大数据应用期末总评
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
一、课程评分标准:
分数组成:
考勤 10
平时作业 30
爬虫大作业 25
Hadoop生态安装与配置 10
分布式文件系统HDFS
分布式并行计算MapReduce
Hadoop综合大作业 25
评分标准:
难易程度
数据量
文章质量:描述、分析与总结
二、17周演示检查:《爬虫大作业》和《Hadoop综合大作业》
三、Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
2.对CSV文件进行预处理生成无标题文本文件
3.把hdfs中的文本文件最终导入到数据仓库Hive中
4.在Hive中查看并分析数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
四、材料提交方式及日期
- 每人提交一个文件夹,以学号姓名命名
- 个人文件夹里包含三个作业的材料:
- 代码
- 结果
- 博客文章
- 请在2019/06/21 日期之前提交给学委
- 学委收齐后,整理刻录一张光盘交给老师。
- 空白光盘可找老师领取
- 建一个班级文件夹,里面放一个一个同学的文件夹,都不要压缩
五、爬虫大作业分析的数据
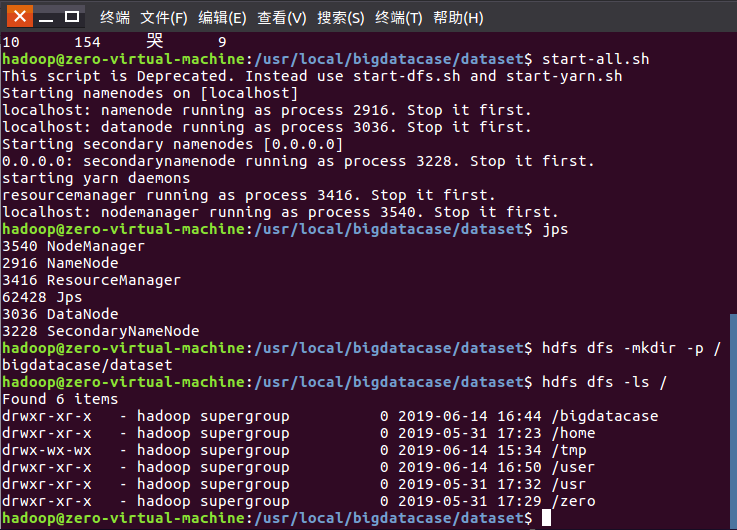
1.将爬虫大作业产生的csv文件上传到HDFS
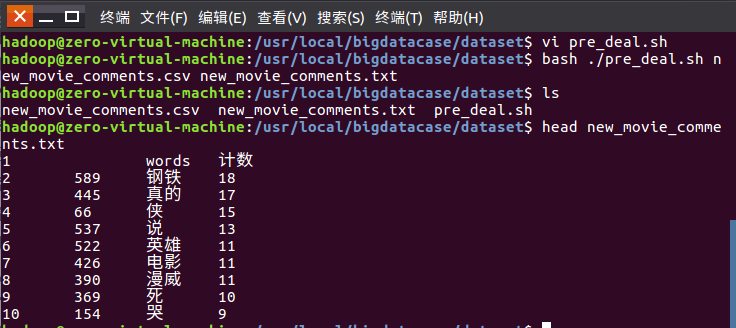
2.对CSV文件进行预处理生成无标题文本文件
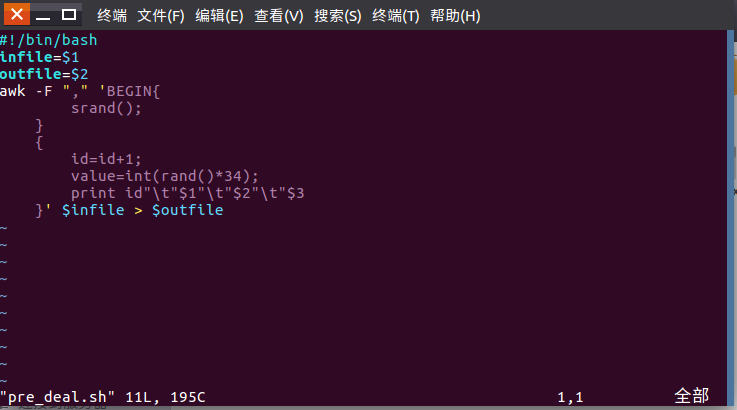
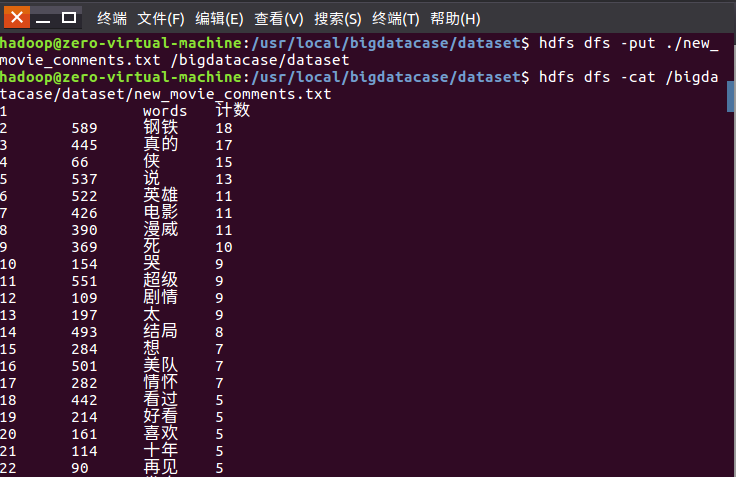
3.把hdfs中的文本文件最终导入到数据仓库Hive中
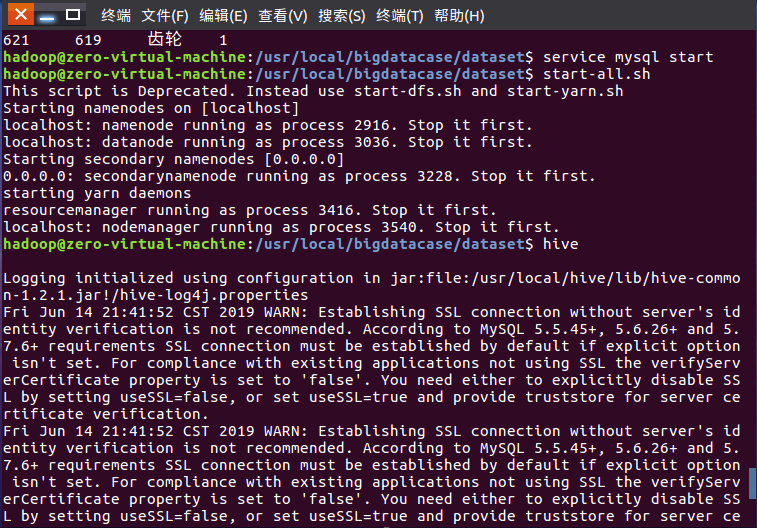
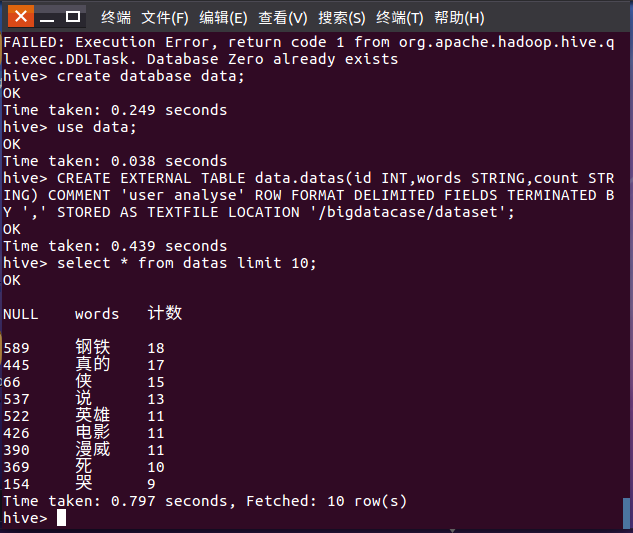
4.在Hive中查看并分析数据
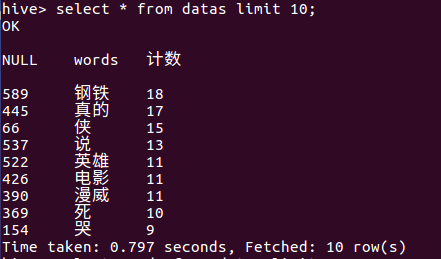
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
(1)查看排名前十的数据
