【图像匹配】Superpoint+AslFeat+SIFT+Superglue
一般图像匹配步骤:提取关键点、提取描述子、最近邻匹配、外点滤除、求解几何约束。其中外点滤除可用最优次优比限制、Ransac等。
一、Superpoint
1.基本原理
Superpoint是2018年的、基于CNN的、自监督的、用于同时提取图像关键点和描述子的网络模型。
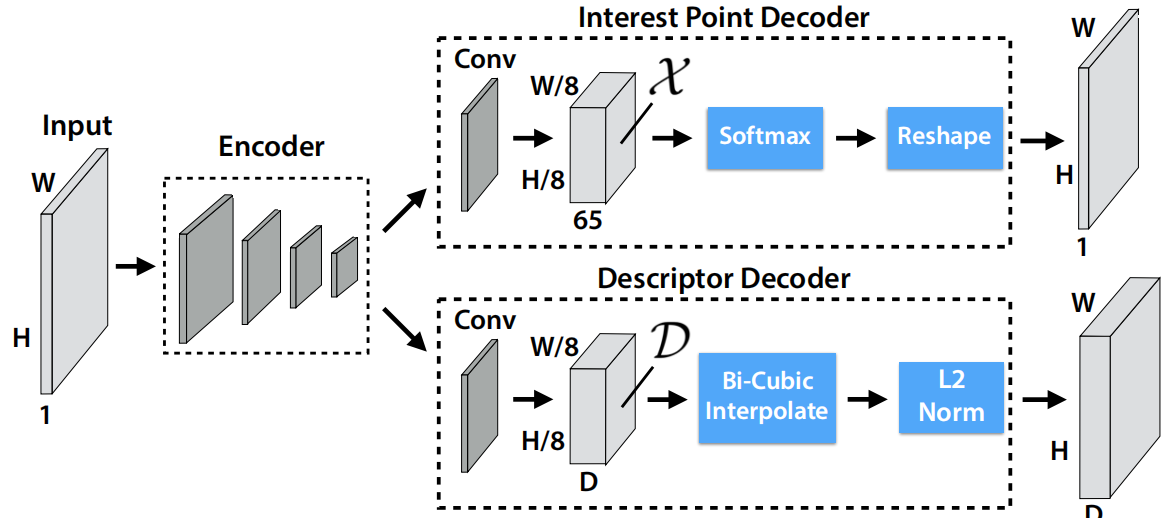
基本思想是,首先将图像输入到普通Encoder(例如VGG)中提取基础特征,然后在输出特征图后接2个分支,分别用来提取关键点和描述子。其中,用于提取关键点的分支是把图像转换成H/8*W/8*65的tensor(可以理解为每个cell对应8*8的区域是关键点的概率,如果都不是关键点则在最后一维进行表示,所以是65)。最后经过softmax和reshape获得H*W*1的tensor,该tensor表示是否为关键点的概率。