Kafka学习笔记(7)----Kafka使用Cosumer接收消息
1. 什么是KafkaConsumer?
应用程序使用KafkaConsul'le 「向Kafka 订阅主题,并从订阅的主题上接收消息。Kafka的消息读取不同于从其他消息系统读取数据,它涉及了一些独特的概念和想法。
1.1 消费者和消费者群组
单个的消费者就跟前面的消息系统的消费者一样,创建一个消费者对象,然后订阅一个主题并开始接受消息,然后做自己的业务逻辑,但是Kafka天生就是支持体量很大的数据消费,如果只是使用单个的消费者消费消息,当生产者写入消息的速度远远大于了消费者的速度,大量消息堆积在消费者上可能会导致性能反而降低或撑爆消费者,所以横向伸缩是很有必要的,就想多个生产者可以向相同的主题写消息一样,我们也可以使用多个消费者从同一个主题读取消息,对消息进行分流,这多个消费者就从属于一个消费者群组。一个群组里的消费者订阅的是同一个主题,每个消费者接收主题一部分分区的消息。
假设主题T1有四个分区,我们创建了消费者群组G1,创建了一个消费者C1从属于G1,它是G1里的唯一的消费者,此时订阅主题情况为,C1将会接收到主题中四个分区中的消息,如图:

此时我们在消费者群组中新增一个消费者C2,那么每个消费者将分别从两个分区接受消息,如图: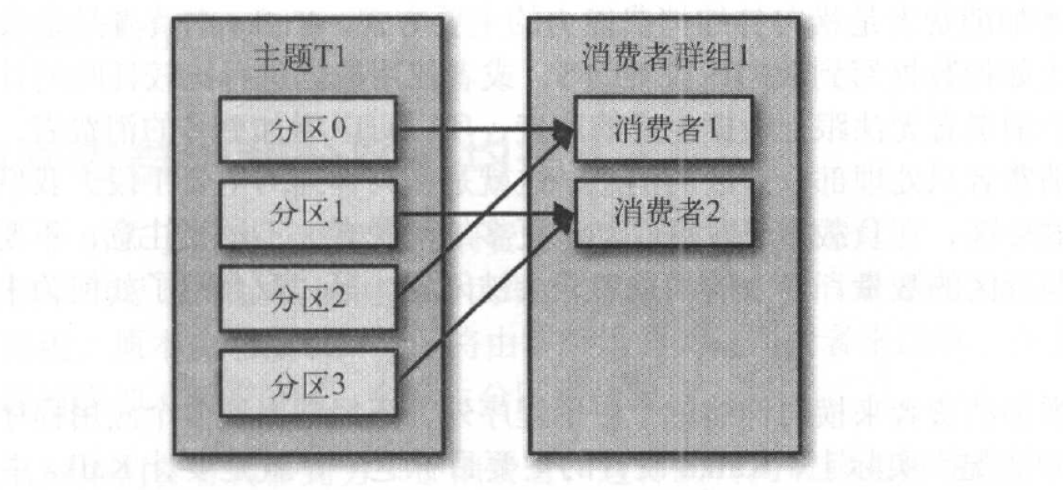
如果我们有四个消费者时,将会每个消费者都分到一个分区。
如果群组中的消费者超过了主题的分区数,那么有一部分消费者就会被闲置,不会接收任何消息。如图:
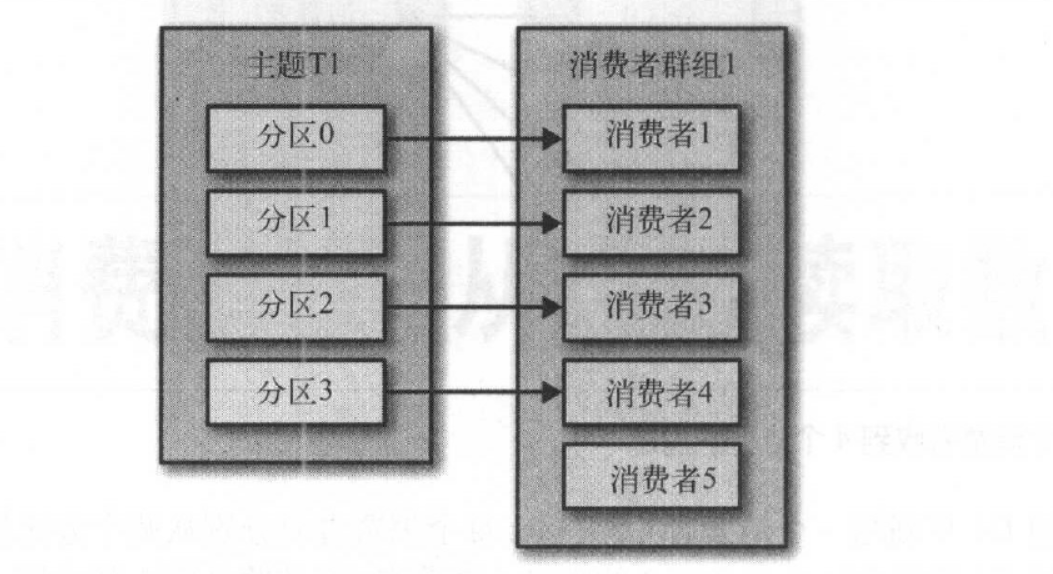
往群组里增加消费者是横向伸缩消费能力的主要方式。
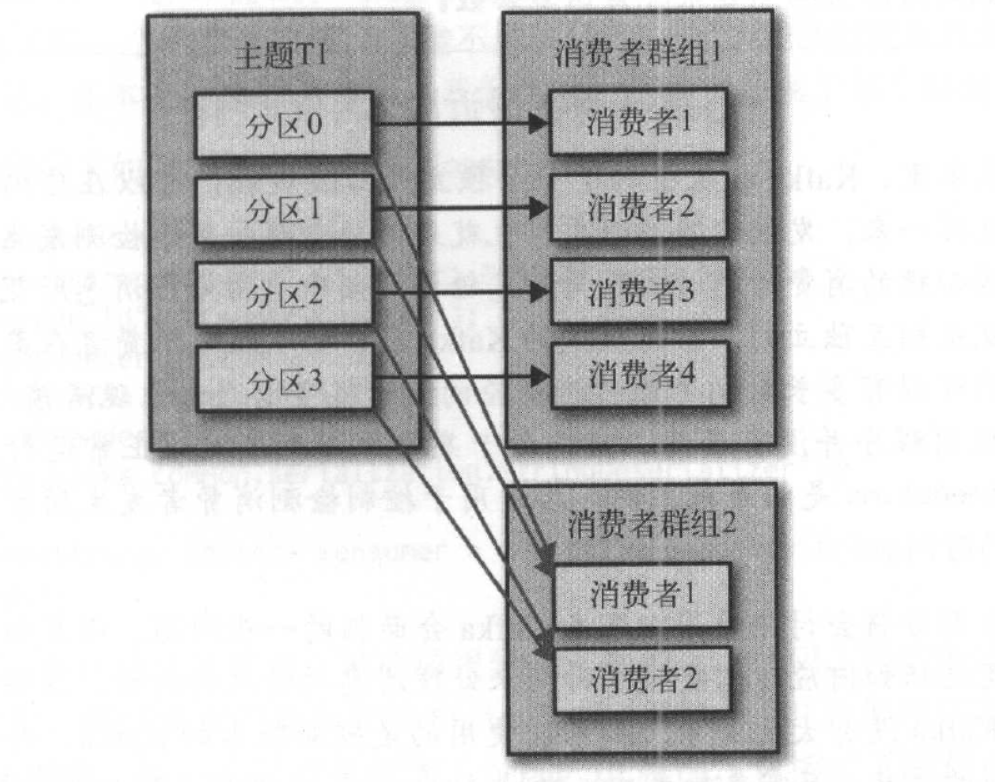
对于多个群组来说,每个群组都会从Kafka中接收到所有的消息,并且各个群组之间是互不干扰的。所以横向伸缩Kafka消费者和消费者群组并不会对性能造成负面影响。简而言之就是,为每一个需要获取一个或多个主题全部消息的应用程序创建一个消费者群组,然后往群组里添加消费者来伸缩读取能力和处理能力,群组里的每个消费者只处理一部分消息。如图:
1.2 消费者群组和分区再均衡
一个新的消费者加入群组时,它读取的是原本由其他消费者读取的消息。当一个消费者被关闭或发生奔溃时,它就离开群组,原本由它读取的分区将由群组里的其他消费者来读取。在主题发生变化时, 比如管理员添加了新的分区,会发生分区重分配。分区的所有权从一个消费者变成了里另一个消费者,这样的行为被称为再均衡。再均衡非常重要, 它为消费者群组带来了高可用性和伸缩性(我们可以放心地添加或移除消费者),不过在正常情况下,我们并不希望发生这样的行为。在再均衡期间,消费者无法读取消息,造成整个群组一小段时间的不可用。另外,当分区被重新分配给另一个消费者时,消费者当前的读取状态会丢失,它有可能还需要去刷新缓存,在它重新恢复状态之前会拖慢应用程序。
消费者通过向被指派为群组协调器的broker (不同的群组可以有不同的协调器)发送心跳来维持它们和群组的从属关系以及它们对分区的所有权关系。只要消费者以正常的时间间隔发送心跳,就被认为是活跃的,说明它还在读取分区里的消息。消费者会在轮询消息(为了获取消息)或提交偏移量时发送心跳。如果消费者停止发送心跳的时间足够长,会话就会过期,群组协调器认为它已经死亡,就会触发一次再均衡。如果一个消费者发生崩溃,井停止读取消息,群组协调器会等待几秒钟,确认它死亡了才会触发再均衡。在这几秒钟时间里,死掉的消费者不会读取分区里的消息。在清理消费者时,消费者会通知协调器它将要离开群组,协调器会立即触发一次再均衡,尽量降低处理停顿。
