学习python日记(基础篇)
 学习python的记录
学习python的记录
python主要是看着小甲鱼的视频开始的
变量和字符串
1 temp = int(input("这次数学考试的成绩:")) 2 3 if temp == 100: 4 print("6") 5 else: 6 print("2") 7 print("4")
在编写这个程序时,忘了“:”和int(),一个是格式的错误,还有一个细节上的错误
然后记录一下,print函数的使用
sep和end的设置,end 默认是换行
name = input("请输入您的名字:") print("你好", name, sep=",", end="!")
避免转义字符的误会,使用原始字符串(在前面加个r)
print(r"D:\three\two\one\now")
还有使用“\”表示还没说完,不会换行
print("hh\ jjj\ lll")
也可以使用三引号表示没说完,且会自动换行
print("""hhh uiswhq oidh""")
字符串也能进行加法和乘法
'233'+'321' 结果:'233321' "21"*3 结果:'212121'
再补充一个常用的东西,大概在字母和数字的应用中经常用到
#这个代码可以得到位移之后的字母是什么 #key是需要位移的数,base一般是ord(A)或者ord(a) # ord(each) - base 操作得到一个字母的偏移值,比如 b 就是 1 # 跟 26 求余数的作用是防止溢出,循环计算偏移 chr((ord(each) - base + key) % 26 + base)
随机数
在调用随机数时,首先要引入再使用
import random
a = random.randint(1,10)
比较印象深刻的有random.randint, random.sample, random.randrange
具体其他的可以参考小甲鱼的编写的文档
数字类型
问题的出现:python计算浮点数有一定误差,0.1+0.2=0.30000000000000004
问题的解决:可以使用decimal来解决
>>>import decimal
>>>a = decimal.Decimal(0.1) >>>b = decimal.Decimal(0.2) >>>c = decimal.Decimal('0.3') >>>a+b == c True
然后再记录一下复数
x=1+2j x.real 1.0 x.imag 2.0
还有数字的运算
还有运算优先级
记录一下我运算优先级犯的错误
#错误的代码:得到的条件一直为真 a = "()" In[32]:a[1]=="["or"{" Out[32]: '{' #改正后的代码(此处代码在一个循环体中) if (a[i+1] == "]")or(a[i+1] == "}")
数字的储存(冷门)
#出于性能优化方面的考虑,Python 在内部为 -5~256 范围内的整数维护了一个数组,起到缓存的作用 a =25 b=25 a is b Out[87]: True #如果超过了 -5~256 这个范围(大家可以自己动手测试一下),比如1000,那么 Python 会为两个 1000 单独开辟两块不同的内存区域,因此 a is b 的结果为 False a=456 b=456 a is b Out[96]: False
分支和循环
学习了一个“炫技”的方法
1 #一般的if语句 2 score = int(input("请输入分数")) 3 4 if score <= 80: 5 print("C") 6 elif score <= 90: 7 print("B") 8 else: 9 print("A") 10 11 #合并为一句 12 level = ("C" if score<=80 else 13 "B" if score<=90 else 14 "A") 15 print(level)
此外,else 还能和 while 搭配使用
1 i = 0 2 while i<7: 3 i += 1 4 Eanswer = input('你喜欢Monika吗(Y/N)') 5 if Eanswer == "N": 6 break 7 else: 8 print("DokiDoki")
再介绍一下continue,程序的输出结果为1,3,5,7,9
1 i = 0 2 while i<10: 3 i += 1 4 if i%2==0: 5 continue 6 print(i)
列表
简单部分
python的列表可以容纳很多东西
a = [1,2,"zky"]
列表的索引和切片
a[:]=[1, 2, 'zky'] a[:1]=[1] a[1:]= [2, 'zky'] a[1]=2
在列表里加其他元素
a.append('Eupho') a = [1, 2, 'zky', 'Eupho']
a.extend(["Huang","Gao"]) #extend 的对象需要是可迭代对象
a = [1, 2, 'zky', 'Eupho', 'Huang', 'Gao']
a[len(a):]=["Hibike"] #也可以使用切片实现
a = [1, 2, 'zky', 'Eupho', 'Huang', 'Gao', 'Hibike']
a.insert(5,"Xiu")
a = [1, 2, 'zky', 'Eupho', 'Huang', 'Xiu', 'Gao', 'Hibike']
在列表里删其他元素
a.remove("Xiu") #指明要删除的对象,若列表中存在多个,则只删除第一个,如果不存在,就会报错 a = [1, 2, 'zky', 'Eupho', 'Huang', 'Gao', 'Hibike'] a.pop(-1) #指明要删除对象的索引值 a = [1, 2, 'zky', 'Eupho', 'Huang', 'Gao'] a.clear() #清空a a=[]
列表和字符串的区别之一在于列表可改,字符串不能改
a = ['3',2,23,'sd','wer23'] a[1:3] =[89] a Out[14]: ['3', 89, 'sd', 'wer23']
列表的排序
a = [2,5,7,3,5,2,6] a.sort() Out[7]: [2, 2, 3, 5, 5, 6, 7] a.reverse() Out[9]: [7, 6, 5, 5, 3, 2, 2] a = [2,5,7,3,5,2,6] a.sort(reverse=True) Out[12]: [7, 6, 5, 5, 3, 2, 2]
列表的索引
a = [2,5,7,3,5,2,6] a.count(5) Out[17]: 2 a.index(5) Out[18]: 1 a.index(5,2,6) Out[19]: 4
列表浅拷贝
a=[2,3,5,2,6] b = a.copy() c=a[:]
列表的相乘相加
1 s = [1,2,3] 2 t = [2,3,4] 3 s+t 4 Out[49]: [1, 2, 3, 2, 3, 4] 5 s*3 6 Out[50]: [1, 2, 3, 1, 2, 3, 1, 2, 3]
困难部分
创建多维列表
matrix=[[1,2,3],[2,1,4],[2,6,3]]
