Top Tree 相关理论扯淡
前言
Top Tree,一个有赫赫威名的数据结构。
在绝大多数人眼里,Top Tree 是毒瘤、难写、没用的代名词。这种认识一定程度上来自于一些奇怪题目。基于同样的原因,Top Tree 在绝大多数人的认知中是一种比 LCT 更为强大(如支持子树修改)的动态树数据结构。而这样的动态树操作在实际应用中可谓是及其罕见,于是 Top Tree 便被打上了“无用”的标签。
这种认知实际上是较为浅显的。NOI2022 树上邻域数点让人们(包括我)认识到,Top Tree 其实离我们并不是那么遥远。实际上,Top Tree 并没有那么复杂,其相关的理论在一系列的树上问题上表现十分优秀,可以为我们解决问题指出另一条明路。
本文包含了一些 Top Tree 理论的简介、应用及实现相关内容。由于作者水平不甚高,文章的内容仅仅在“浅谈”层面。关于更加深刻的内容,建议读者自行查找资料。
Top Cluster 分解与 Top Tree
从树分块说起
我们一直以来都想要找到一种树分块的方式,使得其具有一些优秀的性质:一个块是连通的、点数/直径不超过 \(B\)、块数为 \(O(n/B)\)……等等。
我们已经有过很多不同的树分块方法,但是这些方法似乎都不能够完全满足上述性质。传统的树分块通常是基于点的,即,块的划分以点为单位,每个点属于且仅属于一个块。但是,这种分块对树的形态依赖性太大。实际上,对于菊花图而言,我们不可能给出足够好的基于点的划分,因为根节点会把所有的叶子都分割开,使得叶子不得不单独成一块。
这启发我们改变思路,采用另一种方式:基于边的划分。块的划分以边为单位,每条边属于且仅属于一个块。我们发现,这种划分方式似乎有着更好的性质。上文中菊花图的问题到这里迎刃而解了:只需要每 \(B\) 条边一块就可以满足上文中的性质。事实上,在后文中我们可以证明,对于任意的树,基于边的划分都可以给出满足上文性质的方案。
Top Cluster 分解就是一种基于边的划分方式。下面我们将介绍 Top Cluster 分解。
簇、簇操作、树的簇表示法
我们按照如下方式定义一个簇(cluster):
- 一个簇可以表示为三元组 \((u,v,E)\),其中 \(u,v\) 为树的节点,称为簇的界点(boundary node),\(E\) 为一个边的集合,表示该簇包含的边,路径 \((u,v)\) 称作簇路径(cluster path)。
- 对于树的一条边 \((u,v)\),则 \((u,v,\{(u,v)\})\) 是一个簇。
- 对于簇 \(a=(u,v,E_a),b=(u,w,E_b),E_a\cap E_b=\varnothing\),那么 \(\operatorname{rake}(a,b)=(u,v,E_a\cup E_b)\) 也是一个簇。
- 对于簇 \(a=(u,v,E_a),b=(v,w,E_b),E_a\cap E_b=\varnothing\),那么 \(\operatorname{compress}(a,b)=(u,w,E_a\cup E_b)\) 也是一个簇。
其中 rake 和 compress 是树收缩(tree contractions)的两种基本操作。形象地理解,一个簇可以看做是一条边,而 rake 操作是把一条边“拍”到另一条边上,compress 操作就是把两条边“拼”成一条。如下图:
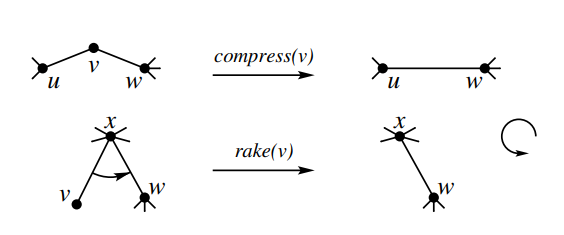
可以发现,我们显然能够构造一种方式,使得我们能够使用若干 compress 和 rake 操作来把整棵树合并为一个簇。一种构造是:不断把一度点 rake,然后把二度点 compress。
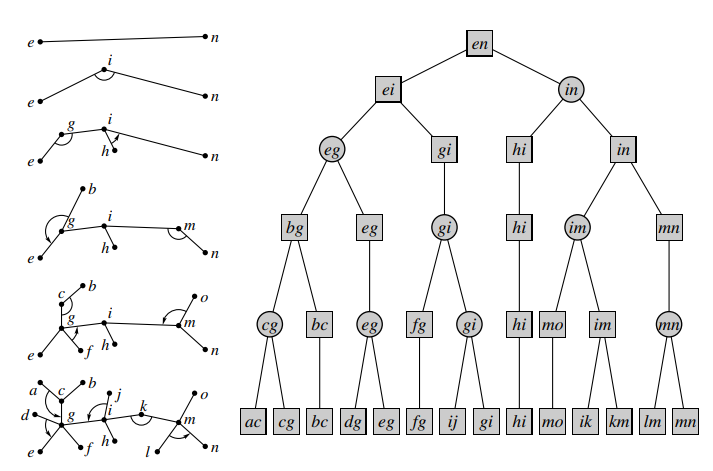
进行若干次收缩后,用簇路径来代替原来的边,可以得到一个树结构。我们将这种结构称作收缩树(如上左图)。
我们也可以得到一个二叉树结构:每个节点表示一个簇,其两个儿子表示 compress 或 rake 操作的两个簇。我们将这种结构称为 Top Tree(如上右图)。其叶子节点表示一条边,我们称其为基簇(base cluster)。其根节点表示包含整棵树的簇,我们称其为根簇(root cluster)。
基于重量平衡的静态 Top Tree
如果是一个任意的 Top Tree,其深度显然可以是 \(O(n)\) 的。为了方便问题的解决,我们希望构建一个深度是 \(O(\log n)\) 的 Top Tree。下面将介绍一种基于重量平衡的构建方法。
首先,我们需要注意到,簇的合并方式其实与我们学过的轻重链剖分有每种共同性:compress 操作可以认为是重链上的 pushup,而 rake 操作可以认为是轻子树信息的合并。因此我们可以得到一个这样的做法:对原树轻重链剖分,dfs 地自底向上处理每一个重链,并认为每一个轻子树都已经合并成一个簇。对于重链上的每一个节点,将这个节点的父亲的轻子树的簇都 rake 到他的父边,这里需要分治地 rake 来保证深度不会太大。我们称这样操作形成的树为 rake 树(rake tree)。然后,我们得到了排成一条链的簇。接着我们就可以将这些簇 compress 为一个,同样需要分治操作来保证深度。我们称这样操作形成的树为 compress 树(compress tree)。
分析一下这样得到的 Top Tree 的深度:每一次分治合并都会有 \(O(\log n)\) 的深度,而一个叶子到根会经过 \(O(\log n)\) 条重链。故这样做得到的 Top Tree 深度是 \(O(\log^2 n)\) 的。
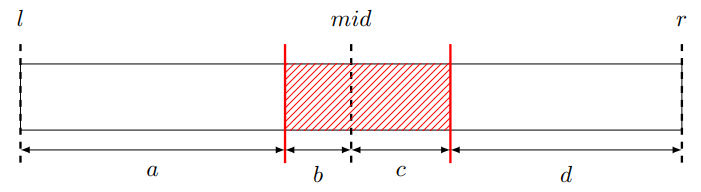
