贪心算法
题目一:
一块金条切成两半,是需要花费和长度数值一样的铜板的。比如长度为20的金条,无论切成长度多大的两半,都要花费20个铜板。
一群人想整分一整块金条,怎么分最省铜板?
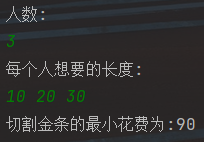
例如,给定数组[10,20,30],代表一共三个人,整块金条长度为10+20+30=60。把金条分为10,20,30三个部分。如果先把长度为60的金条分为10和50,花费60;再把长度为50的金条分为20和30,花费50,一共花费110铜板。但如果先把长度为60的金条分为30和30,花费60,再把长度为30的金条分为10和20,花费30,则一共花费90铜板。
输入一个数组,返回分割的最小代价。
这题典型用贪心:
想想,我先分一下,例如上面的60,我第一次分就分出了一个30,然后再分出10和20,这个过程是不是类似于哈夫曼树?虽然上面第一中分发也是这样,但题目所求的最小代价其实就是哈夫曼树的最小带权路径长度。
于是我们就有思路了。
我们先给这个输入的数组排个序,对于java而言,我们可以使用其封装好的数据结构——小顶堆来实现:
1 private static class MinHeapComparator implements Comparator<Integer> { 2 @Override 3 public int compare(Integer o1, Integer o2) { 4 return o1 - o2; 5 } 6 }
然后,我们从堆中拿出两个元素,相加,把和再扔进堆中...循环往复。直到堆中只剩一个元素为止。这完完全全就是在创建一棵哈夫曼树!
完整代码:
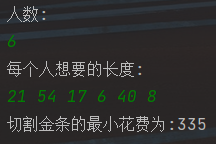
package com.hw.Greedy02; import java.util.Comparator; import java.util.PriorityQueue; import java.util.Scanner; public class LessMoneySplitGold { private static class MinHeapComparator implements Comparator<Integer> { @Override public int compare(Integer o1, Integer o2) { return o1 - o2; } } private static int lessMoney(int[] arr) { PriorityQueue<Integer> queue = new PriorityQueue<>(); for (int i = 0; i < arr.length; ++i) { //先全部扔到小顶堆里面去 queue.add(arr[i]); } int sum = 0; //最终的结果总和 int cur = 0; //循环中间量 //这里就相当于哈夫曼树的创建 while(queue.size() > 1) { cur = queue.poll() + queue.poll(); sum += cur; queue.add(cur); } return sum; } public static void main(String[] args) { Scanner s = new Scanner(System.in); System.out.println("人数:"); int len = s.nextInt(); System.out.println("每个人想要的长度:"); int[] data = new int[len]; for (int i = 0; i < len; ++i) { data[i] = s.nextInt(); } s.close(); int result = lessMoney(data); System.out.println("切割金条的最小花费为:" + result); } }
题目二:
给定一个数组,数组里面存储的数据是一些字符串,试求解一种字符串拼接方式,把这个数组中所有字符串都拼接起来,并使得这个最终拼接而成的字符串具有最小字典序。
可能一开始我们的思路是这样的:把所有这些字符串全部排序,哪个的字典序小哪个就在前面。这样一来看似合理,但是有例外。举个反例:“b”,“ba”.这是两个字符串,单看每个字符串的字典序,肯定b会更小。所以我们把b放前面,也就是“bba”,但如果把“ba”放前面,即“bab”,我们会发现其实后者的字典序更小。所以这种思路是错的。
怎么办呢?我们需要选取合适的贪心策略。
而合适的贪心策略就是,我们每次先按照先后顺序拼接一下字符串,例如,“b”,“ba”.这是两个字符串,我们先拼接成“bba”,再拼接成“bab”,显然后者字典序更小,所以我们选择后者。就这么简单。
来看看代码:
1 package com.hw.Greedy02; 2 3 import java.util.Arrays; 4 import java.util.Comparator; 5 6 public class LowestLexicography { 7 private static class MyComparator implements Comparator<String> { 8 //贪心策略 9 @Override 10 public int compare(String a, String b) { 11 return (a + b).compareTo(b + a); 12 } 13 } 14 15 public static String lowestString(String[] data) { 16 if (data == null || data.length == 0) { 17 return ""; 18 } 19 String result = ""; 20 Arrays.sort(data, new MyComparator()); 21 for (int i = 0; i < data.length; ++i) { 22 result += data[i]; 23 } 24 return result; 25 } 26 27 public static void main(String[] args) { 28 String[] data = {"zoo", "b", "ba", "computer", "science", "apple"}; 29 String result = lowestString(data); 30 System.out.println(result); 31 } 32 }