二维列表的索引
matrix[1] Out[61]: [2, 1, 4] matrix[1][0] Out[62]: 2
依旧创建多维列表
#错误的创建 a = [0]*3 b = [a]*3 Out[68]: [[0, 0, 0], [0, 0, 0], [0, 0, 0]] b[1] is b[2] Out[72]: True #正确的创建(循环) a = [0]*3 for i in range(3): a[i] = [0]*3 a[0] is a[1] Out[75]: False #补充创建三维列表 z = [0] * 3 for i in range(3): z[i] = [0] * 3 for j in range(3): z[i][j] = [0] * 2 #我错误的创建 z = [[0]*3]*3 for i in range(3): for j in range(3): z[i][j]=[0,0]
列表和字符串的又一区别
a = [1,2,3] b = [1,2,3] a is b Out[78]: False a = 'Gongyuan' b = 'Gongyuan' a is b Out[81]: True
我们接着来讲浅拷贝和深拷贝
#前情提要 x = [1,2,3] y=x.copy() x[1]=1 y Out[107]: [1, 2, 3] x Out[108]: [1, 1, 3]
通过copy()浅拷贝,可以让x,y在不同的地址,但面对多维的数组,这样的方法却行不通了
x=[[1,2,3],[4,5,6],[7,8,9]] y=x.copy() y Out[111]: [[1, 2, 3], [4, 5, 6], [7, 8, 9]] x[1][1]=0 x Out[113]: [[1, 2, 3], [4, 0, 6], [7, 8, 9]] y Out[114]: [[1, 2, 3], [4, 0, 6], [7, 8, 9]]
这时,就需要使用深拷贝
import copy #这时的效果和浅拷贝一样 x=[[1,2,3],[4,5,6],[7,8,9]] y = copy.copy(x) x[1][1]=1 y Out[119]: [[1, 2, 3], [4, 1, 6], [7, 8, 9]] #深拷贝 x=[[1,2,3],[4,5,6],[7,8,9]] y = copy.deepcopy(x) x[1][1]=1 x Out[123]: [[1, 2, 3], [4, 1, 6], [7, 8, 9]] y Out[124]: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
此处在补充一个多维数组排序,对多维数组排序使用.sort(),会被返回None,需要使用sorted()
x=[[0,1],[0,3],[0,1,1],[0,1,1],[2,6]]
sorted(x)
Out[8]: [[0, 1], [0, 1, 1], [0, 1, 1], [0, 3], [2, 6]]
列表推导式
在做小甲鱼第五次作业时,最后一题做的很痛苦,索引值感觉很混乱,但好歹终于还是写出来了,但有些烦躁,感觉不像往日那么简洁了~然后玩了好一会,才进入了列表推导式的学习,分外惊喜,又变得pythonic起来
#所有元素乘于2 oho=[1,5,3,7] x = [i*2 for i in oho] x Out[138]: [2, 10, 6, 14] #迭代 oho=[1,5,3,7] x = [i*2 for i in oho] x Out[138]: [2, 10, 6, 14] x = [i for i in range(3)] x Out[140]: [0, 1, 2] x = [i for i in "Gaoban"] x Out[142]: ['G', 'a', 'o', 'b', 'a', 'n']
这个语句,可以转换为如下代码(不是逐一更换x中的元素,而是直接换了个对象~)
x = [] for i in range(10): x.append(i) x Out[145]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
然后再来挑战难一些的列表推导式
matrix = [[1,2,3], [4,5,6], [7,8,9]] #抽取第二列元素 x = [row[1] for row in matrix] x Out[148]: [2, 5, 8] #抽取对角线元素 x = [matrix[i][i] for i in range(3)] x Out[152]: [1, 5, 9]
用列表推导式创建多维矩阵
S = [[0]*3 for i in range(3)] Out[154]: [[0, 0, 0], [0, 0, 0], [0, 0, 0]] S[1][1]=1 Out[156]: [[0, 0, 0], [0, 1, 0], [0, 0, 0]]
列表推导式中除了可以有for循环,还可以有if语句(先执行for语句,再执行if语句,最后append())
W = [i+1 for i in range(10) if i % 2==0] Out[158]: [1, 3, 5, 7, 9] words = ["Gaoban","AR15","Huangqian","XiuYi","Axiu"] awords = [i for i in words if i[0] == 'A'] Out[164]: ['AR15', 'Axiu']
列表推导式还可以有多个for循环
matrix=[[1,2,3],[4,5,6],[7,8,9]] flatten = [col for row in matrix for col in row] Out[167]: [1, 2, 3, 4, 5, 6, 7, 8, 9]
其等价于
flatten = [] for row in matrix: for col in row: flatten.append(col) Out[170]: [1, 2, 3, 4, 5, 6, 7, 8, 9]
再来一个终极版本
_=[] for x in range(10): if x % 2 == 0: for y in range(10): if y % 3 == 0: _.append([x,y]) Out[173]: [[0, 0], [0, 3], [0, 6], [0, 9], [2, 0], [2, 3], [2, 6], [2, 9], [4, 0], [4, 3], [4, 6], [4, 9], [6, 0], [6, 3], [6, 6], [6, 9], [8, 0], [8, 3], [8, 6], [8, 9]]
再补充一个转置矩阵,挺有用的,可惜自己没编出来
>>> matrix = [[1, 2, 3, 4], ... [5, 6, 7, 8], ... [9, 10, 11, 12]] >>> Tmatrix = [[row[i] for row in matrix] for i in range(4)] >>> Tmatrix [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
