
Mysql什么是回表查询和覆盖索引
一、前言
本文主要解释以下几个问题:
1.什么是回表查询?
2.什么是索引覆盖?
3.如何实现索引覆盖?
4.那些场景可以利用索引覆盖优化sql?
本文实验基于8.0版本innodb
二、回表查询
1.建表

CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, `sex` varchar(5) DEFAULT NULL, PRIMARY KEY (`id`), KEY `name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.分析下面两个查询
explain select id,name from user where name='lihua'

explain select id,name,sex from user where name='lihua'

通过explain可以看出当我们增加了sex字段做查询时extra为NULL,意味着本次查询进行了“回表”操作,我们知道innodb采用B+树聚集索引,主键和数据绑定在一起,主键索引b+树的叶子节点存储了数据信息,而普通索引叶子节点存储的是主键值。因此,我们可以得知当通过普通索引查询时无法直接定位行记录,通常情况下,需要扫描两遍索引树。
select * from user where name='lisi';
还是以现有表举例,它是如何执行的?
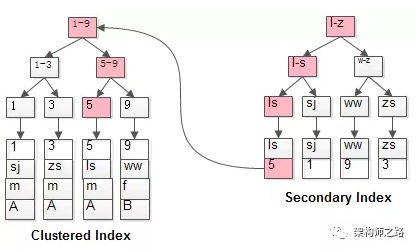
1)先扫描name索引树,找到主键值id=5。
2)再扫描主键索引,找到对应行。
这就是“回表查询”,先定位主键值,再通过主键值定位行记录,性能上较之直接查询索引树定位行记录更慢。
三、覆盖索引
1.什么是覆盖索引?
1)只需要在一棵索引树上就可以获取sql所需所有的列数据,不需要回表,较之回表速度要更快。
2)explain输出结果extra字段为Using index时,触发了索引覆盖。
2.如何实现覆盖索引?
办法:将被查询的字段建立到联合索引中
接我们上面的例子,因为我们对name字段建立了普通索引,且基于name的索引叶子节点存有主键id值,因此满足了在一颗索引树上获得sql所需的所有列数据这一条件,通过观察extra也可发现是Using Index无需回表。
select id,name from user where name='lihua'
观察第二个例子,因为sex并没有被建立到联合索引中,且在name索引树上也无法直接获得,因此只能通过回表查询,两次扫描索引树,效率更低。
explain select id,name,sex from user where name='lihua'
针对第二个例子,我们将sex建立到联合索引中去。
ALTER TABLE `test`.`user` DROP INDEX `name`, ADD INDEX `idx_name_sex`(`name`, `sex`);

再次执行查询,可以看到extra已经变为Using index了,命中了索引覆盖无需回表。
四、使用索引覆盖的场景
1.count查询优化
先对表做修改增加一个address字段,直接count(address)全表查询,可以发现extra为NULL,没有利用到索引覆盖。
ALTER TABLE `test`.`user` ADD COLUMN `address` varchar(255) NULL AFTER `sex`;
explain select count(address) from user

现对address加索引,再做查询,可以观察到extra变为Using index使用了索引覆盖。
ALTER TABLE `test`.`user` DROP INDEX `idx_name_sex`, ADD INDEX `idx_name_sex`(`name`, `sex`, `address`) USING BTREE;

2.列查询回表优化,上述例二建立联合索引解决。
3.分页查询,也可建立联合索引解决,针对下例可以建立(name,sex)覆盖索引。
select id,name,sex ... order by name limit 500,100;
五、结语
本文主要记录mysql学习过程,如有错误请指正。
posted on 2021-02-26 16:02 ExplorerMan 阅读(863) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号