
模拟赛总结
- 2024.9.22 PYYZOJ
- 2024.9.24 33dai
- 2024.9.25 线下
- 2024.9.26 33dai
- 2024.9.28 代码源
- 2024.10.4 PYYZOJ
- 2024.10.5 代码源
- 2024.10.6 PYYZOJ
- 2024.10.9 33dai
- 2024.10.11 33dai
- 2024.10.12 代码源
- 2024.10.13 核桃OJ
- 2024.10.14 33dai
- 2024.10.16 PYYZOJ
- 2024.10.18 33dai
- 2024.10.19 代码源
- 2024.10.21 33dai
- 2024.10.22 PYYZOJ
- 2024.10.24 PYYZOJ
- 2024.10.29 PYYZOJ
- 2024.10.30 PYYZOJ
- 2024.11.01 核桃OJ
- 2024.11.02 代码源
- 2024.11.04 PYYZOJ
- 2024.11.05 核桃OJ
- 2024.11.06 33dai
- 2024.11.08 33dai
- 2024.11.09 代码源
- 2024.11.12 代码源
- 2024.11.13 33dai
- 2024.11.14 代码源
- 2024.11.16 代码源
- 2024.11.19 代码源
- 2024.11.20 33dai
- 2024.11.21 代码源
- 2024.11.23 代码源
NOIP模拟赛
2024.9.22 PYYZOJ
正因为没有翅膀,人们才会寻找飞翔的方法。
——《排球少年》
T1 挺基础的,但是感觉自己也没有多么十拿九稳?题解写了个单调队列优化,自己可能对这个不太熟练,直接码了个线段树😐,这题用单调队列优化写的快,跑的还快。
发现可以预处理出以
每层转移区间覆盖,单点修改,全局查询。
T2 考场上写了个并查集,但是最后才发现假了,像RZ一样,稍微动动脑子的就很难写对。
并查集太玄妙了,至今不太懂,写个线段树做法的。
根据题意,发现结构是森林,每次向一棵树上连一个子树,子树里活着的如果想继续活着,有
要是加入新的子树时,
T3 直接大力写了
考虑第一次出现的数才会产生贡献,修改直接改第一次出现的数就可以了。
设当前这个数的下标为
改成
答案会减少 。 改为
答案会减少 。
可以进一步对式子化简,
T4 比赛的时候,题都没时间看,这题感觉看了也不太能做的样子,需要观察总结性质。
旋转本质上是方向和模
2024.9.24 33dai
真正重要的东西,总是没有的人比拥有的人清楚。
——《银魂》
T1 贪心太难了,根本不是我这种不爱动脑子的人做的,虽然差点就贪对了😅。
每个人是可以来回
T2 这题纯纯的构思,树形
T3 比赛的时候差点就做出来了,但是自己却把自己的想法否决了,也没仔细想想,凭直觉觉得自己的正解想法不对。
或和与直接在
T4 hard
考虑一个数会被贡献多少次,顺便更改一下分割点的定义,我们把第
其实可以再把贡献拆一下,对于第
这两个式子作和:
我们把含
把组合数拆开进一步化简:
直接算就可以了,时间复杂度
2024.9.25
T1
T2
T3 这题做法太巧妙了,感觉自己能想到,但是却没想到。
从
考虑对这个新序列分块,然后分类讨论。
修改的散块
直接暴力扫修改的散块修改了哪些数,然后对询问暴力加就行。
修改的散块
预处理
表示第 个块与前 个位置的贡献,那么询问的时候枚举块 就能得到贡献。
修改的整块
修改的整块
T4
2024.9.26 33dai
T1 硬控我两个小时,打比赛脑子是不转的。
需要将交换这项操作的实质看出来,其实就是对
T2 每次取的
这样就可以 区间
T3 状压
这题就是求让整个图强连通的最小代价。设
T4 最不适合我这种
发现
考虑优化。贡献式子长这样
2024.9.28 代码源
T1 秒了😊
换根
为了严谨,式子写的史了一点😅
T2 秒了😊
算出每个点可以贡献的区间,对于相同两个数,可以在处理左端点的时候可以相等,右端点时必须严格小于即可。树状数组、笛卡尔树都可以做。
二分找第
T3 做不出来一点,不过这种题必须得会,今天写下来希望下次见了能做出来。
考虑容斥。
T4 仔细思考什么时候一个人能活下来,感觉也不是很难。
考虑剪刀,前面和后面都得清空,什么时候会清空呢?
