数据库相关
事务:
概念
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果必须使数据库从一种一致性状态到另一种一致性状态。事务是逻辑上的一组操作,要么都执行,要么都不执行。
MySQL默认就是自动事务管理(自动开启事务,自动提交事务),一条sql语句就是一个事务
事务执行的过程中,若无异常,则会commit完成curd,若出现异常,则会rollback回滚到事务回滚点
四大特性(ACID)
- 原子性(Atomicity):事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency):事务前后数据的完整性必须保持一致。
- 隔离性(Durability):多个用户并发操作数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离。即事务之间互不干扰。
- 持久性(Isolation):事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
事务隔离级别:
为了达到事务的四大特性,数据库定义了4种不同的事务隔离级别,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
脏读:事务A读到了事务B还未commit的内容,事务B若rollback,则事务A读到了不存在的内容即为脏读。
不可重复读:事务A在两次读取同一数据的过程中,若该数据在此期间被事务B修改,则事务A读取的同一数据内容不同,则为不可重复读。
幻读:事务A在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行(如事务B在此期间插入了一条数据)。
个人理解:幻读与不可重复读的区别是,幻读注重范围查和并发增,不可重复读注重重复读和并发改
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
|---|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 | |
| 2 | 读已提交 | read committed | 否 | 是 | 是 | Oracle |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 | MySQL |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生(当前读)。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
需注意:
- InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)**
- InnoDB 存储引擎在 分布式事务 的情况下一般会用到**SERIALIZABLE(可串行化)**隔离级别。
三大范式
第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式
第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。
JDBC连接数据库的过程:
详见下例:
package org.example; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class JDBCTest { public static void main(String[] Args){ try { //String driver = "com.mysql.cj.jdbc.Driver";// 驱动路径 String url = "jdbc:mysql://localhost:3306/test";// 数据库地址 String user = "root";// 访问数据库的用户名 String password = "12345";// 用户密码 String sql = "select *from user_info";// 查询user表的所有信息 ResultSet rs=null;//查询之后返回结果集 // 1、加载驱动(加载成功后会将Driver类的实例注册到DriverManager类中) //注意:MySQL 5之后的驱动包,可以省略注册驱动这一步,因为会自动加载jar包中META-INF>>services>>java.sql.Driver下的驱动类。 //Class.forName(driver); // 2、链接数据库 Connection con = DriverManager.getConnection(url, user, password); if (!con.isClosed()) {// 判断数据库是否链接成功 System.out.println("已成功链接数据库!"); // 3、创建Statement对象 Statement st = con.createStatement(); // 4、执行sql语句 rs = st.executeQuery(sql);// 查询之后返回结果集 // 5、打印出结果 while (rs.next()) { System.out.println(rs.getString("user_id") + "\t" + rs.getString("nick_name") + "\t" + rs.getString("password")); } } rs.close();// 关闭资源 con.close();// 关闭数据库 }catch (Exception e){ e.printStackTrace(); } } }
注:下文中所有提到的单例代码大多源自上例代码
DriverManager(驱动管理类)
作用:注册驱动、获取数据库连接。
driverManager会通过反射扫描类加载器中已存在的实现了Driver接口的类,并将其信息写入 registeredDrivers 中。
![]()
1.加载驱动
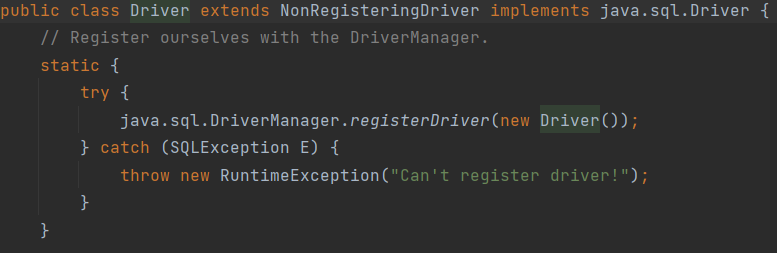
Class.forName(“Driver.class在mysql jdbc包的全路径”)。
主动加载mysql的Driver类时,会调用其内部静态代码块,将new Driver()实例对象注册到DriverManager中,这样就完成了驱动注册操作
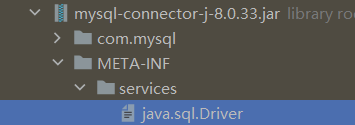
MySQL 5之后的驱动包,可以省略注册驱动这一步。因为会自动加载jar包中META-INF>>services>>java.sql.Driver下的驱动类。

2.获取数据库连接
useSSL=false参数,禁用安全连接方式,可以解决警告提示。Connection(数据库连接对象)
作用:获取执行SQL的对象、管理事务。
1.获取执行SQL的对象
•要执行SQL语句,必须获得java.sql.Statement实例,Statement实例分为以下3 种类型:
1、执行静态SQL语句。通常通过Statement实例实现。
2、执行动态SQL语句。通常通过PreparedStatement实例实现。
3、执行数据库存储过程。通常通过CallableStatement实例实现。
例如:Statement st = con.createStatement();
2.管理事务
| 作用 | 方法名 | 说明 |
|---|---|---|
| 开启事务 | setAutoCommit(boolean autoCommit) | true自动提交事务;false手动提交事务。为false就是开启事务,相当于SQL的BEGIN作用 |
| 提交事务 | commit() | |
| 回滚事务 | rollback() |
Statement(执行SQL语句)
Statement接口提供了三种执行SQL语句的方法:executeQuery 、executeUpdate和execute
1、ResultSet executeQuery(String sqlString):执行查询数据库的SQL语句,返回一个结果集(ResultSet)对象。
2、int executeUpdate(String sqlString):用于执行INSERT、UPDATE或 DELETE语句以及SQL DDL语句,如:CREATE TABLE和DROP TABLE等
3、execute(sqlString):用于执行返回多个结果集、多个更新计数或二者组合的语句。
例如:
ResultSet rs = st.executeQuery("SELECT * FROM ...") ;
int rows = st.executeUpdate("INSERT INTO ...") ;
boolean flag = st.execute(String sql) ;
ResultSet(ResultSet结果集对象,封装了DQL查询语句的结构)
使用方法:
while(rs.next()){
String name = rs.getString("name") ;
String pass = rs.getString(1) ; // 此方法比较高效
}
注:列是从左到右编号的,并且从列1开始
PreparedStatement(预防SQL注入问题)
- PreparedStatement:预编译SQL语句并执行,并且性能更高(预编译功能需要自行开启)。
- 预编译开启方法:在String url的参数里添加
useServerPrepStmts=true。 - SQL注入:通过操作用户输入的内容,来修改代码里原SQL语句的语义,以达到对服务器进行攻击的目的。
- PreparedStatement防止SQL注入原理:将敏感字符进行转义。


