

【实例分割算法】Mask2former及其相关方法
导读:
由于mask2former是在transformer发展较久才出来的,学习mask2former之前有一些方法的依赖(如mask2former是在maskformer上进行的改进,而maskformer又有detr的影子等),因此在本次整理中附加了一些相关方法/概念,以便更好地理解mask2former。
注:本文所有内容均为本人的个人理解,个人学习用,因此接受互相讨论,不接受批评。
一、大致脉略
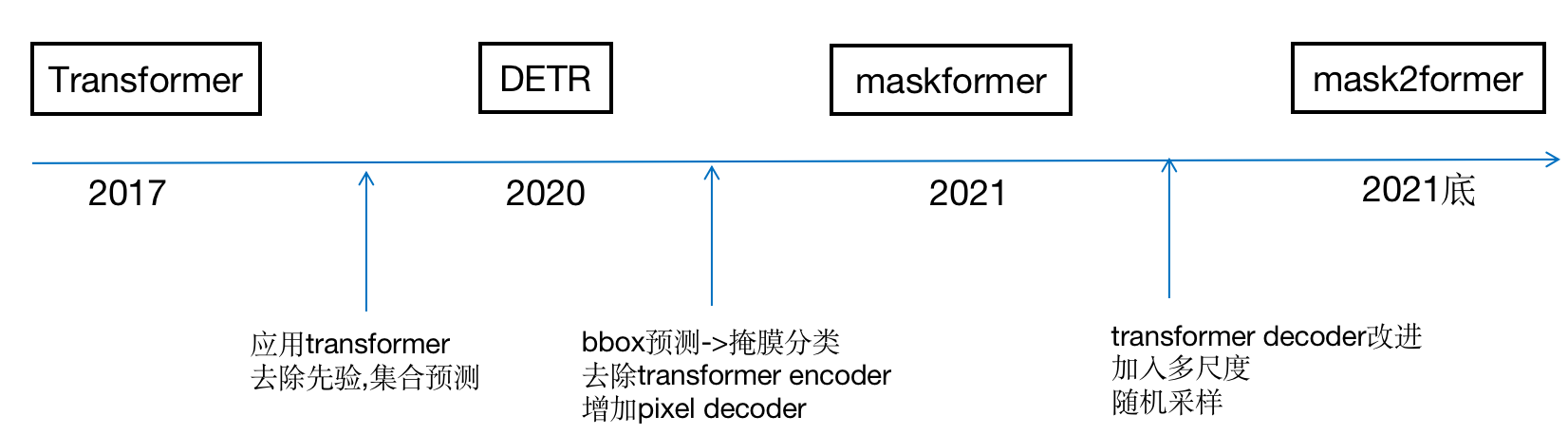
二、Mask2former
1.基本原理
mask2former是Facebook团队在2021年底提出的基于Transformer的端到端的检测、分割框架,是对2021年maskformer的进一步改进。
maskformer的基本思想是把语义分割、实例分割用一个统一的框架、损失和训练过程来实现,都定义为掩膜分类任务,如果是语义分类任务在推理阶段加一个组合层即可获得预测结果。maskformer与detr思想类似,都是去除人工先验,把实例分割作为一个集合预测问题来看待。大致过程是,首先用backbone提取图像基础特征,然后分2个分支,一个分支通过pixel decoder模块生成pixel的embedding,一个分支是通过transformer decoder生成N个segment,然后segment后加FC和softmax就得到了类别的概率估计。对于mask的预测,是先通过N个segment经过两层的MLP生成N个mask embedding,然后mask embedding和前面的pixcel embedding相乘加sigmod激活函数得到的。在计算Loss是用二分图匹配来配对预测和真值构造集合损失,从而简化pipline实现端到端的目标检测。
