C考前预习(根据C Primer Plus中文版)
因为格式问题,代码缩进有点难看,以后可能会改一下(
第一章
编写程序的步骤

第二章
程序的组成
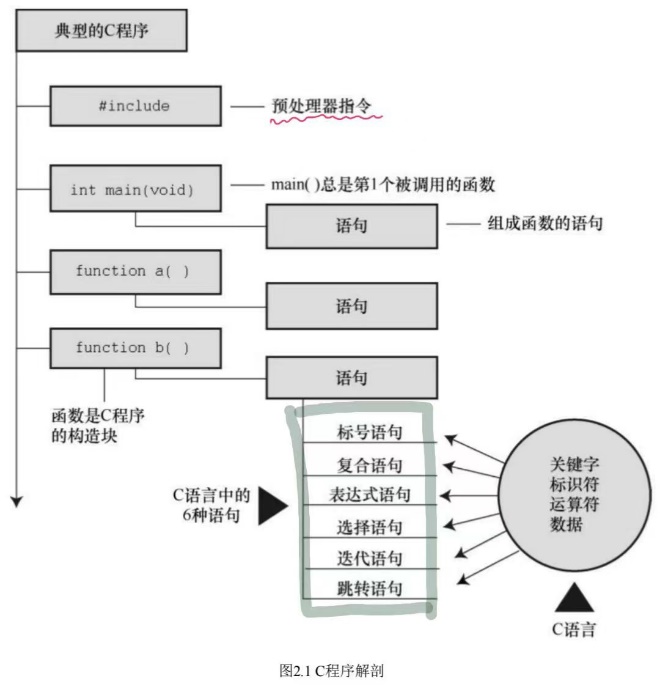
关键字
第三章
数据类型&关键字

C90新增:signed 整数变式;void
C99新增:_Bool 布尔值;_complex 复数; _Imaginary 虚数;int32_t等可移植类型/精确宽度整数类型等;
C语言有3种复数类型:float_Complex、double_Complex和 long double _Complex。例如,float _Complex类型的变量应包含两个float类型 的值,分别表示复数的实部和虚部。类似地, C语言的3种虚数类型是float _Imaginary、double _Imaginary和long double _Imaginary。
运算符 sizeof()
- sizeof(数据类型);会计算出数据类型所占空间大小(以字节为单位)
- 同理,换成sizeof(数组名);也会计算出数组所占内存空间大小
- 输出时 printf("Type long has a size of %zd bytes.\n", sizeof(long));
- Type long has a size of 8 bytes.
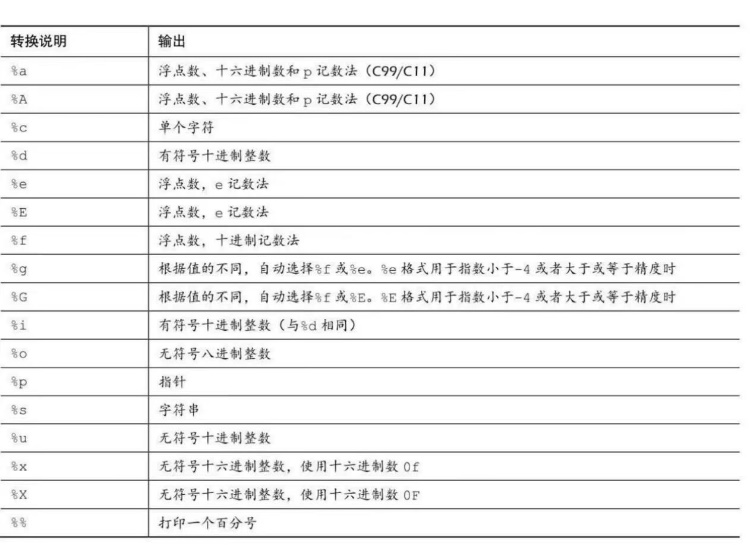
函数scanf()
printf()函数的调用格式为:printf("格式化字符串",输出表列)。
C语言printf()/scanf()的转换说明和转换说明修饰符 - 腾讯云开发者社区-腾讯云 (tencent.com)
格式化字符串包含三种对象,分别为:
(1)字符串常量;
(2)格式控制字符串;
(3)转义字符。
ASCII码字母&数字对应: ‘A’: 65 ‘a’: 97 ‘0’:48


