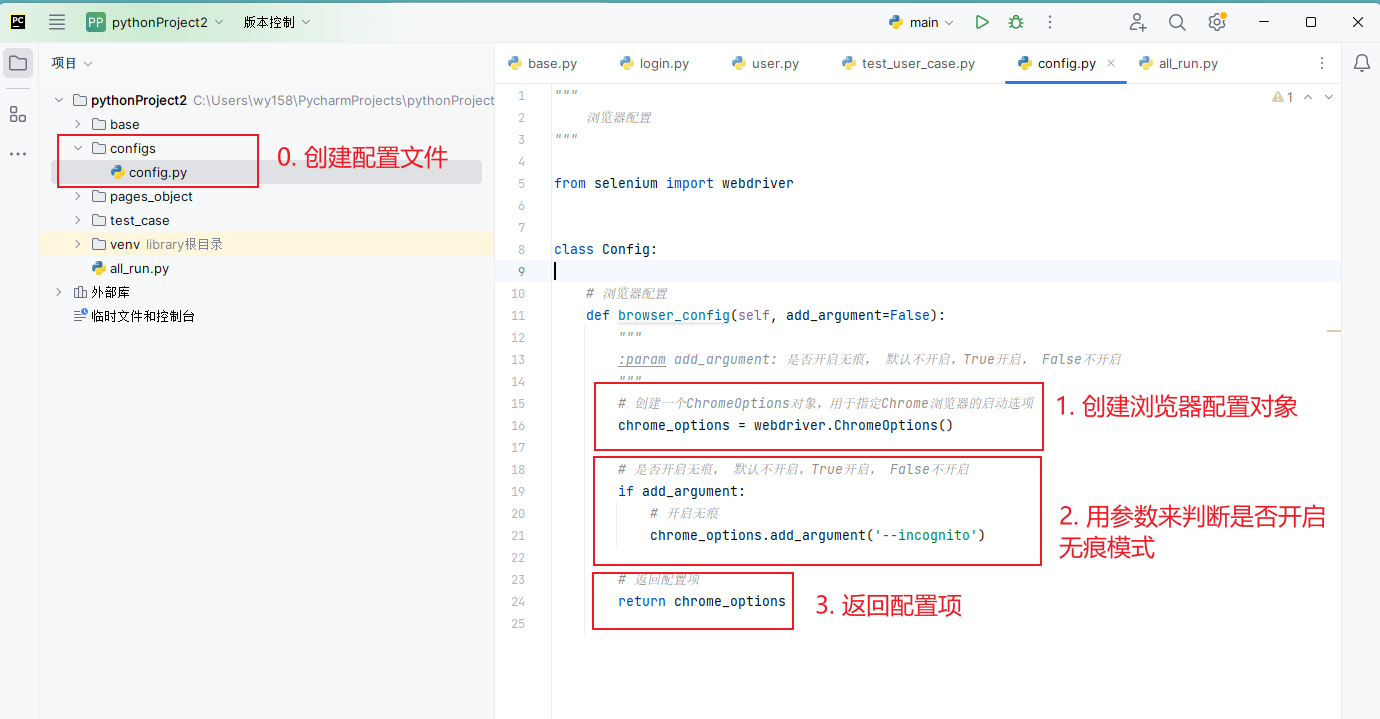
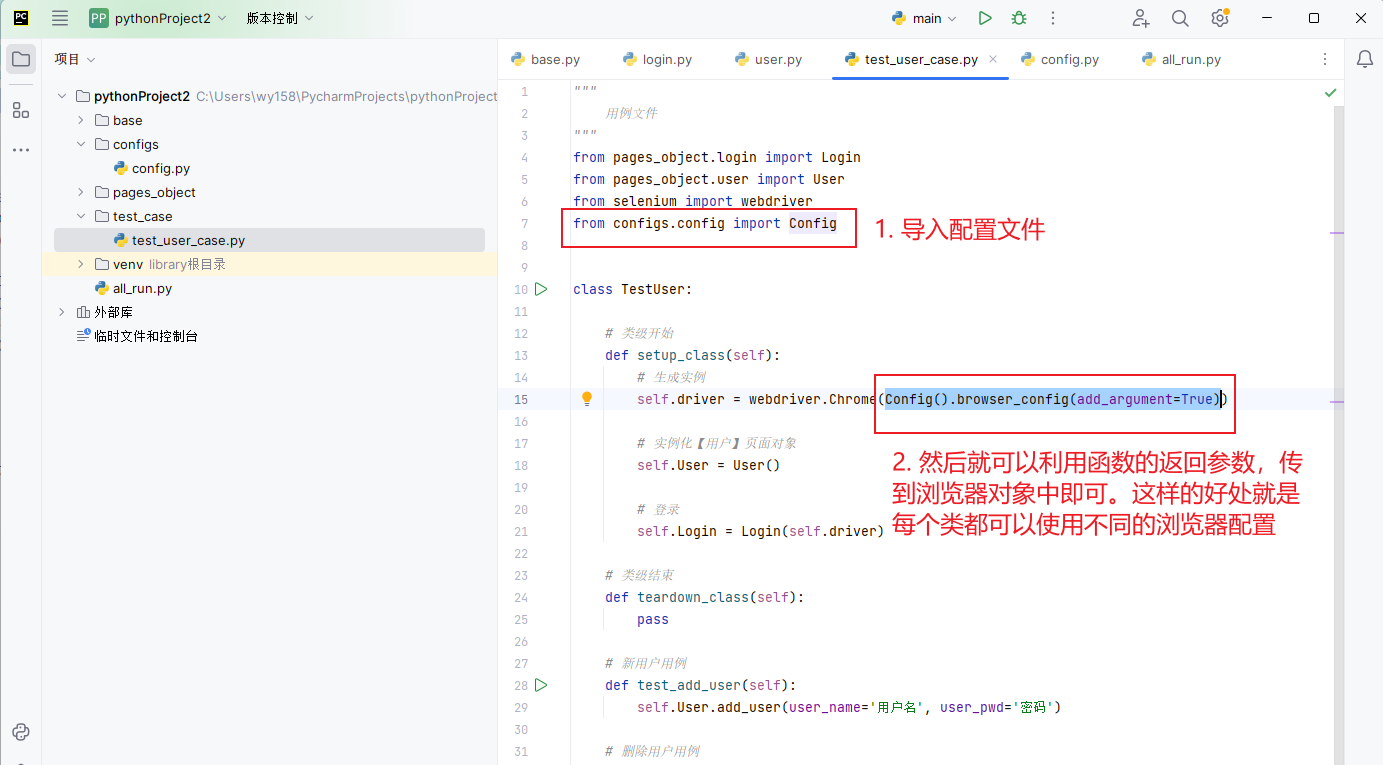
然后如何导入使用呢?如下
5. main.py文件:主程序入口点。所有的测试任务从此处开始执行,可以选择指定要运行的测试用例集合或者整个测试模块。
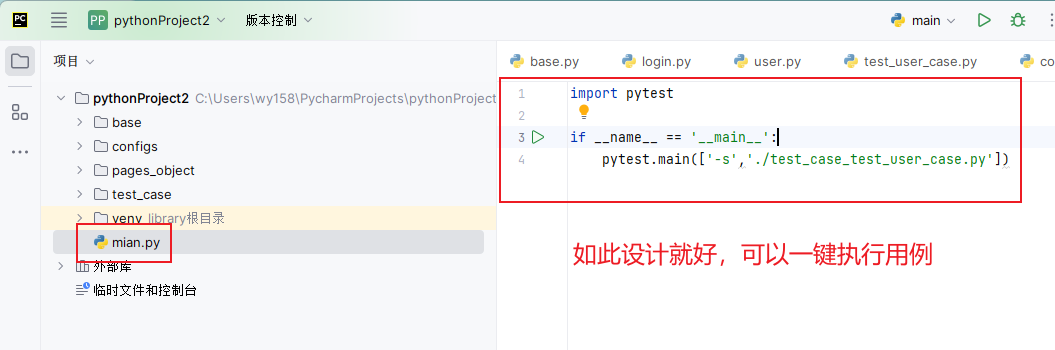
这个是所有用例的执行文件,相当于用例执行开关,如何设计呢? 比如这里使用的是pytest
6. utils文件夹:工具文件。在编写测试时,可能会使到一些重复性高且与特定页面无关的功能,可以将其提取为工具函数并放入此文件夹中。
这个相当于一个工具文件, 比如用例有可能用到正则表达式、特殊计算公式、替换等功能时,都可以封装在这个文件中。该文件暂不代码展示