静态内部类定义的是一个比较器,方便数组排序时使用。

题目三:
一些项目要占用一个会议室宣讲, 会议室不能同时容纳两个项目的宣讲。给你每一个项目的开始时间和结束时间(给你一个数组,里面是一个个具体的项目),你来安排具体的日程。要求会议室进行的宣讲的场次最多。返回这个最多的宣讲场次。
对于这道题,我们同样需要选定一个恰当的贪心策略。
我们可以想想,选择的策略就是,我们以会议项目结束的时间进行选择。当某一个会议结束后,开始了的就不选了,看看哪个还没开始,选择与已结束会议结束时间最近的未开始会议。
我们先定义一个内部类,就叫Program,
1 public static class Program { 2 public int start; 3 public int end; 4 5 public Program(int start, int end) { 6 this.start = start; 7 this.end = end; 8 } 9 }
每一个用这个类创建的对象都代表一个项目,所以拥有开始时间和结束时间。
我们定义一个当前时间对项目进行跟进。当这个当前时间小于某一个项目的开始时间时,我们就选择这个项目,然后更新当前时间即可。
1 package com.hw.greedy; 2 3 import java.util.Arrays; 4 import java.util.Comparator; 5 6 public class BestArrange { 7 public static class Program { 8 public int start; 9 public int end; 10 11 public Program(int start, int end) { 12 this.start = start; 13 this.end = end; 14 } 15 } 16 17 public static class ProgramComparator implements Comparator<Program> { 18 @Override 19 public int compare(Program o1, Program o2) { 20 return o1.end - o2.end; 21 } 22 } 23 24 public static int bestArrange(Program[] programs, int timePoint) { 25 //programs:所有项目(会议) 26 //timePoint:目前所来到的时间点 27 //先把所有项目根据谁的结束时间早进行排序 28 //给定一整个时间段和若干项目或会议以及这些项目或会议的开会时间,求在这时间段里怎样安排使得项目或会议数最多 29 //按照结束时间早的进行选择 30 Arrays.sort(programs, new ProgramComparator()); 31 int result = 0; 32 for (int i = 0; i < programs.length; ++i) { 33 if (timePoint <= programs[i].start) { 34 ++result; 35 timePoint = programs[i].end; 36 } 37 } 38 return result; 39 } 40 }
我们来测试一下这段代码:
1 public static void main(String[] args) { 2 Program[] programs = new Program[10]; 3 Program pro1 = new Program(1230, 1330); 4 programs[0] = pro1; 5 Program pro2 = new Program(1315, 1520); 6 programs[1] = pro2; 7 Program pro3 = new Program(1225, 1445); 8 programs[2] = pro3; 9 Program pro4 = new Program(1430, 1630); 10 programs[3] = pro4; 11 Program pro5 = new Program(1425, 1730); 12 programs[4] = pro5; 13 Program pro6 = new Program(1445, 1625); 14 programs[5] = pro6; 15 Program pro7 = new Program(1525, 1835); 16 programs[6] = pro7; 17 Program pro8 = new Program(1535, 1655); 18 programs[7] = pro8; 19 Program pro9 = new Program(1610, 1830); 20 programs[8] = pro9; 21 Program pro10 = new Program(1715, 1945); 22 programs[9] = pro10; 23 int result = bestArrange(programs, 1200); 24 System.out.println(result); 25 }

经检验,无误。