其实只有三种情况:
1.开头是布
2.结尾是布
3.出现
石头 布 石头 的结构
布和石头是类似的,于是这题就做完了。
2024.10.4 PYYZOJ
T1 现在是 2024年10月9日,我已经忘了当时的心境了,不过看
设
T2 场切,开心😋
先分讨,得到暴力,然后再分讨,得到正解。
T3 牛魔的,三个子树的启发式合并就不会了是吧🤬。
先考虑两个点。求模
这题也可以这么做,先把较大的子树里的所有距离放序列里,排完序后,枚举另外两个子树里的距离,加起来再在序列里二分,这样就可以更新这两个子树的点了。然后反过来枚举两个较小子树的点,把距离加到序列里,然后再枚举较大子树的点,再在序列里二分,更新较大子树的点的答案。
T4 还没补😭。
2024.10.5 代码源
T1
T2 最伤心的一集,明明已经想到很多了,要是当时头脑清醒一点就好了。
直接钦定
设
T3 这种题直接做是很难做的,需要先把题面翻译一下。这题实质上是说,第一个序列选前
还是没太有清晰的思路,冷静思考一下,发现其实有几个数需要分配是可以算出来的,设
考虑进一步优化,我们从
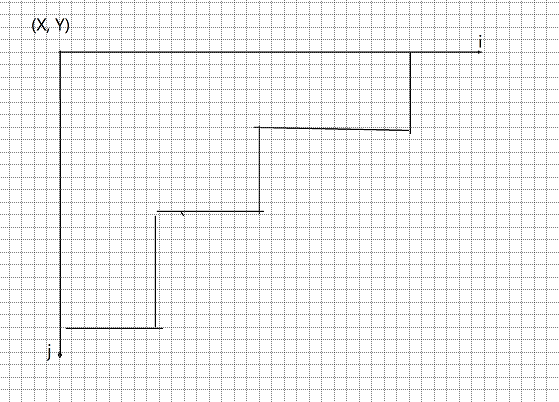
用双指针处理一下,然后类似路径计数的求就行了,需要注意的是已经碰到轮廓线就不能再走了,若以有时能走的步数要少一步。
T4 这题有点神奇。
加入一条边
分别算
枚举一个
2024.10.6 PYYZOJ
T1 不好好看样例,自己瞎几把分类讨论导致的。
打表看样例得,隔一行然后一行全零或隔一列然后一列全零。
先考虑隔一行然后一行全零的情况,判断每一行是哪种类型即可,要么全零,要么
隔一列然后一列全零的同理。
T2 数的种类数不会超过
转移挺神奇的,感觉这种转移的
T3
T4
2024.10.9 33dai
T1 被卡常卡成 20 了,曹操🤬。
从每个根据地开始
如果走到一个之前走到过的点,就把两个
T2 用
T3 考虑从前
T4
这题就是个杨表,可以用勾长公式直接求解:
不想解释了,贴个图举个例子就明白了。
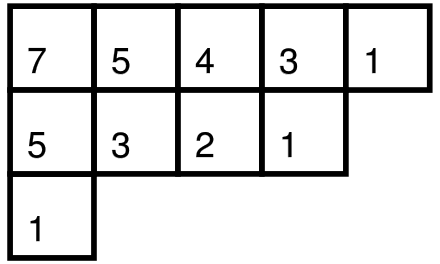
这张图的格子里的数就是这个格子的勾长,对于这个图的方案就是
2024.10.11 33dai
T1 考虑什么时候
T2 根号分治,分治真是充满了人类智慧🤯。
首先第
我们考虑二分的那个第
那小于呢?小于是不是意味着
T3
T4
2024.10.12 代码源
T1
我们发现存两个数就够了,因为这四个数里必定有两个是
T2 很神奇的 区间

我们直接从下往上构造,最底下是第
T3 这题首先得把题读懂,然后注意一下题面里给的限制条件,然后再好好思考一下有什么用,已经不太会了😅
T4 没订
2024.10.13 核桃OJ
2024.10.14 33dai
T1
T2
T3
T4
2024.10.16 PYYZOJ
2024.10.18 33dai
T1 设
T2 涉及二进制运算的答案算的时候可以考虑考虑拆位。
如果
T3 写了个神秘随机化,刚开始
我们可以选一批数值相近的多个数来组合,根据抽屉原理
T4 给了
发现只有
我们还发现 “
重要的不是 “
具体的,我们设
2024.10.19 代码源
T1 直接从每个点出发跑一遍
T2 看着就很贪心,考虑怎么贪,来多试几种排序方式,发现可以把这
T3 首先可以得到一个朴素
考虑
链的答案是好求得,复杂度为
T4 可持久化李超树,是用分块实现的可持久化,记得自己当时听完就糊出来了😎。