mask2former在maskformer的基础上主要做了3个方面的改进。一个是Transformer Decoder中加attention改成mask attention并和self attention换位置,以保证前景间互相attention忽略背景的干扰。一个是加了多尺度的特征,也就是把pixel decoder的不同层作特征金字塔分别输入到transformer decoder的不同层中,以提升小目标的识别效果。最后是在少量采样随机点而非全图上计算mask loss,以提升速度。
2.网络结构
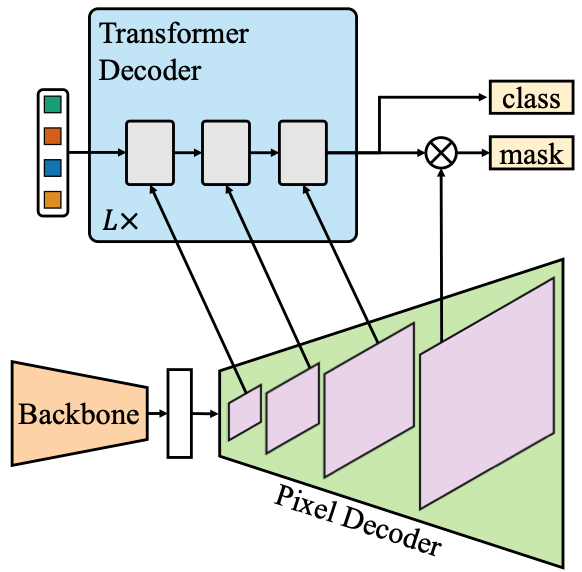
3.相比maskformer做的改进
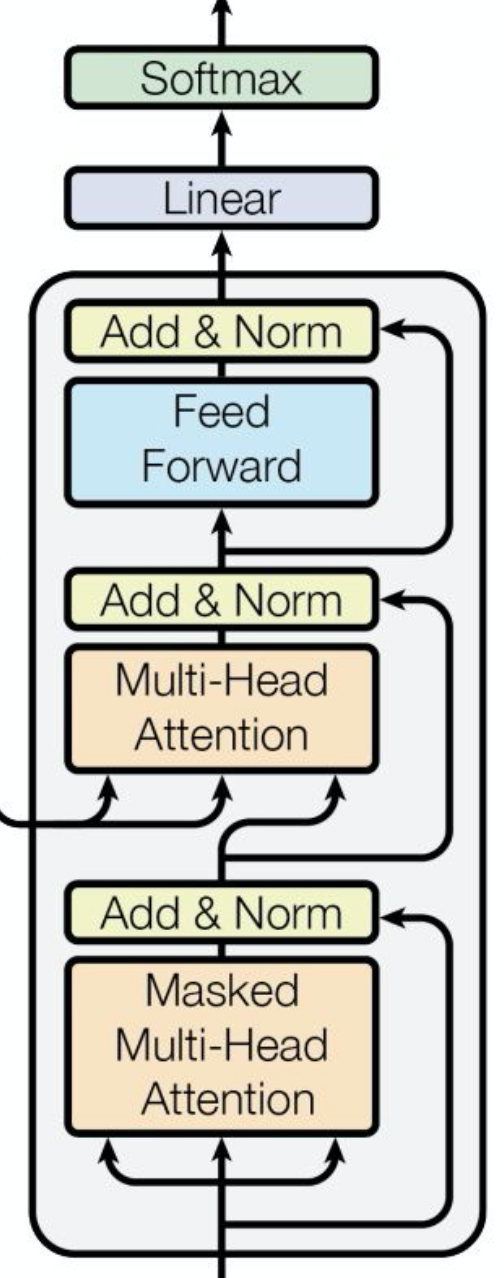 ----->
----->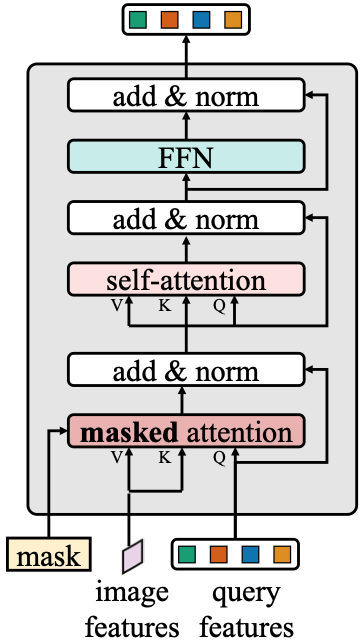
1)Transformer decoder模块的改进
标准decoder结构做了4步修改:attention和self-attention调换位置;self-attention改成masked attention(加入了mask),输入decoder中的除了query和image feature还有mask;使查询特征Query也可学习;去掉dropout。
修改的原因:attention放在第一步用处不大;mask attention用来控制哪些token能够产生attention,原本是每个像素和整张图做attention,现在这个像素只和都是query的像素做attention,也就是只要前景目标间做attetion背景不需要参与。
2)加了多尺度特征:
在transformer decoder的不同层中,加入pixel decoder中的不同层作为输入,这些不同分辨率的层同时也都加入了正弦位置embedding和一个可学习的尺度embedding。
修改的原因:作为特征金字塔,提升小目标的识别效果。
3)随机采样提升速度:
在少量随机采样点上计算mask loss。原本是在整张图上计算loss,现在在二分匹配时进行预测进行均匀采样,在最终loss计算时采用重要性采样。
修改的原因:提升效率。
