玩转CONSUL(3)–大规模部署的性能开销定量分析
1. 引言
今天有朋友问萌叔,consul能否在大规模生产环境下进行应用。场景是总计大约10w+台机器,分为3 ~ 4个机房,单个机房最多3w万+机器。这个问题大的,可把萌叔吓了跳,部门里面consul集群的规模也就是1k+, 还分好几个机房。
不过他的问题确实也让我十分好奇,consul是否有能力支撑这么规模,我决定针对每个可能性能瓶颈进行定量分析
2. 分析
在进行分析前,我们来看看可能遇到瓶颈有哪些?
下图是consul在多DC情况下的体系架构图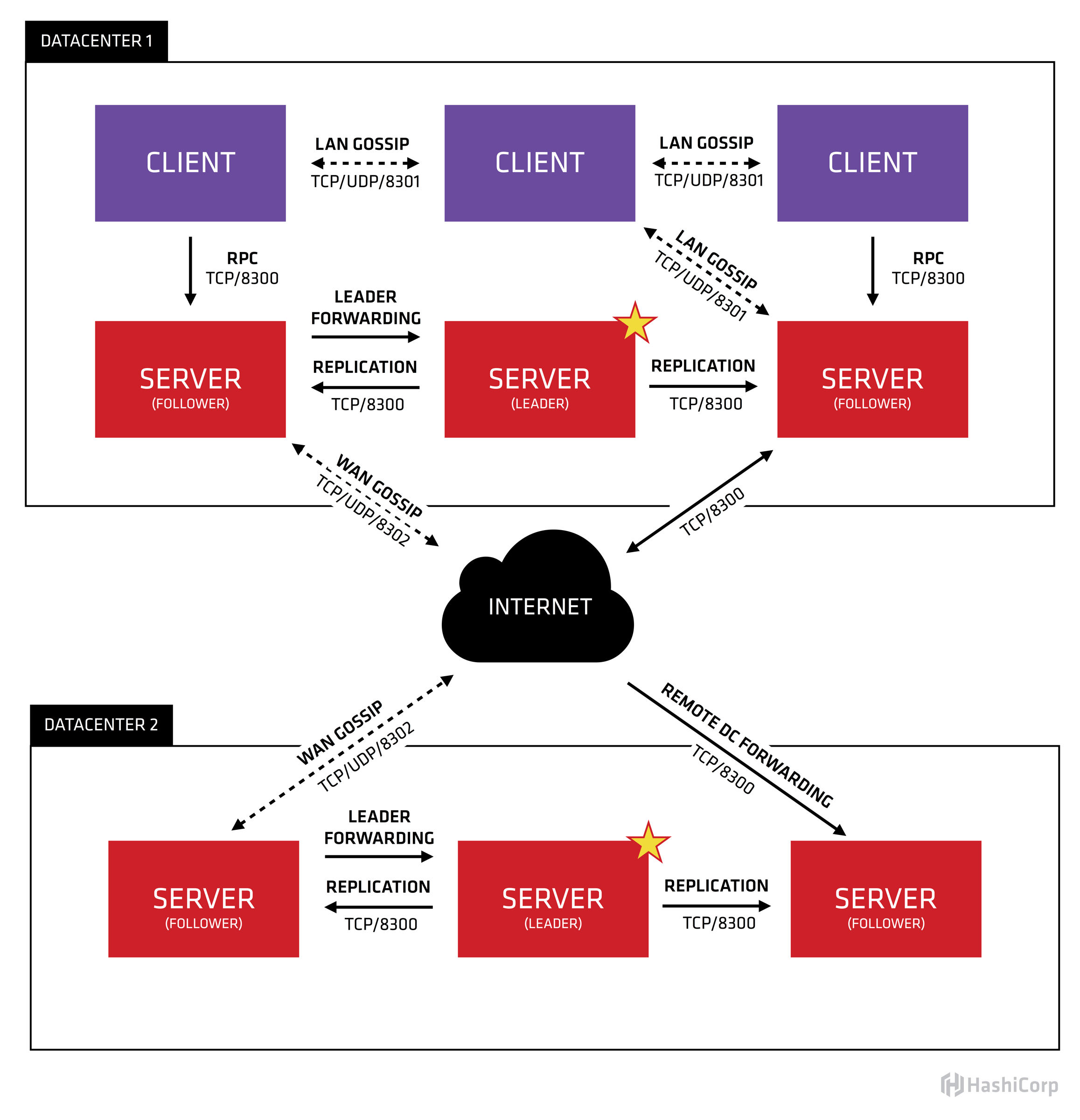
2.1 明确一些概念
- consul agent分2种模式server模式和client模式。在每个机房
consul server(以下简称为server)会部署3 ~ 5台, 其余的consul节点都是consul client(以下简称为server)。server的数量不宜过多,否则选主的速度会变慢 - 数据(包括kv数据,service信息,node信息)都是分机房存储的,由所在机房的
server负责。如果需要请求其它机房的数据,则server会将请求转发到对应的机房。
比如dc1的某个应用app1想要获取dc2中key “hello”对应的值
过程如下
app1 --> client --> server(dc1) --> server(dc2)
如果读者仔细观察会发现,consul中,很多api都是可以加上dc参数的
consul kv get hello -datacenter dc2
- 每个dc的所有
server构成一个raft集群,client不参与选主。注意上图的leader和follower标识。 - 单个机房内部consul节点之间有gossip(端口8301)
- 机房与机房之间
server节点之间有gossip(端口8302)
2.2 可能的瓶颈
2.2.1 client对server的RPC请求
client使用server的TCP/8300端口发起RPC请求, 管理service、kv都要通过这个端口,它们之间是长连接。
1个机房如果有3w+机器,则client和server至少要建立3w+长连接。
不过萌叔观察了一下,3w+长连接是相对均匀的分布在多个server上的,也就是说如果你有6台consul server, 那么每个server最多处理5k个长连接。还是可以接收的。
对于server的处理能力我简单压测了一下。大约是15k qps
Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz
4核CPU 8G内存
╰─$ wrk -t10 -c500 -d30s http://dev2:8500/v1/health/service/consul
Running 30s test @ http://dev2:8500/v1/health/service/consul
10 threads and 500 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 33.15ms 17.65ms 209.29ms 77.50%
Req/Sec 1.56k 330.91 2.46k 66.33%
464810 requests in 30.03s, 1.06GB read
Requests/sec: 15476.11
Transfer/sec: 36.31MB
如果只是把consul作为注册中心,client与server主要是long polling,假定1分钟1个请求、1000个微服务、3w台机器、5个server
30000 * 1000 / 60 / 5 = 100,000
server如果不做扩容,可能有风险
2.2.2 Lan Gossip
很多人会担心局域网内部的Gossip带来的网络风暴。
- 笔者抓包看了一下,虽然consul节点同时监听TCP和UDP的8301端口,但实际上Gossip的数据包都是UDP包。每秒只有几个。
- Gossip包分为2类,一类是probe探针用于探活,一类是push/pull 用于交换信息
- 来看一下Gossip的默认参数
GossipLANGossipInterval 200ms // push/pull间隔
GossipLANGossipNodes 3 // push/pull选择的node数量
GossipLANProbeInterval 1s // probe间隔,其实probe node数量为1
GossipWANGossipInterval 500ms
GossipWANGossipNodes 3
所以QPS是各位数,对性能没有影响
参考笔者的文章 聊聊GOSSIP的一个实现
2.2.3 跨DC的RPC请求
这个可能是大问题,每个跨DC的RPC请求,将会导致本机房的server和目标机房的server各处理一个请求,请求压力相当于翻倍。不过还好可以通过水平扩展server来解决
posted on 2019-11-19 15:27 ExplorerMan 阅读(1453) 评论(1) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号