然后我是用循环语句写的
matrix = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]] a = [] for j in range(len(matrix[0])): b = [] for i in range(len(matrix)): b.append(matrix[i][j]) a.append(b) print(a)
期间,犯了一个错误,再次强化一个概念,python 的变量不是一个盒子,而是一个索引
下面错误的代码,append()是一个“浅拷贝”,(a[1] is b)是True
上面正确的代码,b = [],是将b索引指向[],而没有去改变列表的内容,所以不会改变a的内容
#错误代码 matrix = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]] a = [] b = [] for j in range(len(matrix[0])): for i in range(len(matrix)): b.append(matrix[i][j]) a.append(b) print(a) #最后的结果: #[[1, 5, 9, 2, 6, 10, 3, 7, 11, 4, 8, 12], [1, 5, 9, 2, 6, 10, 3, 7, 11, 4, 8, 12], [1, 5, 9, 2, 6, 10, 3, 7, 11, 4, 8, 12], [1, 5, 9, 2, 6, 10, 3, 7, 11, 4, 8, 12]]
元组
列表方括号,元组圆括号(有时可以不加);列表可改,元组不可改
元组支持索引和切片,可用count和index函数,支持拼接和相乘,支持迭代
如何创建一个元素的元组
x=(234) type(x) Out[4]: int x=(234,) type(x) Out[6]: tuple #元组
多重幅值的原理正是元组(列表和字符串也支持元组)
t = (1,54,27) x,y,z = t x Out[9]: 1 y Out[10]: 54 z Out[11]: 27
多重复值还可以这么操作
a,b,*c='Gaoban' c Out[17]: ['o', 'b', 'a', 'n']
元组也并非固若金汤
x=([1,2,3],[5,2,8]) x[0][2]=8 x Out[14]: ([1, 2, 8], [5, 2, 8])
元组的创建速度大于列表的创建,关于计算代码运行速度的函数timeit,可以参照小甲鱼作业里的动动手一题
字符串
基本处理
这一节主要学习字符串的函数,字符串不能修改,这些函数只能传回一个新的字符串
首先是大小写转换
x ="Gao ban Li nai" #句子开头的字母变大写 x.capitalize() Out[25]: 'Gao ban li nai' #句子字母全变小写,casefold针对的语言更广泛 x.casefold() Out[26]: 'gao ban li nai' x.lower() Out[27]: 'gao ban li nai' #句子每个单词开头的字母变大写 x.title() Out[28]: 'Gao Ban Li Nai' #句子字母全变大写 x.upper() Out[29]: 'GAO BAN LI NAI' #句子字母大小写全部反写 x.swapcase() Out[30]: 'gAO BAN lI NAI'
然后是对齐方法
x="Gaoban" #居中对齐 x.center(10) Out[32]: ' Gaoban ' #右对齐 左对齐 x.rjust(10) Out[33]: ' Gaoban' x.ljust(10) Out[34]: 'Gaoban ' #用零填充 x.zfill(10) Out[37]: '0000Gaoban' "547".zfill(10) Out[38]: '0000000547' "-632".zfill(10) Out[39]: '-000000632' #填充的内容也可以自己设定 x.center(10,"@") Out[41]: '@@Gaoban@@'
字符串的查找和索引
x="GaobanLinai" #计数 x.count("a") Out[4]: 3 x.count("a",3,6) Out[5]: 1 #寻找find x.find("a") Out[6]: 1 x.rfind("a") Out[7]: 9 x.find("f") Out[8]: -1 #注意index和find的区别 x.index("a") Out[9]: 1 x.index("f") Traceback (most recent call last): File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-10-a0348b414980>", line 1, in <module>
关于缩进,可以用.expandtabs(4),来改善缩进(省略演示)
字符串替换
"Huangqian & Xiuyi".replace("Xiuyi","Gaoban") Out[11]: 'Huangqian & Gaoban'
字符串翻译
table = str.maketrans("abcdef","123456") 'Huangqian & Gaoban'.translate(table) Out[13]: 'Hu1ngqi1n & G1o21n' 'Huangqian & Gaoban'.translate(str.maketrans("abcdef","123456","&")) Out[14]: 'Hu1ngqi1n G1o21n'
还可以对字符串的内容进行判断
x = "In my room" #可以判断字符串的开头和结尾 x.startswith("In m") Out[5]: True x.endswith("oom") Out[6]: True x.startswith("my",3) Out[8]: True #判断是否所有单词开头都是大写 x.istitle() Out[9]: False #判断是否所有字母都是大写 x.isupper() Out[10]: False x.upper() Out[11]: 'IN MY ROOM' x.upper().isupper() Out[12]: True #判断是字母 x.isalpha() Out[13]: False "Inmyroom".isalpha() Out[14]: True #判断是否是空格 " \n".isspace() Out[15]: True #判断是否能打印 " \r" .isprintable() Out[17]: False
还有判断是否是数字,这个比较复杂,单独列出
x = "1235" x.isdecimal() Out[19]: True x.isdigit() Out[20]: True x.isnumeric() Out[22]: True x = "2²" x.isdecimal() Out[25]: False x.isdigit() Out[26]: True x.isnumeric() Out[27]: True x="一五" x.isdecimal() Out[29]: False x.isdigit() Out[30]: False x.isnumeric() Out[31]: True