效果上:速度加快,显存降低,小目标效果提升。
4.参考资料:
https://blog.csdn.net/acx0000/article/details/125696782
https://arxiv.org/pdf/2112.01527.pdf
三、Maskformer
1.基本原理
maskformer是Facebook团队在2021年提出的基于Transformer的端到端的检测、分割框架。
maskformer的基本思想是把语义分割、实例分割、甚至全景分割都用一个统一的框架、损失和训练过程来实现。以往语义分割被定义为像素分类,实例分割定义为掩膜分类,现在都定义为掩膜分类任务,如果是语义分类任务在推理阶段加一个组合层即可获得预测结果。
除此之外,maskformer与detr思想类似,都是去除NMS/anchor等人工先验,把实例分割作为一个集合预测问题来看待。大致过程是,首先用backbone提取图像基础特征,然后分2个分支,一个分支通过pixel decoder模块生成pixel的embedding,一个分支是通过transformer decoder生成N个segment,然后segment后加FC和softmax就得到了类别的概率估计。对于mask的预测,是先通过N个segment经过两层的MLP生成N个mask embedding,然后mask embedding和前面的pixcel embedding点乘加sigmod激活函数得到的。在计算Loss是用二分图匹配来配对预测和真值构造集合损失,从而简化pipline实现端到端的目标检测。
2.网络结构
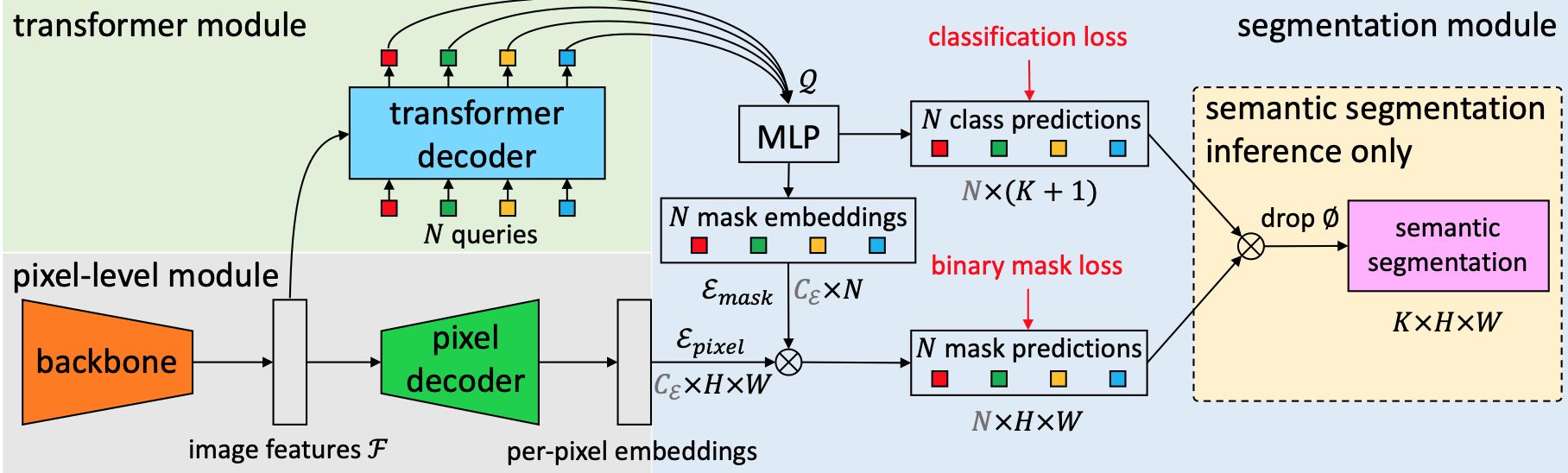
3.损失函数
包括mask损失和类别损失
![]()
4.相比detr的改进
1.去掉了box的预测,取而代之的是直接输出mask的分类
2.去掉了transformer encoder,增加了pixel decoder
5.缺点
训练效率低,显存开销大,小目标效果不好
6.参考资料