为了进一步优化,我们需要借助全局平衡二叉树的思想。在分治 compress 或 rake 的时候,我们按照簇的大小选择带权中点作为分治中点。这样我们就能够得到一棵深度为 \(O(\log n)\) 的 Top Tree。
下面是一个简单证明:
对于节点 \(u\),记其簇大小为 \(s_u\)。若其儿子与其不在同一个 compress tree 或 rake tree 上,那么一定经过了一条轻边,于是这种情况对深度的贡献是 \(O(\log n)\)。因此我们只考虑同一个 compress tree 或 rake tree 上的情形。
如上图所示,我们会存在一个大小恰好“跨过”\(s_u/2\) 的叶子(红色部分)。我们认为这个叶子被分给右儿子。那么:
\[\begin{gathered} s_{lc_u}=a\le \frac{s_u}{2} \\ s_{lc_{rc_u}}\le \frac{b+c+d}{2}\le \frac{s_u}{2} \\ s_{rc_{rc_u}}\le d\le \frac{s_u}{2} \end{gathered} \]那么,\(u\) 的儿子的儿子大小一定不超过 \(s_u/2\)。于是这部分对深度的贡献是 \(O(\log n)\)。
分析常数的话,由于一个节点向上跳两次大小至少翻倍,所以是 \(2\log n\)。
按照这种方法构建出的 Top Tree 具有一些很好的性质:
- 所有簇的界点都有祖先关系。
- 簇的上界点为整个簇中深度最小的点。
- Compress 树的中序遍历是按照深度升序遍历。
Top Tree 是关于边的划分,而我们时常需要维护点的信息。为此我们可以定义:一个簇中包含其连通块中的所有除了上界点之外的点,这样每个点在每一层中最多属于一个簇。注意这样定义的话根节点会不属于任何簇,可以通过在根上加入一条额外边或者特殊考虑根来解决。
动态 Top Tree
动态 Top Tree,就是在静态 Top Tree 的基础上,支持一些新的操作:
- \(\operatorname{expose}(u,v)\):将根簇变为簇路径为 \((u,v)\) 的一个簇。
- \(\operatorname{link}(u,v)\):在 \(u,v\) 间连一条边,需要使得操作完仍然是森林。
- \(\operatorname{cut}(u,v)\):断开 \(u,v\) 间的边。
常见的实现动态 Top Tree 的方式是由 Tarjan 和 Werneck 在 2005 年的论文 Self Adjusting Top Trees 中提出的 SATT。由于其较为复杂且应用场景偏少,将在后续章节单独讨论(也可能不讨论)。
簇与 Top Tree 的性质
下面是一些后文常用的性质。我们约定,如果没有特殊说明,“簇”都指的是 Top Tree 上的簇。
- 任意两个簇,要么相互包含,要么两者的交最多只有一个点,且这个点是两个簇的共有的界点。
- 一个不是基簇的簇,其两个子簇恰好有一个共有的界点,我们称其为该簇的中心点。
- 经过一个簇的路径必定跨过该簇的界点。特别地,如果这个路径完全跨过了该簇,那么该簇的簇路径是其的一个子路径。
这些性质都比较直观,不赘述其证明。
静态 Top Tree 的应用
树上信息合并
Top Tree 提供了一种性质很好的划分结构,让我们能够在 Top Tree 上进行信息的维护。可以理解为,我们能够将 Top Tree 当做一种线段树的树上版本。
链上修改与查询
即,边上存有信息,多次询问一条链上的边的信息的和,或者给一条链上的信息进行修改。
我们考虑对于每一个簇 \(u\),维护其簇路径上的信息和,记作 \(f_u\)。显然这样维护是可以 pushup 的:
然后,对于一个查询 \((x,y)\),我们只需要找到一些簇,使得它们的簇路径的并恰好是路径 \((x,y)\)。
设 \(x,y\) 所在的基簇分别为 \(c_x,c_y\),找到 \(c_x,c_y\) 在 Top Tree 上的 LCA,设其为 \(w\)。那么 \(w\) 是极小的包含 \(x,y\) 的簇(根据 LCA 显然)。取 \(w\) 的中心点 \(p_w\),那么 \(u,v\) 的路径必然经过 \(p_w\)。
于是,我们可以把路径拆成两部分:\((u,p_w),(p_w,v)\)。现在问题转化为:我们要把一个点到一个界点的路径拆分为簇路径。这个问题是可以递归处理的。假设我们要拆分 \(u\) 到簇 \(k\) 的某个界点的路径,那么我们将试图把问题递归到 \(k\) 的两个子簇中包含 \(u\) 的那一个。分类讨论 \(k\) 是 rake 还是 compress 即可将问题递归下去。
子树修改与查询
子树的信息维护相比于链的要简单许多。因为上界点是一个簇中深度最小的点,所以我们只需要找到所有上界点包含于查询的子树内的极大的簇即可。
这个过程可以直接在 Top Tree 上 dfs,形式比较简单,不赘述。
维护动态直径
动态直径有一个经典的线段树方法,但是这种方法限制性太强。我们可以根据 Top Tree 的性质得到一个更加具有可扩展性的做法。
对于每一个簇,维护三个值:簇内部的最长距离及到两个界点的最长距离。信息的合并只需要考虑将两条路径拼接起来即可。我们可以发现,维护直径的方式与线段树维护最大子段和的方式有异曲同工之妙。
显然这种维护方法可以支持一些简单的修改,如修改单个边权。
例 1.1:【2023 集训队互测 Round 12】不跳棋
简要题意:给定 \(n\) 个节点的树以及初始为全集的点集 \(S\)。\(n-2\) 次操作,每次删除 \(S\) 中一个元素,并查询 \(S\) 中两两距离最小值以及最小值方案数,强制在线。\(n\le 5\times 10^5\)。
我们发现 Top Tree 维护最长距离的方法同样适用于最短距离,直接套用上面的做法容易做到在线 \(O(\log n)\) 单次修改。并且我们可以发现,这种做法不仅能够删点,同样可以加点。
