

爬虫综合大作业
本次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:\duym\gzccnews.csv')
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
源代码
import sqlite3
with sqlite3.connect(r'E:\gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con=db)
import sqlite3
with sqlite3.connect('E\gzccnewsdb.sqlite') as db:
df2=pd.read_sql_query('SELECT * FROM gzccnewsdb',con=db)
df2
运行结果
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
源代码
import pymysql import pandas as pd from sqlalchemy import create_engine coninfo="mysql+pymysql://root:@localhost:3306/gzccnews?charset=utf8" engine=create_engine(coninfo,encoding='utf-8') df=pd.DataFrame(allnews) df.to_sql(name='news',con=engine,if_exists='append',index=False,index_label=False)
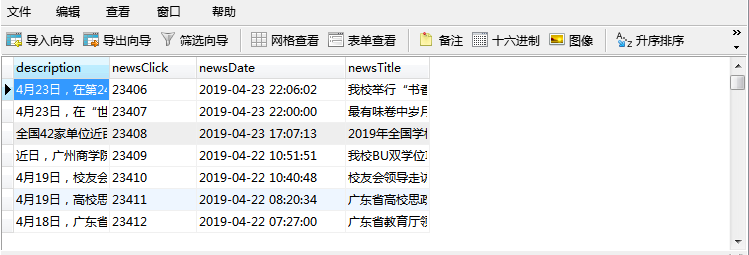
运行结果
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
参考:
爬了一下天猫上的Bra购买记录,有了一些羞羞哒的发现...
Python做了六百万字的歌词分析,告诉你中国Rapper都在唱些啥
分析了42万字歌词后,终于搞清楚民谣歌手唱什么了
十二星座的真实面目
唐朝诗人之间的关系到底是什么样的?
中国姓氏排行榜
三.爬虫注意事项
1.设置合理的爬取间隔,不会给对方运维人员造成压力,也可以防止程序被迫中止。
- import time
- import random
- time.sleep(random.random()*3)
2.设置合理的user-agent,模拟成真实的浏览器去提取内容。
- 首先打开你的浏览器输入:about:version。
- 用户代理:
- 收集一些比较常用的浏览器的user-agent放到列表里面。
- 然后import random,使用随机获取一个user-agent
- 定义请求头字典headers={’User-Agen‘:}
- 发送request.get时,带上自定义了User-Agen的headers
3.需要登录
发送request.get时,带上自定义了Cookie的headers
headers={’User-Agen‘:
'Cookie': }
4.使用代理IP
通过更换IP来达到不断高 效爬取数据的目的。
headers = {
"User-Agent": "",
}
proxies = {
"http": " ",
"https": " ",
}
response = requests.get(url, headers=headers, proxies=proxies)
四、第11周课堂检查
五、爬虫综合大作业
用python爬取豆瓣短评生成词云简单分析《复仇者联盟4》
导读:漫威影业荣誉出品《复仇者联盟4:终局之战》,故事发生在灭霸消灭宇宙一半的生灵并重创复仇者联盟之后,剩余的英雄被迫背水一战,为22部漫威电影写下传奇终章。要说最近一段时间最火爆的是什么,就非《复仇者联盟4》莫属了。这部电影在国内上映才5天,票房就已经破了21亿,不知道这部电影的票房最后会不会超过吴京的《战狼》呢?到底这部漫威影业荣誉出品的科幻电影总体口碑如何?我分别爬取了从上映日起到4月30日10时豆瓣电影《复仇者联盟4:终局之战》的热门和最新的短评数据,通过硬核的分析告诉你答案!