另一描述子提取分支先是把feature map转换为H/8*W/8*D的tensor,然后经过差值和归一化就得到了H*W*D的tensor,该tensor表示每个像素的描述子。
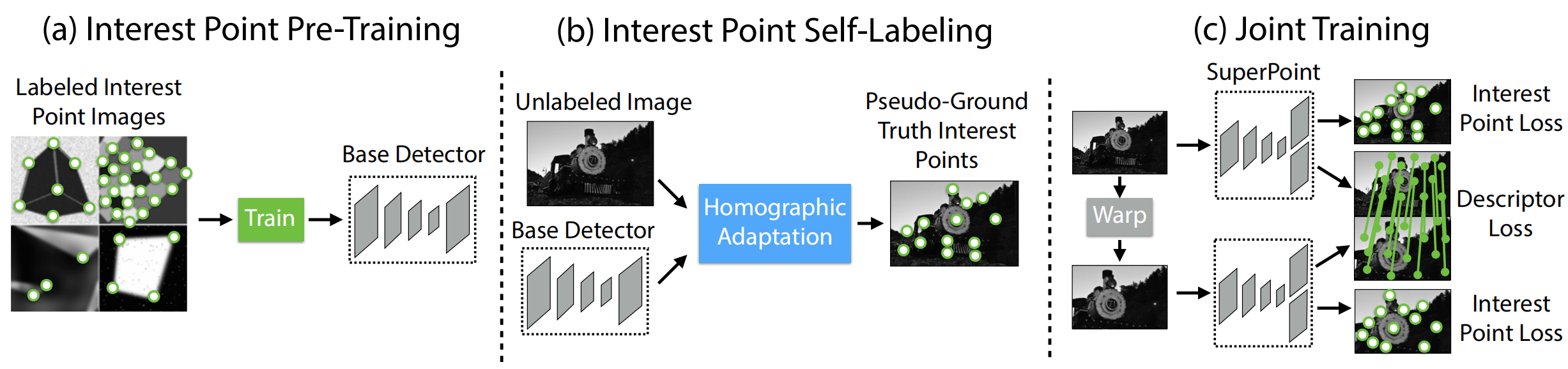
模型的训练需要损失函数,其中损失函数包括关键点损失和描述子损失。描述子用的是Tripple Loss,也就是同类别间的损失小于不同类别间的损失。具体来说是把一对图像A、B分别输入到网络中,其中B是A经过单应性变换来的,所以AB图像中关键点的对应关系是已知的,那么Tripple Loss就是要限制配对关键点Loss小于不配对的关键点Loss。关键点用的是交叉熵损失,要知道的是关键点的位置。因此在训练前,需要获得关键点的位置和成对图像中关键点的对应关系。
关键点位置和对应关系的获取包括以下几步:
1)学习一个Base Detector用于提取简单图像的关键点。方法是随机生成虚拟的三维物体,这些物体角点已知,也就是随机生成已知关键点真值的简单数据集。用该数据集去训练网络,该Base Detector就有了提取基础关键点的能力。
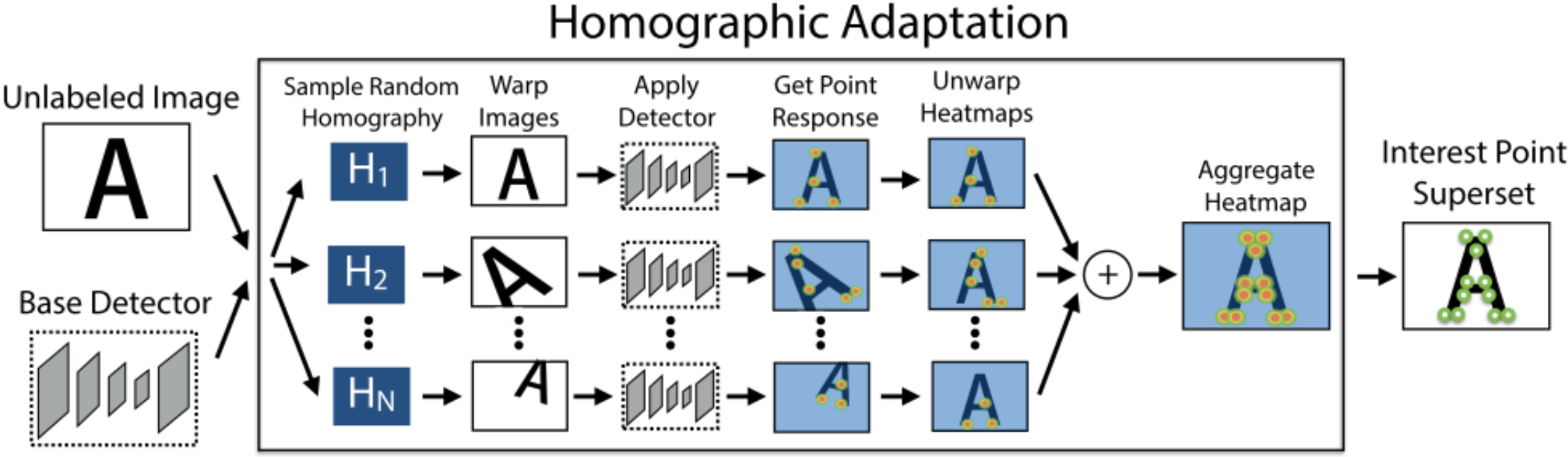
2)提取任意图像的关键点。方法是:把未知关键点的图像做多种单应性变换,变换后的图像都通过Base Detector获得关键点,然后把关键点映射回原图上,再进行合并就得到了完整的关键点。
3)获得对应关系。方法是:把提取完关键点的图像进行单应性变换,变换后的关键点和原始关键点就是互相匹配的。
2.网络结构

3.参考资料
https://www.cnblogs.com/programmerwang/p/15708077.html#gallery-2
二、AslFeat
1.基本原理
Aslfeat是2020年的、用于提取关键点和描述子的模型。
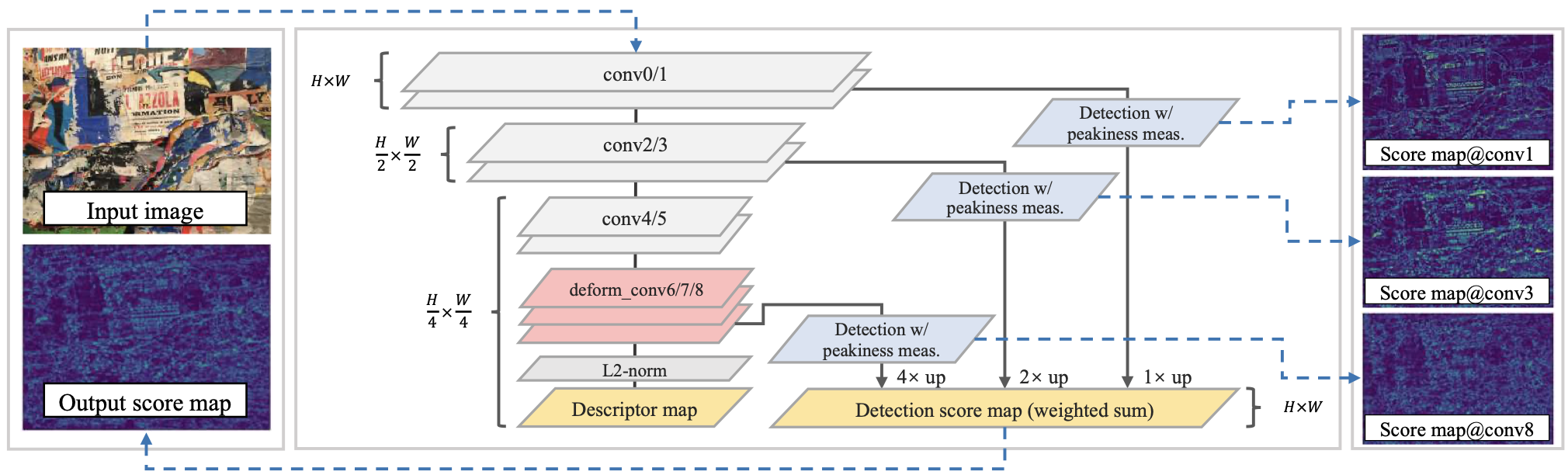
