【深度学习】常用损失函数
一、Smooth L1 Loss
1.公式:
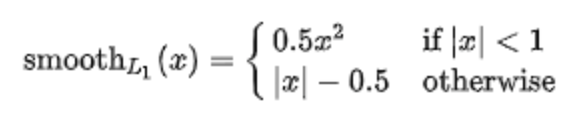
2.原因:
L1损失使权值稀疏但是导数不连续,L2损失导数连续可以防止过拟合但对噪声不够鲁棒,分段结合两者优势。
L1 Loss的导数是常数,那么在训练后期,当预测值与 ground truth 差异很小时, L1 Loss 损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
三、交叉熵损失
1.公式:
![]()
2.平衡交叉熵损失
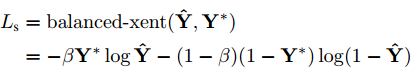
三、Focal Loss
1.基本原理
Focal Loss主要是为了解决单阶段目标检测算法中正负样本严重失衡的问题,该损失降低了简单负样本损失的权重,可以理解为困难样本挖掘。
平衡交叉熵可以平衡正负样本,但不能平衡难分易分样本。
2.公式
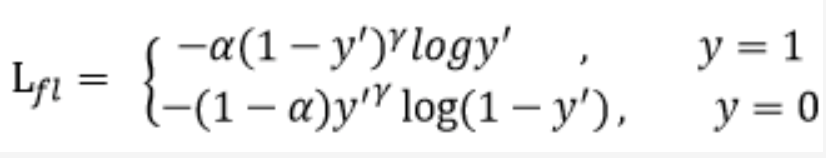
3.参考资料
https://www.cnblogs.com/king-lps/p/9497836.html
四、Dice Loss
1.公式:(类似于交并比)
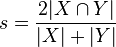
五、平方损失
1.适用
用于线性回归中。
六、hinge损失(铰链损失)
1.公式:
![]()
2.适用:
主要用于SVM中。SVM损失是hinge损失和L2正则损失的和。
七、指数损失
1.适用
用于adaboost中。
八、0/1损失
对应方法:
1.Faster RCNN:cls+loc=交叉熵损失+smooth L1损失
2.YOLO:平方损失
3.SSD:cls+loc=交叉熵损失+smooth L1损失
4.EAST:cls+角度+loc=平衡交叉熵损失+cos损失+log交并比损失
分类:
交叉熵损失、focal loss、指数损失、hinge损失
回归:
平方损失、smooth L1损失、交并比损失、Dice 损失
