【知识点】KMP算法详解
KMP算法
算法简介
KMP算法,即看毛片 \({Knuth-Morris-Pratt}\) 算法。是由三位计算机科学家 \(D.E.Knuth、J.H.Morris、V.R.Pratt\) 提出的。该算法可以在 \(O(n+m)\) 的时间复杂度内查找一个字符串在另一个字符串中的位置。
KMP算法的基本原理就是寻找模式串的公共前后缀,以优化时间复杂度。
算法原理
盗用百度的图片(推荐阅读)
首先,假设我们有一个字符串和一个需要比对的“模式串”,如图:
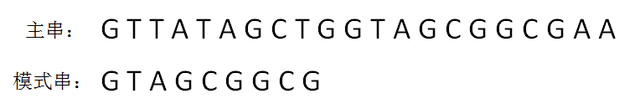
首先,我们一个华(bao)丽(li)的开头,就是把模式串与子串进行逐位匹配:
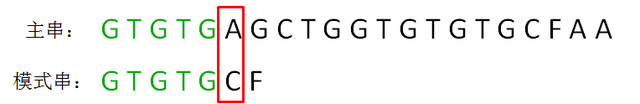
但是我们发现第六个字符不匹配。
按照传统的思路,我们需要将模式串右移一位,然后继续诸位比较。但是KMP算法是一个毒瘤高级算法,怎么能容忍如此赤裸裸的暴力呢?
我们发现目前已经匹配的子串中,前缀和后缀都是一样的,都是“GTG”:

所以我们惊讶地发现,我们可以直接把模式串右移到最长可匹配后缀的位置,然后继续愉快的比较
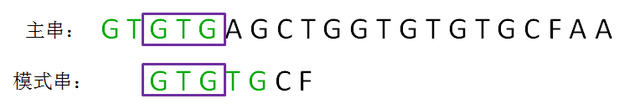
可是又出现了一个“坏字符”,我们应该如何处理呢?
没错,继续寻找可匹配最长前缀和后缀,然后再次移动模式串。

以此类推。这就是KMP算法的流程。
原理应该理解了,那么要如何实现呢?
算法实现
一、\(nxt\) 数组
\(nxt\) 是一个一维整型数组,数组的下标代表了“已匹配前缀的下一个位置”,元素的值则是“最长可匹配前缀子串的下一个位置”。如图所示:
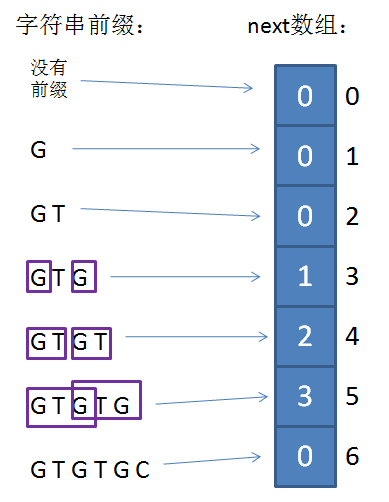
其中,由于子串“G”、“GT”、“GTGTGC”没有可匹配的前缀和后缀,所以对应的 \(nxt\) 值为 \(0\)。
只要我们求出 \(nxt\) 数组,我们就可以解决寻找最长可匹配前后缀并移动模式串的问题了。
相信聪明的你已经理解了
二、求出 \(nxt\) 数组
我们设两个变量,\(i\) 和 \(j\) ,它们分别表示“已匹配前缀的下一个位置”,也就是待填充的数组下标,和“最长可匹配前缀子串的下一个位置”,也就是待填充的数组元素值。它们的初始值如下:
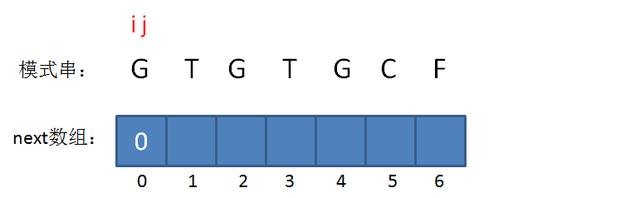
求出 \(nxt\) 数组的过程,就是用模式串“自己匹配自己”。
首先,我们让 \(i++\) 。
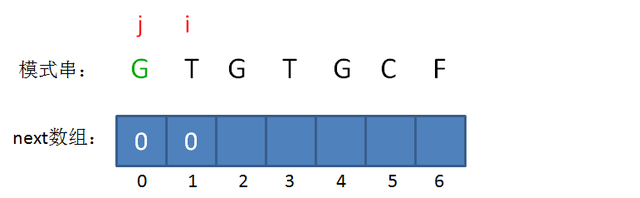
此时,一匹配子串长度为 \(1\) ,不存在可匹配后缀,故 \(nxt[1]=0\)。
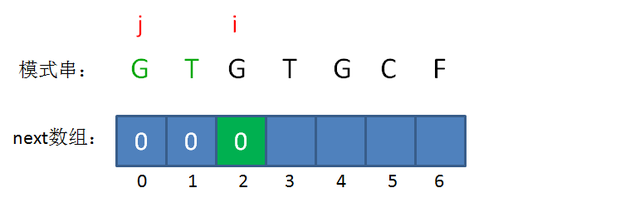
我们令 \(i\) 继续 \(+1\)。
可以发现,最长可匹配前后缀子串仍不存在,所以 \(nxt[2]=0\)。
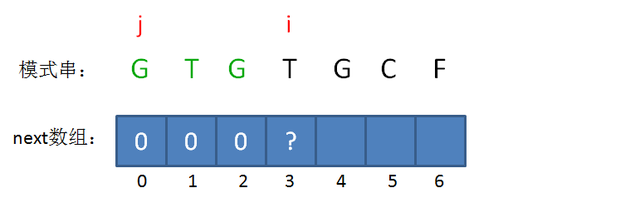
当 \(i\) 又一次加一时,我们发现此时的模式串 \(s\) 中存在 \(s[j]=s[i-1]\) ,于是 \(nxt[3]=nxt[2]+1=1\) 。
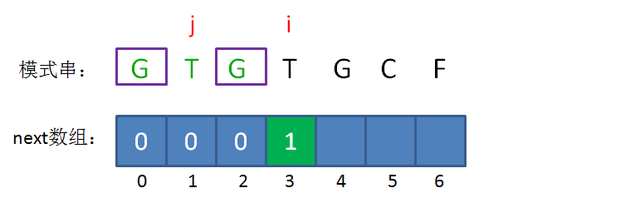
现在,我们需要让 \(i,\ j\) 都加一。
我们惊讶的发现,\(s[j]=s[i-1]='T'\) ,所以可匹配最长前后缀子串的长度加一,即 \(nxt[4]=nxt[3]+1=2\)。