此外还有一个函数isalnum(),只要isalpha(),isdigital(),isnumeric()中的一个返回True,他就会返回True
还有几个和程序有关的
#判断是否可以为变量名 "520Gaoban".isidentifier() Out[32]: False "Gaoban520".isidentifier() Out[33]: True #判断是否是关键字 import keyword keyword.iskeyword("if") Out[35]: True keyword.iskeyword("py") Out[36]: False
将字符串的前缀和后缀进行处理
" 左侧不要留白".lstrip() Out[19]: '左侧不要留白' "右侧不要留白 ".rstrip() Out[21]: '右侧不要留白' " 左右不要留白 ".strip() Out[22]: '左右不要留白' #也可以指明去除的内容,但不能准确去除 "www.Gaobanc.com".strip("wcom.") Out[23]: 'Gaoban' #准确去除的函数: "www.Gaobanc.com".removeprefix("www.") Out[25]: 'Gaobanc.com' "www.Gaobanc.com".removesuffix(".com") Out[26]: 'www.Gaobanc'
对中部的内容进行处理
#分成三部分 "www.Gaobanc.com".partition(".") Out[28]: ('www', '.', 'Gaobanc.com') "www.Gaobanc.com".rpartition(".") Out[29]: ('www.Gaobanc', '.', 'com') #分成几个部分,可以指明切几次 "www.Gaobanc.com".split(".") Out[30]: ['www', 'Gaobanc', 'com'] "www.Gaobanc.com".rsplit(".") Out[31]: ['www', 'Gaobanc', 'com'] "www.Gaobanc.com".rsplit(".",1) Out[32]: ['www.Gaobanc', 'com'] #但对转行符,明显另一个函数更方便 "Gaoban\nHuangqian\nXiuyi".splitlines() Out[37]: ['Gaoban', 'Huangqian', 'Xiuyi'] "Gaoban\n\rHuangqian\n\rXiuyi".splitlines() #这里犯了个错误 Out[38]: ['Gaoban', '', 'Huangqian', '', 'Xiuyi'] "Gaoban\r\nHuangqian\r\nXiuyi".splitlines() Out[39]: ['Gaoban', 'Huangqian', 'Xiuyi']
对字符串进行拼接,可以用“+”,但是join的效率更高
".".join(["www","Gaoban","com"]) Out[43]: 'www.Gaoban.com'
格式化字符串
先给出完整的可选的参数
[[fill]align][sign][#][0][width][grouping_option][precision][type]
大概的使用方法:
#简单的使用 date = 6.11 "meet you on {}".format(date) Out[46]: 'meet you on 6.11' "XiuYi {} Huangqian {}".format("XiaoHao","Euphonium") Out[48]: 'XiuYi XiaoHao Huangqian Euphonium' #通过数字索引 "XiuYi {1} Huangqian {0}".format("XiaoHao","Euphonium") Out[49]: 'XiuYi Euphonium Huangqian XiaoHao' #通过命名索引 "XiuYi {yue} Huangqian {qi}".format(yue="XiaoHao",qi="Euphonium") Out[50]: 'XiuYi XiaoHao Huangqian Euphonium' #通过两者索引 "XiuYi {0} Huangqian {yueqi}".format("XiaoHao",yueqi="Euphonium") Out[51]: 'XiuYi XiaoHao Huangqian Euphonium'
格式化时,还可以设置格式
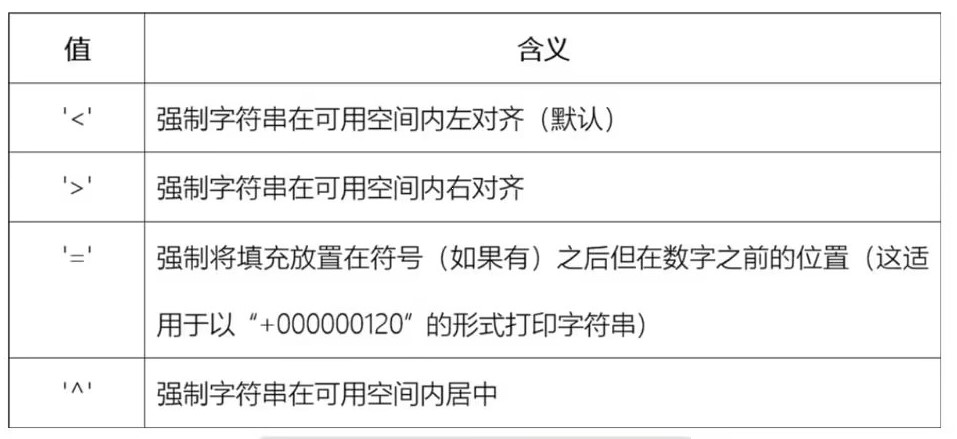
具体的设置格式方法:[[fill]align][width]
#冒号前面表示索引。冒号后面表示索引 "{1:>10}{0:<10}".format(520,250) Out[52]: ' 250520 ' #默认是用空格填充,也可以使用其他的 #选择0填充时 "{:0=10}".format(-76) Out[54]: '-000000076' "{:0^10}".format(-76) Out[55]: '000-760000' #当然也可用其他填充 "{:%^10}".format("Gaoban") Out[56]: '%%Gaoban%%'
此外两个花括号可以有注释的作用,剥夺其format的资格,变成正常的大括号,三个花括号又可以进行format,最外层大括号是注释作用,第二层被注释成大括号,第三层进行索引
"{{0}}".format("hhh") Out[60]: '{0}' "{{{0}}}".format("hhh") Out[61]: '{hhh}'
对于参数:[sign]
“+”,“-”主要是对正数作用,对负数感觉用处不大
"{:+} {:-}".format(520,-520) Out[66]: '+520 -520'
还可以用“,” “_”进行千分位标记
"{:,}".format(123456789) Out[68]: '123,456,789' "{:_}".format(123456789) Out[69]: '123_456_789'
对于参数:[#][precision][type]
设置为‘f’或‘F’的浮点数,则是限定小数点后显示几位,设置为‘g’或‘G’的浮点数,则是限定总共显示几位
设置为%,则是以百分比的形式输出(将数字乘以 100 并显示为定点表示法('f')的形式,后面附带一个百分号
设置为“e”或者“E”,则以科学计数法的形式输出
此外还有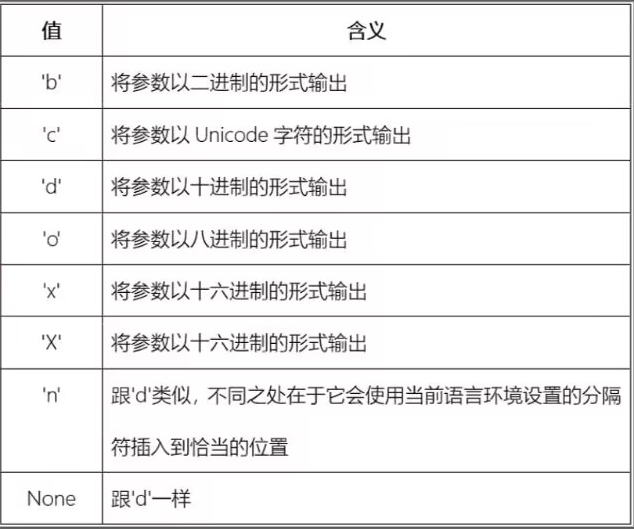
而[#]可以让结果显示出用的什么进制