2. 创建Kafka消费者并读取消息
在创建KafkaConsumer之前,需要将消费者想要的属性存放到Properties中,然后再将properties传给KafkaConsumer。
Consuer也有三个必须的属性。bootstrap.servers,这里跟Producer一样,另外两个key.deserializer和value.deserializer也与Producer类似,不过一个是序列化,一个是反序列化而已。
还有一个group.id不是必须的,但是我们通常都会指定改消费者属于哪个群组,所以也可以认为是必须的。
设置Properties的代码片段如下:
Properties kafkaPropertie = new Properties(); //配置broker地址,配置多个容错 kafkaPropertie.put("bootstrap.servers", "node2:9092,node1:9092,node1:9093"); //配置key-value允许使用参数化类型,反序列化 kafkaPropertie.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); kafkaPropertie.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); //指定消费者所属的群组 kafkaPropertie.put("group.id","one");
接下来创建消费者,将Properties对象传入到消费者,然后订阅主题,如下:
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(kafkaPropertie); /*订阅主题,这里使用的是最简单的订阅testTopic主题,这里也可以出入正则表达式,来区分想要订阅的多个指定的主题,如: *Pattern pattern = new Pattern.compile("testTopic"); * consumer.subscribe(pattern); */ consumer.subscribe(Collections.singletonList("testTopic"));
接下来轮询消息,如下:
//轮询消息 while (true) { //获取ConsumerRecords,一秒钟轮训一次 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); //消费消息,遍历records for (ConsumerRecord<String, String> r : records) { LOGGER.error("partition:", r.partition()); LOGGER.error("topic:", r.topic()); LOGGER.error("offset:", r.offset()); System.out.println(r.key() + ":" + r.value()); } Thread.sleep(1000); }
生产者发送消息,然后查看消费者打印情况:
KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world0 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world1 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world2 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world3 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world4 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world5 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world6 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world7 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world8 KafkaConsuerDemo - partition: KafkaConsuerDemo - topic: KafkaConsuerDemo - offset: key1:hello world9
只存在一个组群和一个消费者时:
当我们启动两个消费者,同一个组群,并在Topic上创建两个Partition(分区),发送消息
final ProducerRecord<String, String> record = new ProducerRecord<String, String>("one",i % 2,"key3","hello world" + i);
将消息分发到0和1两个partition
此时两个消费者消费的消息总和等于发送的消息的总和,使用不同的群组的不同的订阅同一个topic,每个消费者群组都能收到所有的消息。
轮询不只是获取数据那么简单。在第一次调用新消费者的poll ()方法时,它会负责查找GroupCoordinator , 然后加入群组,接受分配的分区。如果发生了再均衡,整个过程也是在轮询期间进行的。当然,心跳也是从轮询里发送出去的。所以,我们要确保在轮询期间所做的任何处理工作都应该尽快完成。
消费者完整代码如下:
package com.wangx.kafka.client; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.time.Duration; import java.util.Collections; import java.util.Properties; public class KafkaConsuerDemo { private static final Logger LOGGER = LoggerFactory.getLogger(KafkaConsuerDemo.class); public static void main(String[] args) throws InterruptedException { Properties kafkaPropertie = new Properties(); //配置broker地址,配置多个容错 kafkaPropertie.put("bootstrap.servers", "node2:9092,node1:9092,node1:9093"); //配置key-value允许使用参数化类型,反序列化 kafkaPropertie.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); kafkaPropertie.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); //指定消费者所属的群组 kafkaPropertie.put("group.id","1"); //创建KafkaConsumer,将kafkaPropertie传入。 KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(kafkaPropertie); /*订阅主题,这里使用的是最简单的订阅testTopic主题,这里也可以出入正则表达式,来区分想要订阅的多个指定的主题,如: *Pattern pattern = new Pattern.compile("testTopic"); * consumer.subscribe(pattern); */ consumer.subscribe(Collections.singletonList("one")); //轮询消息 while (true) { //获取ConsumerRecords,一秒钟轮训一次 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); //消费消息,遍历records for (ConsumerRecord<String, String> r : records) { LOGGER.error("partition:", r.partition()); LOGGER.error("topic:", r.topic()); LOGGER.error("offset:", r.offset()); System.out.println(r.key() + ":" + r.value()); } Thread.sleep(1000); } } }
3. 消费者的配置
1. fetch.min.bytes: 该属性指定了消费者从服务器获取记录的最小字节数。
2. fetch.max.wait.ms:我们通过 fetch.min.byte告诉Kafka ,等到有足够的数据时才把它返回给消费者。
而 fetch.max.wait.ms则用于指定broker 的等待时间
3. max.partition.fetch.bytes:默认值是1MB,该属性指定了服务器从每个分区里返回给消费者的最大字节数.
4. session.timeout.ms: 默认3s,该属性指定了消费者在被认为死亡之前可以与服务器断开连接的时
5. auto.offset.reset:该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下(因消费者长时间失效,包含偏移量的记录已经过时井被删除)该作何处
6. enable.auto.commit:该属性指定了消费者是否自动提交偏移量,默认值是true。
7. partition.assignment.strategy: 分区分配给消费者群组的分配策略,有如下两种策略:
Range:该策略会把主题的若干个连续的分区分配给消费者.
RoundRobin:该策略把主题的所有分区逐个分配给消费.
8. client.id:该属性可以是任意字符串, broker 用它来标识从客户端发送过来的消息,通常被用在日志、度量指标和配额里。
9. max.poll.records: 该属性用于控制单次调用call () 方法能够返回的记录数量,可以帮你控制在轮询里需要处理的数据量。
10. receive.buffer.bytes 和send.buffer.bytes: socket 在读写数据时用到的TCP 缓冲区也可以设置大小。如果它们被设为-1,就使用操作系统的默认值。如果生产者或消费者与broker处于不同的数据中心内,可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。