作业题:
b. putchar ( ' \007') ;
如果系统是ASCII,就发出一个警报。
c. putchar ( ' \n' ) ;
输出换行符,即将输出光标换到下一行开始的位置。
d. putchar ( ' \b' );
将输出光标退后一个字符位。
整数/浮点数类型的区别
整数和浮点数的区别是它们的书写方式不同。对计算机而言,它们的区别是储存方式不同。
第四章
函数:
- strlen(); 由string.h库提供,可以用%zd, %u, %lu输出,strlen(str)求字符串长度
- strcat()
strcat(str1, str2)拼接字符串,str1=str1+str2, str2不变 第一个字符串数组可能溢出
strncat(str1, str2, len) 在加到第len个字符or遇到空字符时停止
- strcpy()
strcpy(str1, str2)后str1的值是str2的拷贝 该函数返回的是第一个参数第一个字符的地址 第一个参数不一定要指向数组的开始,有空字符的话也会一起拷贝
strncpy(str1, str2, n)拷贝前n个字符or空字符之前的字符
- 比较字符串,strcmp(str1, str2)如果相等:0,如果str1<str2:负数如-1,str1>str2:正数如1
- strncmp(str1, str2, n)比较前n个
const只读限定符
第五章
运算符及优先级

第六章
循环
for while do while 读代码:循环几次(略)
三元运算符 (条件表达式)?a:b;
函数fabs() (math.h)返回浮点数的绝对值 abs() (stdlib.h)整数绝对值
第七章
分支和跳转:if,else,continue略
添加bool类型:
#include <stdbool.h>
stdio.h中
getchar() ch=getchar();
putchar() putchar(ch);
ctype.h系列
isalpha(ch)判断ch是否是一个字符

Switch-break

Goto

一般来说不建议用
第八章
输入/输出/缓冲~(完全/行)/无缓冲~
文件以EOF结尾
所以可用while((ch= getc(fp)) != EOF)
对应putc用法:putc(ch,fp);
重定向
I/O函数
文件I/O FILE * fp; fp = fopen(fname, "r");while ((ch = getc(fp)) != EOF); fclose(fp);
第九章
运算符& *
一元&运算符给出变量的存储地址。
*间接运算符/解引用运算符语句
ptr = &bah;和val = *ptr;放在一起相当于下面的语句: val = bah;
float * pf, * pg; // pf、pg都是指向float类型变量的指针
递归
汉诺塔:
void HanoiTower(char A, char B, char C, int n)
{
if (n == 1)
{
move(A, C, n);
}
else
{
//将n-1个圆盘从A柱借助于C柱移动到B柱上
HanoiTower(A, C, B, n - 1);
//将A柱子最后一个圆盘移动到C柱上
move(A, C, n);
//将n-1个圆盘从B柱借助于A柱移动到C柱上
HanoiTower(B, A, C, n - 1);
}
}
第十章
变长数组int sum2d(int rows, int cols, int ar[rows][cols]); // ar是一个变长数组 (VLA)