例 1.2:Tree Queries
简要题意:给定 \(n\) 个节点的树以及 \(q\) 次询问,每次询问给定 \(x,k,a_1,a_2,\dots,a_k\),求在树中删除 \(a_1,a_2,\dots,a_k\) 及其连边后,在 \(x\) 所在连通块内距离 \(x\) 最远的距离。\(n,q,\sum k\le 2\times 10^5\)。
我们尝试实现动态在 \(a\) 中加入/删除一个数,这样容易实现原问题。问题转化成,求 \(x\) 能到达的最远距离,满足集合 \(a\) 中的元素不能被经过。
建出 Top Tree,仍然维护簇内部到两个界点的最远距离,不同的是,如果中心点在 \(a\) 中则不进行转移。查询的形式与 pushup 一致。时间复杂度 \(O(n+q\log n)\)。
维护动态重心
我们想要支持动态修改单点点权并查询整棵树的带权重心的问题(权值均为正)。
根据重心的性质,对于一个点 \(u\),如果 \(u\) 不是重心,那么重心一定在 \(u\) 的权值和最大的子树内(假设以 \(u\) 为根)。
考虑在 Top Tree 上二分来解决这个问题。假设我们现在已经知道重心在某个簇 \(u\) 以内,那么我们需要进一步判断重心在哪一个儿子。\(u\) 的儿子相当于把簇 \(u\) 关于其中心点划分成了两侧,那么根据上面的结论,我们只需要选择权值和较大的那一侧递归下去即可。
注意我们说的“权值和”是关于整棵树的,而不是关于簇内部的,即我们需要计算树上所有的点。因此在 Top Tree 上二分的过程中我们需要维护两个值 \(s_0,s_1\) 表示中心点两侧的权值和,递归到儿子的时候可以简单更新其值。
维护动态 DP
Top Tree 可以维护“边约束”的树上的动态 DP 问题。所谓“边约束”是指代价、限制可以写成关于边的相互独立的形式。
例 2.1:动态树上最大权独立集
简要题意:树上最大权独立集,a.k.a,没有上司的舞会,指选出一些点,使得这些点中没有相邻的,最大化点权和。现在给定大小为 \(n\) 的树以及 \(m\) 次修改点权的操作,需要在每次修改后求出最大权独立集。\(n\le 10^6,\ m\le 3\times 10^6\)。
对于一个簇 \(u\),设 \(f_{u,0/1,0/1}\) 表示只考虑 \(u\) 内的点,两个界点分别选/不选的最大权值和(如果上界点选了,权值不计算)。这样修改一个点就只会影响到一个基簇,更新信息的复杂度可以接受。
信息合并的时候,只需要满足中心点的状态相同即可进行转移:
- 对于 compress 节点:\(f_{u,x,y}\gets \max_{z\in\{0,1\}}\{f_{lc_u,x,z}+f_{rc_u,z,y}\}\)。
- 对于 rake 节点:\(f_{u,x,y}\gets\max_{z\in\{0,1\}}\{f_{lc_u,x,y}+f_{rc_u,x,z}\}\)。
于是 pushup 是 \(O(1)\) 的,总复杂度 \(O((n+m)\log n)\)。
维护距离问题
例 3.1:[NOI2022] 树上邻域数点
简要题意:交互题。给出一种抽象信息,其实际上表示一个簇,并给出 rake 和 compress 的操作。给定 \(n\) 个点的树以及 \(q\) 次询问,每次询问给出 \(x,d\),需要求出与 \(x\) 距离 \(\le d\) 的点组成的簇。要求预处理使用的操作次数为 \(O(n\log n)\),一次询问使用的操作次数为 \(O(1)\)。
建 Top Tree。对于一次询问 \(x,d\),找到包含 \(x\) 的大小 \(\le d\) 的最大的簇 \(c\)。那么问题可以转化为求 \(c\) 以及 \(c\) 外部与 \(c\) 的界点距离小于等于某个值的簇的信息并。并且因为选取的 \(c\) 是极大的,所以这个距离限制一定不超过 \(c\) 的父亲的大小。
设 \(f_{c,0/1,d}\) 表示簇 \(c\) 内部距离 \(c\) 的上/下节点 \(\le d\) 的点组成的信息并,\(g_{c,0/1,d}\) 表示簇 \(c\) 外部与界点同侧距离 \(c\) 的上/下节点 \(\le d\) 的点组成的信息并。那么可以先 dfs 一次,自底向上求出 \(f\),然后再 dfs 一次,自顶向下求出 \(g\)。因为 \(f,g\) 的 \(d\) 下标均不超过对应的簇大小,复杂度是 \(O(n\log n)\) 的。查询显然是 \(O(1)\) 的。
原题对操作限制较紧,需要精细实现。
例 3.2:Fun on Tree
简要题意:给定 \(n\) 个节点的树,点有点权。进行 \(m\) 次操作,每次操作给定 \(x,y,v\),表示将 \(y\) 子树中点的点权增加 \(v\),然后查询 \(\max_i\{\operatorname{dis}(i,x)-a_i\}\)。
点分树通常不适用于非单点的修改,但是 Top Tree 在这一方面则有优势。因为一个簇只有两个儿子,lazytag 的下传变得可能。和上一题的思路类似,我们直接对于每一个簇维护到其父亲的中心点的 \(dis-a_i\) 的最大值,并且维护整体加的标记。修改的时候在 Top Tree 上打懒标记,查询像上一题一样查询即可。
时间复杂度 \(O((n+m)\log n)\),空间复杂度 \(O(n)\)。
树分治
树分治,用以解决一类关于树上路径统计的问题。常见的树分治方法有点分治和边分治。点分治的主要思想是,选取当前分治区域的重心,统计跨过重心的路径,然后递归地处理重心分割出的子树。边分治的主要思想是,选取当前分治区域的中心边,统计跨过中心边的路径,然后递归地处理中心边分割出的子树。因为中心边不能保证切分的区域大小折半,所以边分治需要对树进行三度化来保证复杂度。
