
【深度学习】激活函数对比
一、sigmod
1.函数与图像:[0,1]
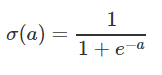
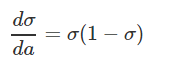
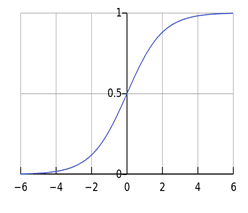
2.优缺点:
优点:输出映射在[0,1]之间;求导容易;无限阶可导。
缺点:容易产生梯度消失的问题,因为小于1的数累乘会接近0;输出不是以0为中心,输出都是正或负,会导致网络的学习能力受限。(这个特性会导致在后面神经网络的高层处理中收到不是零中心的数据。这将导致梯度下降时的晃动,因为如果数据到了神经元永远是正数时,反向传播时权值w就会全为正数或者负数。这将导致梯度下降不希望遇到的锯齿形晃动)。
3.参考资料
https://blog.csdn.net/BGoodHabit/article/details/106217527?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-106217527-blog-122694916.pc_relevant_multi_platform_whitelistv3&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-106217527-blog-122694916.pc_relevant_multi_platform_whitelistv3&utm_relevant_index=1
二、tanh
1.函数与图像:[-1,+1]
![]()
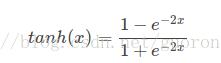

2.优缺点:
优点:和sigmoid相比收敛速度快,以0为中心;
缺点:依然容易梯度消失;
三、Relu
1.函数与图像:[0,+∞]
f(x ) = max(0,x) 即 if x>=0 时 f(x) = x,否则f(x) = 0
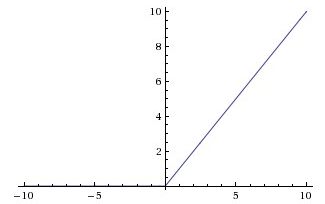
2.优缺点:
优点:非线性,可以逼近任意函数;收敛快;缓解梯度消失问题;提供了神经网络的稀疏表达能力;
缺点:随着训练的进行,可能神经元输出为0,会出现神经元死亡,权重无法更新的情况(梯度可能为输出*残差);(可用小的负梯度如0.01等代替0)
四、Leaky Relu
1.函数与图像
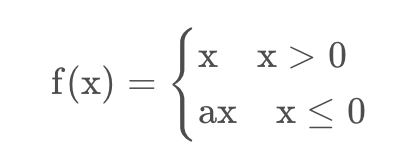

2.优缺点
缓解了Relu的神经元死亡问题,但a是人工设置参数,不够灵活,可以网络学习a。
五、Elu
1.函数与图像
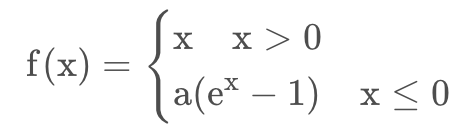
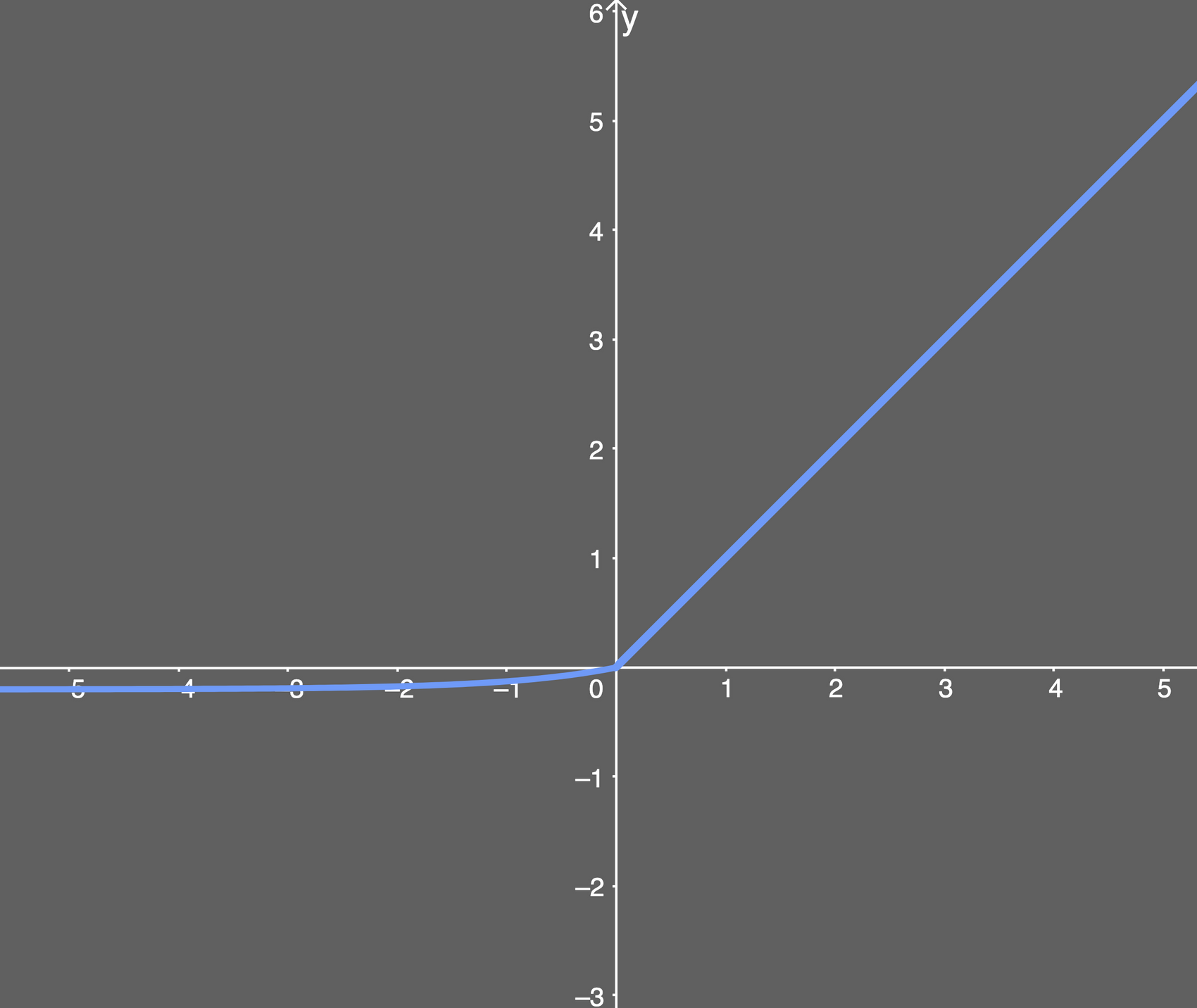