关键字static
只初始化一次,静态存储期(静态内部链接/静态无链接)
创建&初始化数组
对于一个数组:flizny == &flizny[0]; // 数组名是该数组首元素的地址
指针和数组的关系
可以使用指针标识数组的 元素和获得元素的值。从本质上看,同一个对象有两种表示法。
表示不同位置:dates + 2 == &date[2] // 相同的地址 *(dates + 2) == dates[2] // 相同的值
*dates + 2 // dates第1个元素的值加2
1,未初始化,其值有两种可能:一种是全局数组/static,被编译器初始化为0。一种是局部数组/auto,为随机数。
2, 初始化后,局部数组和全局数组,未赋值的数组都会被赋值为0。
处理数组的函数
void sum_cols(int [][COLS], int); // 省略形参名,没问题
int sum2d(int(*ar)[COLS], int rows); // 另一种语法
指向多维数组的指针:
int zippo[4][2] = { { 2, 4 }, { 6, 8 }, { 1, 3 }, { 5, 7 } }; int(*pz)[2]; pz = zippo;
第十一章
字符串数组
自己设定/编辑器自动计算:const char m2[] = "If you can't think of anything, fake it.";
字符串都以’\0’结尾,剩余未定义空间自动填充\0
字符串函数
gets(words) //它读取整行输入,直至遇到换行 符,然后丢弃换行符,储存其余字符,并在这些字符的末尾添加一个空字符(可能导致溢出,慎用)
puts(words) //显示字符串,并在末尾添加换行符
gets_s(words, STLEN); //C11,但也不一定支持,读到换行符,会丢弃它而不是储存。只读标准输入
fgets(words, STLEN, stdin/文件); // 读入len-1个字符,或者读到遇到的第一个换行符(放末尾)为止
fputs(words, stdout); //不在字符串末尾添加换行符
/*处理掉读入的字符串中的换行符:while (words[i] != '\n') // 假设\n在words中 i++; words[i] = '\0';*/
书里推荐的自写读入函数:
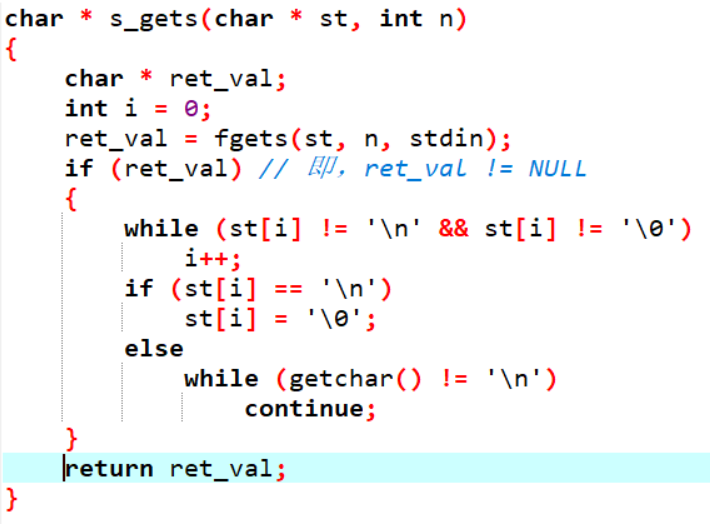
strlen(str); //计算字符串长度
strcat(flower, addon); //接受两个字符串作为参数。该函数把第 2个字符串的备份附加在第1个字符串末尾,并把拼接后形成的新字符串作为 第1个字符串,第2个字符串不变。
//返回第1个参数,即拼接第2个字符串后的第1个字符串的地址char *。
strncat(bugs, addon, 13); //将把 addon字符串的内容附加给bugs,在加到(完)第13个字符或遇到空字符时停止。
strcmp(str1, str2); //如果在字母表中第1个字符串位于第2个字符 串前面,strcmp()中就返回负数;反之,strcmp()则返回正数。
strncmp(str1, str2, len); //比较前len个字符
strcpy(qwords[i], temp); //把整个字符串从临时数组拷贝至目标数组中。 strcpy()函数相当于字符串赋值运算符。
//第2个参数(temp)指向的字符串被拷贝至第1个参数 (qword[i])指向的数组中。
strncpy(qwords[i], temp, TARGSIZE - 1); // 最多复制TARGSIZE-1个字符
sprintf(formal, "%s, %-19s: $%6.2f\n", last, first, prize); //将合成的字符串放入formal字符数组中
char *strchr(const char * s, int c); //该函数返回在字符串 str 中第一次出现字符 c 的位置,如果未找到该字符则返回 NULL。
char *strrchr(const char *str, int c); //在参数 str 所指向的字符串中搜索最后一次出现字符 c(一个无符号字符)的位置。
ret = strstr(haystack, needle); //在字符串 haystack 中查找第一次出现字符串 needle 的位置,不包含终止符 '\0'。
第十二章
变量的作用域和生命期
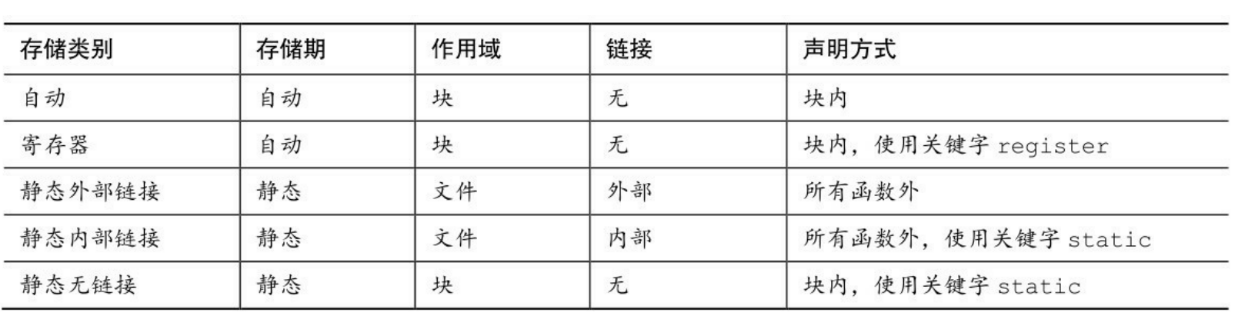