"{:.2f}".format(3.1415926) Out[71]: '3.14' "{:.2g}".format(3.1415926) Out[72]: '3.1' "{:.6}".format("I love Gaoban") Out[73]: 'I love' #但对整数使用会报错 "{:.2f}".format(3) Out[74]: '3.00' "{:.2}".format(3) Traceback (most recent call last): File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-75-12043d094375>", line 1, in <module> "{:.2}".format(3) ValueError: Precision not allowed in integer format specifier "{:b}".format(80) Out[76]: '1010000' "{:c}".format(80) Out[77]: 'P' "{:d}".format(80) Out[78]: '80' "{:o}".format(80) Out[79]: '120' "{:x}".format(80) Out[80]: '50' "{:#b}".format(80) Out[81]: '0b1010000' "{:#o}".format(80) Out[82]: '0o120' "{:#x}".format(80) Out[83]: '0x50' #默认六位(有的是指小数点后六位,有的是总的六位) "{:E}".format(123456.789) Out[85]: '1.234568E+05' "{:G}".format(123456.789) Out[86]: '123457' "{:F}".format(31.415926) Out[90]: '31.415926' "{:%}".format(0.1415926) Out[91]: '14.159260%'
再来一行基本汇总一下知识点
"{:{fill}{align}{width}.{prec}{ty}}".format(3.1415926,fill = "+",align="^",width=10,prec=3,ty="g") Out[93]: '+++3.14+++'
此外在这一部分内容中,还有一个语法糖f-string
#等价的形式 date=611 "Date: {}".format(date) Out[98]: 'Date: 611' F"Date:{date}" Out[99]: 'Date:611' f"{-520:010}" Out[100]: '-000000520' f"{123456:,}" Out[101]: '123,456' f"{3.1415926:.2f}" Out[102]: '3.14'
再来一行基本汇总一下知识点
f"{3.1415926:{fill}{align}{width}.{prec}{ty}}" Out[108]: '+++3.14+++'
序列
在学完列表、元组、字符串之后,我们来一个总结,其实他们都属于序列,列表为可变序列,而元组和字符串属于不可变序列
在写这一部分笔记时,有一部分与前面重复,就会省去很多
先是讲了“+”和“*” 还有怎么看他们的id(一个变量有三个属性,分别是他们的id,变量类型和值)
然后又复习了is和is not,in 和 not in
其中,id和in,not in之前没有提到,在此处补上
x = [1,2,3] id(x) Out[4]: 2738329027264 "Gaoban" in "Gaoban Linai" Out[5]: True
然后又学了clear和del
x = [1,2,3] y="DENGDENGDENGDENG" del x,y #删除之后报错 x Traceback (most recent call last): File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-9-6fcf9dfbd479>", line 1, in <module> x NameError: name 'x' is not defined y Traceback (most recent call last): File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-10-9063a9f0e032>", line 1, in <module> y NameError: name 'y' is not defined #关于clear x = [1,2,3,4,5] x.clear() x Out[13]: [] #与clear等价的两种其他写法——切片和del x = [1,2,3,4,5] del x[:] x Out[16]: [] x=[1,2,3,4,5] x[:]=[] x Out[19]: []
之后又复习了元组、列表、字符串的互相转换
list("FishC") Out[51]: ['F', 'i', 's', 'h', 'C'] tuple("FishC") Out[52]: ('F', 'i', 's', 'h', 'C') str([0,2,4,1,5]) Out[53]: '[0, 2, 4, 1, 5]'
你可能也注意到列表或元组向字符串的转换,并不如我们想象中那样将各个元素取出来成为字符串,要实现这个可以用我们之前提到过的join,且其中的元素需要是字符串,如果不是可以用列表推导式解决
x=[1,3,52,4] y = [str(each) for each in x] y Out[96]: ['1', '3', '52', '4'] "".join(y) Out[97]: '13524'
之后又讲述了min()和max(),这个比较简单,但是有一个比较有意思的参数,当s是空集时,使用min或者max,程序会报错,这时可以这么操作
#报错 s =[] min(s) Traceback (most recent call last): File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-57-4df232394636>", line 1, in <module> min(s) ValueError: min() arg is an empty sequence #使用参数defalt s=[] min(s,default="这是一个空集") Out[59]: '这是一个空集'
然后还介绍了sum函数
s = [1,3,5,2,4] sum(s) Out[61]: 15 sum(s,start=100) Out[62]: 115
之前的博客中有提到.sort(),sorted(),建议此处和前面结合着看
#.sort()和sorted()的区别 #sorted()不会改变列表,会传回一个新的列表 #而.sort()会改变原列表 s=[2,5,1,6,2] sorted(s) Out[64]: [1, 2, 2, 5, 6] s Out[66]: [2, 5, 1, 6, 2] s.sort() s Out[68]: [1, 2, 2, 5, 6] sorted(s,reverse=True) Out[69]: [6, 5, 2, 2, 1] #sorted()可以对序列进行排序,返回列表 #.sort()只能对列表操作 sorted((56,1,5,12)) Out[70]: [1, 5, 12, 56]
