



本次学习我受益匪浅,主要学习了Ascend C算子开发及其相关知识点,现总结如下:
一、相关知识
1.Ascend C算子采用标准C++语法和一组类库API进行编程,方便根据自己的需求开发算子,可以用于 Ascend 处理器。对于算子,可以理解为各类抽象的映射、网络中的层等,根据需求实现相应运算。算子的输入输出数据类型为Tensor(张量)
2.Ascend 处理器采用自研达芬奇架构(可以加速矩阵乘法计算)+高集成Soc,达芬奇架构分为计算单元、存储单元和搬运单元。
3.CANN是用于算子开发的框架。,Ascend C 算子编程语言是专门为 CANN 开发的,可以根据直接的需要编写算子,提高性能。eg:两个16*16的矩阵进行计算,从需要8192条指令优化为1条指令。
二、算子开发
1.算子的开发流程为算子分析、核函数定义、根据矢量编程范式实现算子类。
2.算子实现三个流水任务CopyIn、Compute、CopyOut。任务间通过队列VECIN、VECOUT进行通信和同步,由pipe内存管理对象对任务间交互使用到的内存、临时变量使用到的内存统一进行管理。
3.多个核:如对于(8,2048)的数据使用AIcore的8个核,则需要使用
constexpr int32_t TOTAL_LENGTH = 8 * 2048; // total length of data
constexpr int32_t USE_CORE_NUM = 8; // num of core used
constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; // length computed of each core
constexpr int32_t TILE_NUM = 8; // split data into 8 tiles for each core