一些例子

某个C程序需要用到其他程序中定义过的变量,一般都加extern前缀,编译时编译器会预留访问链接的空位,等到link阶段再在整个工程的其他C编译结果中去对号,把访问链接填上。这就是外部链接。如果你程序全写在一个文件里,那永远都不会有外部链接。
内部链接常指一个程序文件中全局变量,可以被程序文件内各个子程序访问,这在编译过程中处理,和link阶段不发生关系。如果变量前加了static,那么它永远不会被外部程序访问,它不会被编译程序写入目标代码的链接区。
无链接,就是在一个单体程序里,比如一个子程序,定义一个变量只给这个程序段用,那就是无链接。 --百度知道
函数:

time需要include<time.h>

网上的简单用法:

malloc()分配内存。例:

要和free配合使用
malloc生成变长数组:

malloc和calloc:
int * p1 = (int *) malloc (100 * sizeof (int) ) ;
int * p1 = (int * ) calloc (100,sizeof(int) ) ;
两者都是分配100*sizeof(int),即400字节的内存空间,并返回一个指向它的指针。
第一句malloc()不会设置分配的内存为0,calloc()会初始化分配的内存为0。
cosnt&volatile语法一样,const是程序内无法改变,但是volatile表示代理可以改变该变量的值。



(位置11,其实是第12个……)
第十三章
文件I/O模式参数:
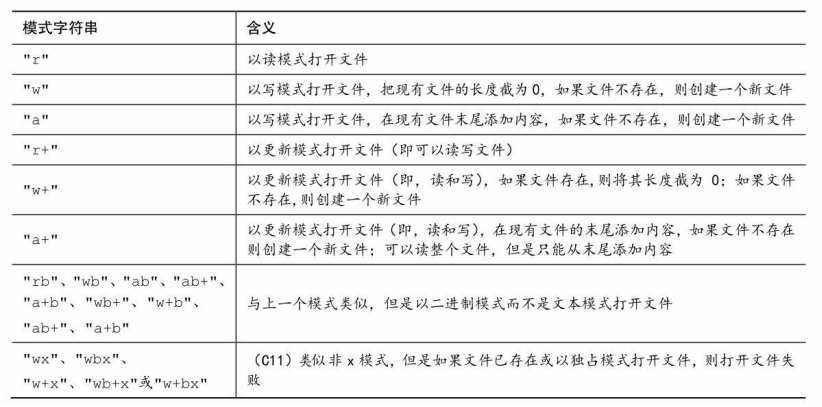

带x的写模式:即使fopen失败也不会删除源文件内容
函数:fopen()
函数:fclose()
以例子说明,截取其中部分语句
int main(int argc, char *argv [])
FILE *fp; // “文件指针”
if (argc != 2) //argc是输入参数的个数,argv[]是具体参数
{
printf("Usage: %s filename\n", argv[0]); //argv[0]是程序名
exit(EXIT_FAILURE);
}
if ((fp = fopen(argv[1], "r")) == NULL) //
{
printf("Can't open %s\n", argv[1]);
exit(EXIT_FAILURE);
}
while ((ch = getc(fp)) != EOF)
{
putc(ch, stdout); // 与 putchar(ch); 相同
count++;
}
fclose(fp); //关闭文件
判断关闭文件情况:
if (fclose(fp) != 0)
fprintf(stderr, "Error closing file\n");
函数:fprintf() fprintf(stdout, "Can't open \"wordy\" file.\n"); fprintf(fp, "%s\n", words);
函数:fscanf() while (fscanf(fp, "%s", words) == 1) puts(words);
函数:fgets() fgets(buf, STLEN, fp); 这里,buf是char类型数组的名称,STLEN是字符串的大小,fp是指向 FILE的指针。保留换行符
函数:fputs() fputs(buf, fp); 不添加换行符
函数:fseek() fseek(fp, 0L, SEEK_END); /* 定位到文件末尾 */
fseek(fp, -count, SEEK_END); /* 回退 */ fseek(fp, 10L, SEEK_SET); // 定位至文件中的第10个字节。有的系统不允许读完立刻写,需要fseek定位再写入。

如果一切正常,fseek()的返回值为0;如果出现错误(如试图移动的距 离超出文件的范围),其返回值为-1。
函数:ftell() ftell(fp)函数返回类型为long当前位置
函数:fflush() C 库函数 int fflush(FILE *stream) 刷新流 stream 的输出缓冲区。
int setvbuf(FILE * restrict fp, char * restrict buf, int mode, size_t size); setvbuf()函数创建了一个供标准I/O函数替换使用的缓冲区。
函数:fread()