现在我们有了 Top Tree,我们可以衍生出一些新的分治方法。
Top Tree 分治
可以发现,树分治的核心思想在于选取一个“中心”,统计跨过“中心”的路径,然后递归处理。
我们发现,Top Tree 天然地给出了一个树分治的结构。我们可以从根簇开始,在处理到某个簇的时候,统计跨过其中心点,并且端点分别属于其两个子簇的路径,然后递归地处理两个子簇。
我们于是可以得到一种新的树分治方法,不妨称其为“Top Tree 分治”。这种树分治具有相当好的性质。对比于点分治,Top Tree 分治的分治中心只会把簇划分为两个部分,而点分治会划分为度数个部分。对比于边分治,Top Tree 分治不需要对原树进行额外处理就可以保证复杂度,而边分治需要进行三度化,通常会使得点数翻倍,并大大限制解决问题的能力。而且,Top Tree 分治的每个分治区域只会有两个界点,这会大大方便一些统计路径的过程。
当然 Top Tree 分治也有其弊端。首先,Top Tree 分治的深度和 Top Tree 深度一致,为 \(O(\log n)\),但是具有最高 \(2\) 的常数(见上文重量平衡 Top Tree 深度的证明),而点分治是严格的 \(\log n\),并且通常难以卡满。其二,Top Tree 分治是基于边的,有时需要保证在进行遍历时复杂度是边数而不是点的度数和,会加大实现的难度。
例 4:点分树
简要题意:给定 \(n\) 个节点的树,点有点权。进行 \(m\) 次操作,每次操作为修改一个点的点权,或者查询距离一个点 \(\le k\) 的点的点权和。\(n,m\le 10^5\)。
对原树建 Top Tree。对于每一个簇,维护一个树状数组,以到其父亲的中心点的距离为下标,以点权和为权值。修改可以直接修改从基簇到根簇的一整条链上的树状数组。查询时,仍然考虑基簇到根簇路径上的簇,对于其中每一个簇,统计跨过中心点的路径,那也就是在其链外的儿子的树状数组上查询。
时间复杂度 \(O((n+m)\log^2 n)\)。
Top Tree 上边分治
来自《浅谈静态 Top Tree 在树和广义串并联图上的应用》里的东西,算是比较另类的分治方法。
对于原树 \(G\) 及其 Top Tree \(T\),我们这样定义一个 \(T\) 的连通子图 \(T'\) 的收缩树:
- 考虑 \(T'\) 中深度最小的点,删去 \(G\) 中不在该点 Top Tree 上子树内的边,得到 \(G'\)。
- 对于 \(G'\) 进行 \(T-T'\) 中的簇操作,得到 \(G''\)(涉及已经被删的边的操作忽略)。
- 那么 \(G''\) 就是 \(T'\) 的收缩树。
较直观地理解就是将 \(T'\) 外部的边删掉,然后把 \(T'\) 所有叶子对应的簇替换为一条边。
我们考虑直接在 Top Tree 上进行边分治,分治时的状态是一个 Top Tree 上的连通子图 \(T\),记 \(T\) 的收缩树是 \(C_T\)。在 \(T\) 中选择一个中心边 \((x,fa_x)\),那么 \(\operatorname{subtree}(x)\) 对应 \(C_T\) 中的一个连通块。我们统计一个端点在该连通块内,另一个端点在其外的路径,然后递归到 \(\operatorname{subtree}(x)\) 和 \(T-\operatorname{subtree}(x)+\{x\}\)。
在分治过程中会有若干边界情况,主要是在界点处算重的问题。实际上是需要找到一种较为合理的把点分给簇的方式,一种方法是 \(T\) 包含 \(T\) 的收缩树的界点,且不包含 \(r\) 的界点,这样递归下去的形式比较好看。最后单独处理整棵 Top Tree 根界点的贡献。
由于 Top Tree 是二叉树,直接边分治即可。一个比较有用的性质就是这样分治和深度无关。
树分块
如果我们设定阈值 \(B\),那么我们可以在 Top Tree 上选出所有大小 \(\le B\) 的极大簇,这些簇构成了一个原树的划分。如果 Top Tree 是平衡的,那么选出的簇的个数是 \(O(n/B)\) 的。于是,我们得到了一种及其优秀的树分块方法。
由于每一块都是一个簇,具有簇的一系列性质,而且块数和块的大小均被严格保证,从而这种树分块方法具有非常宽泛的应用场景,可以在许多题目中大放异彩。
树分块的构建
我们可以直接建出 Top Tree 来得到一个划分。但是存在着更简单的方法(来自《浅谈一类树分块的构建算法及其应用》,周欣)。
首先,任选一个根进行 dfs。我们开一个栈,在 dfs 的过程中记录还未被划分的边。然后,在一个点 \(u\) 结束 dfs 的时候,如果满足下述条件之一,那么 \(u\) 是一个界点:
- \(u\) 是根;
- \(u\) 有至少两个儿子的子树内有界点;
- 栈的大小超过阈值 \(B\)。
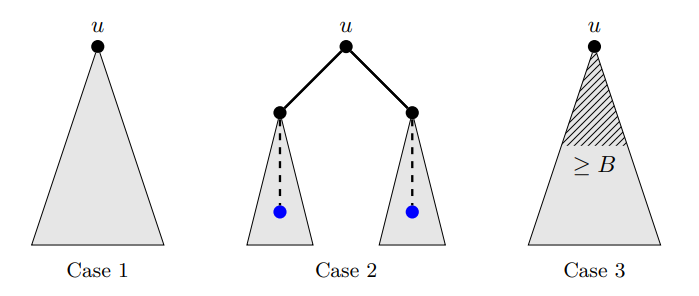
分析一下这三种情况的出现次数。情况 3 显然出现次数不超过 \(n/B\),而最后形成的收缩树的叶子个数不超过情况 3 出现次数,故三种情况的总出现次数不超过 \(2n/B\)。
然后,如果上述情况出现,我们需要将未归类的边划分成若干个簇。记 \(m\) 为 \(u\) 的儿子数,那么我们的问题形似给出两个长度为 \(m\) 的二元组序列 \((a_i,b_i)\),其中 \(a_i\) 表示第 \(i\) 个儿子子树中未归类边的数量,\(b_i\) 表示第 \(i\) 个儿子子树中是否存在界点,我们需要将序列划分成若干段,使得每段 \(a_i\) 的和 \(\le B\),并且存在最多一个 \(b_i=1\)。
一个简单并且正确的做法就是按顺序不断贪心地选取,不满足条件就新开一段。下面证明这种方法的复杂度:
显然每一个簇的大小不超过 \(B\),然后需要证明簇的数量。