主要思想是把关键点和描述子同时检测出来,即学习出的tensor中的既可以作为每个像素上的描述子,又作为关键点。同时加入了特征金字塔和可变形卷积。具体流程为输入图像通过不断卷积和池化获得不同大小的feature map,最后一层1/4大小的tensor经过归一化就获得了描述子(即4*4个像素对应一个描述子),1/4的tensor和1/2,1/1的分别先按通道方向和单特征图方向分别进行打分相乘得到每个像素是否是关键点的概率图,然后把概率图上采样到原图大小后进行加权得到最终概率图。
训练时真值(关键点和关键点的配对关系)是已知的,可能是三维重建获得的。Loss是Tripple Loss,即匹配的点对对应的描述子距离小于不匹配的描述子距离。
2.网络结构
3.参考资料
https://blog.csdn.net/weixin_43605641/article/details/121465839
https://arxiv.org/pdf/2003.10071.pdf
三、SIFT
1.基本原理
SIFT用来提取图像的关键点和描述子,具有尺度不变性,对光照、颜色、视角变化等也具有一定的不变性。
关键点的生成主要思想是在高斯差分金字塔中找极值,加上一些细节的处理,如去除噪声和边缘效应以及极值点进行精确等。
描述子的生成需要先计算关键点的方向,方向是在一定范围内对像素的梯度方向按大小和距离做加权,选择数值的方向作为关键点的方向,描述子是把一定范围内的图像旋转至主方向然后16个格子的方向进行8个方向的直方图统计,即生成128维的描述子。
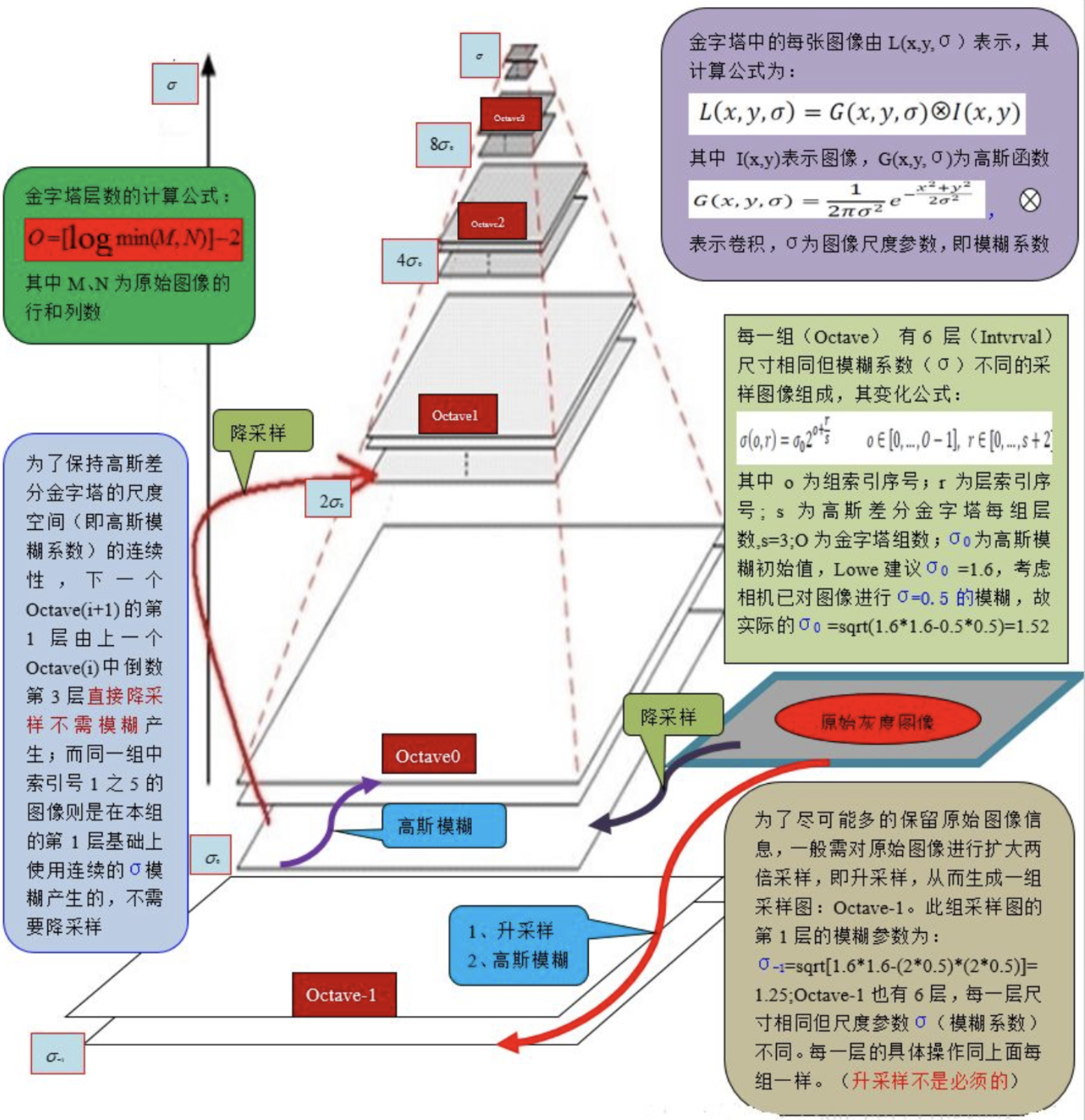
2.高斯差分金字塔的生成
通过下采样获得多组不同尺度的图像,在每组中通过高斯模糊获得不同清晰度的图像,称为高斯金字塔。在高斯金字塔每组的相邻图像求差值,获得高斯差分金字塔。
3.关键点的生成
1)阈值化。用于去除噪声和不稳定像素点。![]() 。 T=0.04,n为待提取特征的图像数。
。 T=0.04,n为待提取特征的图像数。
