设计模式学习笔记(二十二)解释器模式及其实现
解释器模式(Interpreter Design Pattern)指给定一个“语言”,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。这里所指的“语言”是指使用规定格式和语法的代码。
比如说在计算器中,我们输入一个加法/减法表达式(中缀表达式)“1+6-5”字符串,就能在计算器中输出结果2。而我们知道,一般的程序语言像C++、Java和Python无法直接解释这个字符串,那么就必须定义规定格式和语法的解释器,来对这个字符串表达式进行解释成程序语言能计算的方式(后缀表达式),最后再进行输出。也就是中缀表达式转换成后缀表达式。
那么在着这个转换中就需要满足这样的语法:
首先 依次 遍历中缀表达式,
如果是数字 直接输出
如果是符号:
左括号, 直接进栈
运算符, 与栈顶元素 进行比较如果 栈顶元素 优先级较低, 直接入栈即可。
如果栈顶元素 优先级较高,将栈顶元素 弹出 并输出。 之后进栈即可。
右括号, 将栈中的元素依次弹出 直到遇到左括号。
遍历结束后,如果栈中还有元素依次弹出并输出 即可。
一、解释器模式介绍
在介绍解释器模式的结构前,先来了解两个概念文法规则和抽象语法树
1.1 文法和抽象语法树
1.1.1 文法
文法也就是用于描述语言的语法结构,比如对于上面提到的表达式“1+6-5”,可以使用一下文法规则来定义:
# 表达式的组成方式,value和operation是两个语言构造成分或语言单位
expression :: = value | operation
# 非终结表达式,操作符的种类这里定义两种’+‘和’-‘
operation :: = expression '+' expression | expression '-' expression
# 终结表达式,组成元素是最基本的语言单位,这里指像1、6等的整数值
value :: = an integer
- 符号
expression是表达式的组成方式,其中value和operation是后面两个语言单位的定义 - 符号
::=是定义为的意思 - 语言单位分为终结符表达式和非终结表达式,
value是终结符表达式不可再分,operation是非终结符表达式,可以再分
1.1.2 抽象语法树
除了使用文法规则来定义语言外,在解释器模式中还可以通过抽象语法树(Abstract Syntax Tree, AST)图形的方式来直观地表示语言构成,比如“1+6-5”可以用语法树表达为:
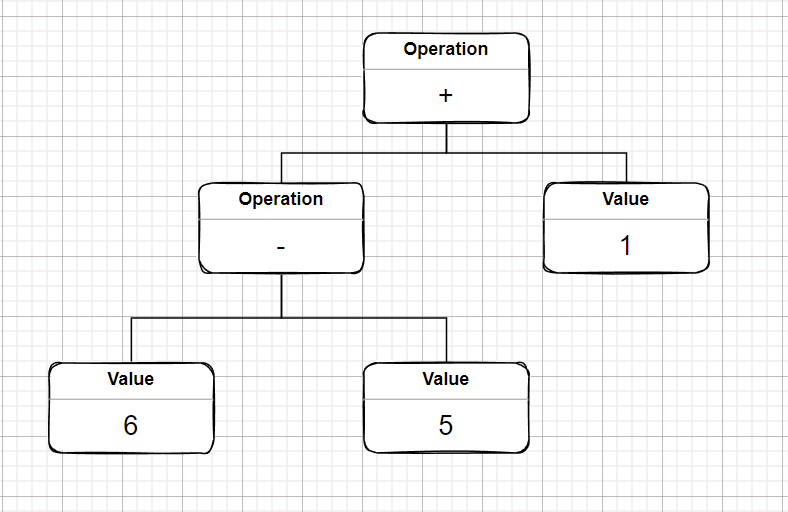
1.2 解释器模式的结构
从上面的文法规则可以知道,表达式可分为终结符表达式和非终结符表达式,因此解释器模式的结构与组合模式的结构类似,它的结构类图如下所示:

AbstractExpression:抽象表达式,声明抽象的解释操作,终结符表达式和非终结符表达式的公共接口TerminalExpression:终结符表达式,实现抽象表达式以及相关的解释操作NonterminalExpression:非终结符表达式,实现抽象表达式的相关解释操作。其中既可以包含终结符表达式,也可以包含非终结符表达式Context:上下文类,用于存储解释器外的一些全局信息Client:客户端
1.3 解释器模式的实现
根据上面的类图,首先来看一下终结符表达式和非终结符表达式的公共接口抽象表达式
public interface AbstractExpression {
void interpret(Context ctx);
}
接下来是终结符表达式和非终结符表达式类
public class TerminalExpression implements AbstractExpression{
@Override
public void interpret(Context context) {
System.out.println("对终结符表达式进行处理");
}
}
public class NonterminalExpression implements AbstractExpression{
private AbstractExpression left;
private AbstractExpression right;
public NonterminalExpression(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
@Override
public void interpret(Context context) {
System.out.println("非终结符表达式进行处理中~");
//递归调用每一个组成部分的 interpret()方法
}
}
最后是上下文类(Context):
public class Context {
private Map<String, String> contextMap = new HashMap<String, String>();
public void assign(String key, String value) {
//向上下文Map中设置值
contextMap.put(key, value);
}
public String lookup(String key) {
return contextMap.get(key);
}
}
二、解释器模式应用场景
在下列的情况可以考虑使用解释器模式:
- 可以将一个需要解释执行的语言中的句子表示为一颗抽象语法树
- 一些重复出现的问题可以用一种简单的语言进行表达
- 一个语言的文法较为简单,对于负责的文法,解释器模式中的文法类层次结构将变得很庞大而无法管理,此时最好的方式是使用语法分析程序生成器
三、解释器模式实战
本案例中模拟监控业务系统的运行情况,及时将异常报告发送给开发者,比如,如果每分钟接口出错数超过100,监控系统就通过短信、微信、邮件等方式发送告警给开发者。(案例来源于《设计模式之美》)
