
【深度学习】基础网络Swin+ViT
一、Swin
1.基本思想
swin transformer是微软2021年发表的文章,是基于transformer的模型。
主要流程是,首先将图像输入到patch partition中进行分块,然后进行线性变换,这两步可以理解为把图像切了许多小块形成了token,这样就可以输入到后续的tranformer模块。后面串联的是4个swin tranformer block模块,分别构建不同尺度的feature map,每个模块前都有patch merge步骤。patch merge的做法是先将feature map分成patch,然后进行拼接以及concat,最后LayerNorm和全连接线性变换,经过这一步feature map的宽高会减半深度会翻倍。
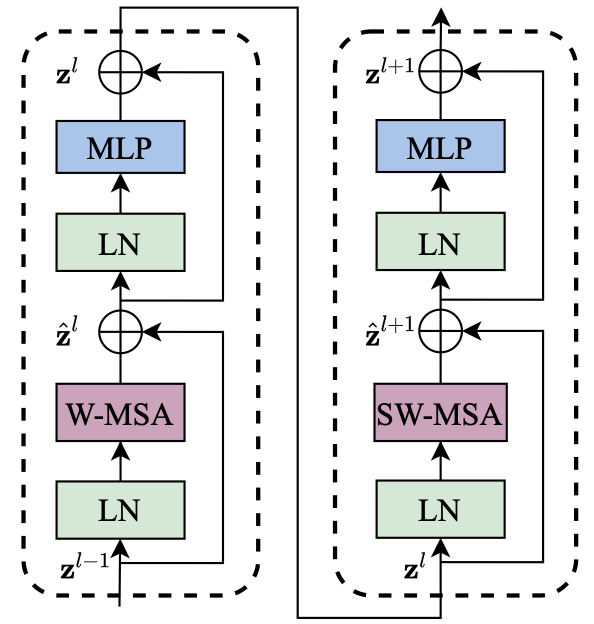
