
本地调试spark程序
用IDEA编写spark程序,每次运行都要先打成jar包,然后再提交到集群上运行,这样很麻烦,不方便调试。
我们可以直接在Idea中调试spark程序。
例如下面的WordCount程序:
package cn.edu360.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object ScalaWordCount {
def main(args: Array[String]): Unit = {
//创建spark配置,设置应用程序名字
val conf = new SparkConf().setAppName("ScalaWordCount")
//创建spark执行的入口
val sc = new SparkContext(conf)
//指定以后从哪里读取数据创建RDD(弹性分布式数据集)
val lines:RDD[String]= sc.textFile(args(0))
//切分压平
val words:RDD[String] = lines.flatMap(_.split(" "))
//将单词和1组合
val wordAndOne:RDD[(String,Int)] = words.map((_, 1))
//按Key进行聚合
val reduced:RDD[(String,Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorted:RDD[(String,Int)] = reduced.sortBy(_._2,false)
//将结果保存到HDFS中
sorted.saveAsTextFile(args(1))
//释放资源
sc.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
本地调试时,我们要设置一个在本地模式下执行:
在setAppName后面加上.setMaster("local[*]"),然后debug就可以了。
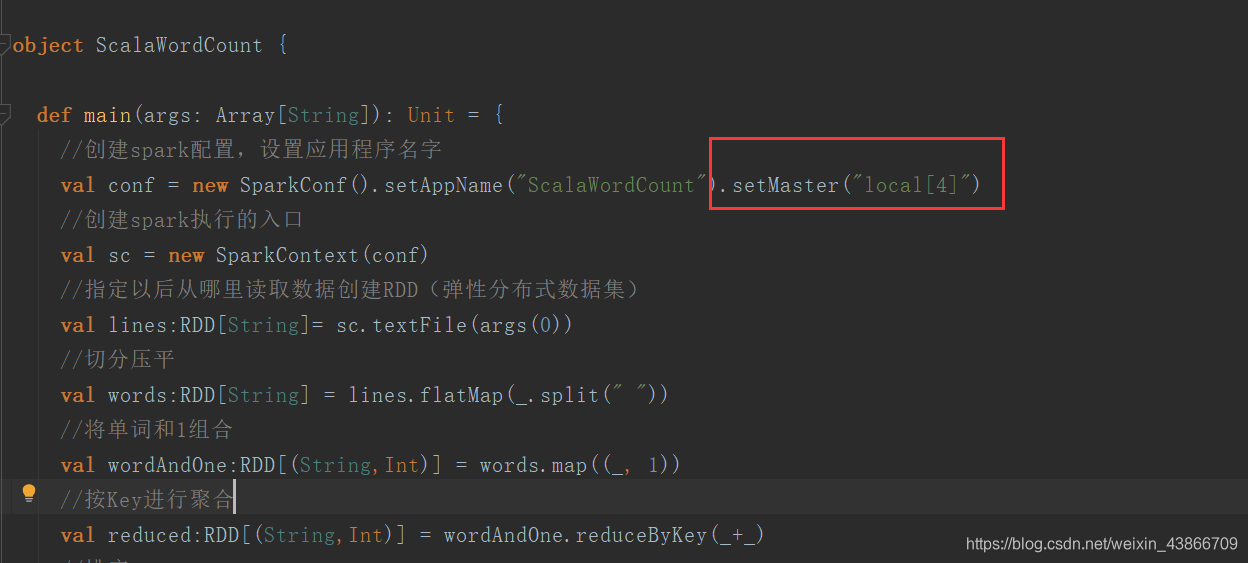
可以再打上一个断点。
posted on 2021-01-21 16:40 ExplorerMan 阅读(1817) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号