首先设置一个告警规则:每分钟API总错数超过100或者每分钟API总调用数超过10000就触发告警
api_error_per_minute > 100 || api_count_per_minute > 10000
我们定义告警的判断规则有五种:||、&&、<、>、==,其中<、>、==运算符的优先级高于||和&&。
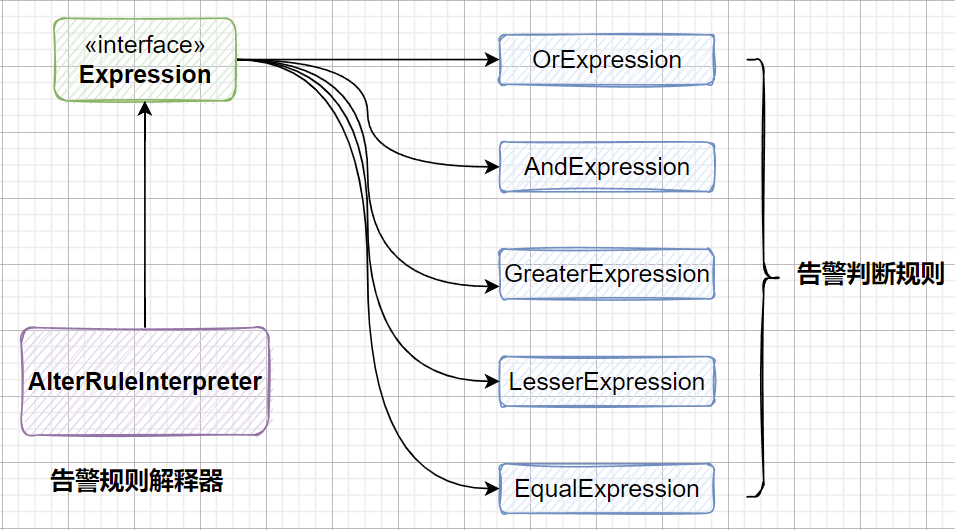
代码的结构如下:
src
├─main
│ ├─java
│ │ AlertRuleInterpreter.java
│ │
│ └─expression
│ │ Expression.java
│ │
│ └─impl
│ AndExpression.java
│ EqualExpression.java
│ GreaterExpression.java
│ LesserExpression.java
│ OrExpression.java
│
└─test
└─java
ApiTest.java
具体代码
- 抽象告警规则接口
public interface Expression {
boolean interpret(Map<String, Long> stats);
}
- 具体告警规则实现
分别有||、&&、<、>、==五种运算符判断规则
public class OrExpression implements Expression {
private List<Expression> expressions = new ArrayList<>();
public OrExpression(List<Expression> expressions) {
this.expressions.addAll(expressions);
}
public OrExpression(String strOrExpression) {
String[] andExpressions = strOrExpression.split("\\|\\|");
for (String andExpression : andExpressions) {
expressions.add(new AndExpression(andExpression));
}
}
@Override
public boolean interpret(Map<String, Long> stats) {
for (Expression expression : expressions) {
if (expression.interpret(stats)) {
return true;
}
}
return false;
}
}
public class AndExpression implements Expression {
private List<Expression> expressions = new ArrayList<>();
public AndExpression(List<Expression> expressions) {
this.expressions.addAll(expressions);
}
public AndExpression(String strAndExpression) {
String[] strExpressions = strAndExpression.split("&&");
for (String strExpression : strExpressions) {
if (strExpression.contains(">")) {
expressions.add(new GreaterExpression(strExpression));
} else if (strExpression.contains("<")) {
expressions.add(new LesserExpression(strExpression));
} else if (strAndExpression.contains("==")) {
expressions.add(new EqualExpression(strExpression));
} else {
throw new RuntimeException("Expression is invalid: " + strAndExpression);
}
}
}
@Override
public boolean interpret(Map<String, Long> stats) {
for (Expression expression : expressions) {
if (!expression.interpret(stats)) {
return false;
}
}
return true;
}
}
public class EqualExpression implements Expression {
private String key;
private Long value;
public EqualExpression(String key, Long value) {
this.key = key;
this.value = value;
}
public EqualExpression(String strExpression) {
String[] elements = strExpression.trim().split("\\s+");
if (elements.length != 3 || !elements[1].trim().equals("==")) {
throw new RuntimeException("Expression is invalid: " + strExpression);
}
this.key = elements[0].trim();
this.value = Long.parseLong(elements[2].trim());
