云题合集
云题合集
$NOI2020$命运
题目大意$:$
每条边有两个状态$(0,1)$,问满足所有限制$($每一条规定链之间必然有一个$1)$
一眼上去肯定是$dp$,考虑怎么设状态
还是说第一维肯定是节点$x$,那么第二维设置什么合适
我一开始想的是记录哪些被满足,哪些没被满足,显然复杂度过高
我每次转移的时候发现能像树形$dp$一样,通过转移子树,来确定每个边的状态
每次转移可以根据枚举这个边的所有状态,然后得到下一步所有的状态
考虑这个东西,我们可以确定一个状态,那么我们还是可以在第二维确定哪些条件没被满足
只不过,我们可以不记录那个状态到底哪些没被满足,我们可以只记录没被满足的起点最深的在哪
为什么,显然可以得到所有状态,考虑每种状态肯定都有一个没有满足条件的起点最深的条件那么就按这个东西另存一维就好了
到这里,我貌似理解了$dp$本质,大概就是把所有状态归成一类,统计这一类的所有方案数,然后分情况讨论罢了
$dp[x][i]$表示子树$x$的状态已经确定,未满足条件的下端点在子树内部的最大深度是多少
那么就可以转移了,直接考虑着一条边选不选就好了,那么我考虑每一次都能转移到最深的就好了,并且我转移的必须保证以后能转移到最终方案
$dp'[x][i]=\sum_{j=0}^{dep_x}dp[x][i]\times dp[y][j]+\sum_{j=0}^{i}dp[x][i]\times dp[y][j]+\sum_{j=0}^{i-1}dp[x][j]\times dp[y][i]$
后面那个$i-1$是防止深度都是$i$的方案被算两次
到了这,咱们就有$64pts$了
至于正解嘛,这个东西可以线段树合并,毕竟是前缀和...
重写以下式子
$dp'[x][i]=dp[x][i]\times sum[y][dep_x]+dp[x][i]\times sum[y][i]+sum[x][i-1]\times dp[y][i]$
$dp'[x][i]=dp[x][i]\times(sum[y][dep_x]+sum[y][i])+dp[y][i]\times sum[x][i-1]$
这个的话,大概就是一个区间乘$sum[y][dep_x]$
实现的话,也很好说,第一部分先求个$sum[y][dep_x]$.递归到最底层然后乘上这个东西
上面的两个$sum$显然是可以在递归时候累加的
$NOI2020$美食家
这$n,m$这么小,显然可以搞到一个矩阵上瞎搞搞,
$dp$显然吧,可以先把美食节按时间排个序,$dp[x][i]$,表示当前时间$x$,在位置$i$得到的最大价值
大概是可以预处理出点对之间所有可能的距离,然后能转移的转移一下就好了,私以为刷表法比较可行
显然这个$dp$复杂度不优秀,那么就搞一下矩阵快速幂,这个东西不是很好设计矩阵。
首先刚刚那个状态不能用填表,需要刷表解决,反正$n$也很小
那么我们基本的式子如下
$dp[y][i+w]=\max(dp[y][i+w],dp[x][i]+val[y])$
显然的,这个东西可以把一个边拆成$w$个点这样去转移,这样显然是可以的,最后只需要统计实际点的权值就好了
其实矩阵设计不是很困难,转移这个的时候
刚刚被加卡住了,发现其实这个东西由于提前把矩阵乘法重新定义了
那么刚刚被点了一下,发现自己是神笔,只需要在转移矩阵上对应位置是$val$就好了
那么咱们解决了$k=0$
至于$k!=0$的情况,搞一个神奇的二进制分组就好了...
