mysql-003:SQL语言
1. 数据库操作:
# 创建数据库 CREATE DATABASE mydb1; # 创建数据库,并设置编码 CREATE DATABASE mydb2 CHARACTER SET gbk; # 创建数据库前,检索是否存在该数据库,存在则不创建 CREATE DATABASE IF NOT EXISTS mysb3; # 查看所有数据库 SHOW DATABASES; # 查看指定数据库信息 SHOW CREATE DATABASE mydb1; # 修改数据库编码格式为:gbk ALTER DATABASE mydb1 CHARACTER SET gbk; # 删除数据库 DROP DATABASE mydb1; # 使用数据库 USE mydb3; # 查看当前正在使用的数据库 SELECT DATABASE();
2. 基本查询:
语法:select 列名 from 表名
# 查询部分列 SELECT id, age, FROM `table` # 查询所有列 SELECT * FROM `table`
对列进行运算,运算符:+、-、*、/、
# 对列进行加法运算 SELECT age*12 FROM `table`
列的别名
# 对列命别名,as可省略不写 SELECT age as '年龄' FROM `table`
查询结果去重
# 对年龄去重
SELECT DISTINCT age FROM `table`
排序查询
# 对年龄进行正序排序(ASC), ASC可省略不写,默认为ASC排序 SELECT age FROM `table` ORDER BY age ASC # 对年龄进行降序排序(DESC) SELECT age FROM `table` ORDER BY age DESC
多个字段排序(只有在第一个排序有相同的情况下才会用到第二个排序)
SELECT age FROM `table` ORDER BY age DESC, age2 ASC
根据字段所在列数排序,2代表着第2列
SELECT age FROM `table` ORDER BY 2 DESC
3. 条件查询
等值判断(=)
# 查询年龄等于12的数据(=) SELECT * FROM `table` WHERE age = '13'
不等值判断(>、<、>=、<=、!=、<>)、分别是大于、小于、大于等于、小于等于、不等于、不等于。!=和<>功能使用上没有区别, 都是不等于查询
# 查询年龄大于12的数据 SELECT * FROM `table` WHERE age > '13' # 查询年龄不等于12 的数据(!=、<>) SELECT * FROM `table` WHERE age != '13' SELECT * FROM `table` WHERE age <> '13' --其它暂不作演示,举一反三都是一样的用法
逻辑判断:(and、or、not)
# 查询年龄等于12 并且 id等于13的数据 SELECT * FROM `table` WHERE age = '12' AND id = '13' # 查询年龄等于12 或者 id等于13的数据 SELECT * FROM `table` WHERE age = '12' OR id = '13' # 查询年龄不是12的数据(is NOT) SELECT * FROM `table` WHERE age is NOT '12'
区间判断(BETWEEN AND)
# 查询年龄在12 到 20 之间的数据 SELECT * FROM `table` WHERE age BETWEEN '12' AND '20' -- 注意:在区间判断语法中,小值在前,大值在后,反之,得不到正确结果
NULL 值判断(IS NULL, IS NOT NULL)
# 查询年龄为空的数据 SELECT * FROM `table` WHERE age IS NULL # 查询年龄不为空的数据 SELECT * FROM `table` WHERE age IS NOT NULL
枚举查询(IN(值1,值2,值3))。注:in 查询效率较低, 可以通过多条件拼接查询