最关键的是swin tranformer block模块,该模块把self-attention模块进行了修改,修改后有两种结构,包括windows multi-head self-attention(窗口多头自注意力)和shifted window multi-head self-attention(平移窗口多头自注意力),这两种结构的swin tranformer block交替出现。修改的目的是减少计算量,做法是把在全局做self-attention改为首先把feature map切成许多小block然后再每个block内部进行self-attention,这叫做窗口多头自注意力。同时为了在各个block间信息传递,切分block时进行了shift,可以理解为非均匀切分feature map,这叫做平移窗口多头自注意力。这两个模块交替出现就可以减少计算量并且能获得全局的信息。
2.网络结构
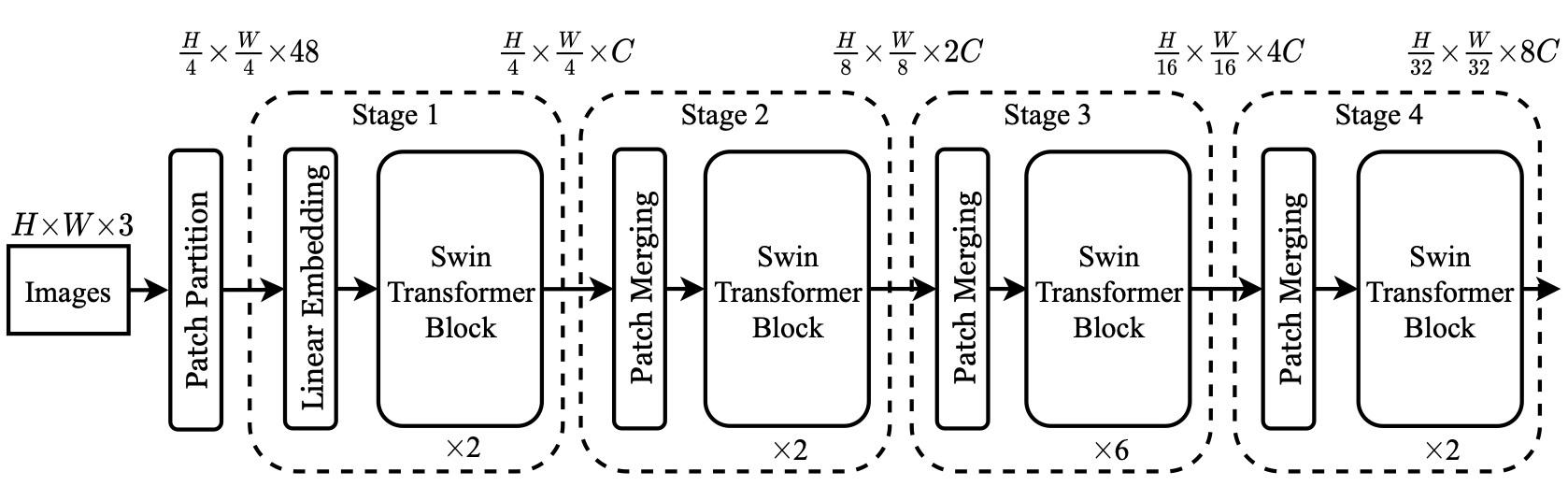
3.详解
3.1.patch partition
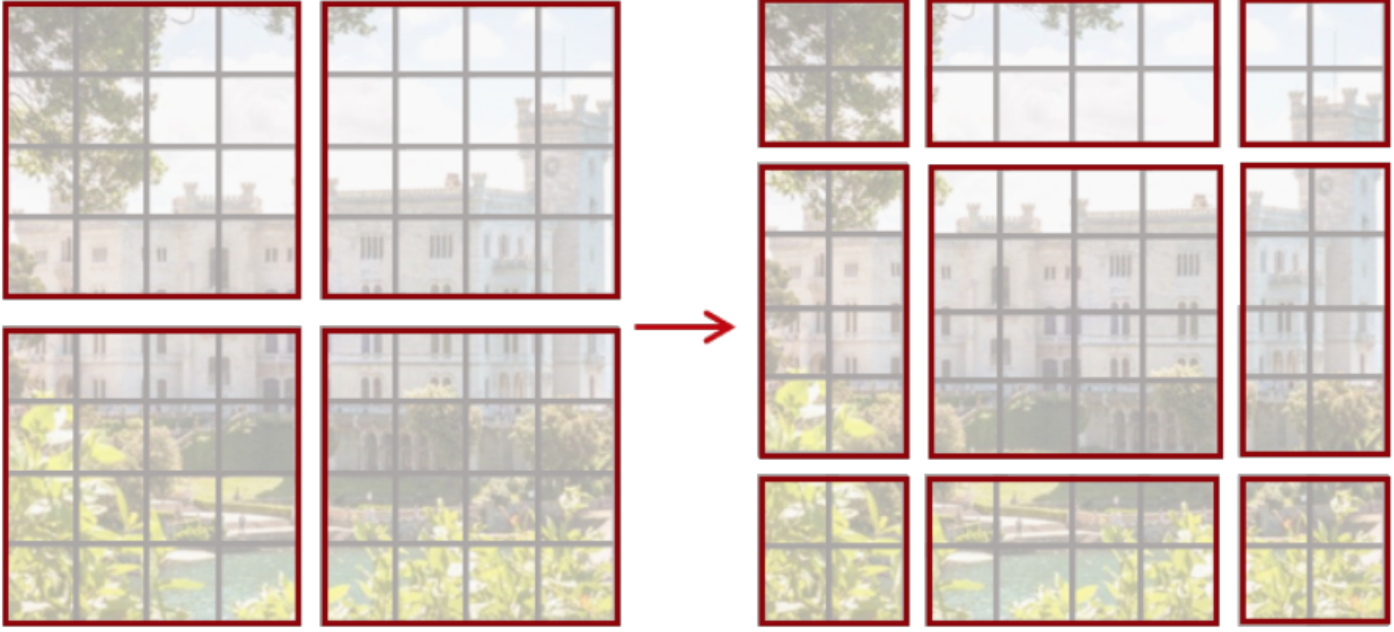