(一)我选取的编译语言是 python,工具是pycharm
(二)我分别打开复仇者联盟4的豆瓣热门和最新的短评页面,鼠标右键打开谷歌浏览器调试,发现短评都在id=comments的div标签里,而详细的评论是在class=short的span标签里。
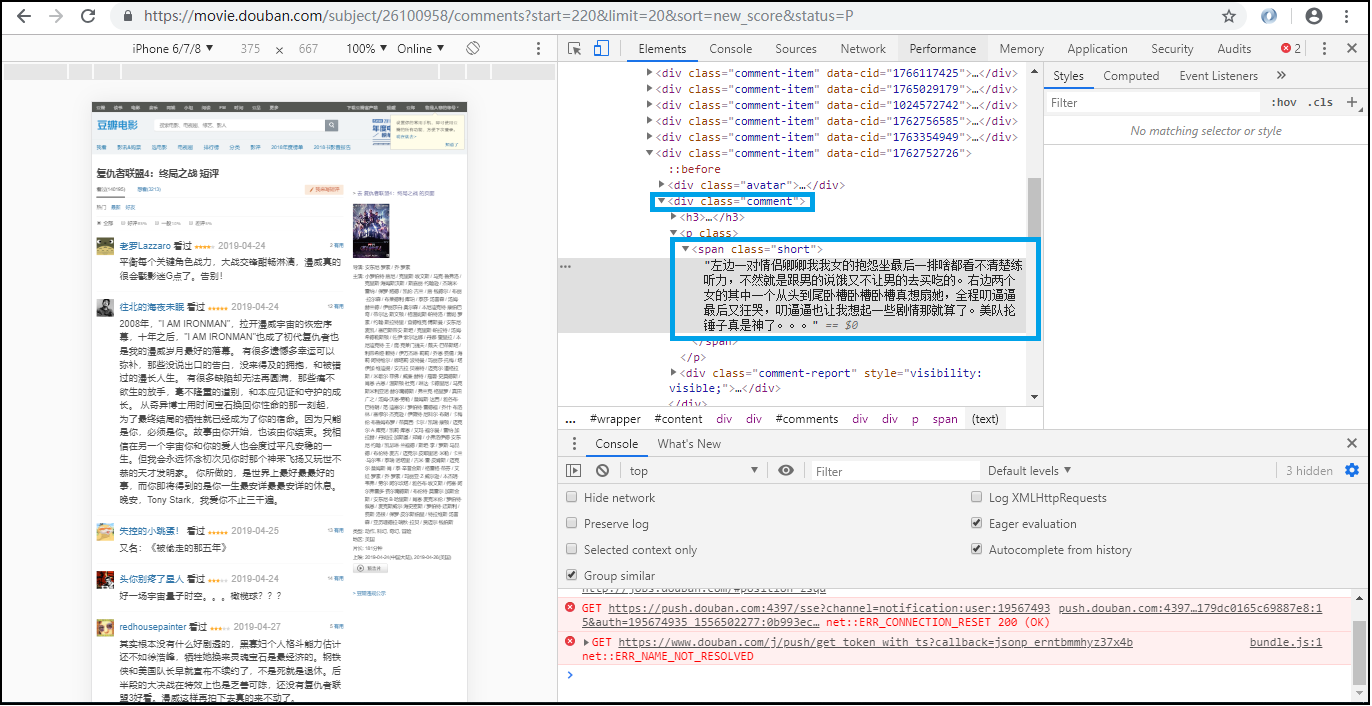
图1 热门短评所在的位置
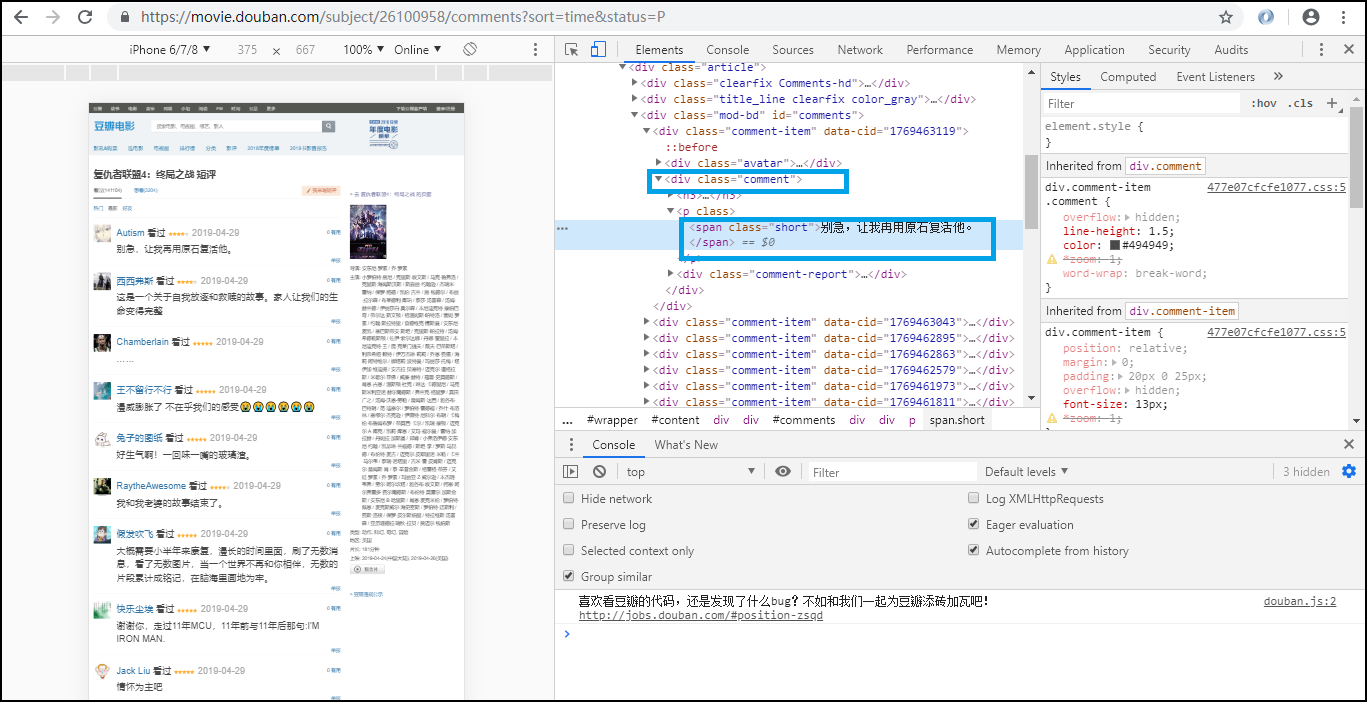
图2 最新短评所在的位置
(三)观察复仇者联盟4请求的url
热门短评的url
第一页 https://movie.douban.com/subject/26100958/comments?status=P 第二页 https://movie.douban.com/subject/26100958/comments?start=20&limit=20&sort=new_score&status=P 第三页 https://movie.douban.com/subject/26100958/comments?start=40&limit=20&sort=new_score&status=P
最新短评的url
第一页 https://movie.douban.com/subject/26100958/comments?sort=time&status=P 第二页 https://movie.douban.com/subject/26100958/comments?start=20&limit=20&sort=time&status=P 第三页 https://movie.douban.com/subject/26100958/comments?start=40&limit=20&sort=time&status=P
我从中发现url变化的部分是'start=""',变化的规律是start=(20*(起始页-1))
(四)编写代码
