
自动写提示词:DSPy.MIPROv2的介绍与实践(附代码)
引言
此前,笔者曾分享过自动写prompt的论文,本文则开展实践工作,用DSPy.MIPROv2来自动写提示词。
本文包含两部分内容:
- 介绍DSPy.MIPROv2优化器的原理和主要参数;
- 在AI生成文本检测任务上实践。
本文的所有代码已上传git:
https://github.com/duanyu/dspy-study
介绍DSPy.MIPROv2
原理
MIPROv2是DSPy的主打提示词优化器,源自这篇论文:
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs:
https://arxiv.org/pdf/2406.11695
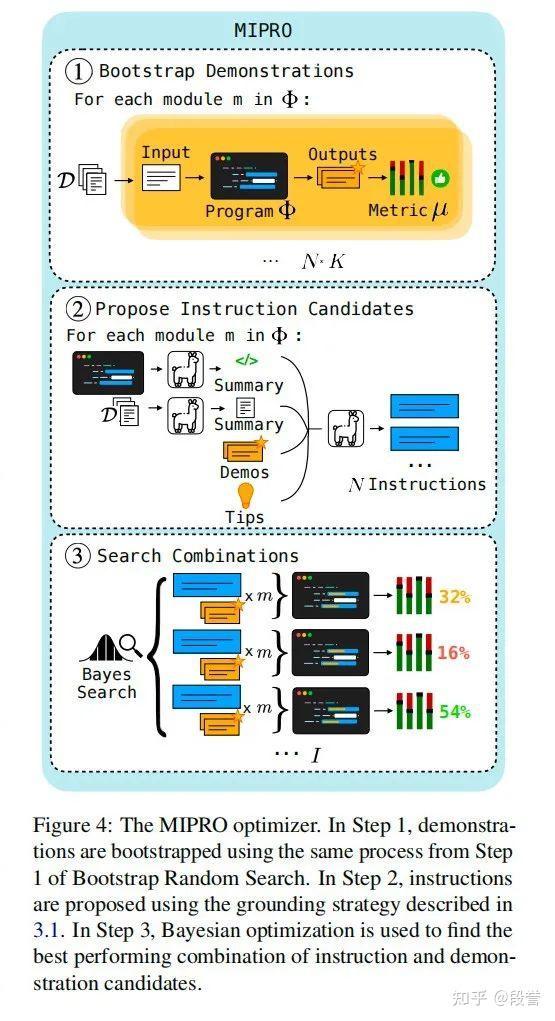
MIPROv2优化器主要包含以下三个步骤:
- Step1: Bootstrap few-shot examples。首先X -> LLM Program -> 中间结果 + Y_pred,然后判断Y_pred是否满足metric要求,将满足要求的(X, 中间结果 + Y_pred)作为few-shot examples;这里中间结果包括CoT、workflow链路上中间节点的输出等。换句话说,无论workflow多长,只需提供X + 最终结果Y + metrics,便能自动构建全链路的examples;
- Step2: Propose instruction candidates。生成N条候选instruction;输入dataset description(由单独的LLM总结而成)、program code、program description(也由单独的LLM总结而成)、task demos(input-output examples)、tips(生成prompt的提示,有6类,如creative/simple/description/high_stakes/persona)等,输出instruction prompt;在每次生成时采样不同的task-demos和tips,以增强instruction candidates的多样性;

- Step3: Find optimal prompt parameters。将Instruction prompt和few-shot examples视为两个优化参数,采取Bayesian Search方法找到最优参数组合;此处也可以选择不使用few-shot examples、仅寻找最佳Instruction prompt。
主要参数
DSPy的文档[1]还比较简略,于是笔者研究了MIPROv2的代码,将一些常用参数的含义罗列如下,让大家少走弯路。
在DSPy(2.5.43版本)中,MIPROv2的初始化、compile阶段主要有以下参数:
- task model。最终用来执行任务的模型,调优后的提示词在这个model上使用;
- auto。取值light/medium/heavy,代表逐级递增的三种自动优化力度(力度越强,搜索的空间越大、耗时越长、越费token),控制num_trials(Step3中的实验次数,light=7,medium=25,heavy=50)、val_size(dev set的最大样本数,light=100,medium=300,heavy=1000),并自动设置num_candidates(Step1和Step2时,生成的候选examples和instruction的组数);该参数也可设置为None,此时需手动传参num_trials、num_candidates,更为灵活,且不再限制val_size大小;
- num_trials。见“auto”参数释义;
- num_candidates。见“auto”参数释义;
- num_threads。同时跑n个线程,加快速度;
- seed。随机种子;
- verbose。是否展示优化过程的日志;要了解原理,看一次就懂了。
- Teacher Settings。Step1时用来Bootstrap examples的模型,通常选择强模型;
- max_bootstrapped_demos。Step1时,以bootstrap方式生成examples的数量上限(每组生成时会在1到max_bootstrapped_demos中随机采样一个数目);
- metric_threshold。在Step1中,超过这一threshold的才被当作bootstrapped examples;若metric返回得分,则需要提供这个参数;若metric返回是/否,则无需提供(常见于有标准答案的场景,如分类、选择题等);
- max_labeled_demos。若此值>0,说明有labeled demos,此时在Step1时有一组会直接将其作为demos_candidate;
- 若同时设置max_bootstrapped_demos=0、max_labeled_demos=0,则表示在优化时不引入few-shot examples,而只搜寻最佳instruction prompt,可认为是zero-shot MIPROv2。
- Prompt Model。Step2中用来生成Instruction的模型,通常选择强模型;
- init_temperature。表示Step2时,prompt model的温度;
- view_data_batch_size。Step2时采取batch的方式,用一批一批data来生成dataset observation,然后将所有的observation合并,一次生成dataset description,此参数设定batch size。
- minibatch。本意为Step3时是否在dev set上采取mini-batch的方式来挑选参数,但只在“auto”参数设置为空时才生效;当“auto”参数不为空、val size大于50时,minibatch始终为True,设置无效;
- minibatch_size。与上一个参数关联,表示mini-batch的大小;
- minibatch_full_eval_steps。Step3时,每N个step将此前最优的prompt在完整的dev set上进行测试。
实践:AI生成文本检测
AI如何区分AI/人类的文本?