每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten),通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48](RGB3个通道)。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。在源码中Patch Partition和Linear Embeding是通过一个卷积层实现的。
3.2.patch merge
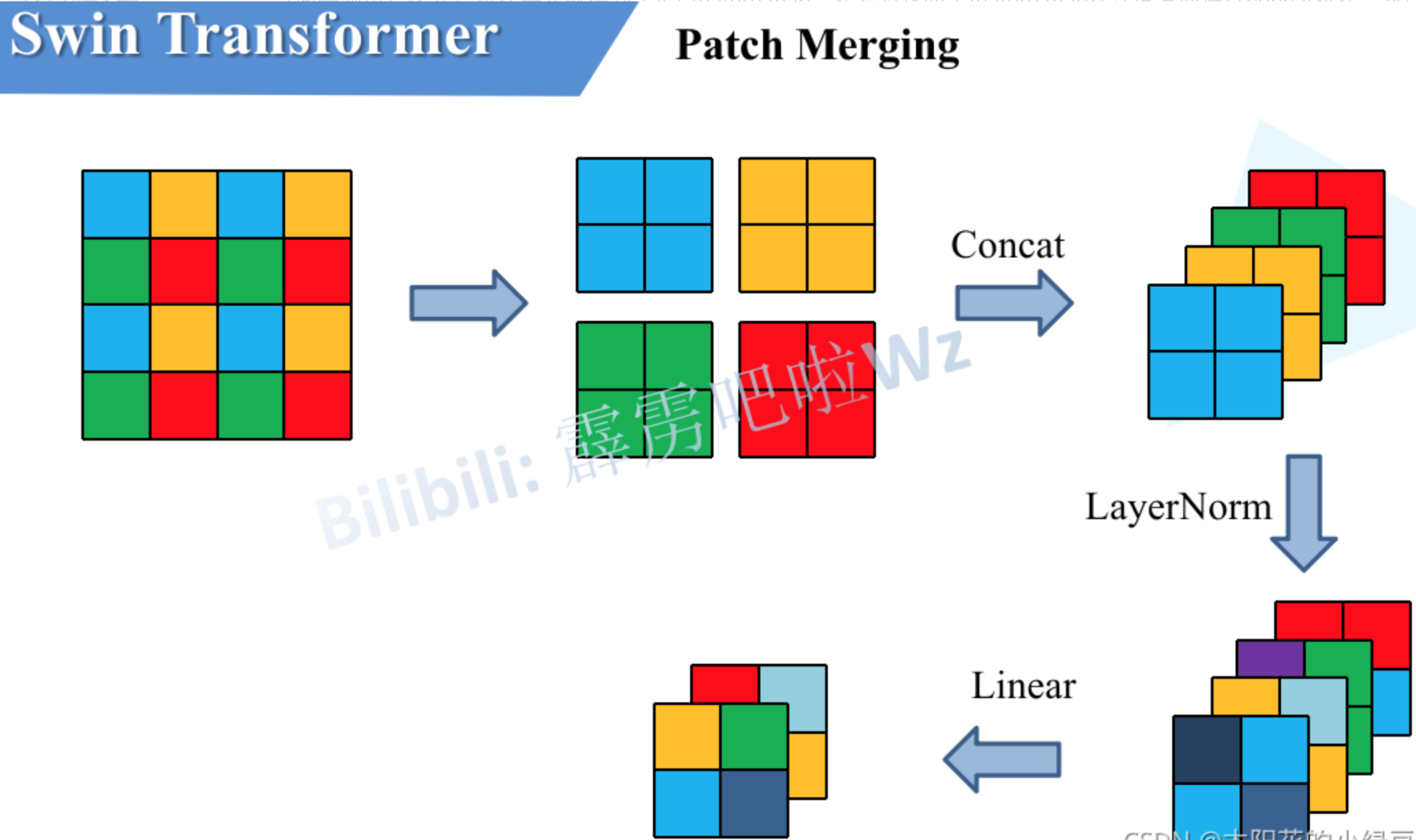
3.3.MSA/SW-MSA
4.参考资料
https://blog.csdn.net/qq_37541097/article/details/121119988
二、ViT
1.基本原理
2021年的谷歌团队的方法,虽然不是首次将transformer应用到图像分类领域,但模型简单效果好且可扩展性强,因此成为了Transformer在CV领域的里程碑著作。