此外.sort()和sorted()
s = ["Gaoban","Xiuyi","Huangqian"] sorted(s,key=len) Out[74]: ['Xiuyi', 'Gaoban', 'Huangqian'] s.sort(key=len) s Out[76]: ['Xiuyi', 'Gaoban', 'Huangqian'] s.sort() s Out[78]: ['Gaoban', 'Huangqian', 'Xiuyi']
还有一个reversed()函数,返回的是一个参数的反向迭代器(这个暂时不用懂),他可以与.reverse()作比较,他们的关系和.sort()和sorted()作类比,高度相似,此处不再列述
s=[2,3,1,5,6,8]
reversed(s) Out[81]: <list_reverseiterator at 0x27d912c0670>
list(reversed(s)) Out[82]: [8, 6, 5, 1, 3, 2]
s.reverse() s Out[84]: [8, 6, 5, 1, 3, 2]
然后在来两个比较简单的all()和any()
x = [1,1,0] y=[1,1,9] all(x) Out[4]: False all(y) Out[6]: True any(x) Out[7]: True any(y) Out[8]: True
关于枚举enumerate()
enumerate(seasons) Out[11]: <enumerate at 0x1cfa536b640> list(enumerate(seasons)) Out[12]: [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] list(enumerate(seasons,10)) Out[16]: [(10, 'Spring'), (11, 'Summer'), (12, 'Fall'), (13, 'Winter')]
关于zip(我感觉可以理解为拉链)
# zip的基本用法 x=[1,2,3] y=[4,5,6] list(zip(x,y)) Out[21]: [(1, 4), (2, 5), (3, 6)] # 当zip里的元素不一样多时,选择最短的元素进行zip z="FishC" list(zip(x,y,z)) Out[23]: [(1, 4, 'F'), (2, 5, 'i'), (3, 6, 's')]
有一个函数可以与zip做对比,它是当元素不一样多时,选择最长的元素进行拼凑
import itertools list(itertools.zip_longest(x,y,z)) Out[26]: [(1, 4, 'F'), (2, 5, 'i'), (3, 6, 's'), (None, None, 'h'), (None, None, 'C')]
zip的作用就是可以进行多对象迭代
#错误 >>> x = [1, 2, 3, 4, 5] >>> y = "FishC" >>> for i, j in x, y: ... print(i, j) ... Traceback (most recent call last): File "<pyshell#26>", line 1, in <module> for i, j in x, y: ValueError: too many values to unpack (expected 2) #正确 >>> for i, j in zip(x, y): ... print(i, j) ... 1 F 2 i 3 s 4 h 5 C
而后是一个map(遍历)
#基本 list(map(ord,"FishC")) Out[28]: [70, 105, 115, 104, 67] #双参数 list(map(pow,[1,3,2],[2,4,3])) Out[29]: [1, 81, 8] #当后面的元素不一样多时,以元素少的那一个为主 list(map(max,[1,3,5],[2,2,2],[0,3,9,8])) Out[30]: [2, 3, 9]
然后是一个filter(过滤器)
list(filter(str.islower,"FishC")) Out[31]: ['i', 's', 'h']
之后引出序列中的主角迭代器和可迭代对象,他们的区别在迭代器只可以迭代一次,可迭代对象可以迭代很多次仍存在
mapped = map(ord,"FishC") for each in mapped: print(each) 70 105 115 104 67 #迭代一次之后,mapped为空 list(mapped) Out[34]: []
可以用list()或tuple()将迭代器变为可迭代对象,也可以用iter()将可迭代对象变为迭代器
iter([1,2,3,4,5])
Out[40]: <list_iterator at 0x1cfa53e66e0>
然后再来演示一个next()
#会报错款 y=iter([1,2,3]) next(y) Out[42]: 1 next(y) Out[43]: 2 next(y) Out[44]: 3 next(y) Traceback (most recent call last): File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-47-81b9d2f0f16a>", line 1, in <module> next(y) StopIteration #不会报错版 y=iter([1,2,3]) next(y,"Good bye") Out[49]: 1 next(y,"Good bye") Out[50]: 2 next(y,"Good bye") Out[51]: 3 next(y,"Good bye") Out[52]: 'Good bye'
字典
先写字典的创建方法,字典的冒号前面的叫键,后面的叫值
#方法一(原始) a = {"yi":"1","er":"2","san":"3"} #方法二(使用函数dict)但键不加引号,值要加引号 b = dict(yi="1",er="2",san="3") c = dict([["yi","1"],["er","2"],["san","3"]]) #方法三(适用函数dict但原始) d = dict({"yi":"1","er":"2","san":"3"}) #方法四 (混合方法二三) e = dict({"yi":"1","er":"2","san":"3"},si="4") #方法五(延伸方法二) f=dict(zip(["yi","er","san"],["1","2","3"]))
快速创建同值的字典
d = dict.fromkeys("Gaoban",520) d Out[14]: {'G': 520, 'a': 520, 'o': 520, 'b': 520, 'n': 520}
字典的调用和增改值
#调用 d['G'] Out[15]: 520 #改值增值 d['a'] = 1314 d['H'] = 521 d Out[18]: {'G': 520, 'a': 1314, 'o': 520, 'b': 520, 'n': 520, 'H': 521}
