
java多线程高并发学习从零开始——初识volatile关键字
java多线程高并发学习从零开始——初识volatile关键字
刚接触java 的高并发编程的时候,基本就会听说到volatile关键字,这个平时都不经常用到的关键字到底是有什么含义,都有什么性质呢?借着这个博客,本人写一下总结和一些自己的想法,如果有任何错误,欢迎指正。
什么是JMM(Java memory model)?
JMM是java内存模型,运用缓存一致性协议完成java线程间以及和主内存间的通信。
这里需要知道java线程在运行的时候设计到的内存空间包括:
- 主内存——记录操作的变量的值,是整个系统中都在此内存中获取该变量值
- 工作内存——可以简单理解为,不同线程都有自己的操作空间,想要对主内存中的某个变量进行操作的时候,先将该变量值获取到本线程的工作内存中,线程只能对自己的工作内存中的数据变量进行操作
- 总线——可以理解为系统内部数据传输的总通道
什么是原子操作?
java的线程操作主内存中的某个变量都包括哪些原子操作?这些操作都拥有什么含义呢?
Read(读取):从主内存中读取数据;
Load(载入):将主内存中读取的数据写入工作内存中;
Use(使用):将工作内存中的数据用来计算;
Assign(赋值):将计算好的值重新赋值到工作内存中;
Store(存储):将工作内存中的数据写入到主内存中;
Write(写入):将store的变量值重新赋值给主内存中的变量;
Lock(锁定):将主内存变量加锁,标识为线程独占状态;
Unlock(解锁):将主内存变量解锁,解锁后其他线程可以锁定改变量;
有了上述的基本知识,可以开始绘制大概的线程变量通信的过程,如下:
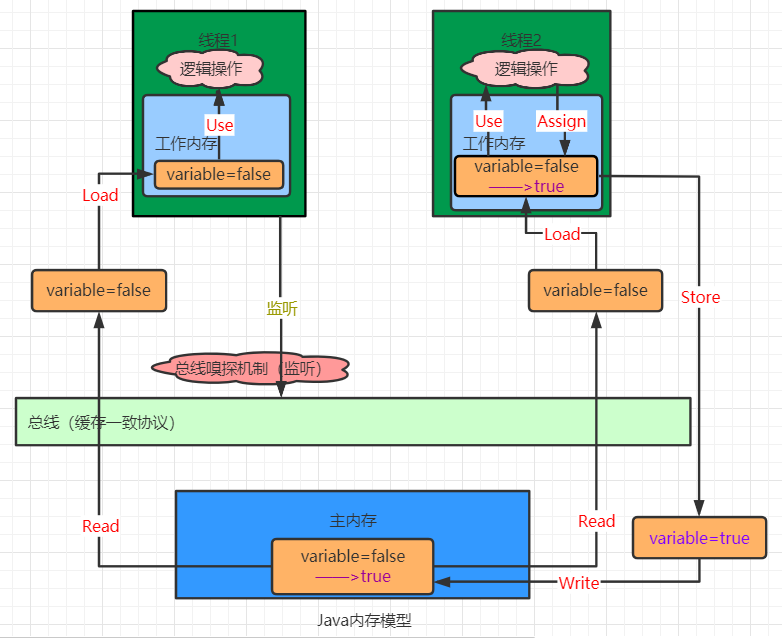
正是由于这个内存模型,我们能够发现一个问题,如果多个线程同时都对主内存中的某个变量 variable 进行操作的话,可能会出现后返回的线程会覆盖掉先操作的值,导致所求结果并非是我们预期的值。
下面通过代码直观感受下:
1 package com.shine; 2 3 public class TestClass { 4 private static int variable = 0; 5 6 /** 7 * @Author: Shine EtherealWind 8 * @Description: 举大事,必慎其终始 9 * @Date: create in 10:35 2021/6/7 10 * @Param: 11 */ 12 public static void main(String[] args) { 13 14 Thread thread1 = new Thread(()->{ 15 while (variable < 10 ){ 16 System.out.println("线程"+Thread.currentThread().getName() +",当前variable的值"+ (variable++)); 17 try { 18 Thread.sleep(100); 19 } catch (InterruptedException e) { 20 e.printStackTrace(); 21 } 22 } 23 }, "thread1"); 24 25 Thread thread2 = new Thread("thread2"){ 26 @Override 27 public void run() { 28 while (variable < 10){ 29 System.out.println("线程"+Thread.currentThread().getName() +",当前variable的值"+ (variable++)); 30 try { 31 Thread.sleep(100); 32 } catch (InterruptedException e) { 33 e.printStackTrace(); 34 } 35 } 36 } 37 }; 38 39 thread1.start(); 40 thread2.start(); 41 } 42 }
运行结果如下图:
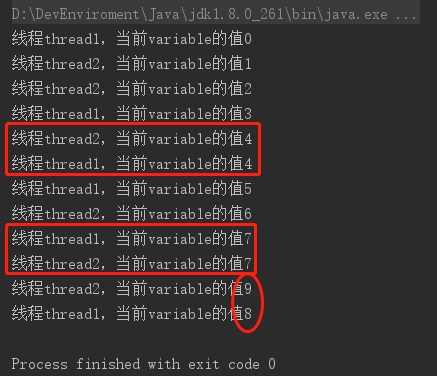
分析结果可以看出有三处是跟预期相悖的,那是为什么呢?
