图像识别技术的原理
链接:https://www.zhihu.com/question/38014222/answer/499925265
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
人类是怎么识别的?当我们看到一个东西,大脑会迅速判断是不是见过这个东西或者类似的东西。这个过程有点儿像搜索,我们把看到的东西和记忆中相同或相类的东西进行匹配,从而识别它。机器的图像识别也是类似的,通过分类并提取重要特征而排除多余的信息来识别图像。这就是最大的原理,看起来一点儿都不复杂对不对?
期初人工智能的先驱们也觉得这挺简单,然鹅……
那是1966年的夏天,人工智能之父Minsky给学生布置了一个暑假作业:要求学生通过编写一个程序,让计算机告诉我们它通过摄像头看到了什么。于是一大票人从此走上了图像识别的不归路,我想当时学生们的内心肯定是这样的:

毕竟,50多年过去了,这个作业还不能说真正做完……
那么,完成作业的方法是如何一步步升级的呢?
1970s-1980s
到了上世纪七八十年代,Minsky布置的作业算是有了些眉目。现代电子计算机的出现,让计算机有机会尝试回答出它看到了什么东西。
研究人员首先从人类看东西的方法中获得借鉴。当时人们普遍认为,人类能看到并理解事物是因为通过两只眼睛可以立体地观察事物(现在看来当然是极大的误解……)。因此要想让计算机理解它所看到的图像,必须先将事物的三维结构从二维的图像中恢复出来,这就是所谓的“三维重构”的方法。
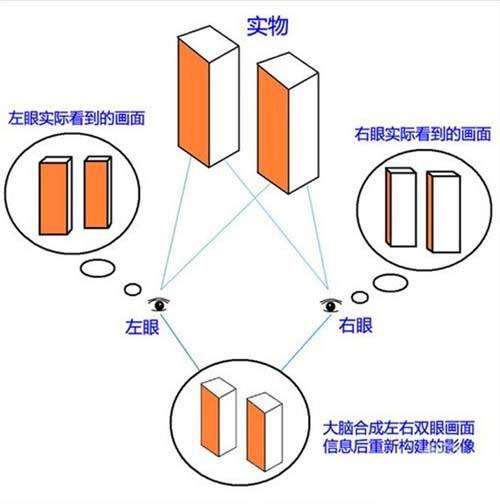 人眼三维效果示意图(图片来自网络)
人眼三维效果示意图(图片来自网络)
另一个灵感是,人们认为人之所以能识别出一个苹果,是因为人们已经有了先验知识:苹果是红色的、圆的、表面光滑的。如果给机器也建立一个这样的知识库,让机器将看到的图像与之匹配,是否可以让机器识别乃至理解它所看到的东西呢,这是所谓的“先验知识库”的方法。
 先验知识分解
先验知识分解
这套方法只能够提取少数基本特征,实用性当然不高,只能用在某些光学字符识别、工件识别、显微/航空图片的识别等。
1990s
到了上世纪九十年代,图像处理硬件技术有了飞速进步,人们也开始尝试不同的算法,包括统计方法和局部特征描述符的引入,使得计算机视觉技术取得了更大的发展,并开始广泛应用于工业领域。
在“先验知识库”的方法中,事物的形状、颜色、表面纹理等特征受到视角和观察环境所影响,在不同角度、不同光线、不同遮挡的情况下会产生变化。因此,研究者的新方法是,通过局部特征的识别来判断事物,对事物建立一个局部特征索引,即使视角或观察环境发生变化,也能比较准确地匹配上。