2.优缺点
保证Relu优势的同时,缓解神经元死亡问题。
六、Gelu
1.函数与图像
![]()
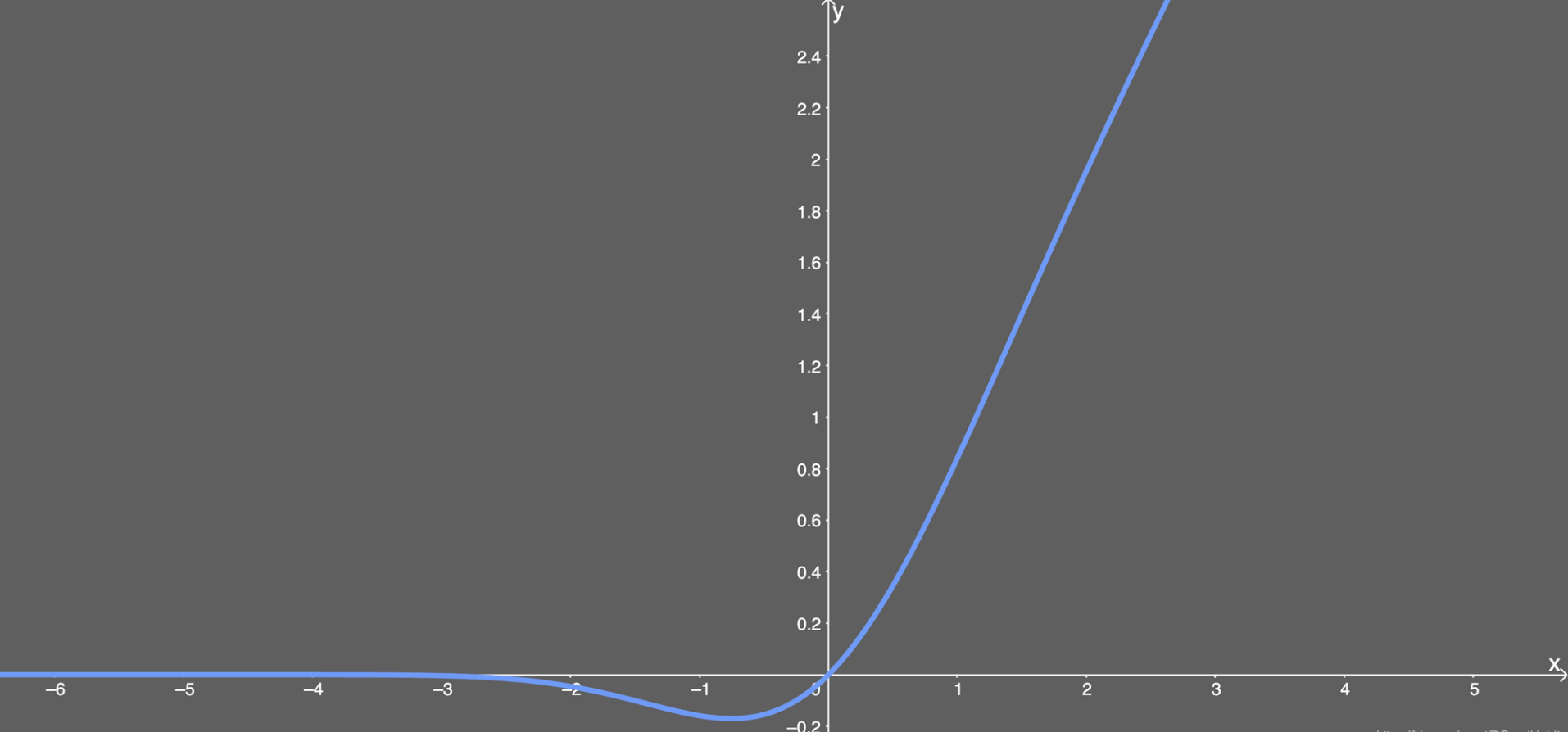
2.优缺点
GeLu函数综合了dropout和ReLu的特色,即加入随机正则提高模型泛化性能,在Transformer中较常使用,比Relu,Elu等效果好。
七、softmax
1.函数与图像:
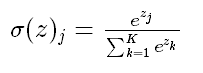
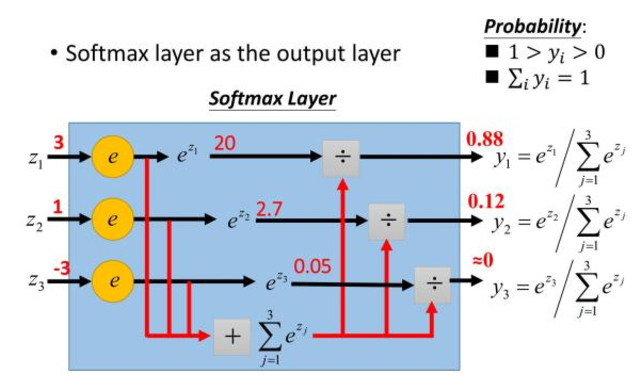
2.一些问题:
为什么要取指数?
第一个原因是要模拟 max 的行为,所以要让大的更大。第二个原因是需要一个可导的函数。
八、一些问题
1.为什么要用激活函数?
答:如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
2.互相比较:
sigmod与softmax:
sigmod做二分类,softmax做k分类的概率值;二分类问题时 sigmoid 和 softmax 是一样的,求的都是 cross entropy loss,而 softmax 可以用于多分类问题,softmax是sigmoid的扩展;softmax建模使用的分布是多项式分布,而logistic则基于伯努利分布。