当 \(i,\ j\) 再次同时加一后,我们找到了 \(s[j]=s[i-1]='G'\),所以 \(nxt[5]=nxt[4]+1=3\)
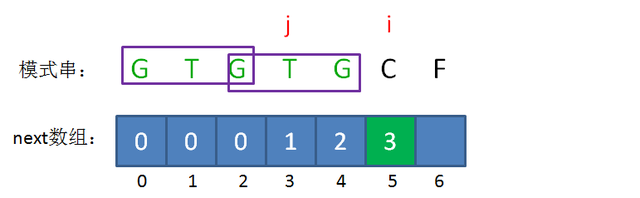
可是此时的 \(s[j]\) 和 \(s[i-1]\) 不匹配了,怎么办呢?
按照套路,应该移动模式串了。如何移动?简单地移动一位吗?当然不,我们令 \(j=nxt[j]\) 。
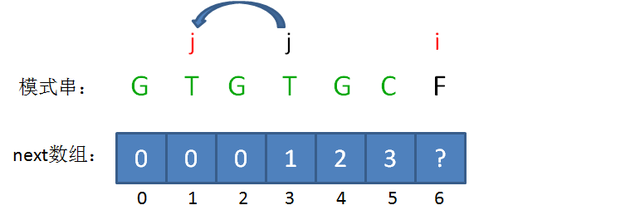
可是天不从人愿,我们发现字符仍然不匹配。所以再次使 \(j=nxt[j]\) 。
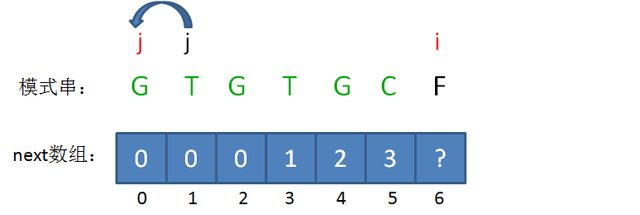
此时, \(j\) 已经无法回溯,所以 \(nxt[6]=0\), \(nxt\) 数组就求出来了。
推导完毕。匹配的过程也类似。
建议将 \(nxt\) 数组的推导多看几遍,这样可以加深理解。因为 \(nxt\) 数组的推导过程是KMP算法最反人类核心的地方。
具体代码实现
\(\mathtt{Talking\ is\ cheap,\ show\ me\ the\ code.}\)
void KMP(char *s1,char *s2)
{
/* KMP算法
* @params s1为主串,s2为模式串,l1,l2分别是它们的长度
* @from 代码来自Luogu P3375,是一道KMP模板题
*/
int l1=strlen(s1),l2=strlen(s2);
int j=0;
for(int i=2;i<=l2;i++)
{
while(j && s2[i]!=s2[j+1])
j=nxt[j];
if(s2[i]==s2[j+1]) j++;
nxt[i]=j;
}
j=0;
for(int i=1;i<=l1;i++)
{
while(j && s1[i]!=s2[j+1])
j=nxt[j];
if(s1[i]==s2[j+1]) j++;
if(j==l2)
printf("%d\n",i-l2+1),j=nxt[j];
}
}
注:\(Galax OJ\) 的 \(KMP\) 练习题题解已经在路上啦~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号