# 查询年龄等于12 和 13的数据 SELECT * FROM `table` WHERE age in ('12','13')
模糊查询(like)
# 查询年龄1开头的数据,'_'代表单个任意字符 SELECT * FROM `table` WHERE age LIKE '_1' # 任意长度字符%,查询包含1的数据 SELECT * FROM `table` WHERE age LIKE '%1%' SELECT * FROM `table` WHERE age LIKE '_1%'
分支结构查询,该查询类似于python中的if else
# 分支结构,关键字(CASE、WHEN、THEN、ELSE、END)。说明:将分支结构所查询出来的值当做列来显示。 # 如果大于1小于30,则返回“年轻人”,如果大于30小于50,则返回“中年人”,如果都不在条件范围内,则为“老年人”。 SELECT id, CASE WHEN age > '1' AND age < '30' THEN '年轻人' WHEN age > '30' AND age < '50' THEN '中年人' ELSE '老年人' END AS '年龄分类' FROM `table`;
4、 时间查询
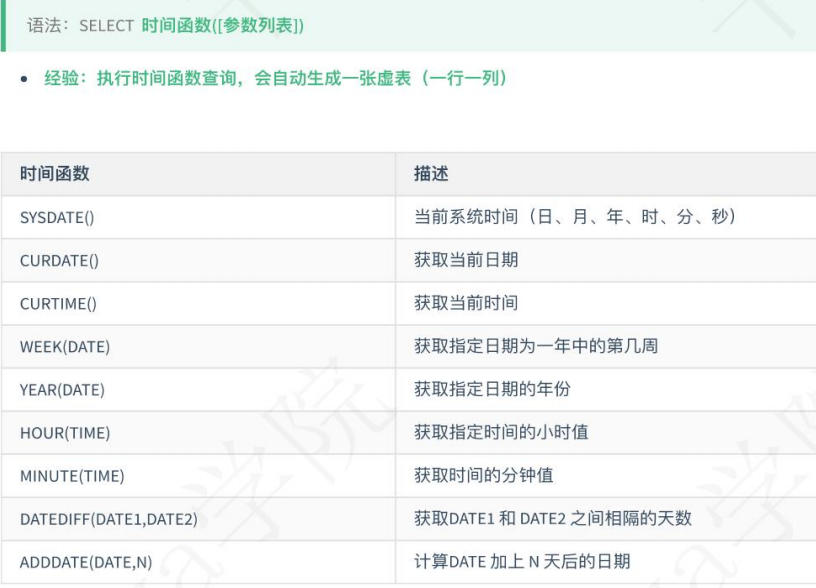
# 查询当前时间,返回格式:2022-07-11 21:11:51 SELECT SYSDATE(); # 查询当前 SELECT NOW(); -- NOW()和SYSDATE()虽然都表示当前时间,但使用上有一点点区别: -- 1. NOW()取的是语句开始执行的时间 -- 2. SYSDATE()取的是动态的实时时间 -- 执行下面这个例子就明白了:SELECT NOW(),SYSDATE(),SLEEP(3),NOW(),SYSDATE() -- 先查询了NOW()和SYSDATE(),然后sleep了3秒,再查询NOW()和SYSDATE(),结果如下: -- now()值不发生改变,sysdate()时间发生改变 # 查询当前日期,返回格式:2022-07-11 SELECT CURDATE(); # 获取当前时间,返回格式:21:55:44 SELECT CURTIME(); -- 其它函数不作演示
5. 字符串查询
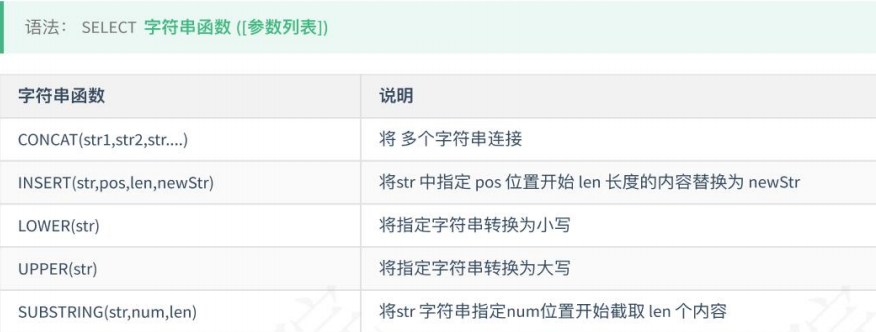
# 拼接内容 SELECT CONCAT('中','国'); #执行结果:中国 # 字符串替换,从第3个开始,替换两个字符,将这两个字符替换成"MySql"。 SELECT INSERT('这是一个数据库',3,2, 'MySql'); # 执行结果:这是MySql数据库 # 将内容转换为小写 SELECT LOWER ('MySql'); # 执行结果:mysql #指定内容转换为大写 SELECT UPPER(' mysql') : # 执行结果:MYSQL #指定内容截取,从第5个字符开始, 往后截取5个字符 SELECT SUBSTRING(' JavaMySQLOracle', 5, 5) : # 执行结果:MySQL -- 注意:mysql下标是从1开始的
6、 聚合函数
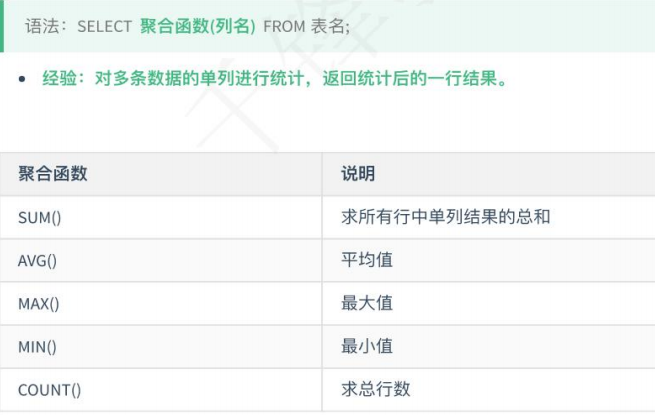
# 求单列总和。统计所有员工每月的工资总和 SELECT sum(salary) FROM t_employees; #统计所有员工每月的平均工资 SELECT AVG(salary) FROM t_employees; #统计所有员工中月薪最高的工资 SELECT MAX(salary)FROM t_employees; #统计所有员工中月薪最低的工资 SELECT MIN(salary) FROM t_employees; #统计员工总数 SELECT COUNT(*) FROM t_employees; -- 注意:聚合函数自动忽略null值,不进行统计。
7、 分组查询(GROUP BY)