具体的,我们按
2024.10.21 33dai
T1
T2
T3
T4
2024.10.22 PYYZOJ
2024.10.24 PYYZOJ
2024.10.29 PYYZOJ
2024.10.30 PYYZOJ
2024.11.01 核桃OJ
2024.11.02 代码源
T1 当时没做出来,直接给干自闭了😰,其实这题一点都不难。
正常的
具体的,对于一个
T2 这题我直接一遍糊出来的,我真厉害🤤。
首先贪心的考虑,左边和右边能匹配的先匹配上,这样一定是优的。然后这时左边或右边就会出现一段你必须得删的。这图画的有点丑,但是挺清晰的。红的代表删掉的,然后就可能有下面的两种情况,蓝的竖杠是回稳中心,横着的是匹配的部分,
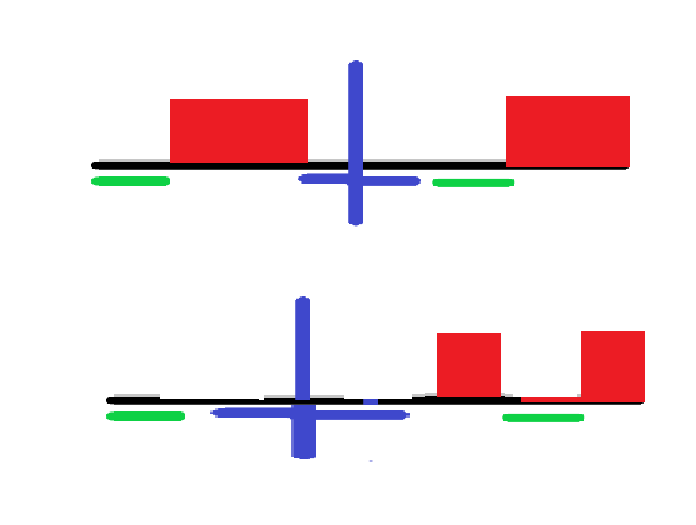
我们可以用
T3 这题比 T2 好写。我们发现得分是正数的位置除了停脚以外,它的得分是不重要的,因为一定能拿到这个得分,所以我们把所有正数先加到答案上,再赋成
T4 推式子的题,感觉不太好想,但是可能比较套路?
还是看看代码吧,不想手打公式了😋。
f[1]=cnt[1]=1;
for(int i=1; i<=n; ++i)
{
if(i>1)
f[i]=Cadd(1ll, Cmul(f[i], Ginv(cnt[i])));
for(int j=i+i; j<=n; j+=i) Madd(f[j], f[i]), cnt[j]++;
}
for(int i=1; i<=n; ++i)
{
g[i].resize(n/i+2);
g[i][1]=1;
for(int j=1; j<=n/i; ++j)
{
if(j>1) Mmul(g[i][j], Ginv(cnt[i*j]));
for(int k=j+j; k<=n/i; k+=j) Madd(g[i][k], g[i][j]);
}
}
for(int i=n; i>=1; --i)
{
int sum=0;
for(int j=i; j<=n; j+=i)
Madd(sum, g[i][j/i]);
h[i]=Cmul(sum, sum);
for(int j=i+i; j<=n; j+=i)
Mdel(h[i], Cmul(h[j], g[i][j/i], g[i][j/i]));
}
int ans=0;
for(int i=1; i<=n; ++i)
{
Madd(ans, Cmul(f[i], n, 2ll));
Mdel(ans, Cmul(f[i], h[i], 2ll));
}
2024.11.04 PYYZOJ
今天有两个重要的常用
抽屉原理和根号分治
抽屉原理在找合法方案时,我们先钦定都不合法,然后发现如果都不合法值域一定会超,发现只要很少的数就可以超过值域,即通过很少的数就可以得到合法的。
根号分治在处理关于序列的次数时,总共
T1
T2
T3
T4
2024.11.05 核桃OJ
2024.11.06 33dai
T1
T2
T3
T4
2024.11.08 33dai
T1
T2
T3
T4
2024.11.09 代码源
T1 发现谁和谁打是固定的,线段树维护一下每个区间赢的那个人的赢的概率。(线段树真是万能啊😀)
T2 比较简单的
显然对于
T3 分治求每个区间的
void solve(int l, int r)
{
if(l==r)
{
Madd(ans, a[l]%P);
return;
}