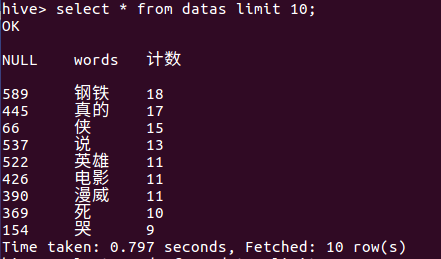
(2)查看排名前十的词语
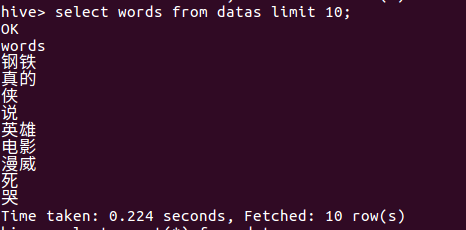
(3)查看总共有多少数据
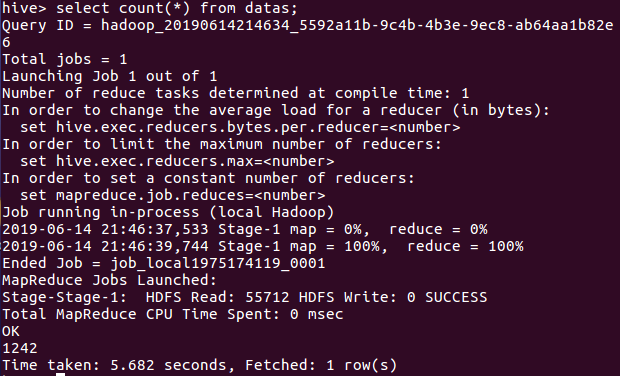
(4)查看总共有多少个词语
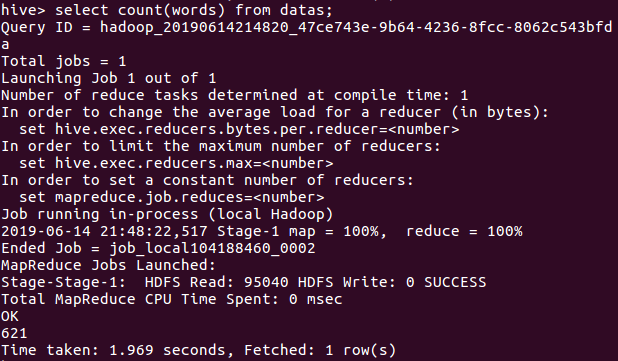
(5)查看排名前二十词语的计数

(6)查看出现数大于5的词语
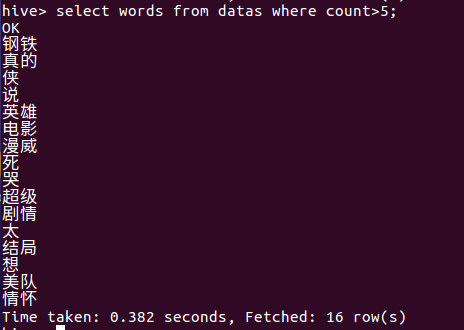
(7)查看前20个出现的词语
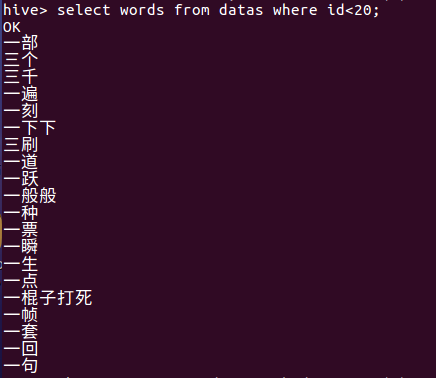
(8)查看词语数大于5的出现位置
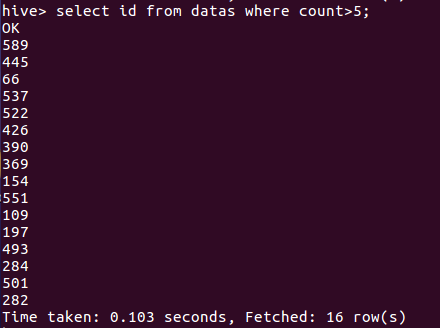
(9)查看词语“钢铁”出现的位置

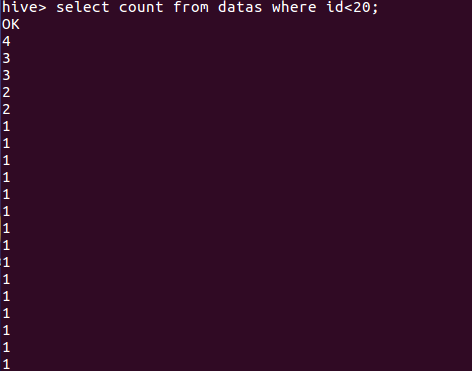
(10)查看前20个出现词语的数量
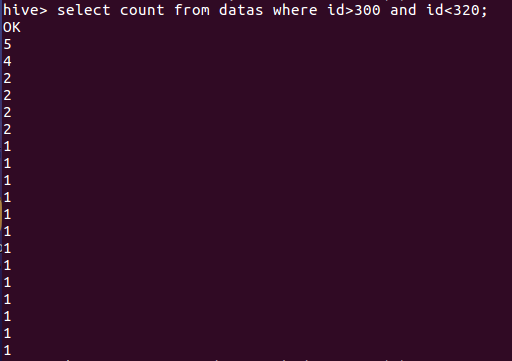
(11)查看出现位置在300到320之间的词语的数量