$WC2019$远古计算机(代码源自洛谷)
感觉这个东西无非就是用二进制模拟一下加减法之类的罢了
第一个$subtask$很简单
直接模拟输入输出就好了
由于这个直接无限循环,那么就整就好了
node 1 read 0 a write a 0
至于第二个$subtask$嘛
那就可以提前预处理,然后直接$write$出来就好了
感觉也很水
#include<bits/stdc++.h> using namespace std; int f[45]; int main() { freopen("oldcomputer2.out","w",stdout); printf("node 1\n"); printf("read 0 a\n"); printf("add a 4\n"); printf("jmp a\n"); f[0]=0;f[1]=1; for(int i=2;i<=45;i++) f[i]=f[i-1]+f[i-2]; for(int i=0;i<=45;i++) printf("write %d 0\n",f[i]); }
至于第三个$subtask$
一条路给他按顺序运过去就好了,就是,输入一个数,依次运过去,就好了
找一个确定的路,显然可以最短路吧
#include<bits/stdc++.h> using namespace std; const int N=110; vector<int> g[N]; bool inq[N]; int dis[N],pre[N],n,m; void spfa() { memset(dis,0x3f,sizeof(dis)); queue<int> q; q.push(1);dis[1]=0; while(!q.empty()) { int u=q.front(); for(int v : g[u]) if(dis[u]+1<dis[v]) { pre[v]=u; dis[v]=dis[u]+1; if(inq[v]) continue; inq[v]=1;q.push(v); } q.pop();inq[u]=0; } for(int i=n,nxt=0;i;i=pre[i]) { printf("node %d\n",i); printf("read %d a\n",pre[i]); printf("write a %d\n",nxt); nxt=i; } } int main() { freopen("oldcomputer3.in","r",stdin); freopen("oldcomputer3.out","w",stdout); int qwq; scanf("%d%d%d",&qwq,&n,&m); for(int i=1,u,v;i<=m;i++) { scanf("%d%d",&u,&v); g[u].push_back(v); g[v].push_back(u); } spfa(); }
第四个$subtask$
既然无所谓顺序,只要求在$51-100$输出,
直接把$1-50$压入队列,然后$BFS$找到最短路,然后把数据传过去就好了
#include<bits/stdc++.h> using namespace std; typedef pair<int,int> pii; const int N=1010; vector<int> g[N]; vector<pii> msg[N]; int dis[N],n,m; bool inq[N]; void spfa() { queue<int> q; memset(dis,0x3f,sizeof(dis)); for(int i=51;i<=100;i++) { dis[i]=0; inq[i]=1; q.push(i); } while(!q.empty()) { int u=q.front(); for(int v : g[u]) if(dis[u]+1<dis[v]) { dis[v]=dis[u]+1; if(inq[v]) continue; inq[v]=1;q.push(v); } q.pop();inq[u]=0; } } int main() { freopen("oldcomputer4.in","r",stdin); freopen("oldcomputer4.out","w",stdout); int qwq; scanf("%d%d%d",&qwq,&n,&m); for(int i=1,u,v;i<=m;i++) { scanf("%d%d",&u,&v); g[u].push_back(v); g[v].push_back(u); } spfa(); queue<int> q; for(int i=1;i<=50;i++) { q.push(i); msg[i].push_back(pii(0,0)); } while(!q.empty()) { int u=q.front(),v=0;q.pop(); for(int vv : g[u]) if(dis[u]==dis[vv]+1) v=vv; printf("node %d\n",u); sort(msg[u].begin(),msg[u].end()); for(pii pr : msg[u]) { printf("read %d a\n",pr.second); printf("write a %d\n",v); msg[v].push_back(pii(pr.first+1,u)); } if(v) q.push(v); } return 0; }
第五个$subtask$
需要对应输出
那么暴力的想一想,每一个跑一遍最短路,按照$subtask3$的方法搞一搞就好了
但是由于是程序,大概类似一个多线程同时操作,那么需要搞一个类似时间戳的东西就好了
表示哪些时间哪个点是空闲的,这样的话多线程就可以进行了,按时间排序运输
#include<bits/stdc++.h> using namespace std; const int N=210; struct MSG{int from,to,time;}; vector<int> g[N]; vector<MSG> msg[N]; bool bad[N][N],inq[N]; int dis[N],pre[N],n,m,ans=0; bool operator < (const MSG &a,const MSG &b){return a.time<b.time;} void spfa(int s,int t) { memset(pre,0,sizeof(pre)); memset(dis,0x3f,sizeof(dis)); queue<int> q;q.push(s); dis[s]=0;inq[s]=1; while(!q.empty()) { int u=q.front(); for(int v : g[u]) { int w=dis[u]+1; while(bad[v][w]||bad[v][w+1]) w++; if(w<dis[v]) { dis[v]=w;pre[v]=u; if(inq[v]) continue; inq[v]=1;q.push(v); } } q.pop();inq[u]=0; } for(int i=t,nxt=0;i;i=pre[i]) { bad[i][dis[i]]=bad[i][dis[i]+1]=1; msg[i].push_back((MSG){pre[i],nxt,dis[i]}); nxt=i; } ans=max(ans,dis[t]); } int main() { freopen("oldcomputer5.in","r",stdin); freopen("oldcomputer5.out","w",stdout); int qwq; scanf("%d%d%d",&qwq,&n,&m); for(int i=1,u,v;i<=m;i++) { scanf("%d%d",&u,&v); g[u].push_back(v); g[v].push_back(u); } for(int i=1;i<=10;i++) bad[i][0]=bad[i][1]=1; for(int i=1;i<=10;i++) spfa(i,101-i); for(int i=1;i<=n;i++) { if(msg[i].empty()) continue; sort(msg[i].begin(),msg[i].end()); printf("node %d\n",i); for(MSG pp : msg[i]) { printf("read %d a\n",pp.from); printf("write a %d\n",pp.to); } } cerr<<ans+2<<endl; return 0; }
$CTSC2016\ NOIP$十合一
题目的本意就是让你观察原图找规律(考场上没有生成图的软件是得多痛苦...)