int mid=(l+r)>>1;
solve(l, mid);
solve(mid+1, r);
f[mid]=f[mid-1]=a[mid];
f[mid+1]=f[mid+2]=a[mid+1];
for(int i=mid-2; i>=l; --i)
f[i]=max(f[i+1], f[i+2]+a[i]);
for(int i=mid+3; i<=r; ++i)
f[i]=max(f[i-1], f[i-2]+a[i]);
g[mid]=g[mid+1]=0;
g[mid-1]=a[mid-1];
g[mid+2]=a[mid+2];
for(int i=mid-2; i>=l; --i)
g[i]=max(g[i+1], g[i+2]+a[i]);
for(int i=mid+3; i<=r; ++i)
g[i]=max(g[i-1], g[i-2]+a[i]);
int sum1=0, sum2=0;
q1.clear(); q2.clear();
for(int i=l; i<=mid; ++i) q1.push_back(i);
for(int i=mid+1; i<=r; ++i) q2.push_back(i), sum1+=f[i];
sort(q1.begin(), q1.end(), [&](int x, int y){return max(f[x]-g[x], 0ll)<f[y]-g[y];});
sort(q2.begin(), q2.end(), [&](int x, int y){return max(f[x]-g[x], 0ll)<f[y]-g[y];});
for(int i=0, j=0; i<q1.size(); ++i)
{
while(j<q2.size() && max(f[q1[i]]-g[q1[i]], 0ll)>=f[q2[j]]-g[q2[j]])
sum1-=f[q2[j]], sum2+=g[q2[j]], j++;
Madd(ans, Cmul((int)q2.size()-j, g[q1[i]]%P), sum1%P);
Madd(ans, Cmul(j, max(f[q1[i]], g[q1[i]])%P), sum2%P);
}
}
T4 二分答案,考虑怎么
bool check(int lim)
{
int Lx=-V, Rx=V;
int Ly=-V, Ry=V;
for(int i=1; i<=n; ++i)
{
int id=a[i].se;
if(lim>=a[i].fi)
{
int t=lim-a[i].fi;
if(calc(Lx-t, Ly-t, Rx+t, Ry+t))
return 1;
}
cmax(Lx, px[id]-lim);
cmax(Ly, py[id]-lim);
cmin(Rx, px[id]+lim);
cmin(Ry, py[id]+lim);
if(Lx==Rx)
{
Ly+=(Lx+Ly)&1;
Ry-=(Lx+Ry)&1;
}
if(Ly==Ry)
{
Lx+=(Ly+Lx)&1;
Rx-=(Ly+Rx)&1;
}
if(Lx>Rx || Ly>Ry) return 0;
}
return 1;
}
2024.11.12 代码源
T1 题意可以转换成给你
对于第一种情况,假设现在
对于第二种情况,对于减掉
T2 根据题意会得到一个暴力,但是我考场上连这个根据题意模拟的暴力都没写出来😢...