https://blog.csdn.net/acx0000/article/details/125690828
https://arxiv.org/pdf/2107.06278.pdf
四、DETR
1.基本原理
detr是Facebook团队在2020年提出的基于Transformer的端到端的检测框架。
基本思想是去除NMS/anchor等人工先验,把目标检测作为一个集合预测问题来看待,用一个标准的transformer encoder-decoder结构生成预测集合,用二分图匹配(匈牙利算法)来配对预测和真值来构造集合损失,从而简化pipline实现端到端的目标检测。
大致过程是,先用backbone提取图像基础特征,然后转换维度变成N个序列,再加上位置encoding输入到transformer的encoder中,最后用过transformer的decoder生成预测。encoder是多头self-attention模块和FFN模块。decoder时输入的query是位置的encoder。
2.网络结构


3.其他
1)detr为什么可以不用先验?
transformer中的self-attention机制能够模型化图像上集合中元素间的交互关系,且能够捕获全部上下文间的关系,使得这个架构十分适合集合预测的特定约束(比如删除重复预测)。
2)detr为什么要二分图匹配?
输出目标中顺序的变化不应该带来损失的变化,因此需要二分图匹配。
4.参考资料
https://blog.csdn.net/baidu_36913330/article/details/120495817
https://blog.csdn.net/amusi1994/article/details/116113351
https://arxiv.org/pdf/2005.12872.pdf
五、Transformer
1.基本原理
Transformer是Google团队在2017年提出的模型,其中的self-attention取代了NLP中常用的RNN。