1.设置合理的爬取间隔,不会给对方运维人员造成压力,也可以防止程序被迫中止。
import time
import random
time.sleep(random.random()*3)
2.设置合理的user-agent,模拟成真实的浏览器去提取内容。
首先打开你的浏览器输入:about:version。
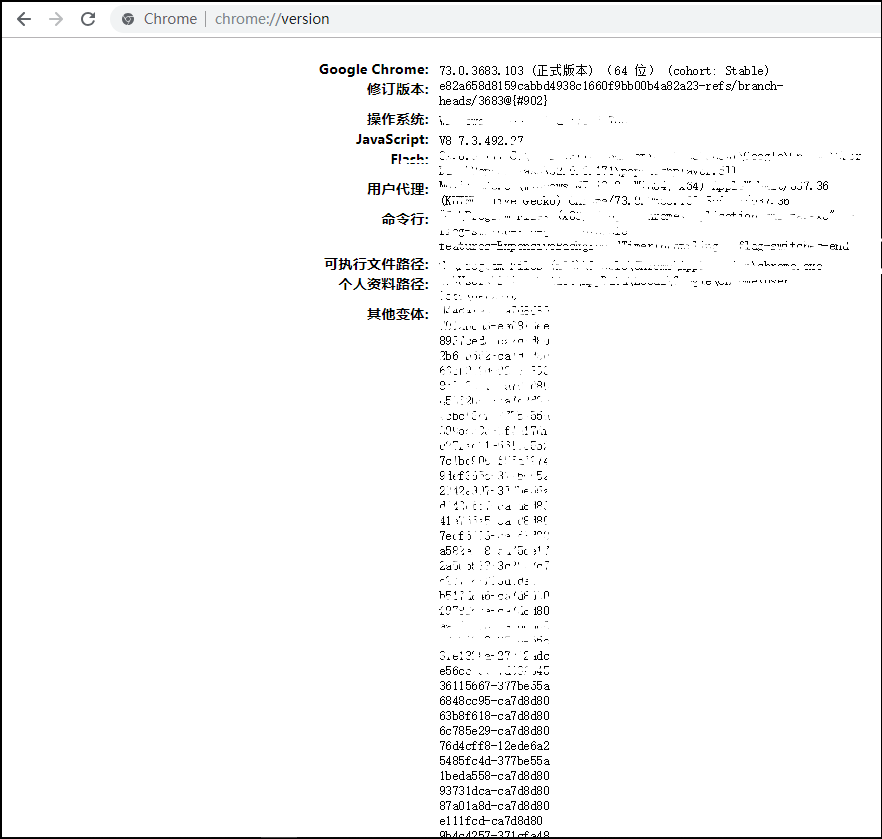
图3 version版本
用户代理:
收集一些比较常用的浏览器的user-agent放到列表里面。
然后import random,使用随机获取一个user-agent
定义请求头字典headers={’User-Agen‘:}
发送request.get时,带上自定义了User-Agen的headers
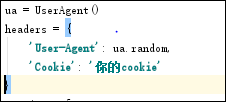
图4 User-Agen的headers
3.需要登录
发送request.get时,带上自定义了Cookie的headers
headers={’User-Agen‘:
'Cookie': }
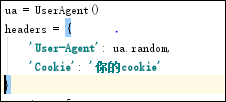
图5 Cookie的headers
4.使用代理IP
通过更换IP来达到不断高 效爬取数据的目的。
headers = {
"User-Agent": "",
}
proxies = {
"http": " ",
"https": " ",
}

图6 代理IP
(五)实现功能
部分代码(完整代码在课堂演示)
def getcomments(): ua = UserAgent() headers = { 'User-Agent': ua.random, 'Cookie': '你的cookie' } proxies = [ {"http": "61.135.217.7:80"}, {"http": "111.155.116.245:8123"}, {"http": "122.114.31.177:808"} ] for i in range(0, 25): res = requests.get('https://movie.douban.com/subject/26100958/comments?start=' + str(20 * i) + '&limit=20&sort=new_score&status=P&percent_type=',verify=False,headers=headers,proxies=random.choice(proxies)) res.encoding='utf-8' html_data = res.text print('正在访问第:'+str(i+1)+'页') Soup = BeautifulSoup(html_data, 'html.parser') comments = Soup.find_all('div', id='comments') comments_content = comments[0].find_all('p') time.sleep(random.random() * 30) print('正在解析第:' + str(i+1) + '页') for j in range(0, 20): text = str(comments_content[j]) print(text) f = open('movie_comments.txt', 'a+', encoding='utf-8') f.write(text) getcomments()
实现效果

图7 最新短评词云

图8 热门短评词云
(六)总结
总体来说,观看《复仇者联盟4》的观众对于这部电影的大部分评论都是围绕着"漫威"、"钢铁侠"的内容进行评论,可以看出观众看完这部电影后的大部分感觉是对漫威这部电影有着不错的看法和不舍的心情。
遇到的问题:在用cookie模仿登陆的时候,cookie有时效,隔段时间后要重新获取cookie。