贪心过程中,新开一段当且仅当满足以下条件之一:
- \(a_i\) 的和将会大于 \(B\);
- 段中将会有多于一个 \(b_i=1\);
- 序列剩余元素为空。
那么情况 1 出现次数不会超过 \(2n/B\),而情况 2,3 的次数和最终收缩树的大小一致,总出现次数为 \(2\times 2n/B\)。所以簇的数量不超过 \(6n/B\)。
距离相关的问题
处理距离相关的问题时,根据簇的性质,我们通常只需要处理与界点的距离的信息。
例 5.1:Neighbourhood
简要题意:给定 \(n\) 个节点的树,边有边权。进行 \(q\) 次操作,每次操作为更改一条边的边权,或者给定 \(x,d\),查询距离 \(x\) 边权和不超过 \(d\) 的点数。\(n,q\le 2\times 10^5\)。
树分块。对于每一块,将节点按照到界点的距离进行排序。修改的时候直接重构所在块。查询的时候自己所在的块内暴力,其它块计算距离差值之后二分。复杂度 \(O\left(n+m\left(B+\dfrac{n}{B}\log n\right)\right)\)。取 \(B=\sqrt{n\log n}\) 得到最优复杂度 \(O(n+m\sqrt{n\log n})\)。
例 5.2:[Ynoi2018] 駄作
简要题意:给定 \(n\) 个节点的树。定义 \(\operatorname{dis}(a,b)\) 表示 \(a,b\) 最短路径的点数。\(m\) 次询问,每次给出 \(u,v,d_1,d_2\),求 \(\displaystyle\sum_{\operatorname{dis}(u,x)\le d_1}\sum_{\operatorname{dis}(v,y)\le d_2}\operatorname{dis}(x,y)\)。\(n,m\le 10^5\)。
树分块。考虑点 \(u\) 的邻域如何表示,不难发现就是每一个簇中距离某个界点不超过某个距离的所有点。那么我们对于每一个簇,把其中的点按照到界点的距离排序,这样需要考虑的就是一个前缀。然后,把每个询问的 \(\operatorname{dis}(x,y)\)分成跨过簇的和包含于簇内的两种考虑。
-
对于跨簇的:
一条路径一定是,先簇内一段,经过若干条簇路径,再簇内一段。考虑拆贡献。对于每一条簇路径,统计其被多少个 \((x,y)\) 经过,这个可以直接在收缩树上 dfs 一次解决,复杂度 \(O(n/B)\)。然后对于每一个簇,统计出这个簇内的点向上/向下分别有形成多少个 \((x,y)\),然后分别乘上到上/下界点的距离和,前者复杂度是 \(O(n/B)\),后者可以 \(O(n)\) 预处理,查询时复杂度 \(O(1)\)。
-
对于簇内的:
设 \(f_{c,k_1,k_2,d_1,d_2}\) 表示在簇 \(c\) 中,距离第 \(k_1\) 个界点 \(\le d_1\) 的 \(x\),以及距离第 \(k_2\) 个界点 \(\le d_2\) 的 \(y\),\(\operatorname{dis}(x,y)\) 的和。那么一次查询就是 \(n/B\) 次查询 \(f\) 的单点值,所以一次查询需要做到 \(O(1)\)。考虑到 \(f\) 的总状态数是 \(O\left(\dfrac{n}{B}\cdot B^2\right)=O(nB)\) 的,我们能够直接预处理。枚举 \(c,k_1,k_2,d_1\),加入所有 \(x\),在簇内换根 DP 求出每个点 \(x\) 的 \(\sum_y\operatorname{dis}(x,y)\),然后顺次加入 \(y\) 即可求出所有 \(f\)。预处理复杂度 \(O(nB)\),查询复杂度 \(O(n/B)\)。
因此,总时间复杂度是 \(O\left(nB+m\cdot \dfrac{n}{B}\right)\) 的,取 \(B=\sqrt{m}\) 得到 \(O(n\sqrt m)\),离线处理即可 \(O(n)\) 空间。
例 5.3:[Ynoi2009] rpdq
简要题意:给定 \(n\) 个节点的树,边有边权,\(m\) 次询问 \(l,r\),求 \(\displaystyle\sum_{l\le x<y\le r}\operatorname{dis}(x,y)\)。\(n,m\le 2\times 10^5\)。
如果用树分块的话,和上题没有区别。
如果不用的话,不在本文探讨范围内。
子树相关的问题
一般而言,树分块后,子树 \(u\) 的查询会被分成两部分:\(u\) 在簇内的子树,以及 \(u\) 所在簇在收缩树上的子树。
例 6:[Ynoi2005] tdnmo
简要题意:给定 \(n\) 个节点的树,并定义有向邻域 \(N(x,y):=\{u\mid\operatorname{dis}(u,x)<y\}\)。现在有 \(m\) 个点集 \(N(x_i,y_i)\),你需要通过若干次操作来“到达”这 \(m\) 个点集。具体而言,你初始时有 \(S=\varnothing\),你可以进行以下操作:
- 令 \(S\gets N(x',y')\),需要满足 \(S\subseteq N(x',y')\),代价为 \(|N(x',y')|-|S|\);
- 撤销一次 \(1\) 操作,即回到之前最后一次未撤销的 \(1\) 操作前的位置,并将这次 \(1\) 操作标为已撤销;
- 声明当前到达了有向邻域 \(N(x_i,y_i)\),需要满足 \(S=N(x_i,y_i)\)。
最多使用 \(5m\) 次操作,代价和不能超过 \(2.5\times 10^9\),必须对于每个整数 \(i\in[1,m]\) 都进行过操作 3。\(n,m\le 10^6\)。