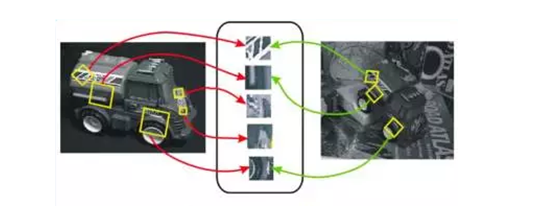 局部特征索引示意图
局部特征索引示意图
2000s
进入21世纪,得益于互联网兴起和数码相机出现带来的海量数据,加之机器学习方法的广泛应用,计算机视觉发展迅速。以往许多基于规则的处理方式,都被机器学习所替代:机器自动从海量数据中总结归纳物体的特征,然后进行识别和判断。
这一阶段涌现出了非常多的应用,包括典型的相机人脸检测、安防人脸识别、车牌识别等等。数据的积累还诞生了许多评测数据集,比如权威的人脸识别和人脸比对识别的平台——FDDB和LFW等,其中最有影响力的是ImageNet,包含1400万张已标注的图片,划分在上万个类别里。
 基于机器学习的图像识别流程示意
基于机器学习的图像识别流程示意
2010以后
到了2010年以后,借助于深度学习的力量,计算机视觉技术得到了爆发增长和产业化。出现了神经网络图像识别,这就是目前比较新的一种图像识别技术了。
它是怎么工作的,我在《财富》杂志上见过一张简明的示意图,把它汉化过来给大家看,算是一目了然了:
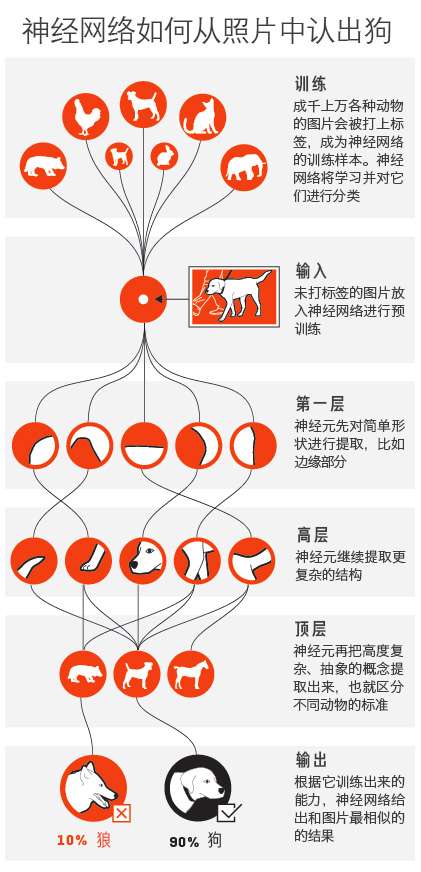 来源:http://fortune.com
来源:http://fortune.com
再举一个医疗影像的图像识别案例,也异曲同工,就是下面这张腾讯觅影对早期肺癌的筛查流程图:
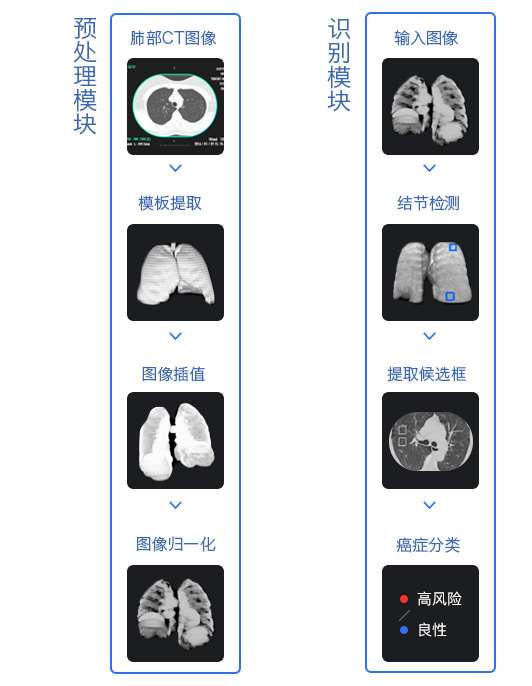 腾讯觅影对早期肺癌的筛查流程
腾讯觅影对早期肺癌的筛查流程
觅影系统会先基于腾讯深度学习技术,对数十万张肺部CT影像数据进行学习分析,获得精准定位可疑结节的能力,实现对良恶性判别,从而帮助提高医生诊断效率和准确率。
通过深度神经网络,各类视觉识别的任务精度都得到了大幅提升。在全球最权威的计算机视觉竞赛ILSVR上,千类物体识别错误率在2011年时还高达25.8%,从2012年引入深度学习之后,后续4年的错误率分别达到了16.4%、11.7%、6.7%、3.7%,出现了显著突破。现在,人脸识别甚至能做到误判率低于百万分之一。
归根结底,机器的图像识别和人类的图像识别原理相近,过程也大同小异。只是技术的进步让机器不但能像人类一样认花认草认物认人,还开始拥有超越人类的识别能力。
比如,我非常期待技术大牛能赶紧开发出口红色号识别软件!!!
女:看看我和昨天有什么不同?
我:嗯……好……好像没什么不同……
女:我换了一支口红呀!你是眼睛瞎了吗?!!
我:哦
女友的口红啊,请放过我的肉眼…………
 口红的色号可视化。来源:Github 作者:@羡辙
口红的色号可视化。来源:Github 作者:@羡辙
啊,差点忘了,我还没有女朋友。内牛满面.gif
.