主要思路是将图像分为16*16的块,然后经过线性变换再加上类别作为块的输入,接着加上位置编码输入(sum不是concat)到Transformer Encoder中,最后通过MLP(多层感知机)头获得类别。
当有足够的数据进行预训练时,ViT的表现会优于CNN,否则会差一些,原因是CNN有局部性(图片上相邻的区域具有相似的特征)和平移不变形这两种先验知识。
微调:当图像块变大时,理论效果会变好,但位置信息会变得不可用因为大图片和小图片被切分成了不同的块数,位置信息变得无效。可以线性插值,但效果会降低。
2.网络结构
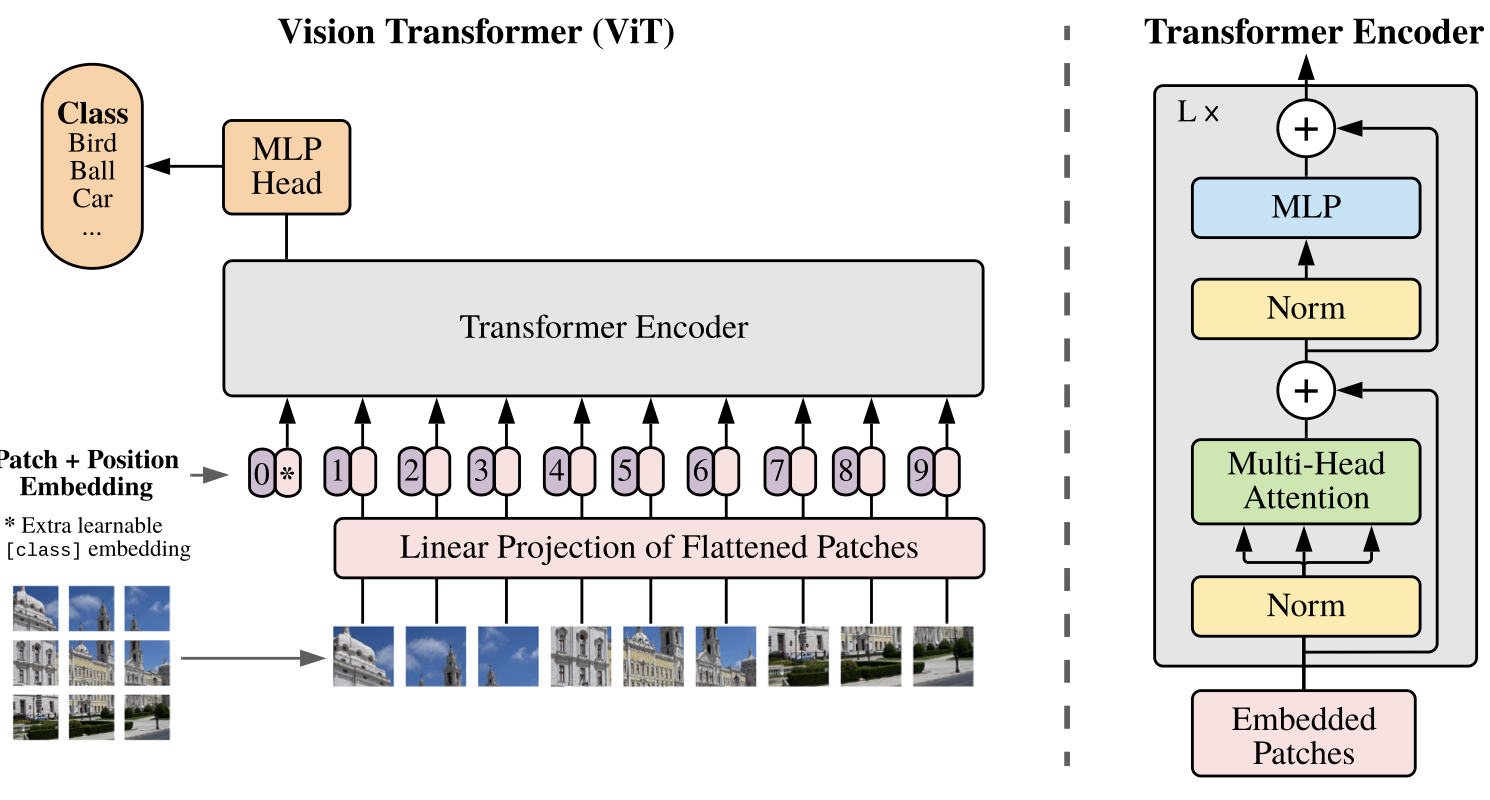
3.参考资料
https://zhuanlan.zhihu.com/p/445122996
https://arxiv.org/pdf/2010.11929.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号