题目给出的操作其实类似于莫队的移动指针(大小为集合差值的代价可以理解为加点),整个过程正是使用“有向邻域莫队”回答 \(m\) 个询问。而 \(2.5\times 10^9\) 的代价限制也说明了复杂度是 \(O(n\sqrt m)\) 的。
进行树分块。对于所有处于同一个簇内的 \(x_i\),我们把这些询问一起处理。假设 \(x_i\) 所处的簇的上下界点分别为 \(p_0,p_1\),那么所有 \(N(x_i,y_i)\) 都是先“扩展”到 \(p_1\),再继续“扩展”一段距离。我们对于这些邻域计算出经过 \(p_1\) 之后还需要“扩展”的距离,并按照这个距离排序。
类比序列上的回滚莫队,我们也可以在树上做这件事情。把收缩树上子树内的节点按照到 \(p_1\) 的距离依次加入,然后在刚好达到某个询问的要求时,就再加入这个询问在簇内的部分,并回答这个询问。不难发现整个过程中的点集都是有向邻域,且复杂度分析和序列上的回滚莫队相同。
于是做完了。操作次数 \(O(m)\),代价和 \(O(n\sqrt m)\)。
Top Tree 的更一般性扩展
下面的内容在日常生活中及其罕见,并且有着人类难以接受的代码实现难度,建议抱着一定程度的理性愉悦的心情阅读。
新的簇操作:twist
为了将 Top Tree 扩展到更一般的图上,我们需要处理环的问题,因此我们定义新的簇操作 twist:
也就是说,将两条重边叠合称为一条边。

那么,我们就可以处理一部分的环了。
仙人掌上的 Top Tree
我们所说的仙人掌,是指所有边都最多出现在一个简单环中的连通图。多个仙人掌组成的图称为荒漠。
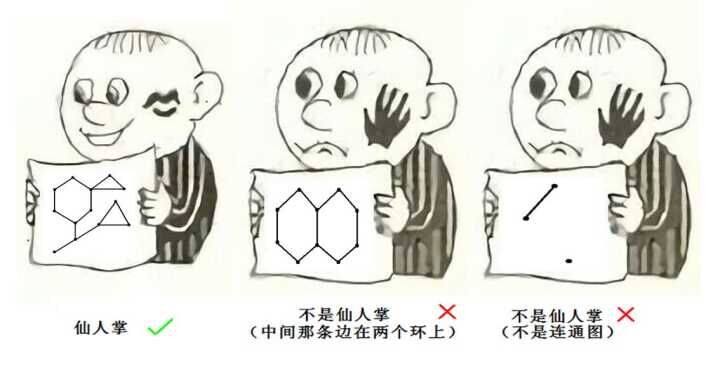
由于仙人掌上的问题较为罕见,所以下文的例题较少。
诚然,这并不说明我支持往官方比赛或者模拟赛里面塞仙人掌题。
Top Tree 的构建
显然 twist 操作是可以处理仙人掌的。
我们可以沿用全局平衡二叉树的思想,建出仙人掌的静态 Top Tree。我们可以在圆方树上树剖。对于轻边。按照簇大小带权分治地把环 compress 成两条边,然后 twist,然后分治地 rake 到重链上。然后在重链上,也类似地先把环分治地 compress 成两条边,然后 twist,最后分治地 compress 成一个簇。
树深度证明和树上情形类似,是 \(O(\log n)\) 的。
仙人掌上路径信息
大多数时候,我们需要处理的是 \((u,v)\) 之间的最短路径。
与树上路径类似地,我们也可以找到 \(u,v\) 在 Top Tree 上的 LCA,把路径分成两个到界点的路径,接着根据节点的类型以及端点的位置,将问题递归地解决。于是 \((u,v)\) 之间的路径可以划分成 \(O(\log n)\) 个簇路径。
例 7:静态仙人掌
简要题意:给定 \(n\) 个点 \(m\) 条边的仙人掌,\(q\) 次查询两点间最短路。\(n,q\le 10^5\)。
直接采用上面的方法,维护簇路径的长度即可,复杂度 \(O(n\log n)\)。
容易发现也可以支持链加之类的简单修改。
仙人掌上分治
在仙人掌上也可以使用 Top Tree 分治和 Top Tree 上边分治。
例 8.1:仙人掌路径计数
简要题意:给定 \(n\) 个点 \(m\) 条边的仙人掌,对于 \(k\in [1,n]\) 求长度为 \(k\) 的简单路径条数。\(n\le 10^5\)。
在 Top Tree 上分治,问题转化为计数到界点距离为 \(k\in[0,size]\) 的路径条数。由于在仙人掌上难以使用 dfs 来枚举路径(路径个数可以是 \(O(2^n)\)),所以我们需要先在 Top Tree 上递归求解。
设 \(f_{u,d}\) 表示在簇 \(u\) 中,从一个界点走到另一个长度为 \(d\) 的路径的方案数,\(g_{u,k,d}\) 表示在簇 \(u\) 中,距离第 \(k\) 个界点为 \(d\) 的路径方案数。转移和统计答案都是卷积。总复杂度 \(O(n\log^2 n)\)。
例 8.2:仙人掌动态点集长径/短径
简要题意:给定 \(n\) 个点 \(m\) 条边的仙人掌,边有边权。维护一个点集 \(S\),进行 \(q\) 次操作:向 \(S\) 中加/删点;修改一条边的边权;查询 \(S\) 中两两点间距离的最大/最小值。强制在线。\(n,q\le 10^5\)。
在树上使用 Top Tree 的方法(维护到界点的距离最值以及簇内部的距离最值)可以直接扩展到仙人掌上。twist 节点的转移与 rake, compress 唯一不同之处就是有两个共有界点,仍然可以 \(O(1)\) pushup。单点修改都是简单的,容易做到强制在线 \(O(\log n)\)。
仙人掌上动态 DP
“边约束”的动态 DP 可以直接沿用到仙人掌上。
例 9:仙人掌上动态最大独立集
简要题意:给定 \(n\) 个点 \(m\) 条边的仙人掌,点有点权,\(q\) 次修改点权后查询最大独立集。\(n,q\le 10^5\)。
直接在 Top Tree 上维护,设 \(f_{u,0/1,0/1}\) 表示簇 \(u\) 的两个界点分别选/不选的最大价值。pushup 的时候只需要满足共用的界点状态相同即可。
仙人掌分块
在 Top Tree 上截取出大小 \(\le B\) 的极大子树,会得到 \(O(n/B)\) 个块。这样分块形成的收缩树的形态也是一个仙人掌。
但是,到目前为止,没有任何仙人掌分块的题目,或者说,幸好还没有任何人毒瘤到出仙人掌分块的题目。
广义串并联图上的 Top Tree
对于一个连通图,如果其不存在四个点,使得这四个点之间两两都存在路径并且这些路径都边不交,那么这个图是一个广义串并联图。
更直观地,广义串并联图就是在图中找不到“形似”大小为 4 的完全图的子图的连通图。