$subtask1$
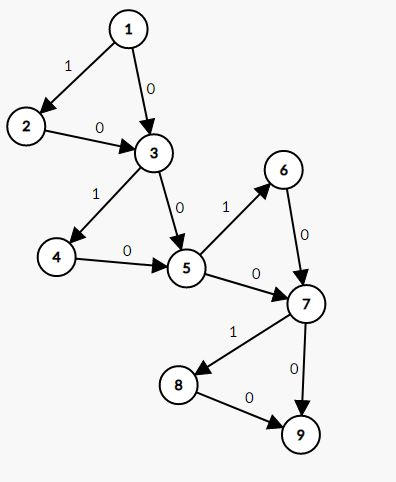
那么我们显然经过每一个子图(三角形)有两种选择,总长度$+1$,或者不变
那么就可以搞一个组合数的东西就好了
$subtask2$
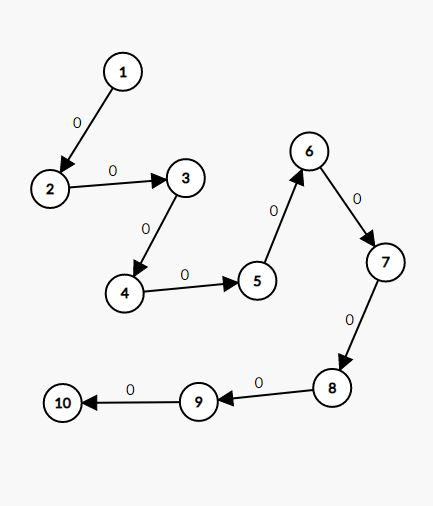
当然每个点都有一个自环(貌似这个画图软件不能体现自环...)
我的想法是,把自环看成点权,看成一个完全背包,在$DAG$上跑完全背包就好了...
由于起点都是$1$,那么直接从$1$,预处理跑一遍预处理就好了
$subtask3$
和上面图一样,只不过起点不一样了,那么总不能都跑一遍吧...(毕竟是提交答案,谁知道能不能跑出来,$AVX+Ofast+64bit/ww$)
$subtask4$
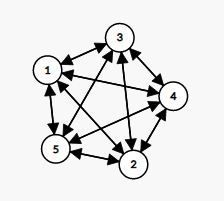
只有$5$个点,任意点对之间很多边,是个(完全$^x$图)
当然少不了自环...
这个的话,不是很会...
如果是我的话,我大概会刷表吧,从小往大刷表,然后枚举每个点的所有情况,啊不对,这个显然有后效性
不太行的样子,有后效性最常用的方法是高斯消元(开玩笑...)
不太会...啊不对,貌似可以先枚举距离再枚举五个点,这样的话更新距离是保证目前点当前状态的所有方案都累加了
复杂度看上去很危...
$subtask5$
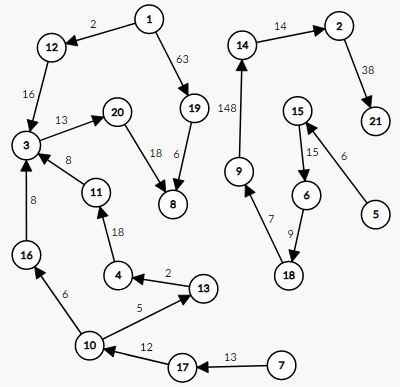
显然是个$DAG$,那么显然两个点对之间的方案数可以用拓扑跑出来吧
起点已知的情况下,或许直接$dfs$也是可行的
$subtask6/7/8/9/10$
不完整图,其实和上面一样,只不过需要加速递推
也是$DAG$,只不过边权都是$1$,这个东西也可以$dfs?$...