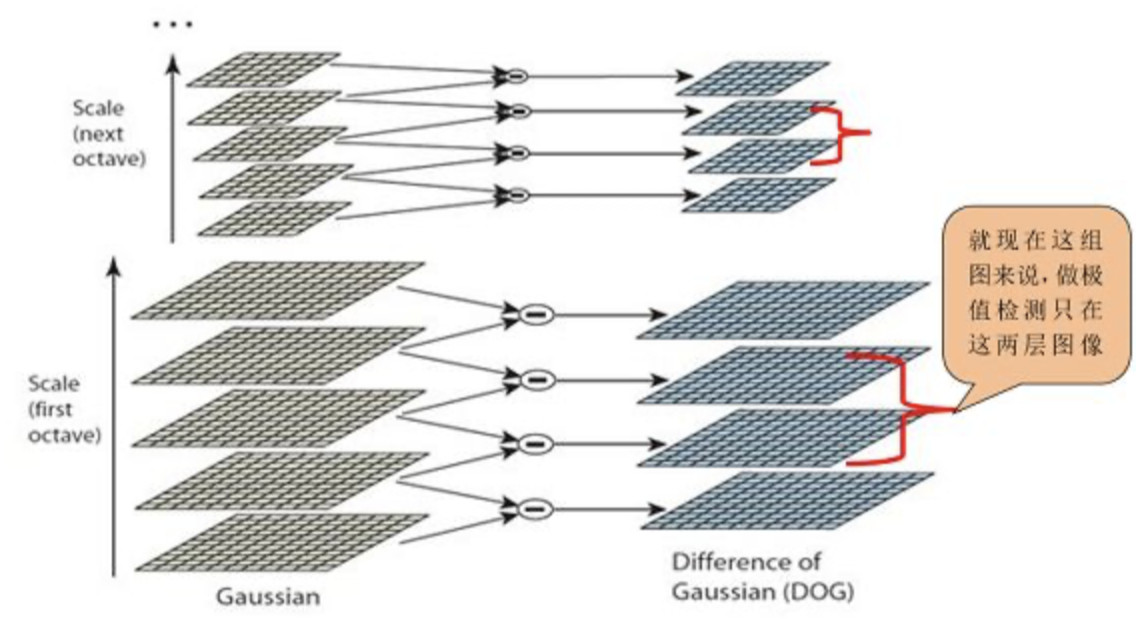
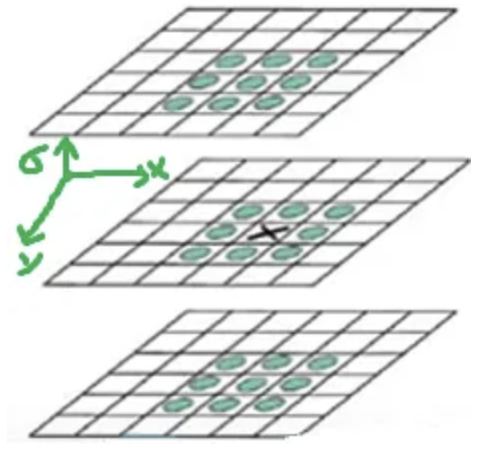
2)在高斯差分金字塔中找极值点。在高斯差分金字塔中,在XYZ3个方向均为极值的是关键点的备选,称为极值点。
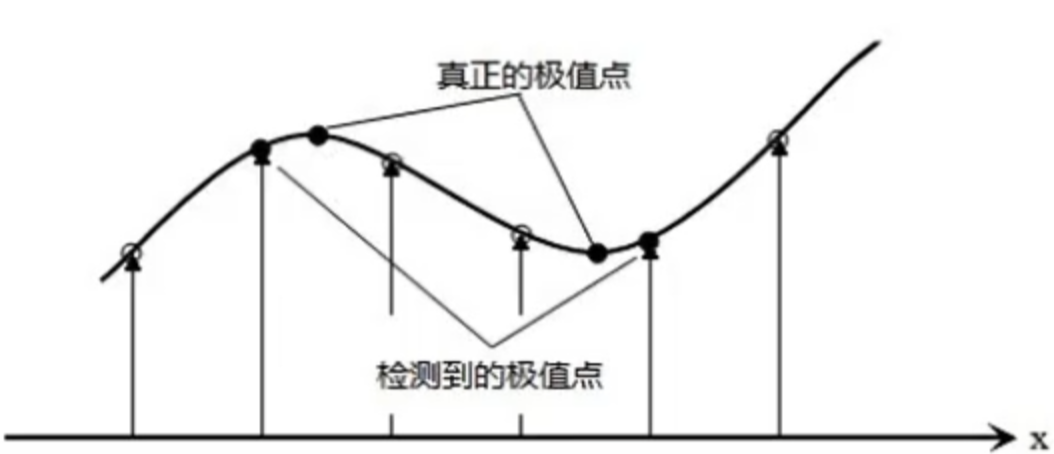
3)更正极值点的位置。高斯差分金字塔是离散的,所以找到的极值点不太准确的,很大可能在真正极值点附近,为了找到更高亚像素位置精度的极值点,需利用泰勒展开式。
4)舍去低对比度的点。
5)去除边缘效应。
4.关键点方向的生成
统计以特征点为圆心,以该特征点所在的高斯图像的尺度的1.5倍为半径的圆内的所有的像素的梯度方向及其梯度幅值,并做1.5σ的高斯滤波。
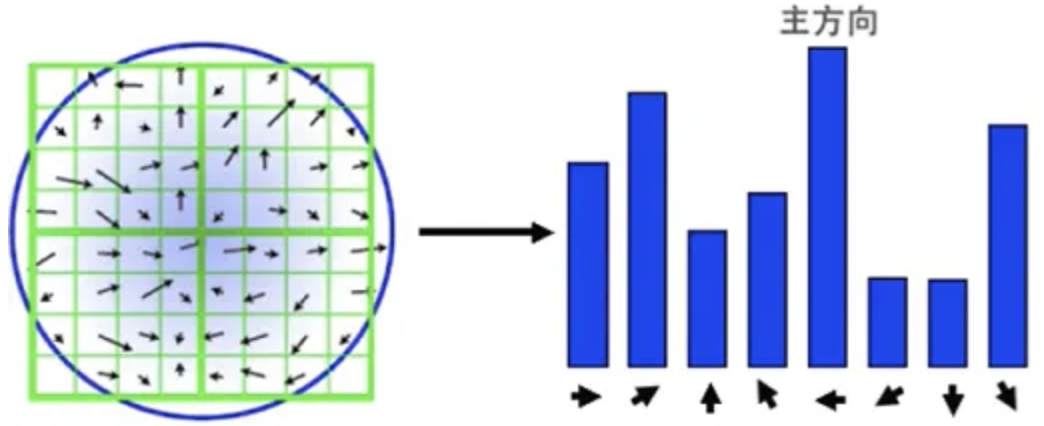
5.描述子的生成
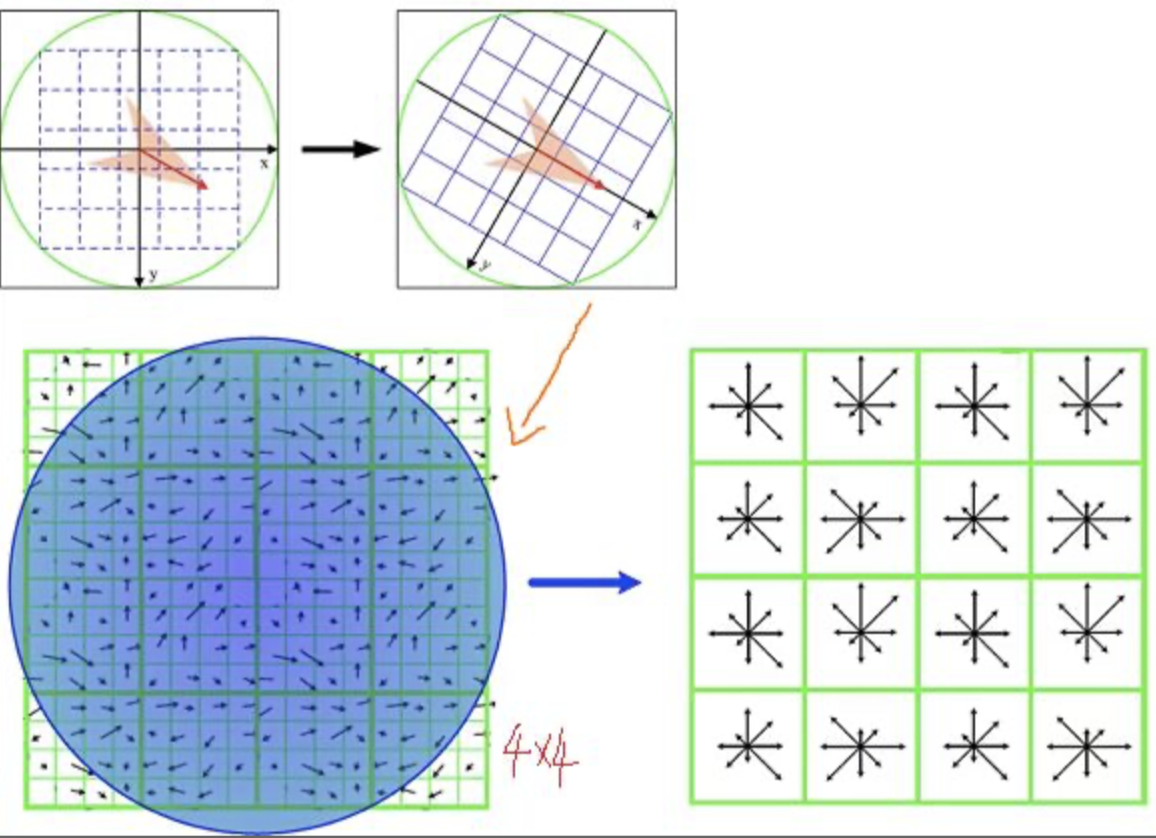