笔者选取AI生成文本检测任务,使用zero-shot MIPROv2(仅写instruction prompt部分),看看AI的理解能力如何。
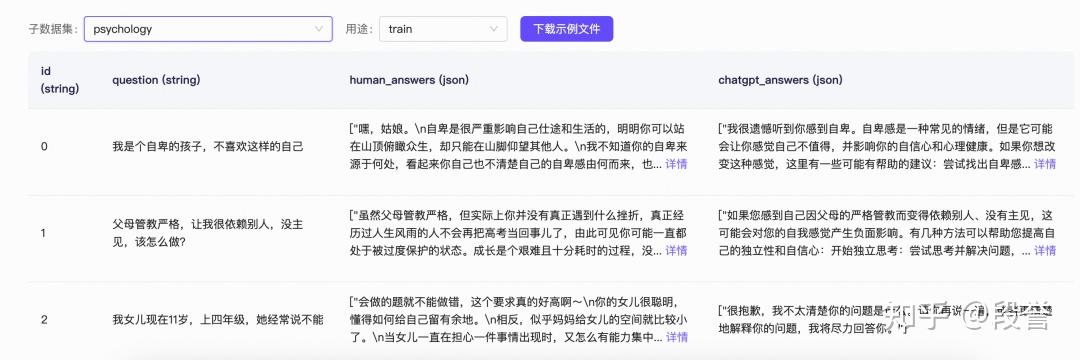
数据集地址:
https://modelscope.cn/datasets/simpleai/HC3-Chinese/summary
数据大概长这样:
实验设置:
- task model:qwen2.5-coder-7b-instruct
- prompt model:qwen2.5-coder-32b-instruct
- teacher model:qwen2.5-coder-32b-instruct
- api:所有适配openai-sdk的都可使用,笔者用的是硅基流动
- 训练集/验证集/测试集大小:10/100/100;与ml不同,在数据量较少时,请优先保证验证集的数量,以防止overfitting现象
- auto='light'
- 仅使用instruction proposal能力,不使用few-shot examples
- minibatch_size = len(val)
- 使用CoT
等待十几分钟、花费不到一毛钱之后,模型写出了这样的instruction:
Given a question and an answer, carefully analyze the tone, empathy, metaphorical language, and overall style of the answer to determine whether it is more likely to have been produced by a human or an AI. Provide a reasoning that details your thought process, and output the label as either 'human' or 'ai'. Consider human responses as subjective, often storytelling-based, and emotionally resonant, while AI responses are typically structured, practical, and professionally written.
翻译为中文如下:
给定一个“问题”和一个“答案”,仔细分析“答案”的语气、同理心、隐喻性语言以及整体风格,以确定它更可能是人类还是AI产生的。提供一个“推理”过程,详细说明你的思考过程,并输出“标签”为“人类”或“AI”。考虑到人类的回应通常是主观的,基于故事讲述,并且情感上富有共鸣,而AI的回应则通常是结构化的、实用的和专业写作的。
MIPROv2确实找到了该任务的规律。
在实验测试集中,这个提示词能提升识别准确率(acc从60% -> 70%+ 不过注意测试集仅有100条)。
本次实验的代码如下:
https://github.com/duanyu/dspy-study
注意,实验具有随机性,每次实验时生成的prompt都是不一样的。
若读者要在自己的任务上进行实验,以下是建议:
1. 在成本可接受范围内,选择最强的模型作为prompt model、teacher model;
2. 优先保证dev set的数量和质量,这是防止overfitting的关键;
3. MIPROv2善于归纳任务的通用规律,若要针对性解决badcase,仍需人工调prompt、或引入few-shot examples。
最后
本文介绍了DSPy.MIPROv2优化器的原理和常用参数,并进行了一次自动写提示词的动手实践。
推荐读者也进行动手实践,看看AI写的prompt能否提供不一样的思路,同时培养构建训练集/验证集/测试集 + 衡量指标(metric)的习惯。
欢迎关注
欢迎关注公众号「漫谈NLP」,了解有趣有用的NLP知识,一同探索技术的价值与边界:)
参考资料
[1] dspy文档: https://dspy.ai/
posted on 2025-02-26 22:49 ExplorerMan 阅读(445) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号