$subtask10$有自环
以上都是我的想法,看一下题解
不过貌似大部分的$dp$都可以来个加速递推$/ww$
题解思路$:$
$subtask1$和上面思路一致,关于组合数计算需要$EXLucas$(这都要套数论,$cbddl$)
$subtask2$和上面思路一致,反正边权不超过$50000$,安安心心跑$dp$吧
$subtask3$好,不一样了,显然直接跑$dp$会死的很惨,那么这个东西显然可以多项式...
上标表示选了多少,系数表示方案数,两个多项式相乘表示方案数相乘,上标相加
由于是一条链,显然可以多项式乘法逆,求个前缀逆就好了
多项式$yyds$
$subtask4$都是用的$dp$,不过不太一样(啊不对,一样,那没事了,我竟然想对了$hhh$),转移时候状态和转移边太多了,就很不好搞,由于上限是$50000$,复杂度很安全,跑个几分钟就好了(毕竟是提交答案)
$subtask5$寄,我的图不完整...
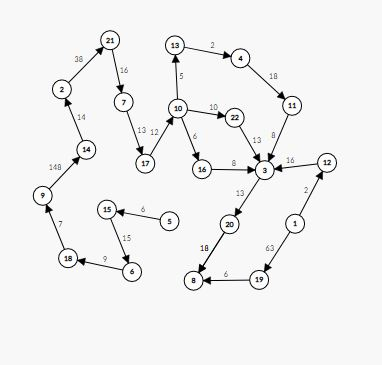
悲,我竟然对着一张残缺的图找规律...(貌似挺完整的...)
那么重新找一下规律,发现这个东西都是两个$1-10$的端点中间有一个$11-50000$的点
那么首先可以定位每个点的前驱和后继,这个是一个$DAG$,那么就可以像$subtask4$一样$dp$
那么显然的话还是可以枚举每个点的出边去更新状态,这样的话在满足当前点的当前状态已经全部更新完成
那么和$sub4$一样了
$subtask6-10$图的相似度很高
$sub6$
而且我又见识了那个神奇的二进制分组的矩阵快速幂...
首先如果是$DAG$的话,肯定可以和$subtask4/5$一样没有后效性的转移
首先处理每个二进制位的转移矩阵,然后由于每次只需要一个点,那么就乘矩阵的一部分就好了,可以优化掉一个$n$
具体说一下,普通的矩阵快速幂转移矩阵大概是,一些位置是$1$表示可以转移到
那么这个相当于只处理一部分有用的就好了
$sub7$
暴力拆边就好了,这道题怎么这么像$NOI2020$美食家...
$sub8$
可以有很优秀的写法,但是电脑不是我家的$/ww$,就让他和$sub7$一样跑就好了,尽管跑了很久...
我们可以枚举在一个里面走了多少圈到了另一类点,那么转移矩阵的话,大概就是这个矩阵的什么
$sub9$
建边就很神奇...$u->v(u=v+1 \mod 1e3)$,询问也很神奇,$b-a=c\mod 1e3$
那么这个可以把点分成$1e3$类,大概转移的话就是这个圈哪个值,转移的话就是这个方案能转移到哪个点方案数
反正就是随便转移...看看在当前取模是多少,然后转多少圈,会变到多少就好了,那么就好了
大概就是$1->2->3$这个也可以延续原来的转移方式
$sub10$
继续暴力跑,耐心等候$2h$即可得出答案...
$Loj2769$
第一感觉的话,维护一个最短路,顺便维护一下平方和最大值就好了
复杂度不能保证
第二感觉这是个很神仙的$dp+$优化问题
首先可以把最短路图建出来,然后肯定是个$DAG$
那么接下来怎么搞,显然可以$dp$一下,$dp[i]$表示到这个点的平方和最大值
而且这个还要搞相邻的一段转移时候才能贡献答案
那么就好说了,$dp[i]=max(dp[i],dp[s]+val)$
好吧,我读错了$3$遍题...
那么这个转移就很显然了,复杂度是$n^2$,那么必然是需要优化的
$dp[i]=max(dp[j]+(dp[i]-dp[j])^2)$
$dp[i]=max(dp[j]+dp[j]^2-2\times dp[i]\times dp[j])+dp[i]^2$
这个东西就可以斜率优化了(单调栈维护)
$Loj2757$
第一感觉还是优化$dp$
$dp[i][j]$表示选到了第$i$个盒子,有了$j$个馒头的最大价值
复杂度貌似很安全...(然后就切了?)
来点贪心,先选大的比较优,那么排个序就好了