# 对年龄进行分组,也就是同一个数值为一组 SELECT * FROM `table` WHERE GROUP BY age;
分组过滤查询(HAVING)
# 对年龄分组,并对分组后的数据加以条件 SELECT * FROM `table` WHERE GROUP BY age HAVING age = '12';
限定查询(分页查询)。(LIMIT)
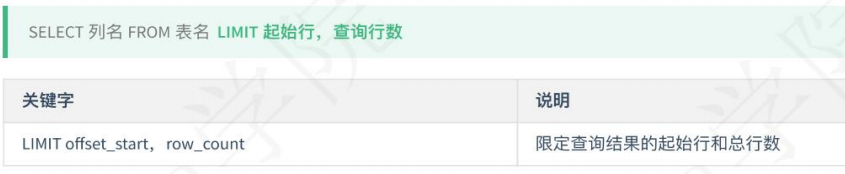
# 对年龄进行分页,从第0行开始查询,一共查询10行数据 SELECT * FROM `table` LIMIT 0,10; # 0可以省略不写,查询前10行数据 SELECT * FROM `table` LIMIT 10;
查询总结:sql语句执行顺序

8、子查询

# 将括号里的查询结果作为条件 SELECT * FROM `table` WHERE age > (SELECT age FROM `table` WHERE age = '12'); # 将子查询结果作为枚举值 SELECT * FROM `table` WHERE age in (SELECT age FROM `table` WHERE age = '12');
子查询作为一张表,也叫嵌套查询

# 子查询作为一张表时,需要赋予别名才行。 SELECT * FROM ( SELECT * FROM `table` ) AS age_table WHERE age_table.age = '12'
9、 合并查询(UNION ALL)。了解即可

# 合并两张表,去重记录 SELECT * FROM t1 UNION SELECT * FROM t2; # 合并两张表, 不做去重记录 SELECT * FROM t1 UNION ALL SELECT * FROM t2;
10、表连接查询

# 内连接(INNER JOIN on) SELECT * FROM t1 INNER JOIN t2 on t1.id = t2.id; # 三表连接查询 SELECT * FROM t1 INNER JOIN t2 on t1.id = t2.id INNER JOIN t3 on t2.id = t3.id; # 左外连接查询(LEFT JOIN on) SELECT * FROM t1 LEFT JOIN t2 on t1.id = t2.id; # 右外连接查询(RIGHT JOIN on) SELECT * FROM t1 RIGHT JOIN t2 on t1.id = t2.id;
11、新增、插入(INSERT)

# 向表插入一条信息 INSERT INTO t1 (id,name) VALUES('1','小芳');
12、修改、更新(UPDATE)

# 更新表中的某一个数据 UPDATE t1 SET id = '2' WHERE id = '1'; -- 注意: SET后多个列名=值,绝大多数情况下都要加WHERE条件,指定修改,否则为整表更新
13、删除表(DELETE)

# 删除表中的一个数据 DELETE FROM t1 WHERE id = '1' -- 注意:删除时,如若不加WHERE条件,删除的是整张表的数据
清空表数据(TRUNCATE)
# 清空某张表数据 TRUNCATE TABLE t1; -- 删除表和清空表不同,前者是将整张表删除,后者是清空表内容,表结构还是在的
14、 数据类型:数据库的数据类型:(MySQL 支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。)