1. 是因为这里有两个线程“thread1” 和 “thread2” 当主内存中的variable值是 4 的时候,两个线程中的一个先从主内存中Load(载入) variable=4到该线程的工作内存中,进行加一操作。注意此时刻 variable 仅仅是在线程的工作内存中将值计算得到5了,但是如果恰在这个时间段之前,另外的线程也开始从主内存中Loadvariable的值,此时是4。然后在这个线程的工作内存中对variable = 4进行处理。就这样得到了两个线程处理后的variable值都是5了,打印出来的结果也就不是期望的顺序增加。
2. 同理等于7也是一样的情况。
3. 那么为什么会出现9和8输出顺序反了呢?这是由于cpu采用时间片轮转调度算法导致的,通俗的说,就是当线程1执行到输出语句的前一步,时间片用完了,接着是线程2的时间片执行时间。在线程2的时间片内,完成了它自己的所有工作。等线程1的下一次时间片获得,继续执行先前没有完成的工作,进行输出。
并发编程的三个特性
分别是原子性,可见性,有序性
原子性:线程执行的操作无论多少,每个操作都应当遵从 操作要么完全执行,执行过程中不会被打断;要么就不执行;
可见性:当有多个线程同时访问主内存中的共享数据变量时,只要有一个线程对该变量进行了操作,导致数据改变,其他线程都立马能看见修改的内容;
有序性:jvm在执行程序的时候,有时候并非按照代码的顺序一步步执行的,它会在不影响单线程执行结果的前提下,为了最大限度的发挥机器性能,对机器指令进行重排优化。(可以参见下面描述的 “指令重排” 部分)
缓存一致性协议MESI modify exclusive share invalid
多个线程从主存读取一个数据到高速缓存,当其中某个线程修改了缓存里的数据,该数据会马上同步回主内存,其他线程会通过 “总线嗅探机制” 可以感知到数据的变化从而将自己缓存里的数据失效,然后重新从主存开始取数据。 实现了线程对数据操作的可见性。
指令重排
在不影响单线程程序执行结果的前提下,计算机为了最大限度的发挥机器性能,会对机器指令进行重排优化。
源代码—> 1:编译器优化重排序—>2:指令级并行重排序—>内存系统重排序—>最终执行的指令序列
注意:是计算机在不影响单线程的程序执行结果的前提下,才会主动进行指令重排。
重排序会遵循as-if-serial 与 happens-before
(1)as-if-serial:不管怎么重排,单线程程序的执行结果不能被改变
因此编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会影响结果.
(2)happens-before:
- 程序顺序原则 在一个线程内必须保证语义串行性,也即按照代码顺序执行;
- 锁规则 解锁操作必然发生在后续的同一个锁的枷加锁之前,也就是说,如果对于一个锁解锁后,再加锁,那么加锁的动作必须在解锁动作之后(同一个锁)
- volatile规则 volatile变量的写先发生于读,这保证了volatile变量的可见性,简单地说,volatile变量在每次被线程访问时候,都强迫从主内存中读该变量的值,而当该变量发生变化时,又会强迫将最新的值刷新到主内存,任何时刻,不同线程总是能看见该变量的最新值。
- 线程启动规则 线程的start()方法先于他的每一个动作,即线程A在执行线程B的start方法之前修改了共享变量的值,那么当线程B执行start方发时,线程A对共享变量的修改对线程B可见
- 传递性 A先于B B先于C,那么A必然先于C
- 线程终止原则 线程所有操作先于线程终结,thread.join()方法的作用是等待当前执行的线程终止,假设在线程B终止之前,修改了共享变量,线程A从线程B的join方法成功返回后,线程B对共享变量的修改将对线程A可见。
- 线程中断规则 对线程interrupt()方法的调用先行于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测线程是否中断。
- 对象终结规则 对象的构造函数执行结束先于finalize()方法。
引申:
阿里面试题:双重检测锁DCL对象半初始化问题
在底层实现的时候,一定需要增加volatile,底层会因此增加内存屏障保证
内存屏障
在不希望可能被重排的两行代码之间增加一行代码,使其不能发生重排
JVM规范定义的内存屏障有下列表格中的:
|
屏障类型 |
指令示例 |
说明 |
|
LoadLoad |
Load1; LoadLoad; Load2; |
保证load1的读取操作在load2及后续操作之前执行。 |
|
StoreStore |
Store1; StoreStore; Store2; |
在store2及其后的写操作执行前,保证store1的写操作已经刷新到主内存。 |
|
LoadStore |
Load1; LoadStore; Store2; |
在store2及其后的写操作执行前,保证load1的读操作已经读取结束。 |
|
StoreLoad |
Store1; StoreLoad; Load2; |
保证store1的写操作已经刷新到主内存之后,load2及其后的读操作才能执行。 |
当然这些屏障不需要开发人员们主动去设置,而是jvm通过对代码分析过后自动补充上的。
volatile 关键字具体有什么用处
接下来我们来详细了解下volatile这个关键字的具体用处吧!
volatile在Java并发编程中常用于保持内存 可见性 和 有序性 ,volatile关键字在读写操作的前后都会分别插入内存屏障
使用volatile变量JVM能够保证:
- 每次
读操作前都必须先从主内存刷新最新的值 - 每次
写操作后必须立即同步回主内存当中
以此保证操作的可见性。
JVM对volatile变量的前后添加了内存屏障操作:
a=2; //volatile写,a为volatile变量 --StoreStore屏障 a=1; //volatile写 b=a; //volatile读 --LoadLoad屏障 --LoadStore屏障
以此保证了操作的有序性。
总结
注意volatile关键字并不能保证线程操作的原子性,所以两个线程同时对一个变量做更新操作的时候还是会有数据共享安全问题,需要配合 锁 才可以完全保证数据安全问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号