constexpr int32_t BUFFER_NUM = 2; // tensor num for each queue
constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM;
分割成16块,每块长度128,此外还需要注意设置好偏移量
三、微认证
1.核函数开发
核函数(Kernel Function)是Ascend C算子设备侧实现的入口。在核函数中,需要为在一个核上执行的代码规定要进行的数据访问和计算操作,当核函数被调用时,多个核都执行相同的核函数代码,具有相同的参数,并行执行。核函数的定义为:
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z);
2.Kernel直调工程体验
(1)进入相应文件夹
cd ~/samples/operator/AddCustomSample/KernelLaunch/ cp -r AddKernelInvocationNeo/ test cd test/ bash run.sh -r cpu -v Ascend310P1
观察结果,发现没有输出正常结果
(2)用MobaXTerm左侧的文件栏打开~/samples/operator/AddCustomSample/KernelLaunch/test/scripts/gen_data.py
修改其中代码:
input_x = np.random.uniform(1,10,[8,2048]).astype(np.float16) golden = np.sinh(input_x).astype(np.float16)
保存
再打开add_custom.cpp
修改其中compute()函数,把“Add(xxxxxxxxxxxxxxxxx)”那一行注释掉,改成sinh的计算逻辑,用xLocal当输入,zLocal当输出,改完后保存。
这样就完成了sinh的计算逻辑
使用下面的语句再次进行测试:
bash run.sh -r cpu -v Ascend310P1
输出“test pass”即为修改成功,此时,已经成功完成了sinh的计算逻辑。
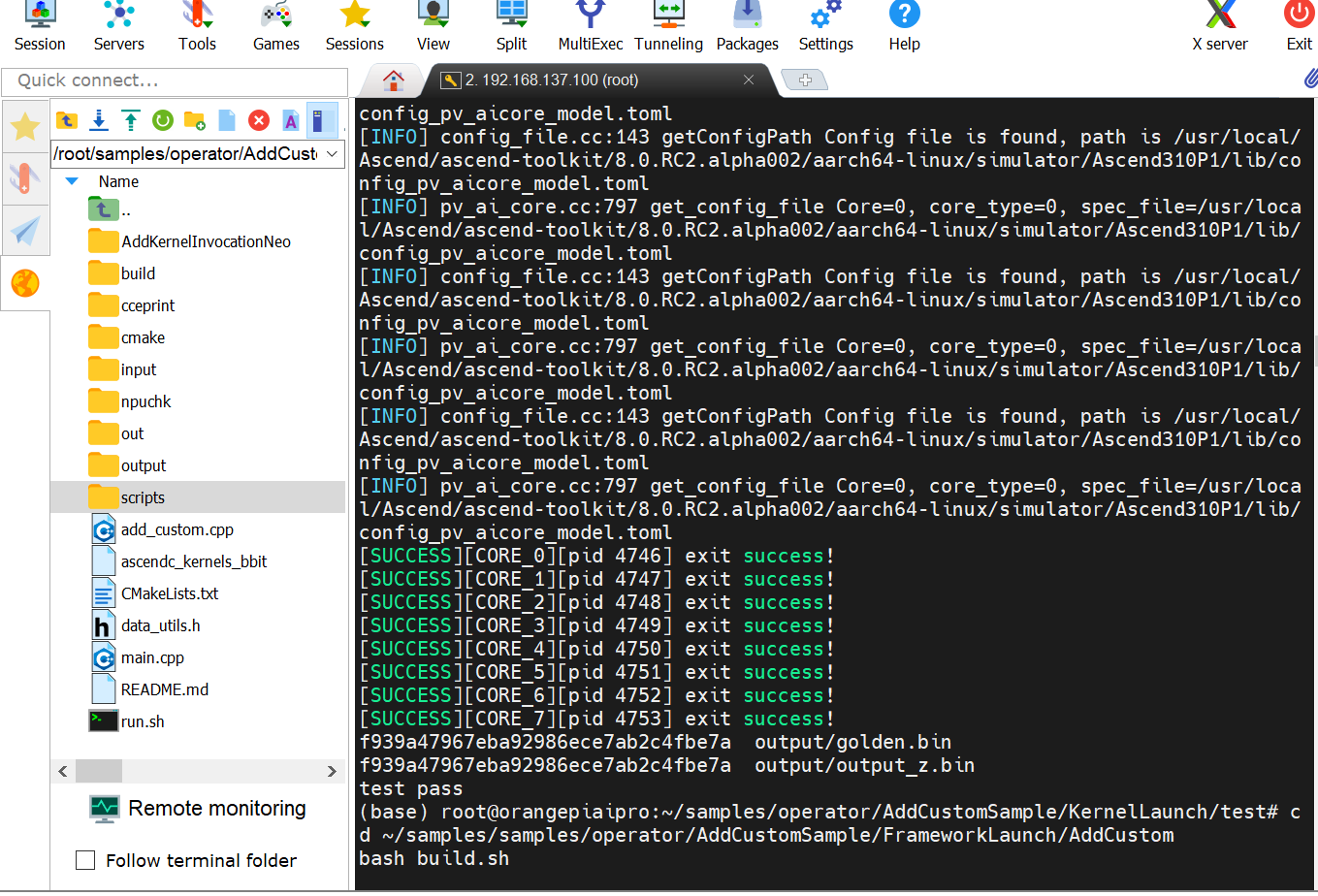

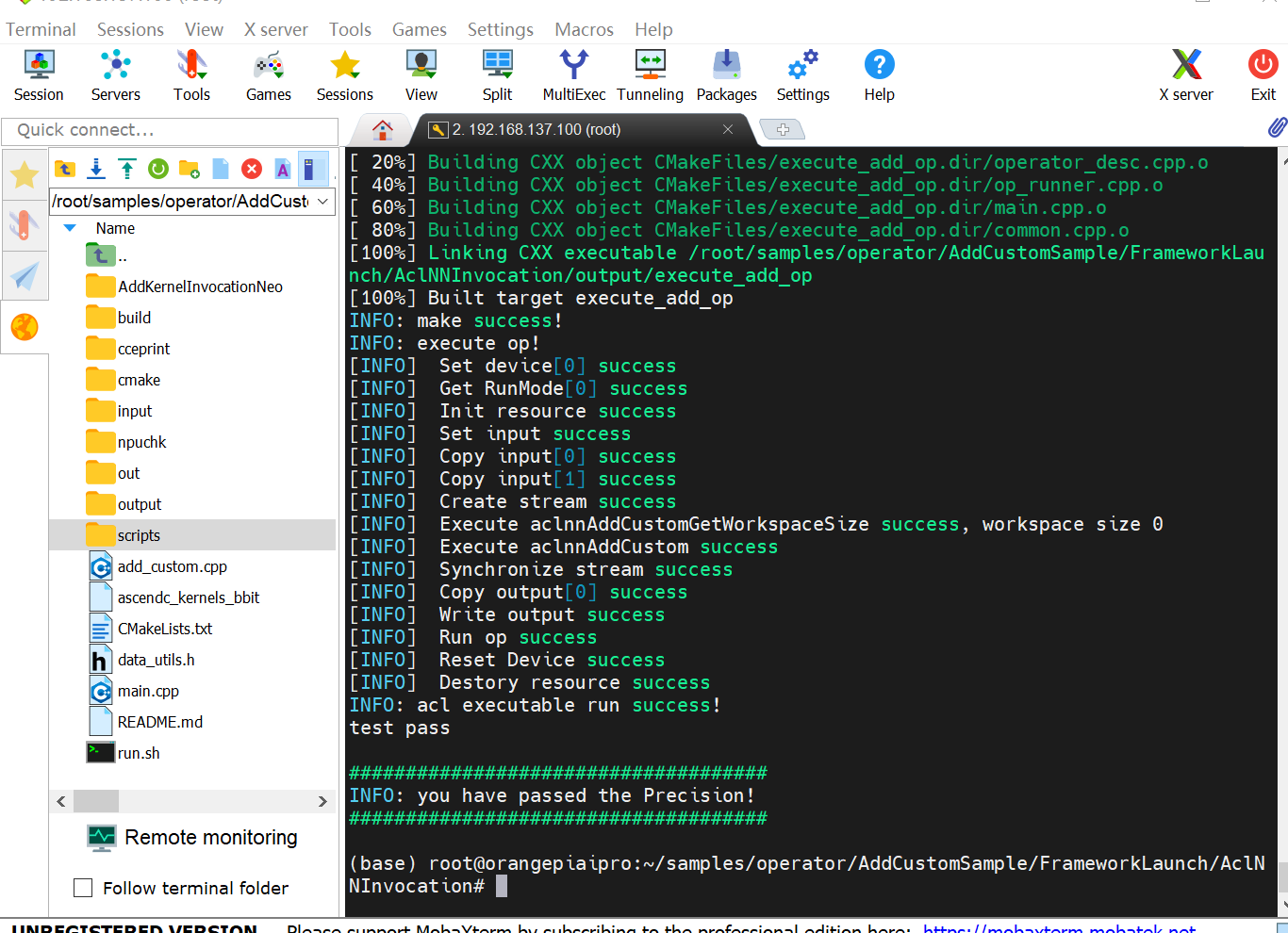
cd ~ /samples/operator/AddCustomSample/FrameworkLaunch/AddCustom bash build.sh cd build_out ./custom_opp_ubuntu_aarch64.run cd ~/samples/samples/operator/AddCustomSample/FrameworkLaunch/AclNNInvocation bash run.sh
四、矩阵计算
Ascend C的矩阵计算为A*B+偏移量
前面已经说了Ascend C的矩阵计算单元可以快速完成 16 x 16 的矩阵乘法,但当输入超过 16 x 16 的矩阵相运算时,需要进行分块处理,如下图。

五、性能优化
性能优化主要优化Tilling,关键是如何划分,优化好Tilling可以带来数倍的提升,但是其他方面可能只有几个百分点的提升。
之前的实验是固定维度的输入输出,但实际情况往往不同
1.Tiling实现:数据切分
2.Shape推导:根据输入数据数据的张量描述,算子逻辑,算子属性,可以得到输出结果的各种属性
3.算子原型注册


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本