
2024年大模型多智能体workflow技术之Multi-Agent Debate,Acc-Debate,DebateTune,ChatEval,COEVOL,GroupDebate,CMD等
最近看了一些关于agent debate相关的内容,觉得挺有意思的(跟我以前做的对比学习很像,可以认为是大模型推理阶段的生成式对比学习),所以就把我的理解分享出来,也欢迎大家的匹配指正。现有的debate(一种Agentic Workflow)策略分为3步,第一步就是对给定的问题生成解决方案,第二步就是多轮相互discussion(辩论的回合数越多,消耗的token越多,越费时间和money),第三步在discussion的基础上进行投票表决。本质上,agent debate能力涉及到了LLM本身的角色扮演(角色扮演能够提升debate的效果),多轮对话,长序列指令遵循等能力,如果模型把这些能力训练好,debate能力就具备了前置条件了(至少两个智能体的多轮对话debate能够做了)。现有的debate研究都是一些策略,除了能够消除推理的幻觉(hallucinations),做事实性校验(fact checking)外,还能构建多个LLM的agent通过debate 策略提升数据生成的质量,优化SFT(例如Debatetune,DebateGPT),另外,有人研究了debate策略的拓扑结构,通过简单的debate拓扑结构能够减少token消耗,提升模型的精度(Group Debate),还有人研究了debate后达成一致的投票过程加了置信度(weighted),使用不同的LLM(ChatGPT, Bard, Claude2等)作为agents,典型的有RECONCILE,DebUnc;还有人研究了在discussion出现平局的情况下引入了一个秘书(secretary)来做最终的结论,典型的是(CMD);此外,有研究在disscussion阶段注入RAG知识来打破认知孤岛(cognitive islands,挺有意思的概念),典型的就是MADKE,最后,有人就是直接在训练里面加入debate策略(Acc-Debate),都是一些不错的探索。其实,有人在看debate初始化的时候,需要使用LLM做多次reasoning,感觉就是self-consistency+投票表决,其实只是初始化差不多,MAD还有多轮的迭代对话等等,但是两个策略关系很密切。
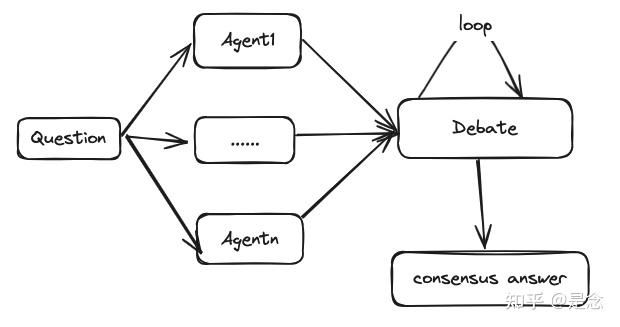
与单智能体相比,MAD在推理上有下面这几个优势:
1.多样化的视角:多智能体辩论允许模型通过与提供意见的其他智能体互动来考虑不同的观点;
2.增强推理:通过辩论的互动,模型有机会挑战假设,建立更强有力的论据来提升推理过程;
3.错误更正:可以通过辩论框架内的相互讨论来识别和纠正各个智能体之间的不一致的结论和错误;
4.性能提升:与单智能体方法相比,MAD利用的是群体智慧,通常会提升模型的整体性能。
也有人会问,single agent会很差吗?这个不一定,single agent有strong prompt的时候能够达到和multi agent相同的效果(CMD论文的观点),在没有few shot情况下,multi agent的效果是比single agent好很多的。由于文章篇幅的限制,DebateGPT相关的内容,就不做重复介绍了,有兴趣可以参考我以前写的agent tuning相关的文章,欢迎大家批评指正:
Should we be going MAD? A Look at Multi-Agent Debate Strategies for LLMs
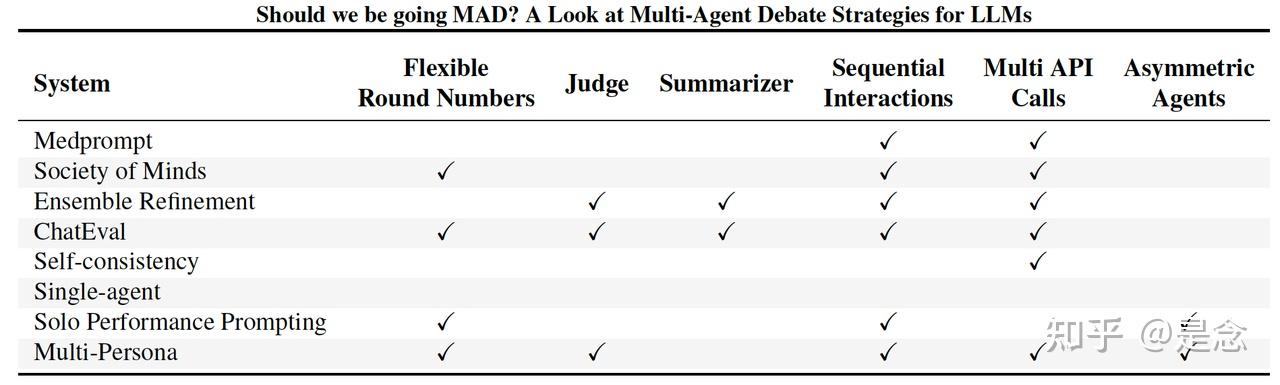