7. reports文件夹:测试报告。当测试完成后,可以将测试结果输出为HTML格式的报告,并保存在此文件夹中。
测试报告文件, 这里使用的是allure报告,对于如何使用安装allure报告, 可以看这篇文章:https://www.cnblogs.com/FBGG/p/15491711.html
8. main.py文件:主程序入口点。所有的测试任务从此处开始执行,可以选择指定要运行的测试用例集合或者整个测试模块。
如果想把allure测试报告结合到该文件来, 请看该文章:https://www.cnblogs.com/FBGG/p/15491711.html
想查看该文件更多用法,请看该文章:https://www.cnblogs.com/FBGG/p/15670922.html

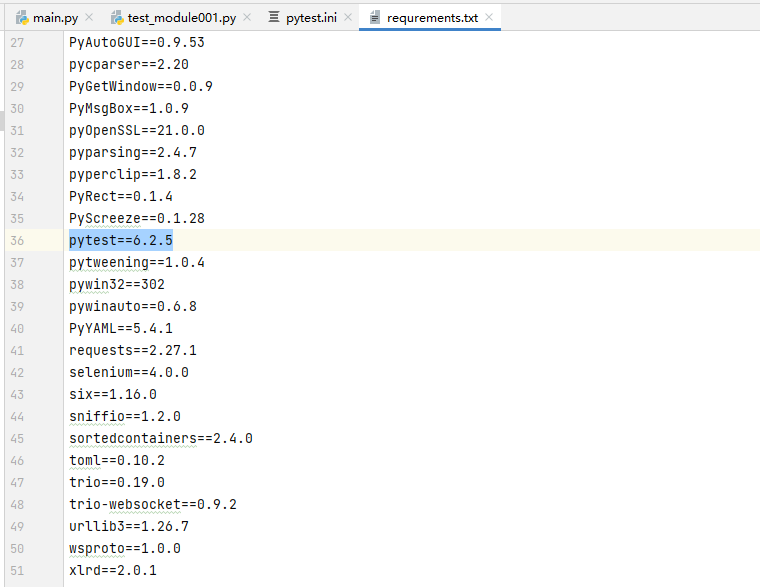