Transformer本质是一个encoder-decoder架构。每个encoder由self-attention(自注意力)层和FFN(前馈网络)层组成,FFN是具有ReLu激活函数的2层全连接层,每个encoder的结构相同但权重不同。encoder的输入是一个序列,输出是一组注意力向量key和value。这些向量会作为decoder的输入。
encoder/decoder最关键的部分是attention和self-attention。
attention的作用是让模型对重要信息重点关注并充分学习,在cv中嵌入attention机制,实际是新建一层掩膜训练出新的权重,将图像中关键特征标识出来。
attention的本质是加权求和,权重是元素/序列间的相似度,softmax(XXt)X实现加权求和,QKV都是X的线性变换,线性变换是为了提升拟合能力。除分母是为了保证均值为0方差为1。
对self-attention来说,Query和Key,value都是相同的,序列中的每个元素都能与其他任意位置的元素建立敏感的关系。
多头注意力机制的多头表示对每个Query和所有的Key-Value做多次注意力机制,这样做的意义在于获取每个Query和所有的Key-Value的不同的依赖关系。
优点:self-attention可以建立全局的依赖关系,扩大图像的感受野,也可以获得要素间的各种依赖关系。相比于CNN,其感受野更大,可以获取更多上下文信息。
缺点:self-attention是通过筛选重要信息过滤不重要信息实现的,无法利用图像本身具有的尺度/平移不变性以及图像的特征局部性等先验知识,只能通过大量数据学习,因此只有大量数据基础上才能有效地建立准确的全局关系,而在小数据的情况下,其效果不如CNN。
2.网络结构
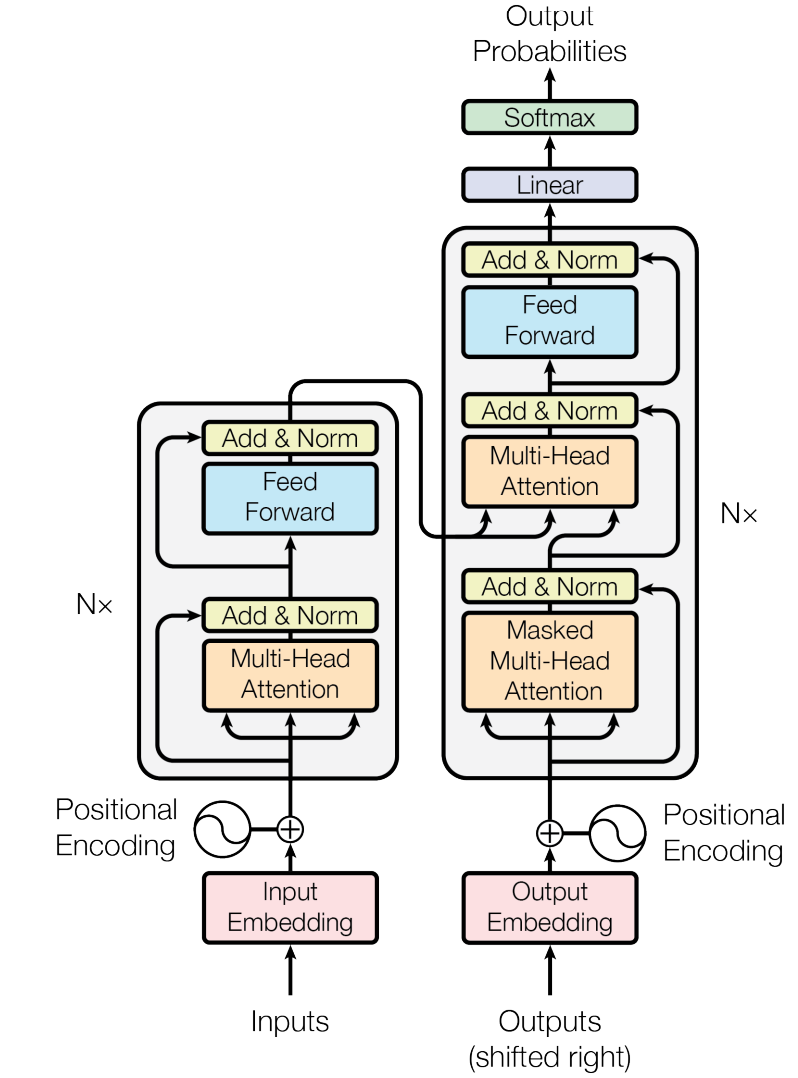
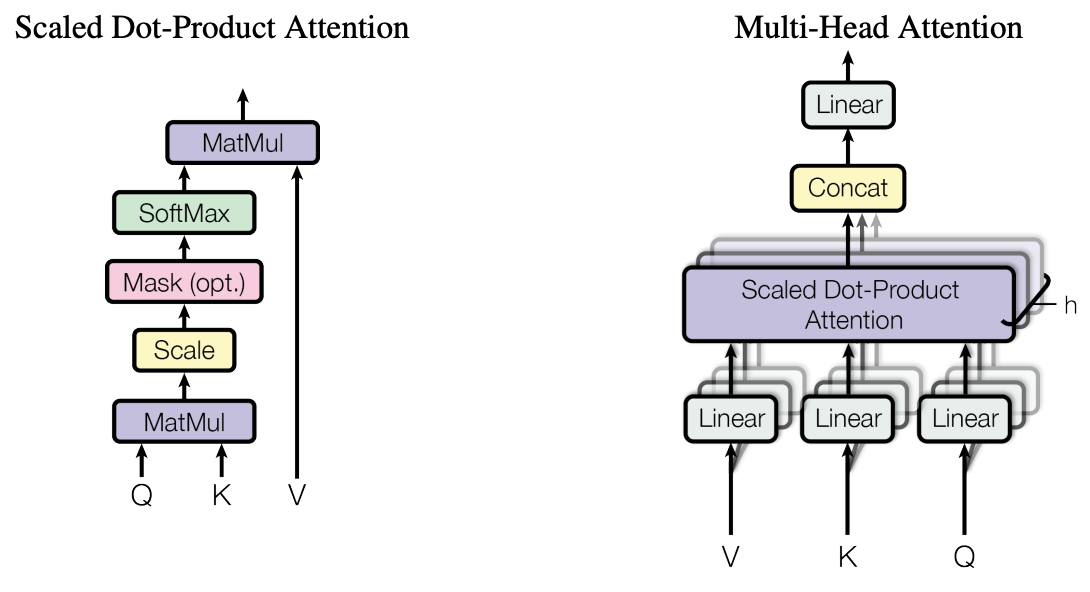
3.attention
![]()