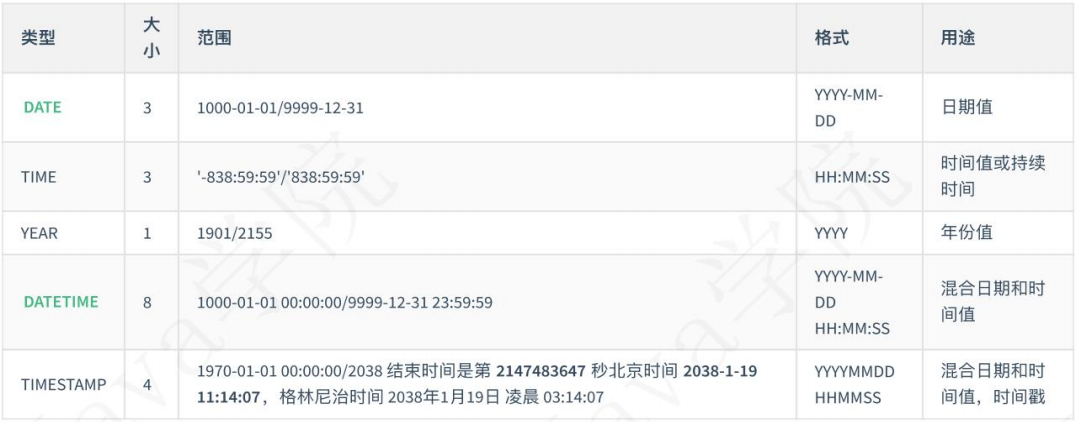
15、 日期类型
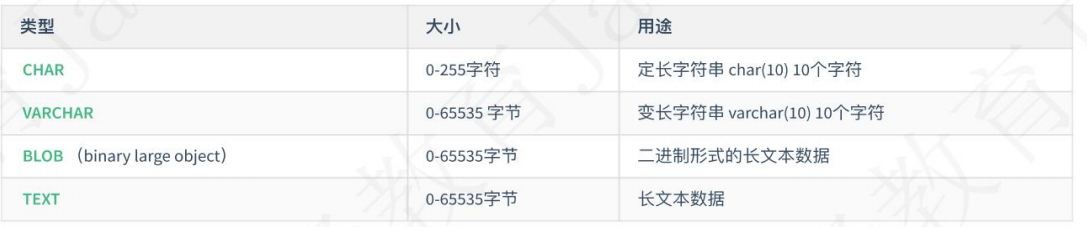
16、字符串类型
17、 表的创建

# 创建表 CREATE TABLE t1 ( # t1表名 id int, # id列名,int类型 namesd VARCHAR(20) # namesd 列名, VARCHAR数据类型,限制字符20个 )charset=utf8
表的修改、修改表