//获取连接 String url = "jdbc:mysql://127.0.0.1:3306/db1?useServerPrepStmts=true&serverTimezone=UTC&userUnicode=true&charsetEncoding=utf-8"; String user = "root"; String password = "000000"; Connection conn = DriverManager.getConnection(); //定义sql String name = "zhangsan"; String pwd = "000000"; String sql = "select * FROM student where name=? and pwd = ?"; //获取PreparedStatement对象 PreparedStatement ps = conn.prepareStatement(sql); //设置sql的值 ps.setString(1,name); ps.setString(2,pwd); //执行sql ResultSet rs = ps.executeQuery();
MVCC:
当前读和快照读:
MVCC属于快照读,即普通的select语句
当前读即每次读取最新数据,需要利用锁机制来实现,常见sql语句如下:
- select lock in share mode(共享锁)
- select for update(排他锁)
- update(排他锁)
- insert(排他锁)
- delete(排他锁)
实现原理:
MVCC 没有正式的标准,所以在不同的 数据库管理系统(DBMS) 中,MVCC 的实现方式可能是不同的。
mvcc的实现,基于undolog、版本链、readview。
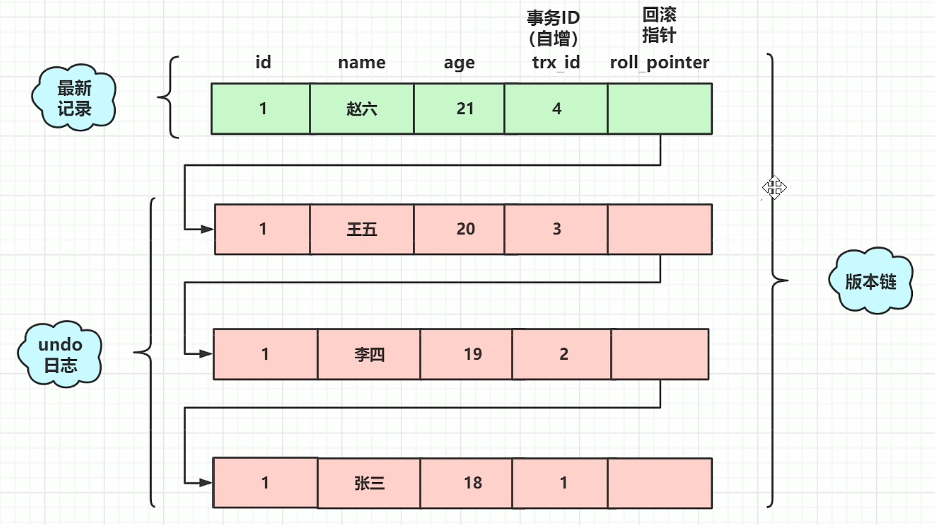
在mysql存储的数据中,除了我们显式定义的字段,mysql会隐含的帮我们定义几个字段。
-
trx_id:事务id,每进行一次事务操作,就会自增1。
-
roll_pointer:回滚指针,用于找到上一个版本的数据,结合undolog进行回滚。
mvcc所提到的读是快照读,也就是普通的select语句。快照读在读写时不用加锁,不过可能会读到历史数据。
readview:
readview即快照,事务中每个select读前会生成一个readview。快照是用来获取当前事务能够读取版本的字段集,包含以下字段:
-
m_ids:当前活跃的事务id列表。活跃的事务就是指还没有commit的事务。
-
max_trx_id:下一个活跃事务将被分配的id值。例如m_ids中的事务id为(1,2,3),那么下一个应该分配的事务id就是4,max_trx_id就是4。
- min_trx_id:活跃事务中的最小事务id,即min(m_ids)。
-
creator_trx_id:当前readview的事务id。
由上可知,若trx ∈ m_ids,则min_trx_id <= trx <= max_trx_id
若trx == creator_trx_id 或 trx < min_trx_id 或 trx!=m_ids,则trx版本可以被当前事务访问
MVCC对RC和RR事务隔离级别的实现:
RC:每个快照读都会生成并获取最新的readview,即选择可选取的最大的trx
RR:有在同一个事务的第一个快照读才会创建readview,之后的每次快照读都使用的同一个readview,所以每次的查询结果都是一样的。
需注意:
- 仅作MVCC的快照读时不会产生幻读
- innodb的RR级别,当前读时,通过使用where给定区间(select...from...where... for update)则不止会加行锁(record lock),还有间隙锁(gap),即next-key锁(行锁+gap锁),这种锁会解决绝大部分幻读问题。若仅仅只有select for update,则还是会产生幻读。
缓存池(Buffer Pool)
当我们使用MySQL数据库时,每次执行查询都需要向数据库发出请求,并在完成查询后将结果返回。这个过程需要花费很多时间,特别是在高并发的环境下。为了优化查询的性能,MySQL引入了缓存机制,其中一个重要的组成部分就是缓存池。MySQL缓存池主要是为了优化数据库查询性能而设计的。它可以缓存经常被查询的数据和执行计划,从而避免每次查询都要向磁盘发起请求,提高了数据库的响应速度和性能。
缓存池详细见该文
索引相关
mysql中 innodb和myisam索引区别(聚集索引和非聚集索引)
相同点: innodb和myisam都使用b+树作为索引结构,且都分主键索引和辅助索引
innodb
主键索引:
在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
辅助索引:
InnoDB的所有辅助索引都引用主键作为data域。我们在使用辅助索引作为条件查询时会查询两次(回表),首先从辅助索引中查出主键,再在主键索引中查数据。因此对于这种情况我们可以对数据库sql语句进行针对性优化,如在海量数据情况下需要使用辅助索引进行查询时,可以先用辅助索引查主键索引作为临时表,和原表进行拼接,再去查数据。
为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,2、用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
MyISAM
主键索引:
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
辅助索引:
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
索引失效
- 数据类型不匹配。查询值与索引值数据类型不同时,会对索引列进行类型转换,从而使得索引失效 解决方法:保持数据类型的一致性,或者在查询条件中使用显式类型转换。
- 模糊查询以%开始。如 where like '%xxx' 解决方法:避免使用以%开头的模糊匹配,或者使用覆盖索引(只包含索引列的查询)。
- 索引列使用了函数或运算。 解决方法:尽量避免对索引列使用函数或运算,或者建立基于函数或运算的索引
- 索引列包含空值,查询条件使用IS NULL 或 IS NOT NULL。MySQL建立索引时不会存储空值,所以无法通过索引来判断是否为空。 解决方法:避免让索引列为空
- 使用OR,且OR两边涉及不同的索引列。解决方法:尽量避免使用OR关键字,或者将OR两边的条件分别用括号括起来,并且在括号内部使用相同的索引列。
- 联合索引违反了最左前缀原则。左前缀原则,即从左到右依次使用联合索引中的列,不能跳过任何一列。例如,如果建立了(name, age, gender)的联合索引,那么在查询条件中可以使用name,或者name和age,或者name,age和gender,但是不能只使用age或gender,也不能只使用age和gender。
- 全表扫描比使用索引更快。MySQL有一个优化器,它会根据表中的数据量和分布情况,预估使用索引和全表扫描的代价,选择一个更快的方案。
SQL语句种类
数据定义语言DDL(Data Ddefinition Language)CREATE,DROP,ALTER
主要为以上操作 即对逻辑结构等有操作的,
其中包括表结构,视图和索引。
数据查询语言DQL(Data Query Language)SELECT
这个较为好理解 即查询操作,以select关键字。
各种简单查询,连接查询等 都属于DQL。
数据操纵语言DML(Data Manipulation Language)INSERT,UPDATE,DELETE
主要为以上操作 即对数据进行操作的,
对应上面所说的查询操作 DQL与DML共同构建了多数初级程序员常用的增删改查操作。
而查询是较为特殊的一种 被划分到DQL中。
数据控制功能DCL(Data Control Language)GRANT,REVOKE,COMMIT,ROLLBACK
主要为以上操作 即对数据库安全性完整性等有操作的,可以简单的理解为权限控制等。
数据类型
1.整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
2.浮点数类型:FLOAT、DOUBLE、DECIMAL
3.字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
4.日期类型:Date、DateTime、TimeStamp、Time、Year
5.其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection等
参考文章:https://blog.csdn.net/m0_49790240/article/details/123775697?spm=1001.2014.3001.5506
https://blog.csdn.net/lans_g/article/details/124232192
https://www.cnblogs.com/zlcxbb/p/5757245.html
https://blog.csdn.net/qq_44708895/article/details/127863597
https://zhuanlan.zhihu.com/p/534415409
https://baijiahao.baidu.com/s?id=1763976789426879771&wfr=spider&for=pc
https://blog.csdn.net/weixin_62023527/article/details/127504535

 浙公网安备 33010602011771号
浙公网安备 33010602011771号