for(int i=1; i<=n; ++i)
cnt+=(s[i]=='1');
for(int i=1; i<=n; ++i)
if(s[i]=='1') ans+=2*i+1;
for(int i=1; i<=cnt; ++i)
ans-=i*2;
然后直接线段树维护一个
T3 先按左端点排序,维护两个
不想手打式子了,直接贴个代码。
for(PII x : f[i-1])
if(x.fi>=a[i].fi)
{
Madd(g[i][a[i].se], x.se);
Madd(f[i][min(x.fi, a[i].se)], x.se);
}
for(PII x : g[i-1])
if(x.fi>=a[i].fi)
{
Madd(g[i][x.fi], x.se);
Madd(g[i][max(x.fi, a[i].se)], x.se);
}
else
{
Madd(f[i][a[i].se], x.se);
Madd(g[i][a[i].se], x.se);
}
这玩意其实就是个区间乘,单点加,线段树维护就行了。
int tmp1=F.query(rt_f, 0, 1e9, a[i].fi, 1e9);
int tmp2=F.query(rt_f, 0, 1e9, a[i].se+1, 1e9);
int tmp3=G.query(rt_g, 0, 1e9, a[i].fi, a[i].se-1);
int tmp4=G.query(rt_g, 0, 1e9, 0, a[i].fi-1);
F.change(rt_f, 0, 1e9, 0, a[i].fi-1, 0);
F.change(rt_f, 0, 1e9, a[i].se+1, 1e9, 0);
F.update(rt_f, 0, 1e9, a[i].se, Cadd(tmp2, tmp4));
G.change(rt_g, 0, 1e9, 0, a[i].fi-1, 0);
G.change(rt_g, 0, 1e9, a[i].se, 1e9, 2);
G.update(rt_g, 0, 1e9, a[i].se, Cadd(tmp1, tmp3, tmp4));
时间复杂度是
T4 没订😋。
2024.11.13 33dai
T1
T2
T3
T4
2024.11.14 代码源
T1 先在从左往右每个数和一个下标对应上,整个序列会形成若干个段,只要不跨过这些段,怎么拍都是对的。因为它同时要求字典序最小,所以直接模拟就可以了。虽然在场上并没有做出来。
void solve(int op)
{
for(int i=1; i<=n; ++i)
{
if((i&1)==op)
vis[i]=1;
else vis[i]=0;
}
vector <int> res;
res.resize(n+2);
int now=0, sum=0, last=1;
for(int i=1; i<=n; ++i)
{
res[i]=a[i];
if(a[i]%2==0 && vis[i])
{
now--;
if(!now)
{
while(q.size()) q.pop();
for(int j=i; j>=last; --j)
{
if(a[j]%2==0)
q.push({a[j], j});
if(!vis[j])
{
res[j]=q.top().fi;
sum+=abs(q.top().se-j);
q.pop();
}
}
while(q.size()) q.pop();
for(int j=last; j<=i; ++j)
{
if(a[j]%2==1)
q.push({-a[j], j});
if(vis[j])
{
res[j]=-q.top().fi;
sum+=abs(q.top().se-j);
q.pop();
}
}
last=i+1;
}
}
if(a[i]%2==1 && !vis[i])
{
now++;
if(!now)
{
while(q.size()) q.pop();
for(int j=i; j>=last; --j)
{
if(a[j]%2==1)
q.push({a[j], j});
if(vis[j])
{
res[j]=q.top().fi;
sum+=abs(q.top().se-j);
q.pop();
}
}
while(q.size()) q.pop();
for(int j=last; j<=i; ++j)
{
if(a[j]%2==0)
q.push({-a[j], j});
if(!vis[j])
{
res[j]=-q.top().fi;
sum+=abs(q.top().se-j);
q.pop();
}
}
last=i+1;
}
}
}
if(sum<ans)
{
ans=sum;
tmp=res;
}
else if(sum==ans)
cmin(tmp, res);
}
T2 我们按怀疑度从大到小加边,注意到如果想走一条边,必须把一个连通块内所有怀疑度大于这条边的边都走了,也就是把整个连通块里的点都访问一遍,这样我们就确定了每条边的权值,然后跑遍
for(int d=9; ~d; --d)
{
for(int i=1; i<=n; ++i)
for(int j=1; j<=n; ++j)
if(f[i][j]==d+1) merge(i, j);
for(int i=1; i<=n; ++i)
for(int j=1; j<=n; ++j)
cmax(f[get(i)][j], f[i][j]);