9. requirements.txt文件:记录了项目所需的第三方库及版本号。可以使用pip命令安装所列出的库。
详细用法请看该文章:https://www.cnblogs.com/FBGG/p/16244902.html
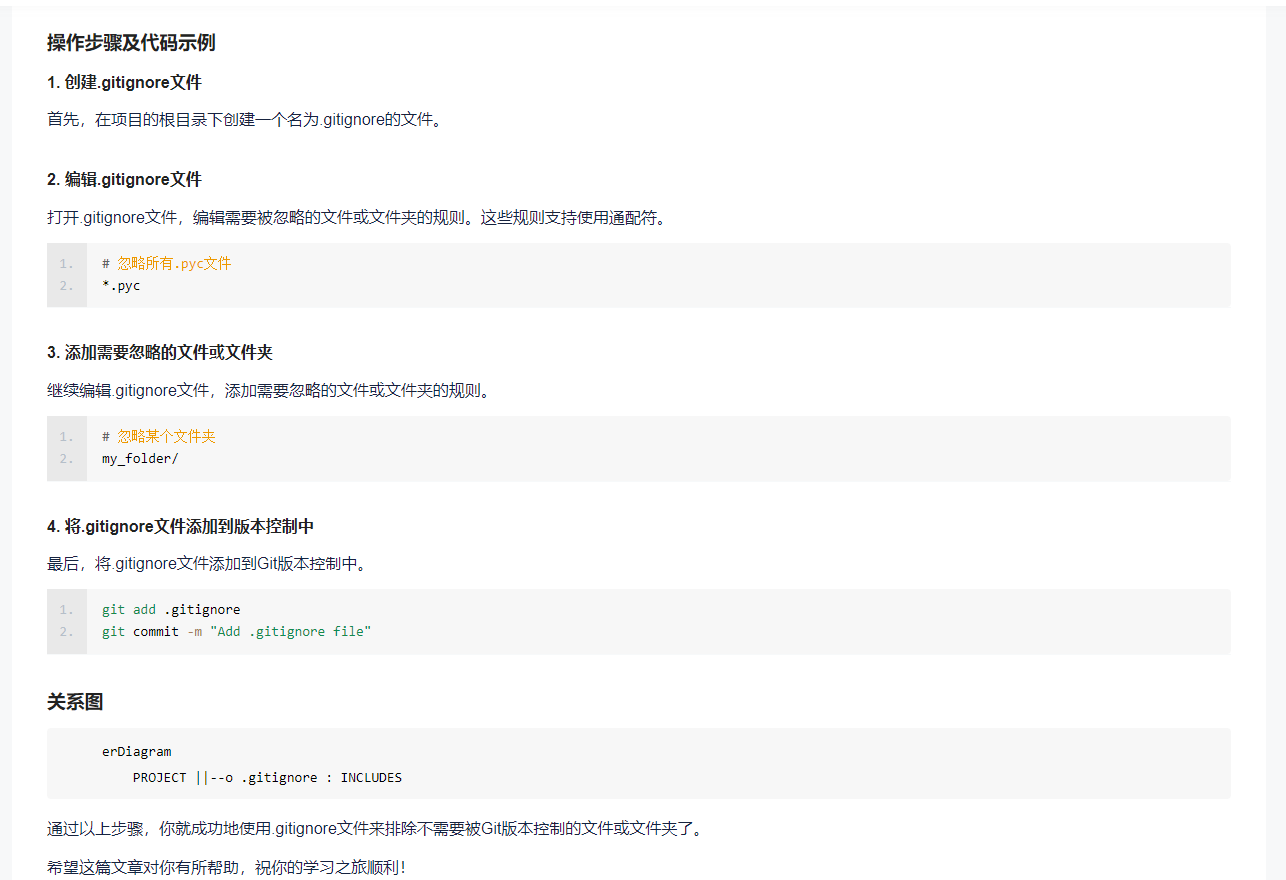
10. .gitignore文件:Git版本控制系统的忽略文件,用于指定哪些文件/文件夹不被添加到版本控制中。有些系统版本文件是不需要版本控制的, 比如vene文件夹,该功能就是将不需要版本控制的文件加入该文件中,这样同步代码get就不会对这些文件进行更新提交
11. README.md文件:项目说明文档,介绍项目名称、目录结构、使用方法等内容。
相当于一个项目说明书, 大项目才有可能会用到, 小项目一般用不到

 浙公网安备 33010602011771号
浙公网安备 33010602011771号