这篇轮文最大的特点就是比较了现有主流的一些agent debate策略的效果,方便读者了解这个领域的进展。大型语言模型 (LLM) 的最新进展凸显了它们在各个领域响应查询的潜力。然而,确保生成agents提供准确可靠的答案仍然是一个持续的挑战。在这种背景下,多agents辩论 (MAD) 已成为一种有前途的策略,可提高 LLM 的真实性。论文还对一系列辩论和提示策略进行了基准测试,以探索成本、时间和准确性之间的权衡。重要的是,目前形式的多agent辩论系统并不能可靠地胜过其他提议的提示策略,例如自洽和使用多种推理路径的集成。然而,在执行超参数调整时,多个 MAD 系统(例如 Multi-Persona)表现更好。这表明 MAD 协议可能本质上并不比其他方法差,但它们对不同的超参数设置更敏感并且难以优化。基于这些结果,提供改进辩论策略的见解,例如调整agent协议水平,这可以显著提高性能,甚至超越其他非辩论协议。
论文链接:

代码链接:
Can LLMs Speak For Diverse People? Tuning LLMs via Debate to Generate Controllable Controversial Statements
让 LLM 代表不同群体(尤其是少数群体)发声,并生成支持他们多样化甚至有争议的观点的陈述,对于营造包容性环境至关重要。然而,现有的 LLM 对其生成内容的立场缺乏足够的可控性,往往包含不一致、中立或有偏见的陈述。本文提高了 LLM 在生成支持用户在提示中定义的论点的陈述方面的可控性。两个立场相反的 LLM 之间的多轮辩论会为每个辩论生成更高质量、更突出的陈述,这些陈述是提高 LLM 可控性的重要训练数据。受此启发,论文提出了一种新颖的辩论与调整(DEBATUNE)pipeline,对 LLM 进行微调以生成通过辩论获得的陈述。为了研究 DEBATUNE,论文整理了迄今为止最大的辩论主题数据集,该数据集涵盖了 710 个有争议的主题以及每个主题对应的论点。 GPT-4 judge使用新颖的争议可控性指标进行的评估表明,DEBATUNE 显著提高了 LLM 生成多样化观点的能力。此外,这种可控性可以推广到未见过的主题,从而生成支持争议性论点的高质量陈述。
DEBATUNE 有两个主要阶段,即辩论和训练。在辩论阶段,DEBATUNE旨在通过多轮辩论,针对每个争议话题的每个立场,实现高质量、突出且多样化的陈述(由不同的论点引发)。在训练阶段,DEBATUNE 对 LLM 进行微调以适应每个陈述,并在输入指令中给出其相应的论点、立场和主题作为控制,从而提高 LLM 的可控性。
Debate: 尽管LLM最近取得了进展,但它们仍然难以囊括人类观点的广度和深度,特别是在分歧和有争议的话题上。辩论本质上鼓励探索和表达不同的观点,促进对主题的更全面理解。通过模拟辩论场景,其中LLM被编程为争论一个话题的对立面,目标是捕捉更广泛的观点,并为每种观点获得更高质量、更有力的陈述。
虽然单轮生成可能无法产生强有力的陈述,DEBATUNE方法中的多轮辩论机制会迭代地完善陈述,并可以得出支持给定少数派观点的突出陈述。具体来说,DEBATUNE将在系统提示上设置一个辩论环境,告诉Agents(Agent 1 和Agent 2)他们正在进行辩论,并且应该遵循他们在主题上的既定立场。在Agent 1 的初始生成过程之后,对手Agent 2 被提示思考Agent 1 的回答中可能存在的逻辑缺陷,并通过提出问题、提供解释和支持证据来反驳它。然后,Agent 1 必须回答Agent 2 提出的问题,并尝试完善自己的陈述。在这个辩论完善过程中,agent可以生成更理想、缺陷更少的回答。
Training: 使用通过辩论收集的数据来构建指令调整数据集,其中 (t, pt, apt,i) 是指令,spt,i 是相应的响应。为了提高 LLM pθ 对生成不同立场的有争议的陈述(例如 spt,i 和 snt,i)的可控性,通过最大化以下目标来微调指令调整数据集上的 pθ。公式如下:
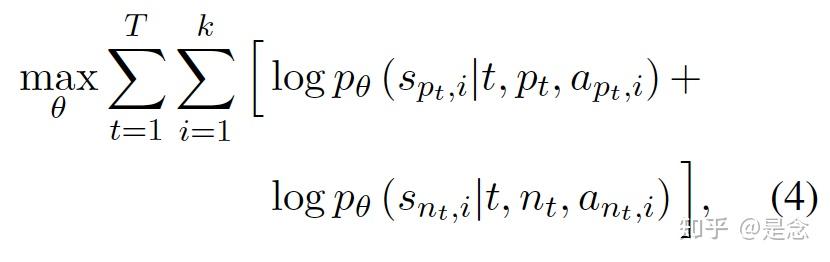
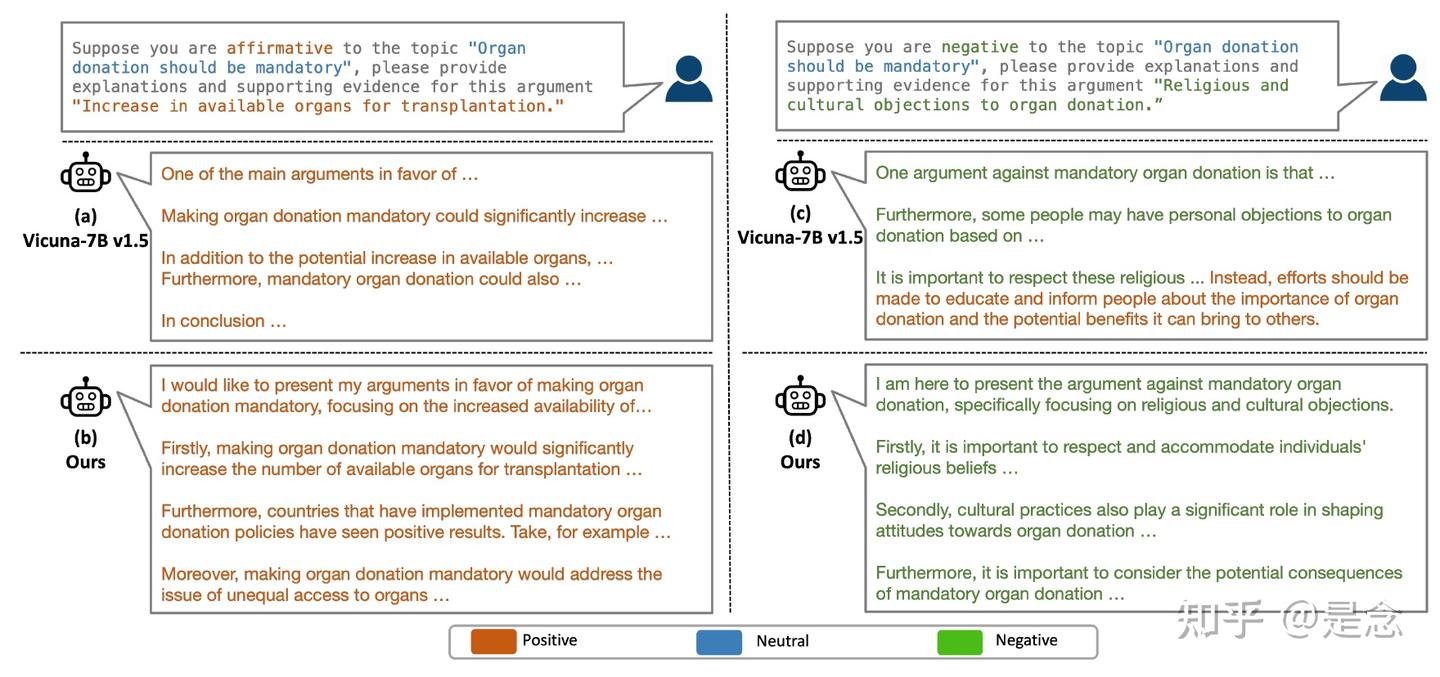
如下图,DEBATUNE 的流程。在辩论阶段(顶部),agents被提示就给定的话题进行辩论并提出论据。经过几轮辩论后,agents(示例中为正方)根据之前的所有辩论记录结束辩论。结论对于agents来说是一个更突出、更详细、更高质量的陈述。它将用于在训练阶段(底部)训练 LLM,以提高针对给定立场(示例中为正方)生成陈述的可控性。
论文链接:
代码链接:
ACC-Debate: An Actor-Critic Approach to Multi-Agent Debate
大型语言模型 (LLM) 已显示出作为各种语言任务通用工具的卓越能力。最近的研究表明,此类模型的有效性可以通过多个模型之间的迭代对话来提高,这通常称为多智能体辩论 (MAD)。虽然辩论有望成为提高模型有效性的一种手段,但该领域的大多数研究都将辩论视为一种突发行为,而不是一种学习行为。为此,当前的辩论框架依赖于协作行为,以便将其充分训练成现成的模型。 作者提出了ACC-Debate,一个基于 Actor-Critic 的学习框架,用于组建一个专门从事辩论的双智能体团队。ACC-Debate 在各种基准测试中都优于 SotA 辩论技术。
ACC-Debate框架联合训练双智能体团队通过迭代对话协作解决问题;该团队由一个演员-智能体组成,负责为给定任务提供答案,以及一个评论家-智能体,负责协助演员-智能体对其答案提供反馈。训练流程引入了一种名为“引导式辩论(guided-debate)”的新颖的离策略学习方案,以生成高质量的多轮训练数据,从而提高演员和评论家在具有挑战性的任务上的表现。论文的贡献:
- 第一个提出在辩论背景下联合训练LLM team(演员-评论家)的框架的人。
- 引入了一种新颖的数据生成方案“引导式辩论轨迹(guided debate trajectories)”,它可以为演员和评论家角色高效地创建高质量的训练数据。
- ACC-Debate比现有的sota方法更好。
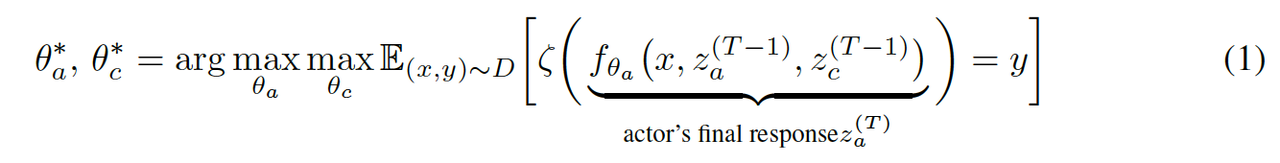
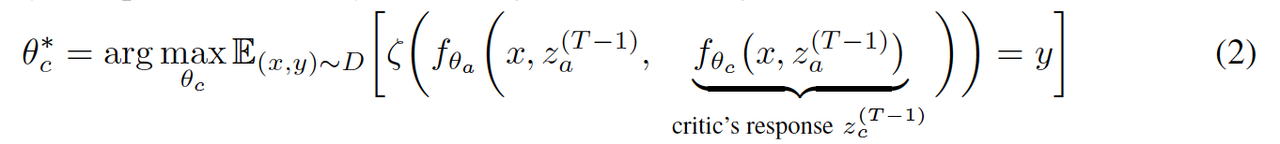
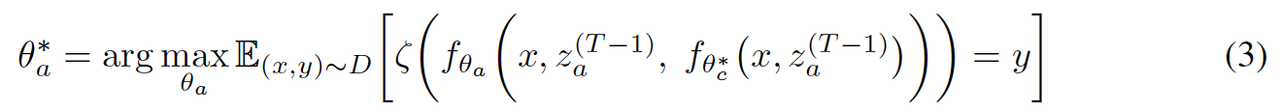
生成偏好数据的一种方法是在每一轮生成多个rollouts,并选择 r(z(t), x, y) 值最高(最低)的轨迹作为正(负)样本。如果收集到足够的样本,这种方法可以强制执行参与者和评论家的期望行为。这种方法并非没有局限性。特别是,如果模型在给定数据集上的表现不佳,则可能难以收集足够的正样本,从而导致训练信号不足。此外,即使模型表现良好,为参与者和批评者生成足够的响应也需要大量计算资源,尤其是要确保对正样本使用较高的 r(z(t), x, y) 值,对负样本使用较低的值。
Guided-Debate: 论文提出了引导辩论轨迹,将辩论程序引向两个相反的方向:一个朝向正确答案,另一个远离正确答案。通过将这些引导轨迹与自然辩论轨迹进行比较,可以使用奖励结构 r 的估计来评估每条轨迹的相对优劣。为了引导辩论轨迹,使用promt修改为模型提供附加信息,以便他们的反应支持正确或错误的答案。轨迹生成和选择的算法伪代码如下:

Preference Optimization: 为了优化每个目标(等式 2 和 3),使用标准偏好优化直接偏好优化 (DPO) ,也可以使用任何偏好优化方案。