}
@Override
public boolean interpret(Map<String, Long> stats) {
if (!stats.containsKey(key)) {
return false;
}
Long statsValue = stats.get(key);
return statsValue == value;
}
}
public class GreaterExpression implements Expression {
private String key;
private long value;
public GreaterExpression(String key, long value) {
this.key = key;
this.value = value;
}
public GreaterExpression(String strExpression) {
String[] elements = strExpression.trim().split("\\s+");
if (elements.length != 3 || !elements[1].trim().equals(">")) {
throw new RuntimeException("Expression is invalid: " + strExpression);
}
this.key = elements[0].trim();
this.value = Long.parseLong(elements[2].trim());
}
@Override
public boolean interpret(Map<String, Long> stats) {
if (!stats.containsKey(key)) {
return false;
}
Long statValue = stats.get(key);
return statValue > value;
}
}
public class LesserExpression implements Expression {
private String key;
private long value;
public LesserExpression(String key, long value) {
this.key = key;
this.value = value;
}
public LesserExpression(String strExpression) {
String[] elements = strExpression.trim().split("\\s+");
if (elements.length != 3 || !elements[1].trim().equals("<")) {
throw new RuntimeException("Expression is invalid: " + strExpression);
}
this.key = elements[0].trim();
this.value = Long.parseLong(elements[2].trim());
}
@Override
public boolean interpret(Map<String, Long> stats) {
if (!stats.containsKey(key)) {
return false;
}
Long statsValue = stats.get(key);
return statsValue < value;
}
}
- 告警规则解释器
负责解释并实现告警规则
public class AlertRuleInterpreter {
private Expression expression;
public AlertRuleInterpreter(String ruleExpression) {
this.expression = new OrExpression(ruleExpression);
}
public boolean interpret(Map<String, Long> stats) {
return expression.interpret(stats);
}
}
- 测试类及结果
public class ApiTest {
private Logger logger = LoggerFactory.getLogger(ApiTest.class);
@Test
public void test() {
String rule = "api_error_per_minute > 100 || api_count_per_minute > 10000";
AlertRuleInterpreter alertRuleInterpreter = new AlertRuleInterpreter(rule);
HashMap<String, Long> statsMap = new HashMap<>();
statsMap.put("api_error_per_minute", 99l);
statsMap.put("api_count_per_minute", 121l);
boolean alertInterpret = alertRuleInterpreter.interpret(statsMap);
String alert = alertInterpret == true ? "超过阈值,危险!!" : "目前运行良好";
logger.info("预警结果为:alert:{}", alert);
}
}
最后的测试结果为:
16:18:14.525 [main] INFO ApiTest - 预警结果为:alert:目前运行良好
参考资料
《设计模式之美》
《Java设计模式》
《设计模式》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号