# 向表中添加列 ALTER TABLE t1 ADD id2 int; # 修改列名 ALTER TABLE t1 CHANGE id1 id2 int。 # 修改列类型 ALTER TABLE t1 MODIFY id VARCHAR(10); # 删除表中的列 ALTER TABLE t1 DROP id1; # 修改表名 ALTER TABLE t1 rename t2;
# 删除表
DROP TABLE t1;
18、约束
定义:给列添加某种约束,像是不能为空,不能重复等,此叫约束。约束可以在创建表时添加,也可以在修改列名时添加。
主键约束:PRIMARY KEY 唯一,给表的某一个列添加数时,此列的值不可重复,且不能为NULL
唯一约束:UNIQUE 唯一,给表的某一个列添加数时,不可重复,可以为NULL
自动增加列:AUTO_INCREMENT 自动增长,假如有id和name两个列,给id列加了自动增加功能,只给name列插入数据时, id列也会自动加入数据。从1开始,每次加1。不能单独使用,和主键配合。
# 添加(主键约束):PRIMARY KEY CREATE TABLE t1 ( # t1表名 id int PRIMARY KEY, # id列名,int类型 )charset=utf8 # 添加(唯一约束):UNIQUE CREATE TABLE t1 ( # t1表名 id int UNIQUE, # id列名,int类型 )charset=utf8 # 添加(自动增长):AUTO_INCREMENT CREATE TABLE t1 ( # t1表名 id int PRIMARY KEY AUTO_INCREMENT, # id列名,int类型 name VARCHAR(20) UNIQUE )charset=utf8
域完整性约束:限制列的单元格的数据正确性。
# 非空约束:(UNIQUE NOT NULL) 非空,此列必须有值。 CREATE TABLE t1 ( id int PRIMARY KEY UNIQUE NOT NULL, )charset=utf8 # 默认值约束:(DEFAULT 值) 为列赋予默认值,当新增数据不指定值时,书写DEFAULT,以指定的默认值进行填充。 CREATE TABLE t1 ( id int DEFAULT '20', )charset=utf8 # 引用完整性约束 -- 语法: CONSTRAINT 引用名FOREIGN KEY (列名) REFERENCES被引用表名(列名) -- 详解: FOREIGN KEY引用外部表的某个列的值,新增数据时,约束此列的值必须是引用表中存在的值。 CREATE TABLE t1 ( id int CONSTRAINT '引用名' FOREIGN KEY (列名) REFERENCES 被引用表名(列名), )charset=utf8
19、 事务
事务的概念:事务是sql语句中最小执行单元。可以由一个或多个SQL语句组成事务,当事务中的所有最小执行单元都执行成功, 则认为该事务执行成功,反则执行失败。
事务作用:拿银行转账为例,A账户和B账户各有100块, A账户给B账户转账10块, 在SQL中是这样操作的:先扣减A账户的10块, 然后给B账户添加10块。但是这会有一个问题,假如A账户
扣减10块这个SQL执行成功,但是因为某种原因B账户添加10块的SQL执行失败。这时系统需要回滚,才能保证A、B账户的钱款一致。问题是失败的SQL系统可以识别并回滚,但是成功的SQL系统无法识别,
且系统也无法知道需要回滚到哪个节点。
这时事务就出现了,将(先扣减A账户的10块, 然后给B账户添加10块)这两个SQL操作添加为一个事务, 要是任意一个SQL执行失败,则将该事务内的所有SQL回滚即可。

如何使用事务?
# 事务场景:A账户给B账户转账 # 1.首先开启一个事务 START TRANSACTION; | setAutoCommit=0; #setAutoCommit=0禁止自动提交 setAutoCommit=1开启自动提交 # 2. 事务内数据操作语句 UPDATE t1 SET MONEY = MONEY-10 WHERE ID = 1; # 给A账户减10块 UPDATE t1 SET MONEY = MONEY+10 WHERE ID = 2; # 给B账户加10块 # 3. 事务内语句都成功,则提交 COMMIT; # 4. 事务内语句如果出现错误,则回滚 ROLLBACK; -- 注意:开启事务后,执行的语句均属于当前事务,成功再执行COMIIT,失败要进行ROLLBACK
20、权限管理
# 创建用户 CREATE USER 用P名 IDENTIFIED BY 密码; # 授权 GRANT ALL ON 数据库.表TO 用户名; # 撤销权限:将 zhangsan的companyDB 的权限撤销 REVOKE ALL ON companyDB.* FROM 'zhangsan'; # 删除用户 DROP USER 用户名;
21、视图
视图概念:视图,虚拟表,从一个表或多个表中查询出来的表,作用和真实表一样,包含一系列带有行和列的数据。视图中,用户可以使用SELECT语句查询数据,也可以使用INSERT, UPDATE, DELETE修改记录,视图可以使用户操作方便,并保障数据库系统安全。
视图作用:简单来说,就是将一大段sql或多表连接的sql所查出来的结果,做成一张虚拟表,下次查询数据时直接从虚拟表查就行了,不用再执行那一大段sql

视图的创建,语法:CREATE VIEW 视图名 AS 查询数据源表语句
# 创建视图 CREATE VIEW t123 from SELECT * FROM t1; # 使用视图 SELECT * FROM t123 # 视图修改 -- 方式一: CREATE OR REPLACE VIEW 视图名 AS 查询语句 -- 方式二: ALTER VIEW 视图名 AS 查询语句 # 视图删除 DROP VIEW 视图名 注意:。视图不会独立存储数据,原表发生改变,视图也发生改变。没有优化任何查询性能。 如果视图包含以下结构中的一种,则视图不可更新 聚合函数的结果 DISTINCT 去重后的结果 GROUP BY 分组后的结果 HAVING 筛选过滤后的结果 UNION UNION ALL 联合后的结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号