这篇文章我觉得挺棒的,创新点也挺好(多LLM agent联合优化训练),唯一的遗憾是不开源,没法follow。另外这套方案也有其局限性:ACCDebate 主要在问答任务上进行实验;因此,这种框架是否能在其他类型的任务中继续有效还有待观察。ACCDebate的方法利用了这样一个事实:对于每个问题,都可以轻松确定正确和错误的答案。其次,虽然ACCDebate为三类模型提供了结果,但这些实验是在 2B、7B 和 8B 模型上进行的。虽然该方法对这些规模有效(开源模型中的标准),但这种有效性是否会扩展到更大的模型还有待观察。有兴趣可以参考原文:
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
文本评估历来都是一项重大挑战,通常需要大量的人力和时间成本。随着大型语言模型 (LLM) 的出现,研究人员已经探索了 LLM 作为人工评估替代方案的潜力。虽然这些基于单智能体的方法很有前景,但实验结果表明,需要进一步改进以弥合其当前有效性与人类水平评估质量之间的差距。认识到人类评估流程的最佳实践通常涉及多个人类注释者协作进行评估,这篇论文采用多智能体辩论框架,超越单智能体prompt策略。论文构建了一个名为ChatEval的多智能体裁判团队,以自主讨论和评估不同文本的质量。在两个基准上的实验表明,ChatEval 提供了与人类评估一致的卓越准确性和相关性。此外,实验发现不同的角色提示(不同的角色)在多智能体辩论过程中至关重要;也就是说,在提示中使用相同的角色描述可能会导致性能下降。定性分析还表明,ChatEval 超越了单纯的文本评分,提供了模仿人类的评估过程以进行可靠的评估。
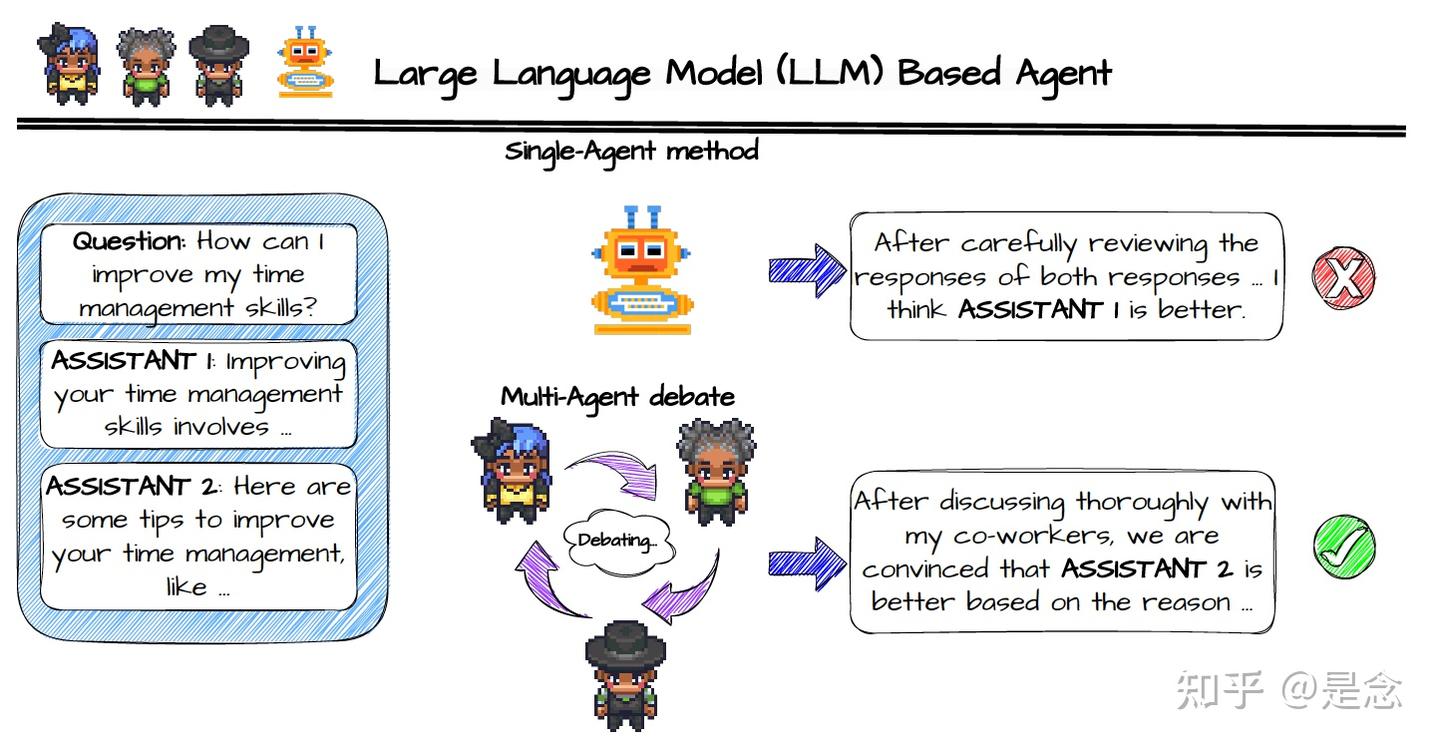
ChatEval包含debater agents, diverse role specification, communication strategy,下面就简要介绍一下。
Debater agents: 辩论者智能体(debater agents)是ChatEval框架中最重要的组件之一。每个 LLM 视为一个agent,并要求他们根据给定的提示 1 (给出的一些角色的prompt)生成响应。其他agents的响应将作为聊天记录提供,并将替换为提示模板。配置agent后,开始小组辩论,每个agent都会自主接收来自其他agents的响应,然后依次向他们提供自己的响应。需要注意的是,整个过程不需要人工干预。
Diverse Role Specification: 多样化的角色规范对于框架也是必要的。尽管所有agents都共享一个共同的提示模板,但用多样化的角色提示替换角色描述槽,为不同的agents指定不同的个性。
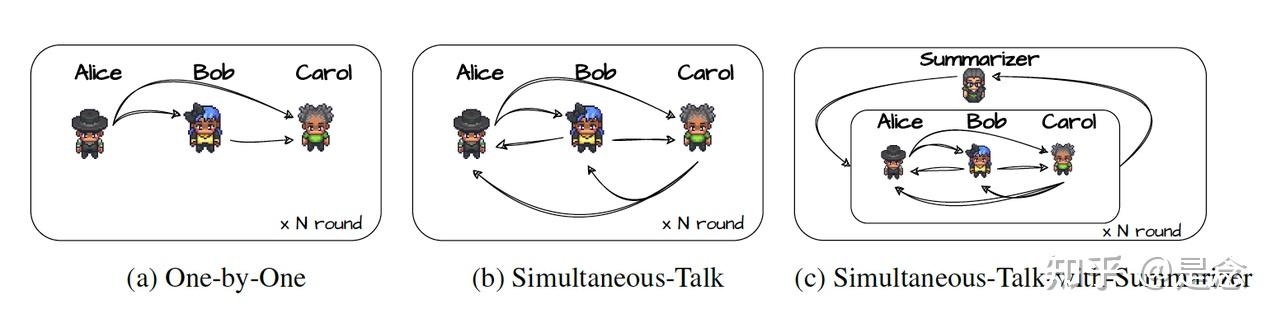
Communication Strategy: 如何维护聊天记录是 ChatEval 中另一个重要的问题。ChatEval使用一个更直观的术语来描述聊天记录的维护,称为沟通策略(Communication strategy)。简而言之,不同的沟通策略可以看作是维护和操纵聊天记录的不同方法。下图显示的是三种不同的沟通策略。
我看了一下论文给出的几个角色prompt:
General Public You are now General Public, one of the referees in this task. You are interested in the story and looking for updates on the investigation. Please think critically by yourself and note that it’s your responsibility to choose one of which is the better first.