除去一个值,当除去的值不在时,会报错,同样可以增加一个参数防止报错
d.pop('H') Out[20]: 521 d Out[21]: {'G': 520, 'a': 1314, 'o': 520, 'b': 520, 'n': 520} d.pop("X","没有这个值") Out[22]: '没有这个值' #popitem在新版的python中是默认除去最后一个,但旧版好像是随机的 d.popitem() Out[24]: ('n', 520) d Out[25]: {'G': 520, 'a': 1314, 'o': 520, 'b': 520} #再来一个clear()和del del d["a"] d Out[28]: {'G': 520, 'o': 520, 'b': 520} d.clear() d Out[30]: {} del d d Traceback (most recent call last): File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-32-e983f374794d>", line 1, in <module> d NameError: name 'd' is not defined
补充知识:
{}是字典不是集合
b={} type(b) Out[38]: dict b={"吕布":"口口布"} type(b) Out[40]: dict b={1,2,4} type(b) Out[43]: set
可以用in判断,某个变量是否存在在字典的“键”中
if name in phone_book:
前面虽然已经介绍过字典的索引和增改值,但是不够详细,此处进行详解
先讲增改值,这里主要要在之前的基础上介绍一种批量改值
d=dict.fromkeys("FishC") Out[8]: {'F': None, 'i': None, 's': None, 'h': None, 'C': None} #update()的两种形式 d.update({"i":23,"F":456}) Out[10]: {'F': 456, 'i': 23, 's': None, 'h': None, 'C': None} d.update(s=24,h=654) Out[12]: {'F': 456, 'i': 23, 's': 24, 'h': 654, 'C': None} #增值 d.update(u=34) Out[14]: {'F': 456, 'i': 23, 's': 24, 'h': 654, 'C': None, 'u': 34}
字典的索引可以用键索引,但是当字典内没有这个键时,程序就会报错,此时可以调用函数.get(),在里面可以有更多的参数,可以在没这个键的时候print一句字符串
也可以用.setdefault(),当字典内没有这个值,将其设置为一个里面的一个参数的值
d.get('d',"没有此键") Out[15]: '没有此键' d.setdefault('c',96) Out[16]: 96 d.setdefault('C',96) #此处因为‘C’是None,所以没有返回任何值 d Out[18]: {'F': 456, 'i': 23, 's': 24, 'h': 654, 'C': None, 'u': 34, 'c': 96}
另外介绍了三个函数,这三个函数返回的值,与原字典息息相关,当之后原字典发生改变时,它们也会改变,而.copy()则不会,但在更深一层的嵌套中则会改变
#原本 d Out[18]: {'F': 456, 'i': 23, 's': 24, 'h': 654, 'C': None, 'u': 34, 'c': 96} keys = d.keys() values = d.values() items = d.items() keys Out[22]: dict_keys(['F', 'i', 's', 'h', 'C', 'u', 'c']) values Out[23]: dict_values([456, 23, 24, 654, None, 34, 96]) items Out[24]: dict_items([('F', 456), ('i', 23), ('s', 24), ('h', 654), ('C', None), ('u', 34), ('c', 96)]) e = d.copy() #原字典改变 d.pop("F") Out[26]: 456 #结果 e Out[27]: {'F': 456, 'i': 23, 's': 24, 'h': 654, 'C': None, 'u': 34, 'c': 96} d Out[28]: {'i': 23, 's': 24, 'h': 654, 'C': None, 'u': 34, 'c': 96} keys Out[29]: dict_keys(['i', 's', 'h', 'C', 'u', 'c']) values Out[30]: dict_values([23, 24, 654, None, 34, 96]) items Out[31]: dict_items([('i', 23), ('s', 24), ('h', 654), ('C', None), ('u', 34), ('c', 96)])
>>> d = {"小甲鱼":{"千年王八":"万年龟"}}
>>> e = d.copy()
>>> d["小甲鱼"]["千年王八"] = "666"
>>> e
{'小甲鱼': {'千年王八': '666'}}
字典也可以转换为列表,也可以转换为迭代器iter()
list(d) Out[37]: ['i', 's', 'h', 'C', 'u', 'c'] list(d.values()) Out[38]: [23, 24, 654, None, 34, 96]
之后再介绍一下字典的嵌套
#字典与字典之间的嵌套和索引 d = {"吕布":{"语文":60,"数学":70,"英语":80},"关羽":{"语文":80,"数学":90,"英语":70}} d["吕布"]["语文"] Out[40]: 60 #字典和数列之间的嵌套 d={"吕布":[60,70,80],"关羽":[80,90,100]} d["吕布"][1] Out[42]: 70 #字典推导式 d = {'F':70,'i':50,'s':24,'h':2,'C':34} b = {v:k for k,v in d.items()} b Out[45]: {70: 'F', 50: 'i', 24: 's', 2: 'h', 34: 'C'} d = {x:ord(x) for x in "FishC"} d Out[47]: {'F': 70, 'i': 105, 's': 115, 'h': 104, 'C': 67} #字典的键是唯一的 d = {x:y for x in [1,3,5] for y in [2,4,6]} d Out[49]: {1: 6, 3: 6, 5: 6}
集合
集合里的元素是无序的,用数字索引会报错
s = {each for each in "FishC"}
s
Out[4]: {'C', 'F', 'h', 'i', 's'}