函数:fwrite() fwrite(earnings, sizeof(double), 10, fp); 把earnings数组中的数据写入文件,数据被分成10块,每块都是double的大小。第一个参数是指针类型,返回成功写入项数量。
rewind(fp); /* 返回到文件开始处 */
文本/二进制模式
如果文件最初使用二进制编码的字符(例如,ASCII或Unicode)表示文本(就像C字符串那样),该文件就是文本文件,其中包含文本内容。如果文件中的二进制值代表机器语言代码或数值数据(使用相同的内部表示,假设,用于long或double类型的值)或图片或音乐编码,该文件就是二进制文件。
二进制文件与文本文件的区别是,这两种文件格式对系统的依赖性不同。二进制流和文本流的区别包括是在读写流时程序执行的转换(二进制流不转换,而文本流可能要转换换行符和其他字符)。
第十四章
结构
运算符. ->
指向结构体的指针
struct guy fellow[2] = {略};
struct guy * him; /* 这是一个指向结构的指针 */
him = &fellow[0]; /* 告诉编译器该指针指向何处, 注意结构名并不是结构的地址*/
//fellow 是一个结构数组,这意味着 fellow[0]是一个结构。him指向fellow[0], him+1指向fellow[1]
him->income等同于 (*him).income
访问方法
如果him == &barney,那么him->income 即是 barney.income
fellow[0].income == (*him).income //*优先级比.低,所以必须使用圆括号
总之,barney.income == (*him).income == him->income // 假设 him == &barney
如果想用指针替换结构体中的字符串数组,应该用malloc配合
pst->fname = (char *) malloc(strlen(temp) + 1); // 把名拷贝到已分配的内存 strcpy(pst->fname, temp);
释放:
void cleanup(struct namect * pst)
{
free(pst->fname);
free(pst->lname);
}
union
和struct类似,但只能储存一个成员值
union hold valA; valA.letter = 'R'; union hold valB = valA; // 用另一个联合初始化
union hold valC = {88}; // 初始化联合的第一个成员digit
union hold valD = {.bigfl = 118.2}; // 指定初始化器
typedef固化
typedef char * STRING;
即STRING name, sign; 相当于: char * name, * sign;
结构体对齐/计算结构体所占内存
第十五章
位运算运算符
二/八/十/十六进制计数法,换算(略)
C11位字段对齐
_Alignas, _Alignof include<stdalign.h>
typedef struct
{
int value; // aligns on a 4-byte boundary. There will be 28 bytes of padding between value and alignas
alignas(32) char alignedMemory[32]; // assuming a 32 byte friendly cache alignment
} cacheFriendly; // this struct will be 32-byte aligned because alignedMemory is 32-byte aligned and is the largest alignment specified in the struct
alignas(32) char alignedMemory[32]; // 假设一个32字节的友好缓存对齐。
alignof(cacheFriendly) //返回32,因为上文是32字节对齐
第十六章
#define
#pragma pack(n) //指定n个字节对齐
(18条消息) #pragma pack详解_OuJiang2021的博客-CSDN博客_#pragma pack
常用的函数/宏
预定义宏