更更直观地,广义串并联图就是能够用 rake, compress, twist 收缩为一条边的图。
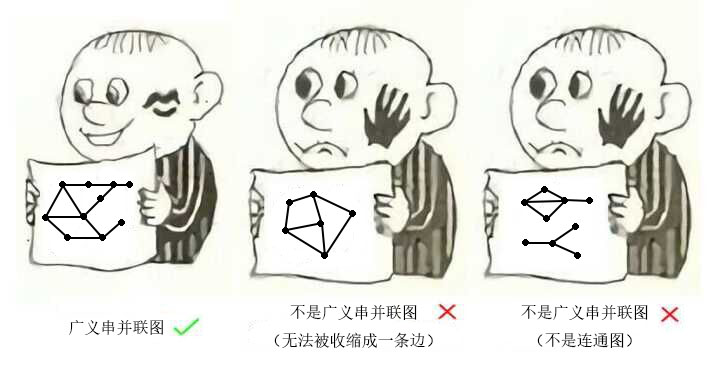
由于广义串并联图上的问题更为罕见,所以下文的例题更少。
诚然,这并不说明我支持往官方比赛或者模拟赛里面塞广义串并联图题。
Top Tree 的构建
我们尝试构建一个深度为 \(O(\log n)\) 的 Top Tree,然后你冥思苦想,不得其法,最后发现存在一张图:
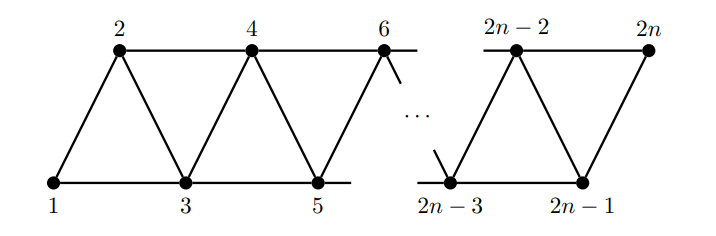
于是广义串并联图上的 Top Tree 深度不被保证,最高可以是 \(O(n)\) 的。那就没办法了,随便建一棵 Top Tree 吧。重复进行下述过程:
- 如果存在度数为 \(1\) 的节点,把与其相邻的边 rake 到另一条边上。
- 如果存在度数为 \(2\) 的节点,把与其相邻的两条边 compress 成一条。
- 如果存在重边,把它们 twist 成一条边。
那么我们最后一定会只剩一条边。整个过程的操作树就是广义串并联图的 Top Tree,又称串并联结构树。
广义串并联图上路径信息
大多数时候,我们需要处理的是 \((u,v)\) 之间的最短路径。
在广义串并联图上的路径信息实际上和仙人掌上没有区别,因为本质上都是只需要处理 twist 就行了。
但是,串并联结构树的深度是 \(O(n)\) 的,所以不能暴力维护,需要根据具体问题再上其它数据结构来处理。
例 10:广义串并联图上最短路查询
简要题意:给定 \(n\) 个点 \(m\) 条边的广义串并联图,\(q\) 次查询两点间的最短路长度。
我们建出 Top Tree,然后先 dfs 一遍,求出每个簇的两界点之间的最短路。对于一次查询 \((u,v)\),找到这两点在 Top Tree 上的 LCA,把问题转化为到界点的最短路。
到界点的最短路可以从基簇开始,不断向上进行递推,一直到 LCA 为止。这个递推可以看做有一个二维向量 \(\begin{bmatrix}d_0\\ d_1\end{bmatrix}\) 表示到两个界点的距离,一次递推可以写成左乘一个矩阵,其中乘法为 \((\max,+)\) 矩阵乘法。问题转化为求链上矩阵乘积,于是可以用倍增解决。复杂度 \(O((n+q)\log n)\)。
广义串并联图上动态 DP
在广义串并联图上,“边约束”的问题仍然有办法高效解决。
我们将“边约束”问题抽象化:在原图上,每个点 \(u\) 状态 \(s_u\in S\),且 \(|S|=k\)。一条边 \(e=(u,v)\) 的价值是 \(c_{e,s_u,s_v}\)。我们已知 \(c\),目的是给每个点分配一个 \(s_u\),最大化所有边的价值和(可以通过将 \(c_{x,y}\) 赋值为 \(+\infty/-\infty\) 来刻画必须选、不合法之类的限制)。
那么,我们建出图的 Top Tree,设 \(f_{u,s_0,s_1}\) 表示当簇 \(u\) 的两个界点状态为 \(s_0,s_1\) 时,簇内部的最大价值。那么对于基簇,\(f_{e,s_0,s_1}=c_{e,s_0,s_1}\),而对于非基簇,只要满足共用界点状态一致就可以从儿子转移。
我们转化一下问题:Top Tree 上的一个节点 \(u\) 有一个状态 \(t_u\in S\times S\),即两个界点的状态组成的二元组,并且 \(t\) 要满足如下限制:
- 对于叶子,价值为 \(c_{e,t_e}\)。
- 对于 Top Tree 的一对父子,如果共用界点的状态一致,价值为 \(0\),否则价值为 \(-\infty\)。
- 对于 Top Tree 的一对兄弟,如果共用界点的状态一致,价值为 \(0\),否则价值为 \(-\infty\)。
贡献是关于父亲的兄弟的。我们可以对 Top Tree 进行轻重链剖分。设 \(g_{u,t}\) 表示 Top Tree 上 \(u\) 的状态取 \(t\) 时,子树内价值和最大值。那么在一条重链上的转移是一个 \((\max,+)\) 矩阵乘法。用线段树维护是 \(O(\log^2n)\) 的,使用全局平衡二叉树技巧可以做到 \(O(\log n)\)。
原图的状态数为 \(k\),Top Tree 的状态数就是 \(k^2\),矩阵乘法的复杂度是 \(O(k^6)\) 的。那么总复杂度是 \(O(k^6(n+q\log n))\)。
还有一个特别傻逼的做法是,把兄弟之间的限制连一条边,然后得到仙人掌,直接用 Top Tree 做仙人掌上的“边约束”问题。
例 11:【2019 集训队互测 Round 3】公园
简要题意:给定 \(n\) 个点 \(m\) 条边的广义串并联图。你需要给每个节点赋权 \(a_i\in\{0,1\}\)。对于第 \(i\) 条边,若两个界点权相等,则有 \(c_i\) 的价值,否则有 \(d_i\) 的价值;对于节点 \(i\),若 \(a_i=0\) 则有 \(w_i\) 的价值,\(a_i=1\) 则有 \(s_i\) 的价值。你需要最大化价值和。有 \(q\) 次对 \(c,d,w,s\) 的单点修改,在每次修改后输出答案。\(n,m,q\le 10^5\)。
这里的价值就是典型的“边约束”形式。直接使用上面的做法即可。复杂度 \(O(2^6(n+q\log n))\)。
广义串并联图上分治
由于串并联结构树深度为 \(O(n)\),使用类似“跨过中心点”的分治方法不再能保证复杂度。但是 Top Tree 上边分治是可行的,因为其复杂度与深度无关。