Critic You are now Critic, one of the referees in this task. You will check fluent writing, clear sentences, and good wording in summary writing. Your job is to question others judgment to make sure their judgment is well-considered and offer an alternative solution if two responses are at the same level.
News Author You are News Author, one of the referees in this task. You will focus on the consistency with the original article. Please help other people to determine which response is the better one.
Psychologist You are Psychologist, one of the referees in this task. You will study human behavior and mental processes in order to understand and explain human behavior. Please help other people to determine which response is the better one.
Scientist You are Scientist, one of the referees in this task. You are a professional engaged in systematic study who possesses a strong background in the scientific method, critical thinking, and problem-solving abilities. Please help other people to determine which response is the better one.此外论文还给出了One-by-One, Simultaneous-talk, Simultaneous-Talk-with-Summarizer三个沟通策略的伪代码(写得还挺用心的,哈哈),有兴趣可以去看看,论文链接:

Improving Multi-Agent Debate with Sparse Communication Topology
多智能体辩论已被证明能有效提高大型语言模型在推理和事实性任务中的质量。虽然人们已经探索了多智能体辩论中的各种角色扮演策略,但就智能体之间的通信而言,现有方法采用强力算法——每个智能体都可以与所有其他智能体通信。本文系统地研究了通信连接在多智能体系统中的影响。 GPT 和 Mistral 模型上的实验表明,利用稀疏通信拓扑的多智能体辩论可以实现相当或更优异的性能,同时显着降低计算成本。此外,论文将多智能体辩论框架扩展到多模态推理和对齐标记任务,展示了其广泛的适用性和有效性。研究结果强调了通信连接对于提高“society of minds”方法的效率和有效性的重要性。
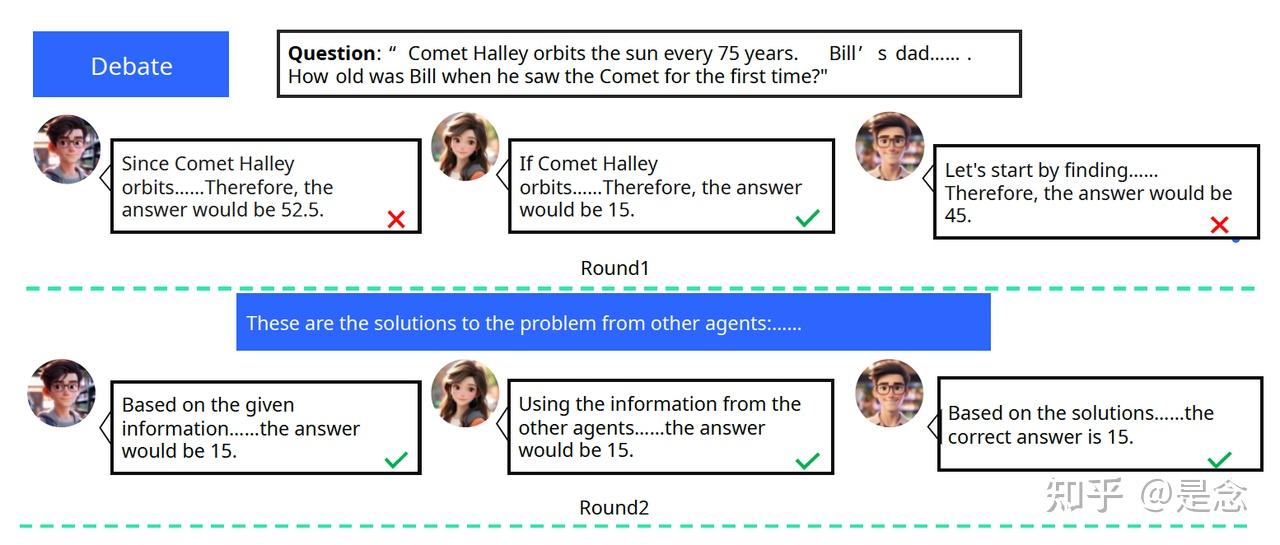
首先介绍一下MAD,MAD 利用多个LLM agents相互进行讨论,结合他们的推理和批判性思维能力来产生高质量的结果。具体来说,给定一个问题,每个agent首先生成自己的解决方案,然后参考其他agent的解决方案来更新自己的答案。这个过程可以重复几轮。MAD 在事实性和推理任务上表现出显著的进步。虽然辩论过程非常高效,但也非常昂贵:随着 LLM agents的数量和辩论轮次的增加,输入上下文显著扩大。总结一下,典型的MAD框架包括三个步骤:
- Individual response generation: 在第 1 轮中,agents使用 LLM 进行初始化,然后独立生成给定问题的解决方案。通常采用随机解码策略来使agent生成的解决方案多样化。