for(int i=1; i<=n; ++i)
for(int j=1; j<=n; ++j)
if(f[get(i)][j]==d)
g[i][j]=siz[get(i)];
}
memset(ans, 0x3f, sizeof(ans));
ans[1]=0;
for(int i=1; i<=n; ++i)
{
int t=0;
for(int j=1; j<=n; ++j)
if(!vis[j] && ans[j]<ans[t])
t=j;
vis[t]=1;
for(int j=1; j<=n; ++j)
if(!vis[j])
cmin(ans[j], ans[t]+g[t][j]);
}
2024.11.16 代码源
T1 当时首先想到
for(int i=1; i<=n; ++i)
{
a[i]=a[i-1]+s[i]-'0'-f;
b[i]=b[i-1]+s[i]-'0';
}
for(int i=n; ~i; --i)
{
if(i!=n)
{
auto t=st.lower_bound({a[i], 0});
PII res=*t;
ld sum=(b[res.se]-b[i])/(res.se-i);
if(!id || fabs(f-sum)<=fabs(f-ans))
{
id=i;
ans=sum;
}
if(t!=st.begin())
{
t--; res=*t;
ld sum=(b[res.se]-b[i])/(res.se-i);
if(!id || fabs(f-sum)<=fabs(f-ans))
{
id=i;
ans=sum;
}
}
}
if(i) st.insert({a[i], i});
}
printf("%lld", id);
T2 很牛的
bool check(int lim)
{
memset(dp, 0x3f, sizeof(dp));
for(int i=0; i<=n; ++i)
if(sum_a[i]+sum_b[i]<=lim)
dp[i][1]=max(sum_a[i], sum_b[i]);
for(int i=1; i<=n; ++i)
for(int j=0; j<i; ++j)
for(int k=0; k<=m; ++k)
{
if(s[j][i]>lim) break;
if(dp[j][k]+f[j][i]>lim) continue;
cmin(dp[i][k+1], max(dp[j][k]+min(sum_a[i]-sum_a[j], sum_b[i]-sum_b[j]), g[j][i]));
}
for(int i=0; i<=n; ++i)
if(max(dp[i][m]+max(sum_a[n]-sum_a[i], sum_b[n]-sum_b[i]),
sum_a[n]-sum_a[i]+sum_b[n]-sum_b[i])<=lim)
return 1;
return 0;
}
T3 有点难,忘了咋推的了。
sort(a+1, a+n+1);
for(int i=1; i<=n; ++i)
b[i]=a[i], f[n]+=a[i];
f[n]=f[n]/n-C;
for(int i=n-1; i>=1; --i)
{
for(int j=1; j<=i; ++j)
c[j]=b[j]*(i+1-j)/(i+1)+b[j+1]*j/(i+1);
for(int j=1; j<=i; ++j)
f[i]+=max(f[i+1], c[j]);
f[i]=f[i]/i-C;
for(int j=1; j<=i; ++j) b[j]=c[j];
}
printf("%.9Lf", f[1]);
T4 没订。
2024.11.19 代码源
T1 场切😋。直接根据
T2 场切😋。线段树维护长度为
T3 首先有一个观察,就是去了就必须加油,否则就没必要去。贪心的想,一个点去另一个点之前,要么加满,要么加到另一个点的距离的油。这样一个点对应的状态就是
cmin(f[(d+1)&1][mp[j][0]], f[d&1][mp[i][dist(i, j)]]);
cmin(f[(d+1)&1][mp[j][W-dist(i, j)]], f[d&1][mp[i][W]]);
还有点内转移。
cmin(f[d&1][id[i][j+1].se], f[d&1][id[i][j].se]+(id[i][j+1].fi-id[i][j].fi)*c[i]);
两个部分都是
T4 没订。
2024.11.20 33dai
T1
T2
T3
T4
2024.11.21 代码源
T1 发现整个序列的最大值一定能赢,这就启发我们根据最大值,把序列分成两部分。对于分治后的部分,求出最大值,如果把整个序列的全吃了,如果比上一个最大值大,就可以吃掉最大值后,把上一个区间里的全吃掉,如果还能把之前的最大值吃掉,就赢了,这里是好实现的,具体的。
solve(l, res-1, max(a[res], mx-r+res-1));
solve(res+1, r, max(a[res], mx-res+l-1));
T2 区间
T3 喝的。
T4 喝的。
2024.11.23 代码源
T1 我们令
T2 小
T3 线段树合并。
T4 没订。
本文作者:EthanYates
本文链接:https://www.cnblogs.com/Ethan-Yates/p/18427809
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步