1)确定计算描述子所需的图像区域。
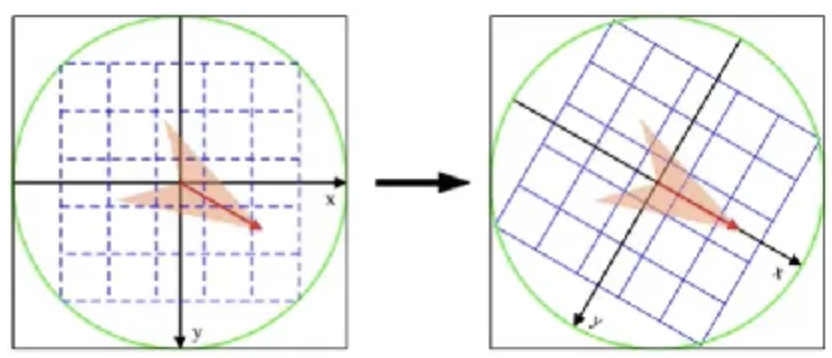
2)将坐标移至关键点方向。
3)生成关键点描述符。将区域划分为4×4的子块,对每一子块进行8个方向的直方图统计操作,获得每个方向的梯度幅值,总共可以组成128维描述向量。
6.参考资料
https://zhuanlan.zhihu.com/p/343522892?ivk_sa=1024320u
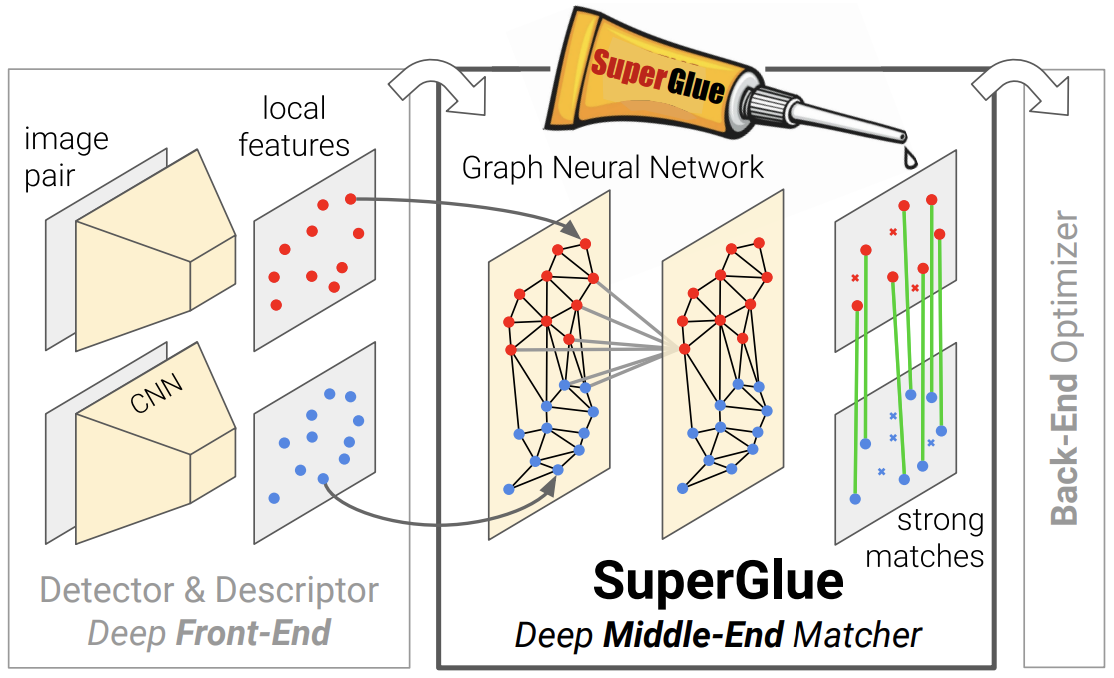
四、Superglue
1.基本原理
Superglue是2020年用于关键点(包括描述子)匹配的模型。
基本思想是模拟人眼找匹配关系的过程,即来回浏览两张图根据上下文关系增强特征点的特异性。实现上把注意力机制引入到网络中,用于学习图内和图间关键点的关系,从而构造一个分配矩阵(可以理解为两图关键点间的相似度),最后用sinkhorn算法求解分配结果。
Superglue框架分为注意力图神经网络模块和最优匹配模块。其中,注意力图神经网络模块首先把特征点和描述子编码为一个向量,然后利用self-attention和cross-attention捕获图像内和图像间关键点的关系,这个过程来回迭代,从而增强向量的匹配性能。最优匹配模块是通过计算特征匹配向量的内积来获得匹配度得分矩阵,然后用sinkhorn算法迭代求解分配结果。
sinkhorn算法是用于解决最优传输问题,要解决的是把得分矩阵代价最小地转为0/1的分配。(理解为多名同学对多门课有不同分值的喜爱程度,sinkhorn优化使得每个人选一门课、加起来喜爱度最高)
2.网络结构

3.参考资料
https://arxiv.org/pdf/1911.11763.pdf
https://zhuanlan.zhihu.com/p/146389956

 浙公网安备 33010602011771号
浙公网安备 33010602011771号