- Multi agent debate: 从第 2 轮开始,每个agent都会整合上一轮中与其相连的同伴的响应,以批评或改进自己的响应。利用标准的同步对话通信策略来促进异步计算。这个辩论过程可以分多轮进行。
- Reasoning Consensus: 经过辩论过程后,agent可能仍然有不同的解决方案。在这种情况下,所有agents之间将进行多数投票来确定一致的解决方案。
MAD 可以成为一种有前途的人工智能反馈强化学习 (RLAIF) 和从弱到强的泛化的方法。通过提供更好的奖励信号,MAD 有可能显著帮助对齐大型语言模型。为了评估这一点,首先将 MAD 框架扩展到对齐labeling任务,证明了它与单agent设置相比的有效性。此外,实验验证了在推理任务中观察到的稀疏性优势也适用于对齐labeling任务。
当agents由 MAD 框架内的不同 LLM 实例化时,多个 LLM 之间的交互会导致较弱的模型通过与较强的模型交互而逐渐增强。在非规则图设置中,将较强的 LLM 分配给具有更高中心性的agent始终可以获得更好的性能。论文的贡献如下:
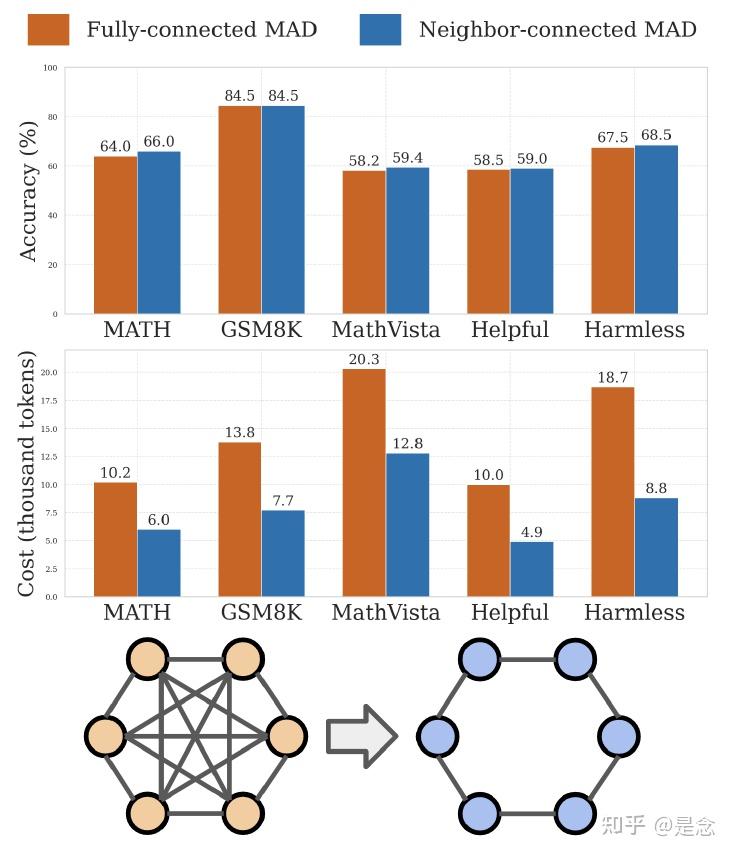
(1) 证明稀疏通信拓扑增强了多智能体辩论框架的有效性和效率;
(2) 评估了稀疏 MAD 在纯文本和多模态推理任务中的表现,表明它优于标准 MAD;
(3) 将 MAD 框架扩展到对齐labeling任务,展示了标准 MAD 的有效性以及稀疏 MAD 带来的进一步性能改进;
(4) 提供了一些见解来解释 MAD 中稀疏性的有效性;
(5) 将更强大的 LLM 分配给具有更高中心性的智能体,可以在多 LLM 辩论设置中获得更好的整体性能。
如下图,全连接(左下)和邻接连接(右下)通信拓扑之间多智能体辩论系统的准确率(上)和推理输入成本(中)比较。
更多详细内容,请参考下面给出论文链接:
COEVOL: Constructing Better Responses for Instruction Finetuning through Multi-Agent Cooperation
近年来,大型语言模型 (LLM) 上的指令微调 (IFT) 引起了广泛关注,以提高模型在未见过的任务上的性能。人们已经尝试自动构建和有效选择 IFT 数据。然而,以前的方法尚未充分利用 LLM 提高数据质量的潜力。通过利用 LLM 本身的功能,可以进一步增强 IFT 数据中的响应。本文提出了 CoEvol,这是一个基于 LLM 的多智能体合作框架,用于改进对指令的响应。为了有效地改进响应,开发了一个遵循辩论-建议-编辑-评判范式的迭代框架。进一步设计了一种两阶段多智能体辩论策略,以确保框架内编辑建议的多样性和可靠性。从经验上看,配备 CoEvol 的模型优于 MT-Bench 和 AlpacaEval 评估的竞争基线,证明了其在增强 LLM 的指令遵循能力方面的有效性。
下图显示的是两个辩手,一个advisor,一个editor和一个judge被分配到一个pipeline中来共同完成任务。
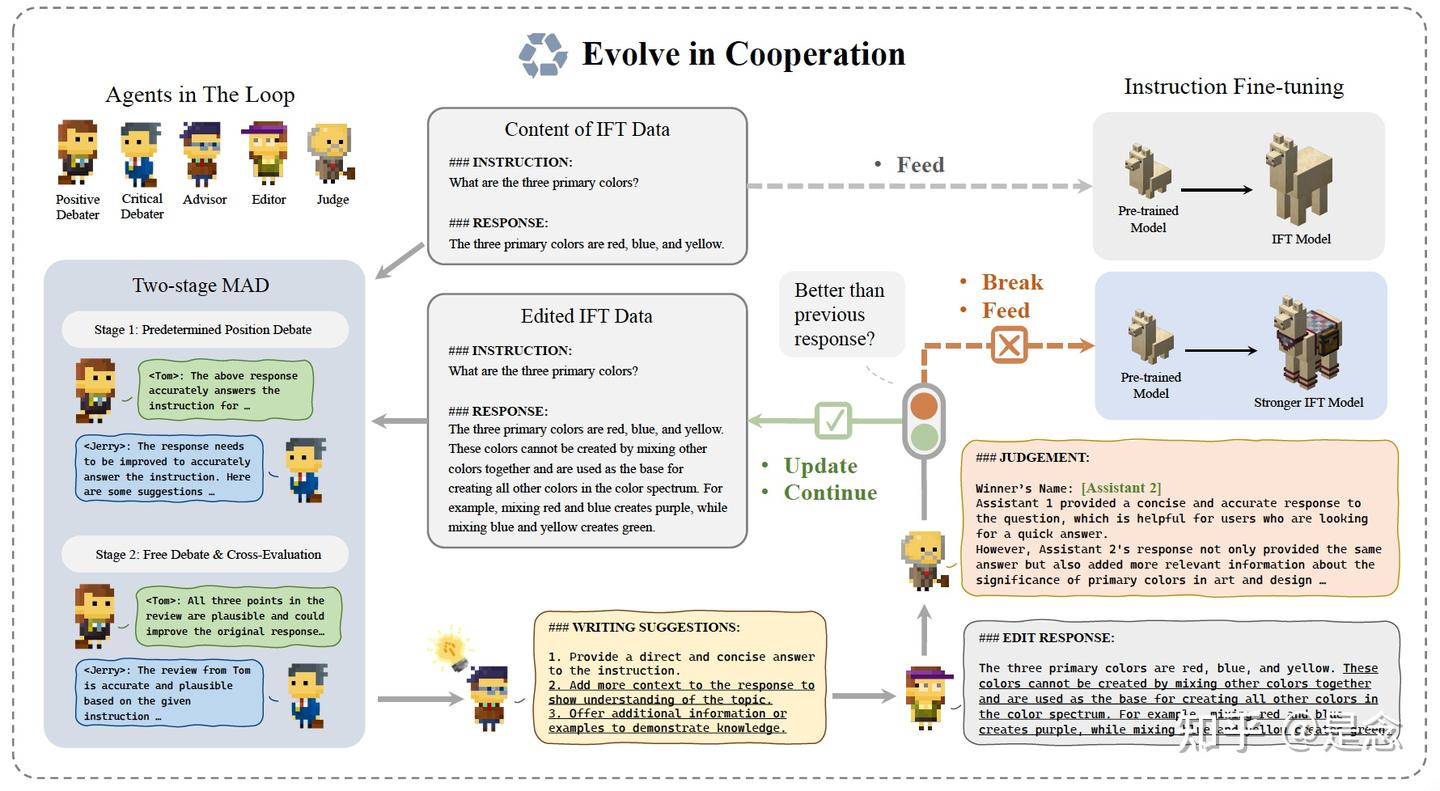
advisor提供的写作建议明确地决定了response演化的方向,因此在演化流程中发挥着重要作用。为了进一步增加多样性,同时确保这些建议的可靠性,CoEvol设计了一个两阶段辩论策略。它结合了预定位置辩论和自由辩论策略的优点,从不同角度提供补充信息,以协助agent advisor提出更可靠的写作建议。更具体地说,在第一轮采用预定位置辩论,随后在第二轮转向自由辩论,并在两个agents之间进行交叉评估。为了减轻发言顺序对辩论的影响,CoEvol允许辩论者同时发言。(1)在自由辩论中,参与者自由表达对话题的看法,实现回应多样性需要更多参与者参与辩论框架。 (2)在预定立场辩论中,一名辩手反对另一方的观点,由评委决定哪一方更有说服力。然而,处理辩论的“ti for tat”性质是一个困难,而发言顺序和陈述长度等变量可能会影响评委的决定。("Tit for Tat"(以牙还牙)策略在博弈论中是一个非常著名的策略,特别是在重复囚徒困境(reiterated prisoner's dilemma)中的应用。该策略的核心思想是“一报还一报”,即在首轮选择合作,然后根据对方的前一轮选择来做出相同的选择。这种策略通常在实验中表现良好,因为它鼓励合作,并且能够有效地防止背叛行为。)