set("FishC")
Out[5]: {'C', 'F', 'h', 'i', 's'}
判断某元素是否在集合中,但判断子集不是特别好用,而要用函数判断,或运算符
"C" in s Out[6]: True
>>> set("FishC") in set("FishC.com.cn")
False
>>> set("FishC").issubset(set("FishC.com.cn"))
True
>>> set("FishC") < set("FishC.com.cn")
True
>>> set("FishC") <= set("FishC.com.cn")
True
集合里的元素是唯一的,可以用于判断列表等序列中是否用重复元素
s=[1,2,3,2,4] len(s)==len(set(s)) Out[8]: False
还可以用一下函数判断某个集合是否是另一个集合或序列的子集或超集,或者是否有交集
s = set("FishC") #是否有交集 s.isdisjoint("Python") Out[13]: False s.isdisjoint("JAVA") Out[14]: True #是否是子集或超集 s.issubset("Fish.comC") Out[16]: True s.issuperset("Fsh") Out[17]: True
还可以进行并集交集的函数
#并集 s.union({1,2,3}) Out[18]: {1, 2, 3, 'C', 'F', 'h', 'i', 's'} s.union({1,2,3},"Gaoban") Out[21]: {1, 2, 3, 'C', 'F', 'G', 'a', 'b', 'h', 'i', 'n', 'o', 's'} #交集 s.intersection("FishB") Out[19]: {'F', 'h', 'i', 's'} s.intersection("FishB","Python") Out[22]: {'h'} #与参数中不一样的元素(单向) s.difference("FishB") Out[20]: {'C'} s.difference("FishB","python") Out[24]: {'C'} #与参数中不一样的元素(双向) s.symmetric_difference("FishB") Out[25]: {'B', 'C'}
还支持运算符,但不同于函数,运算符两端都得是集合,而函数中集合和序列都行
s = set("FishC") s <= set("FishC.com") Out[27]: True s >= set("Fsh") Out[28]: True #并集 s|{1,2,3}|{"Fish"} Out[29]: {1, 2, 3, 'C', 'F', 'Fish', 'h', 'i', 's'} #交集 s&set("php")&set("python") Out[30]: {'h'} #相减 s-set("Php") Out[32]: {'C', 'F', 'i', 's'} #并集-交集 s^set("FishB") Out[34]: {'B', 'C'}
再来介绍更改列表的方法
s Out[36]: {'C', 'F', 'h', 'i', 's'} #并集更新 s.update(".com","php") s Out[38]: {'.', 'C', 'F', 'c', 'h', 'i', 'm', 'o', 'p', 's'} #交集更新 s.intersection_update("FishB") s Out[40]: {'F', 'h', 'i', 's'} #单向不同更新 s.difference_update("FiB") s Out[42]: {'h', 's'} #双向不同更新 s.symmetric_difference_update("sb") s Out[44]: {'b', 'h'} #注意与.update()的区别 s.add("Gaoban") s Out[46]: {'Gaoban', 'b', 'h'} #移除,只是对remove()而言,当移除不存在的元素时会报错,而当.discard()移除不存在的元素时会静默处理 s.remove("b") s Out[48]: {'Gaoban', 'h'} s.discard("h") s Out[50]: {'Gaoban'} #随机移除一个元素 s.pop() Out[51]: 'Gaoban' #清空 s.clear() s Out[53]: set() #{}是字典,而要创建空集合,需要set()
对于集合而言,他里面的值需要是可哈希的,不可变的,对于不可变的元素,他都有一个哈希值
hash(1) Out[54]: 1 hash(1.0) Out[55]: 1 hash(1.001) Out[56]: 2305843009213441 hash("Gaoban")
Out[57]: -1310668480371891955 hash((1,4,2)) Out[60]: -6883017376499719401
而对于可变的元素他就没有哈希值,获取哈希值会报错
hash({1,2,3})
Traceback (most recent call last):
File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-61-d5ba4eb1a90a>", line 1, in <module>
hash({1,2,3})
TypeError: unhashable type: 'set'
hash([1,4,2])
Traceback (most recent call last):
File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3460, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-62-0534f82e4375>", line 1, in <module>
hash([1,4,2])
TypeError: unhashable type: 'list'
由于集合不可哈希,这就会导致集合不可嵌套,所以引入了不可变集合
x = {1,2,3}
y ={x,4,5}
y
Out[69]: {4, 5, frozenset({1, 2, 3})}
加密
由于小甲鱼的作业老涉及这块内容,为便于翻阅,在此处记录
>>> import hashlib >>> result = hashlib.md5(b"FishC") >>> print(result.hexdigest()) 9d22182e926ca703cd0f5926e7d57782 #hashlib.md5() 的参数是需要一个 b 字符串(即 bytes 类型的对象),这里可以使用 bytes("123", "utf-8") 的方式将 "123" 转换为 b"123" bstr = bytes(passwd, "utf-8") passwd = hashlib.md5(bstr)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号