我的Python分析成长之路5
一、装饰器:
本质是函数,装饰其他函数,为其他函数添加附加功能。
原则:
1.不能修改被装饰函数的源代码。
2.不能修改被装饰函数的调用方式。
装饰器用到的知识:
1.函数即变量 (把函数体赋值给函数名)
2.高阶函数 (1.一个函数接受另一个函数名作为实参2.返回值中含有函数名)
3.嵌套函数(一个函数嵌套这另一个函数)
先看高阶函数 :
1。要实现不修改被装饰函数的源代码,就要使用一个函数接受另一个函数名作为实参
2.要实现不修改源代码的调用方式,使用返回值中包含函数名

嵌套函数:
def test1():
print("in the test1")
def test2():
print("in the test2")
test2()
test1() #一个函数中包含另一个函数,而且内部的函数只能在内部调用
装饰器的实现
#给计算test的运行时间 def timer(func): def wrapper(): start_time = time.time() func() end_time = time.time() print("函数运行时间:%s"%(end_time-start_time)) return wrapper @timer def test(): time.sleep(1) # test = timer(test) test()
import time def timer(func): def wrapper(n): start_time = time.time() func(n) end_time = time.time() print("函数运行时间:%s"%(end_time-start_time)) return wrapper @timer def test(n): #当函数中含有参数时 time.sleep(1) print("打印的值为:%s"%n) # test = timer(test) test(5)
1 import time 2 def timer(func): 3 def wrapper(*args,**kwargs): #当函数中含有任意多个参数参数时 4 start_time = time.time() 5 func(*args,**kwargs) 6 end_time = time.time() 7 print("函数运行时间:%s"%(end_time-start_time)) 8 return wrapper 9 @timer 10 def test(age,name): 11 time.sleep(1) 12 # print("打印的值为:%s") 13 print("年龄是%s,名字是%s"%(name,age)) 14 # test = timer(test) 15 test(24,name='小明')
二、迭代器与生成器
列表生成式 [i *2 for i in range(10)]
生成器 1.只有在调用的时候才会生成数据。2.只记录当前位置。3.只有next方法,直到最后抛出stopiteration才终止
第一种形式
1 [i *2 for i in range(10)] #列表生成式 2 x = (i *2 for i in range(10)) #生成器 3 print(x.__next__()) 4 print(x.__next__()) 5 print(next(x))
第二种形式
1 def f(maxiter): 2 n,a,b = 0,0,1 3 while n<maxiter: 4 yield b #用函数形成生成器 含有 yield 5 a,b = b,a+b 6 n += 1 7 x = f(10) 8 print(x.__next__()) #要想生成数据,需要调用next方法 9 print(x.__next__())
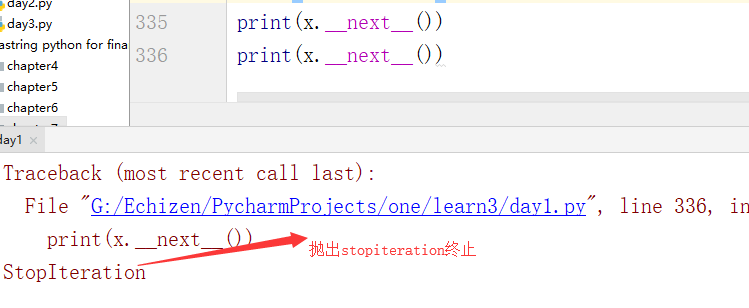
如果要获取生成器的值,就要捕获stopiteration异常
1 def f(maxiter): 2 n,a,b = 0,0,1 3 while n<maxiter: 4 yield b 5 a,b = b,a+b 6 n += 1 7 return "done" #如果要获取函数的返回值,就要捕获stopiteration异常 8 x = f(3) 9 while True: 10 try: 11 print("x:",x.__next__()) 12 except StopIteration as e: 13 print("生成器返回值:",e.value) 14 break
1 #最简单的生产者消费者模型 2 import time 3 def consumer(name): 4 print("%s要准备吃包子了"%name) 5 while True: 6 baozi = yield 7 print("%s包子被%s吃了"%(baozi,name)) 8 def produser(name): 9 c1 = consumer('A') 10 c2 = consumer('B') 11 c1.__next__() 12 c2.__next__() 13 for i in range(10): 14 time.sleep(1) 15 print("%s做了2个包子"%name) 16 c1.send(i) 17 c2.send(i) 18 produser('xiaoming')
迭代器iterator:可以调用next方法,并不断返回下一个值的对象 生成器都是迭代器,list、dict、str 都是可迭代对象,但不是迭代器。可用iter方法使之称为迭代器
三、map、filter、reduce函数
1 print(map(lambda x:x*2,range(10))) 2 print(list(map(lambda x:x*2,range(10)))) 3 #map(func,iterable)对iterable调用func 得到的是 4 print(list(filter(lambda x:x>5,range(10)))) 5 #filter(func,iterable) #对可迭代对象进行筛选 6 print(list(filter(lambda x:x.startswith('m'),['mn','mb','b']))) 7 from functools import reduce 8 print(reduce(lambda x,y:x+y,range(10))) #进行累加操作 9 # reduce(func,iterable)
四、json和pickle模块
1 data ={'name':'zqq','age':8,'sex':"boy"} 2 f = open("file.json","r") 3 # f.write(str(data)) 4 import json 5 x = json.dumps(data) #序列化 或 json.dump(data,f) dump可以多次,load只能一次 6 f.write(x) 7 data = json.loads(f.read()) #反序列化 或json.load(f) 8 print(data) 9 f.close() 10 11 f = open("ddd.txt","wb") 12 import pickle 13 x = pickle.dumps(data) #序列化 pickle.dump(data,f) 14 f.write(x) 15 f.close() 16 f = open("ddd.txt","rb") 17 import pickle 18 data = pickle.loads(f.read()) #反序列化 pickle.load(f) 19 print(data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号