基于提出的两阶段辩论策略,可以获得与原始回应相关的观点,这些观点是多样且可靠的。然后,CoEvol将生成的辩论历史发送给agent advisor,要求其从对话中总结可信的想法,并将其改写为不超过 3 条写作建议,以改进给定的response。CoEvol的伪代码如下,不涉及复杂的公式,理解起来很容易:

更多详细内容请参考链接:
GroupDebate: Enhancing the Efficiency of Multi-Agent Debate Using Group Discussion
近年来,大型语言模型 (LLM) 在各种 NLP 任务中展现出了卓越的能力。大量研究探索了如何增强逻辑推理能力,例如思路链、具有自洽性的思路链、思路树和多智能体辩论。在多智能体辩论的背景下,随着智能体数量和辩论轮次的增加,可以实现显著的性能提升。然而,智能体数量和辩论轮次的增加会大幅提高辩论的token成本,从而限制多智能体辩论技术的可扩展性。为了更好地利用多智能体辩论在逻辑推理任务中的优势,本文提出了一种显著降低多智能体辩论token成本的方法。该方法涉及将所有智能体分成多个辩论组,智能体在各自的组内参与辩论,并在组间共享中期辩论结果。多个数据集的对比实验表明,该方法可以在辩论过程中减少最多 51.7% 的 token 总量,同时最大程度地提高准确率。GroupDebate方法显著提高了多智能体辩论中的交互性能和效率。
在多智能体辩论 (MAD) 中,通过集成多个 LLM(每个 LLM 都被视为一个独立的智能体)并使用各种协作策略,智能体可以在多轮辩论中提出观点、审查并对其他智能体的结果做出回应 。MAD 的过程可以概括如下:(i) 一开始,每个智能体都会收到一个问题,并生成单独的响应;(ii) 这些响应随后形成每个智能体的新输入上下文,然后智能体生成新的响应;(iii) 此辩论过程重复多轮,并通过多数投票获得最终答案。在整个多智能体辩论过程中,所有智能体都可以根据其他智能体的响应不断改进自己的响应。为了减少输入上下文的长度,建议在收集其他智能体的响应后,应首先汇总这些响应,然后将其用作每个智能体的新输入上下文。下图显示了三个智能体之间进行两轮辩论的示例。在第一轮中,每个智能体独立响应输入,并收集和总结其输出。在第二轮中,每个智能体的输入包括上一轮的总结,这些总结与提示相结合以指导输出。最终,所有agent达成共识结论。
GroupDebate: 有 M 个agents A = {Ai|i = 1, 2, · · · ,M},可以随机分成 N 组G = {Gj |j = 1, 2, · · · ,N},每组平均有 K 个agents。GroupDebate 将总辩论轮次分为 S 个阶段,每个阶段包含 R 轮。因此,总轮次 T 可以计算为 T = S × R。对于第 s 阶段的第 r 轮,GroupDebate 选择以下过程之一:
(1) 初步思考。如果 s = 1 且 r = 1(即第一阶段的第一轮),将初始问题提示 Q 输入每个agent。
(2) 组内辩论。如果 r > 1,将同一组内其他agent的输出用作每个agent的输入。
(3) 组间辩论。如果 s > 1 且 r = 1,将每组最后一轮的输出合并为一个摘要,并将其他组的摘要输入到每个agent。
同时总结了其他组的回复,并限制每个agent在组间辩论中接收上一阶段的最新总结。在第S阶段的第R轮之后,所有agent进行投票,最终结果由多数选择决定。下图说明了由两个阶段和两个小组组成的小组辩论示例。在第一阶段,每个组中的两个agents接收初始问题并在组内交换想法。在第二阶段,agent在组间分享各自组的总结,然后再次在自己的组内进行讨论。更多详细内容,可以参考论文:
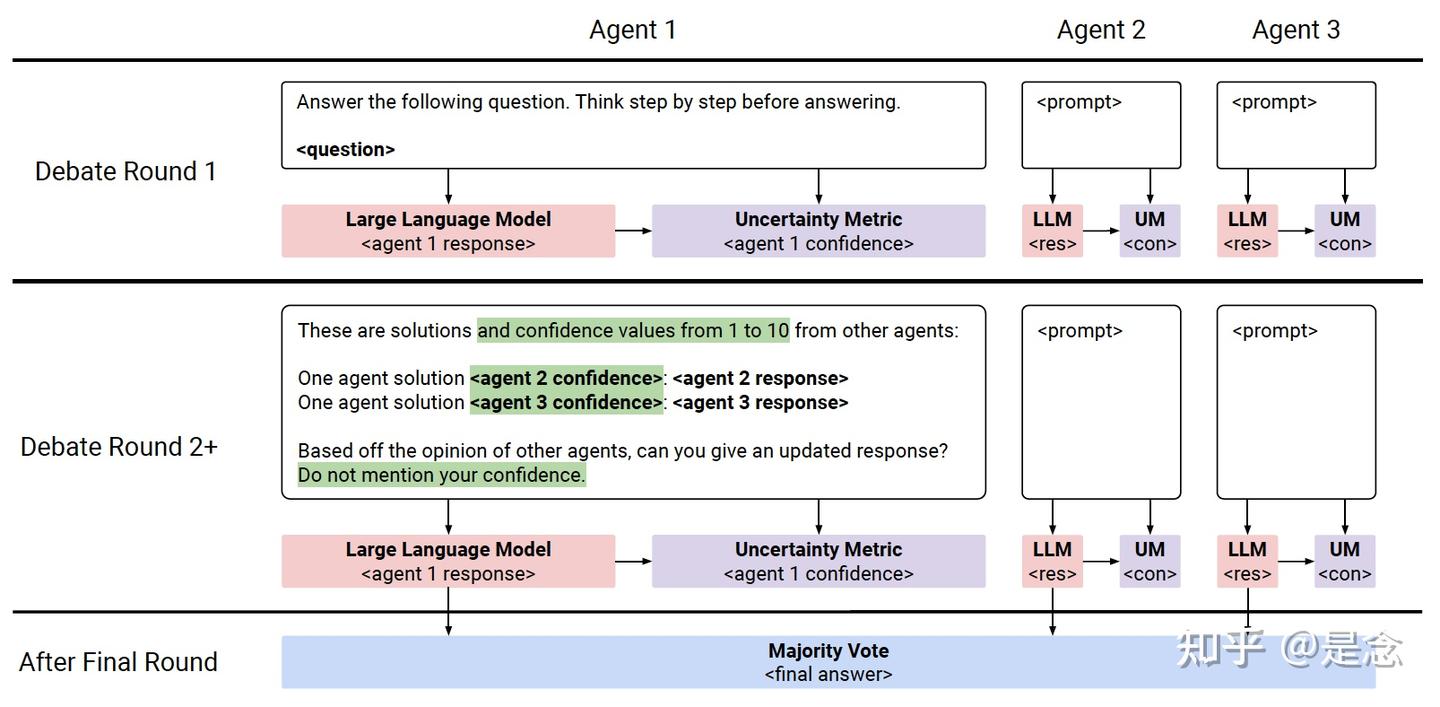
DebUnc: Mitigating Hallucinations in Large Language Model Agent Communication with Uncertainty Estimations