链接:https://www.zhihu.com/question/38014222/answer/601659233
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
图像识别,是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术,并对质量不佳的图像进行一系列的增强与重建技术手段,从而有效改善图像质量。
图像识别以开放API(Application Programming Interface,应用程序编程接口)的方式提供给用户,用户通过实时访问和调用API获取推理结果,帮助用户自动采集关键数据,打造智能化业务系统,提升业务效率。
图像标签
自然图像的语义内容非常丰富,一个图像包含多个标签内容,图像标签可识别三千多种物体以及两万多种场景和概念标签,更智能、准确的理解图像内容,让智能相册管理、照片检索和分类、基于场景内容或者物体的广告推荐等功能更加准确。
 图1 图像标签示例图
图1 图像标签示例图
名人识别
利用深度神经网络模型对图片内容进行检测,准确识别图像中包含的政治人物、影视明星及网红人物。
翻拍识别
翻拍识别是定制化图像识别的一种,基于深度学习技术及大规模图像训练,翻拍识别可准确识别出商品标签图片是原始图片,还是经过二次翻拍、打印翻拍等手段处理的非合规图片,帮助用户打造智能化业务系统,减少人力成本。
低光照增强
主要解决的是夜晚或光线暗区域拍摄的图像导致人眼或机器“看不清”暗光区域的场景。低光照增强可以将图像的暗光区域增强,使得原来人眼不可见区域变得可见,突显富光照增强图像中的有效视觉信息。
 图2 低照度增强前后对比图
图2 低照度增强前后对比图
图像去雾
主要解决雾霾对成像质量的影响。摄像机在雾霾天气拍摄照片或视频时,不可避免出现图像/视频质量不高,拍摄场景不清晰的情况。图像去雾算法除了可以去除均匀雾霾外,还可以处理非均匀的雾霾。
 图3 图像去雾前后对比图
图3 图像去雾前后对比图
超分图像构建
主要解决图像在成像过程中像素过少导致的视觉信息不够或者由于压缩导致的图像信息丢失的场景。超分图像重建基于深度学习算法,对图像中缺失的视觉信息进行补充,使得图像视觉效果更好。
 图4 超分图像重建前后对比图
图4 超分图像重建前后对比图
视频背景音乐识别
可以实现视频中背景音乐的识别。对于用户提供URL的视频,系统完成视频获取、音频提取、音频识别并返回歌曲名称。
链接:https://www.zhihu.com/question/38014222/answer/1792423405
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
现在,图像识别通常是通过深度学习算法实现的,主要包括
1)卷积神经网络
卷积神经网络最开始是用于手写数字识别,后来也用于具体物体的识别。
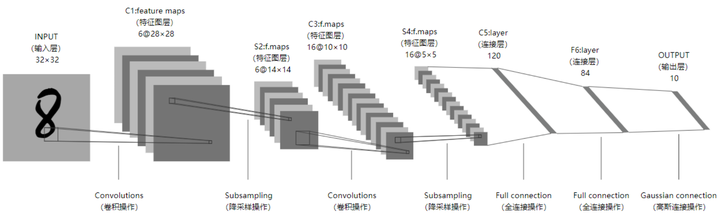 卷积神经网络
卷积神经网络
2)残差网络
残差网络是一种添加了跨层路径的卷积神经网络,其训练难度显著降低。
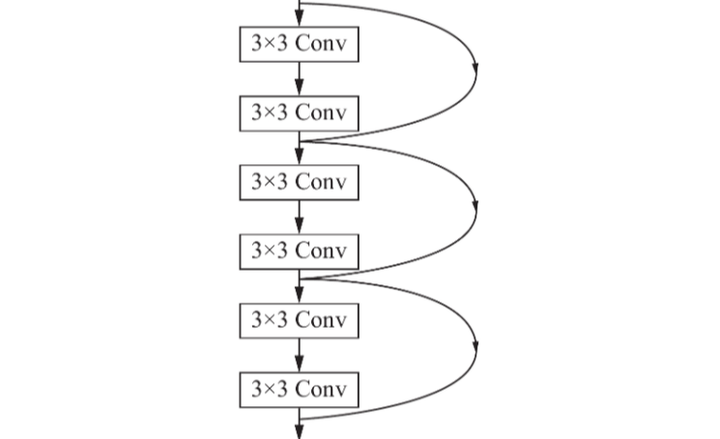 残差网络
残差网络
3)残差收缩网络
在数据面临强噪声干扰时,残差收缩网络[1][2]能够通过自适应软阈值化,减轻噪声的影响。
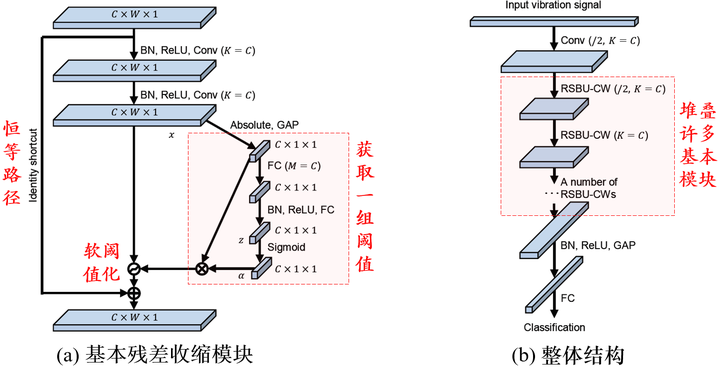 (面向强噪、高冗余数据的)残差收缩网络
(面向强噪、高冗余数据的)残差收缩网络
参考
- ^M. Zhao, S. Zhong, X. Fu, B. Tang, M. Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, vol. 16, no. 7, pp. 4681-4690, 2020. https://ieeexplore.ieee.org/document/8850096
- ^深度残差收缩网络:借助注意力机制实现特征的软阈值化 https://zhuanlan.zhihu.com/p/121801797
posted on 2021-04-08 16:27 ExplorerMan 阅读(6455) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号