
【pytorch】 train demo
一、用pytorch实现lenet类似网络的训练
1.网络结构
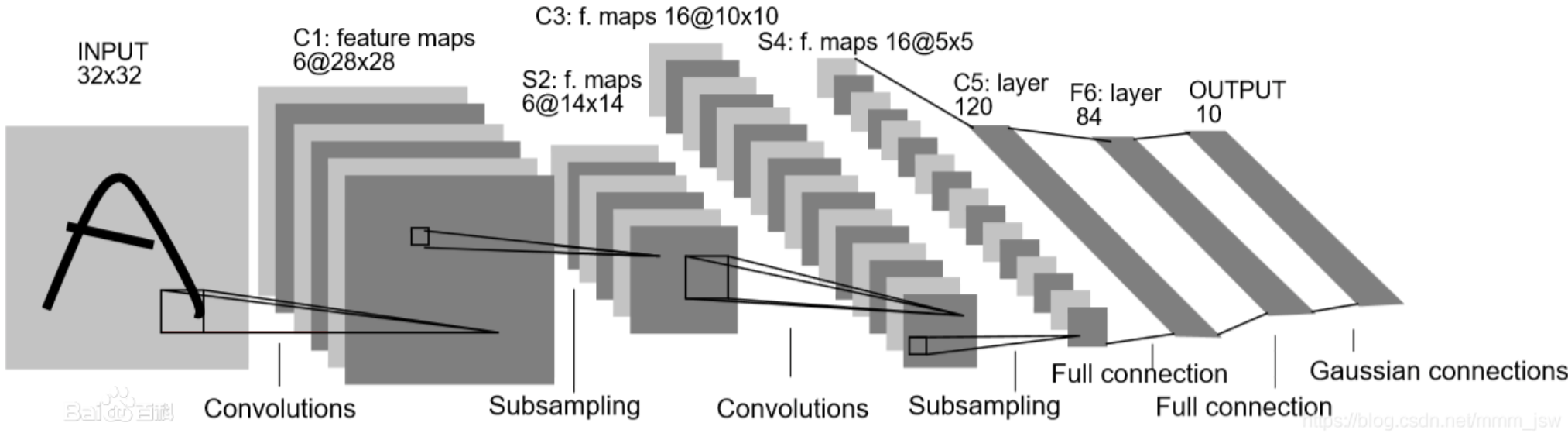
2.代码
from torch import nn, optim import torch.nn.functional as F import torchvision import torchvision.transforms as transforms from torch.utils.data import DataLoader import pdb def get_data(): transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))] ) train_data = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) train_loader = DataLoader(train_data, batch_size=50, shuffle=False, num_workers=0) test_data = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform) test_loader = DataLoader(test_data, batch_size=1000, shuffle=False, num_workers=0) test_data_iter = iter(test_loader) test_image, test_label = test_data_iter.next() return train_loader, test_image, test_label class Lenet(nn.Module): def __init__(self, num_classes): super(Lenet, self).__init__() self.conv1 = nn.Conv2d(3, 16, 5) self.pool1 = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(16, 32, 5) self.pool2 = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(32 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28) x = self.pool1(x) # output(16, 14, 14) x = F.relu(self.conv2(x)) # output(32, 10, 10) x = self.pool2(x) # output(32, 5, 5) x = x.view(-1, 32 * 5 * 5) # output(32*5*5) x = F.relu(self.fc1(x)) # output(120) x = F.relu(self.fc2(x)) # output(84) x = self.fc3(x) # output(10) return x def train(train_loader, test_image, test_label): net = Lenet(10) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") net.to(device) loss_func = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001) for epoch in range(100): running_loss = 0.0 for step, data in enumerate(train_loader, start=0): inputs, labels = data optimizer.zero_grad() outputs = net(inputs.to(device)) loss = loss_func(outputs, labels.to(device)) loss.backward() optimizer.step() running_loss += loss.item() if step % 1000 == 999: with torch.no_grad(): outputs = net(test_image.to(device)) # 将test_image分配到指定的device中 predict_y = torch.max(outputs, dim=1)[1] accuracy = (predict_y == test_label.to(device)).sum().item() / test_label.size(0) print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' % (epoch + 1, step + 1, running_loss / 1000, accuracy)) running_loss = 0.0 if __name__ == '__main__': train_loader, test_image, test_label = get_data() train(train_loader, test_image, test_label)
二、用pytorch实现一个基础函数
from torch import nn, optim import torch.nn.functional as F import torchvision import torchvision.transforms as transforms from torch.utils.data import DataLoader, TensorDataset import torch class Net(nn.Module): def __init__(self, n_feature, n_hidden, n_output): super(Net, self).__init__() self.fc1 = nn.Linear(n_feature, n_hidden) self.fc2 = nn.Linear(n_hidden, n_output) def forward(self, x): x = F.relu(self.fc1(x)) x = self.fc2(x) return x def get_data(): x = torch.unsqueeze(torch.linspace(-1,1,10), dim=1) y = torch.linspace(9, 0, 10).to(dtype=torch.long) train_data = TensorDataset(x, y) train_loader = DataLoader(train_data, batch_size=3, shuffle=False, num_workers=0) return train_loader def train(train_loader): net = Net(n_feature=1, n_hidden=10, n_output=10) loss_func = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001) for epoch in range(100): # train for step, (x, y) in enumerate(train_loader): optimizer.zero_grad() output = net(x) loss = loss_func(output, y) loss.backward() optimizer.step() for step, (x, y) in enumerate(train_loader): # val output = net(x) predict_y = torch.max(output.data, 1)[1] correct = (predict_y == y).sum() total = y.size(0) print('Epoch: ', step, '| test accuracy: %.2f' % (float(correct) / total)) if __name__ == '__main__': train_loader = get_data() train(train_loader)
博文转载请注明出处。