C预处理器
C预处理器在程序执行之前查看程序(故称之为预处理器)。根据程序中的预处理器指令,预处理器把符号缩写替换成其表示的内容。预处理器可以包含程序所需的其他文件,可以选择让编译器查看哪些代码。预处理器并不知道 C。
第十七章
malloc()进阶
ADT总结/设计
提供类型属性和相关操作的抽象描述。这些描述既不能依赖特定的实现,也不能依赖特定的编程语言。这种正式的抽象描述被称为抽象数据类型 (ADT)
栈
a.
类型名:栈.
类型属性: 可以储存有序项.
类型操作: 初始化栈为空.
确定栈是否为空.
确定栈是否已满.
从栈顶添加项(压入项.
从栈顶删除项(弹出项).
b. 下面以数组形式实现栈,但是这些信息只影响结构定义和函数定义的细节,不影响函数原型的接口.
/* stack.h –– 栈的接口 */
#include <stdbool.h>
/* 在这里插入Item类型 */
/* 例如, typedef int Item; */
#define MAXSTACK 100
typedef struct stack
{
Item items[MAXSTACK]; /* 储存信息 */
int top; /* 第一个空位的索引 */
} Stack;
/* operation: 初始化栈 */
/* precondition: ps 指向一个栈 */
/* postcondition: 该栈被初始化为空 */
void InitializeStack(Stack * ps);
/* operation: 检查栈是否已满 */
/* precondition: ps 指向之前已被初始化的栈 */
/* postcondition: 如果栈已满,该函数返回true;否则返回false*/
bool FullStack(const Stack * ps);
/* operation: 检查栈是否为空 */
/* precondition: ps 指向之前已被初始化的栈 */
/* postcondition: 如果栈为空,该函数返回true;否则返回false */
bool EmptyStack(const Stack *ps);
/* operation: 把项压入栈顶 */
/* precondition: ps 指向之前已被初始化的栈 */
/* item 是待压入栈顶的项 */
/* postcondition: 如果栈不满,把item放在栈顶,该函数返回true;否则,栈不变,该函数返回false */
bool Push(Item item, Stack * ps);
/* operation: 从栈顶删除项 */
/* precondition: ps 指向之前已被初始化的栈 */
/* postcondition: 如果栈不为空,把栈顶的item拷贝到*pitem,删除栈顶的item,该函数返回true */
/* 如果该操作后栈中没有项,则重置该栈为空*/
/* 如果删除操作之前栈为空,站不变,该函数返回false*/
bool Pop(Item *pitem, Stack * ps);


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人