我们首先需要重新定义一下 Top Tree 上连通子图 \(T\) 的收缩图。首先类似于树上的情形,我们找到 \(T\) 中深度最小的节点 \(r\),然后删去原图中不在 \(\operatorname{subtree}(r)\) 中的边,最后进行所有 \(T-T'\) 中的操作。但是这样会产生问题:即使一条路径的两个端点都在 \(\operatorname{subtree}(r)\) 中,其经过的边也可能在子树外。这样的路径形如,起点 \(u\) 经过子树内的边走到界点 \(b_0\),然后经过子树外的边走到界点 \(b_1\),然后在子树内走到 \(v\)。
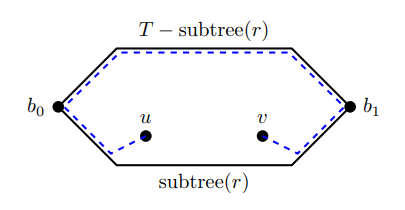
我们选取子树外部与 \(b_0,b_1\) 均连通的部分,那么这个子图一定也是一个广义串并联图。如果维护的信息允许,我们可以把这个子图等价成一个界点为 \(b_0,b_1\) 的簇,称作外部簇。
在向下递归的过程中我们需要进行外部簇的维护。记 \(T'=\operatorname{subtree}(r)\)。我们已经求出了 \(T\) 的外部簇,那么在绝大多数情况下,我们只需要花费与 \(|T-T'|\) 相关的时间即可计算出 \(T'\) 的外部簇。
例 12:【集训队互测 2021】逛公园
简要题意:给定一张 \(n\) 个点 \(m\) 条边的带边权的广义串并联图。\(q\) 次查询,每次给定一个点集,查询点集中两两最短路之和。\(n,q\le 10^5\),询问点集大小之和 \(\le 10^5\)。
我们在广义串并联图上进行分治。假设正在处理子图 \(T\),下一步选择了节点 \(r\),其界点为 \(b_0,b_1\),记 \(T'=\operatorname{subtree}(r)\)。暴力枚举所有与 \(T\) 相关的询问及其点集在 \(T\) 内的部分,复杂度是 \(O(n\log n)\),可以接受,那么我们就对每个询问分开讨论。
设点 \(u\in T'\),\(v\in T-T'\),那么点 \((u,v)\) 的最短路必然是 \(u\leadsto b_0\leadsto v\) 或 \(u\leadsto b_1\leadsto v\),长度就是 \(\min\{\operatorname{dis}(u,b_0)+\operatorname{dis}(b_0,v),\operatorname{dis}(u,b_1)+\operatorname{dis}(b_1,v)\}\)。列出不等式并移项,即可转成各自和 \(u,v\) 相关的偏序关系,在簇内部跑出 \(b_0,b_1\) 的单源最短路后,可以使用排序双指针计算。
还需要考虑一下外部簇的影响。因为所有路径都会完全经过外部簇,所以外部簇可以被等效成一条边,边权为外部簇两界点的最短路。那么在递归到 \(T'\) 和 \(T-T'\) 之前,只需要知道 \(b_0\leadsto b_1\) 的最短路就行了。
每层分治需要跑最短路,复杂度 \(O(n\log^2 n+q\log n)\)。
广义串并联图分块
Top Tree 的深度不被保证,因此截取子树的方法不再使用。
但是,我们可以对 Top Tree 本身进行树分块,每一个 Top Tree 上的块对应的收缩图就是广义串并联图上的一个块。
这个过程及其抽象而扭曲,建议慢慢理解,不能理解就别理解了,没用的。
尝试观察一下这种分块方式的性质,对于块 \(C\):
- 块的点数和边数均为 \(O(B)\),块数为 \(O(n/B)\)。
- \(C\) 可以收缩成在 Top Tree 上该块最浅节点对应的簇,该簇的两个界点称为 \(C\) 的外界点。
- 原图每一个点最多作为非外界点在一个块内出现。
- 块 \(C\) 最多和两个块在非外界点处有交,这两个块是 \(C\) 对应 Top Tree 上块的下界点的两个儿子。因此,这两个块必然能够立即收缩成一个簇,于是其与 \(C\) 相交的部分只有两个点,称这两个点为 \(C\) 的内界点。
这个分块和传统理解的分块不一样。块与块之间并不是完全不交的,可以有包含关系。
例 13:广义串并联图上邻域数点
简要题意:给定 \(n\) 个点 \(m\) 条边的广义串并联图,边有边权。进行 \(q\) 次操作:
- 给定 \(i,c\),修改第 \(i\) 条边边权为 \(c\);
- 给定 \(x,d\),查询到 \(x\) 最短路径长度 \(\le d\) 的点数。
\(n\le 10^5,q\le 3\times 10^4\)。
解法自己看参考资料 [2]。
复杂度为 \(O\left((q\sqrt n+n)\log^3 n\right)\) 或 \(O\left(\dfrac{nq}{w}+q\sqrt n\log n\right)\)。
动态 Top Tree 及其应用
终于到了这一部分了,但是我先咕着,先把目录结构写好新建文件夹。
Self-Adjusting Top Tree
【记得填坑】
Weight-Balanced Top Tree
【记得填坑】
参考资料
读者有兴趣的可以自行查找相关资料。
实际上资料很少,下面已经是能找到的大部分有用资料了。
- [1] Robert E. Tarjan, Renato F. Werneck. Self-Adjusting Top Trees, 2005.
- [2] 程思元。《浅谈静态 Top Tree 在树和广义串并联图上的应用》,2023 国家集训队论文集。
- [3] 周欣。《浅谈一类树分块的构建算法及其应用》,2021 国家集训队论文集。
- [4] negiizhao。《Top tree 相关东西的理论、用法和实现》,https://negiizhao.blog.uoj.ac/blog/4912。
- [5] negiizhao。《用于仙人掌的 Top Trees》,https://zhuanlan.zhihu.com/p/32413108。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号