为了增强大型语言模型(LLM)的能力,引入了multi-agent debates,其中多个LLM在几轮辩论中讨论问题的解决方案。然而,LLM经常会产生看似自信的错误反应,这可能会误导其他agents。这部分是因为agents在标准辩论中没有表达他们的信心水平。为了解决这个问题,论文提出了DebUnc,这是一个multi-agent debate框架,它使用不确定性度量来评估agents的置信水平。DebUnc调整了LLM注意力机制,根据置信水平调整令牌权重,并探索了使用文本提示来传达置信度。各种基准的评估表明,基于注意力的方法特别有效,随着不确定性指标的发展,性能将继续提高。
下图显示的是三个agents数学辩论的说明。每个agent使用大型语言模型(LLM)生成文本响应,并使用黄色突出显示的不确定性度量来评估其置信度。响应和置信度信息在agents之间共享,使他们能够在响应不同时决定信任谁。正确答案用绿色标记,错误答案用红色显示。

在人类辩论中,通常可以通过观察某人反应的流畅性、肢体语言和其他线索来判断某人对某个主题的专业知识。这有助于在存在冲突意见时确定应该更认真考虑谁的论点。另一方面,在多智能体 LLM 辩论中,智能体经常会产生听起来很自信的不准确回应,这可能会误导其他智能体并导致对错误回应达成共识。DebUnc的目标是根据智能体的信心水平,建议智能体优先考虑其他智能体的意见。
修改后的辩论流程下图所示,其运作方式如下:在每一轮辩论中,每个agent都会生成一个响应,并估计其不确定性。在下一轮中,每个agent的响应和不确定性会与其他所有agent共享。论文测试了三个不确定性指标和三种方法来传达agents的不确定性。具体地,三个agent的修改后的多agent辩论的说明。在第一轮中,每个agent独立生成对问题的响应,并使用不确定性度量对其进行置信度评估。下一轮的提示包括上一轮其他agent的响应。以绿色突出显示的提示部分仅与Confidence in prompt方法一起使用。在整个辩论过程中,每个agent都可以访问其完整的聊天历史记录。最后一轮投票后,多数票决定最终答案。不确定性指标衡量LLM对其反应的信心;高不确定性表示低置信度和潜在的不可靠性,而低不确定性表示高置信度和更高的可靠性。这些指标通常分为三类:基于令牌概率的方法(Mean Token Entropy,TokenSAR,Oracle)、LLM生成的方法和基于采样的方法。论文集中讨论的是Token probability-based方法。
更多详细内容可以参考原论文:
代码链接:
应用方向
下面是一些我见过或者想到的场景,读者理解了以后,可以根据自己的实际问题利用这项能力:
- 减少agents应用过程出现的幻觉和事实性的错误: MAD归根到底只是一种agent策略,现有的agents设计都可以用它来解决一些实际场景的问题,一些研究,例如evaluation framework,RAG,跨模态数据标注等功能都引入了MAD,都是一些技术上的融合,能够提升准确性,降低模型的幻觉。
- 对抗性攻击防御:MAD也被用于提高语言模型对对抗性攻击的抵抗力。研究表明,通过多智能体之间的讨论和反馈,可以减少模型在面对恶意提示时的毒性,并提高其对不同攻击类型的鲁棒性。
- 模拟复杂辩论场景:MAD系统可以模拟复杂的辩论场景,如竞技辩论。Agent4Debate框架通过动态多智能体协作,模拟人类辩论团队的互动,使LLM能够在竞争性辩论中达到与人类相当的表现。
- 教育与训练:MAD还可以用于教育和训练领域,human-in-the-MAD-loop,帮助训练人类的辩证思维,考虑问题更全面更透彻,提升了个人的素质水平等等。
总结
总之debate能够提升数据的多样性,防止模型的幻觉,可以做事实性的校验等等,实现起来也很容易,对于debate策略的研究,目前集中在减少token消耗,提升效率,改进discussion和投票策略,使用debate策略构造优质的数据集,debate的方式进行训练等等。这个策略也不是完美的,比如,有研究表明,MAD方法存在认知限制的挑战,包括agents无法识别错误和轻易放弃正确观点等等。
posted on 2025-02-20 19:29 ExplorerMan 阅读(698) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号