可以分为基于输入项和基于位置两种:对于输入项,需要明确指出项的序列和通过预处理突出包含明确序列的项(可以是向量,或是图); 对于位置:需要单独指出特征项的突出位置。也可以分为柔性和硬性:柔性注意力(soft-Attention),更加注重图像中的通道或区域,是确定的注意力,训练完成后直接通过网络生成,而且由于可微,可通过不断地向前传播和反向传播来完善权重;硬性注意力(hard-Attention),相较于soft-Attention更加具体,更加注重某一点,对图像中每一点都会考虑到,每个点都有可能延伸出注意力出来,同时hard-Attention是一个随机过程,强调动态变化,而且不可微,一般通过强化学习对其完成训练。以上两种Attention机制都可以直接嵌入原网络中以增强对中心特征的选择。
对于视觉中注意力作用方向可分为三类:
空间域:由于pooling layer虽然起到下采样的作用,但不可避免地会造成信息的丢失,因此使用基于Attention机制的空间转化器模块把其进行取代。
通道域:图片的卷积过程,无非就是(R,G,B)通过卷积核的运算后变为(L,W,channel)的形式,而类比在模数转换或是更直接点通过傅氏变换,把时域信号映射到频域上,一个时域通道被分解变换成多个频域通道的信号。通过不断地训练,是不同卷积核所应射出的通道权重不同,进而选择出需要Attention的通道。
混合域:实际上就是通过把以上两种思想结合进行设计Attention模型,现在一般这种方法会更加普适。
4.多头注意力
由于self attention只从一个角度去学习关注点,可能会有点偏颇。所以,设计h种不同的权重矩阵对,然后做基本的attention操作前,将query,key和value分别用上述权重对做线性变换,然后再计算得到h个不同角度的attention权重 head ,将这些 head按列拼接后,再与一个新的权重矩阵做线性变换,得到最终的attention输出。
5.位置编码
6.参考资料
https://blog.csdn.net/benzhujie1245com/article/details/117173090
https://arxiv.org/pdf/1706.03762.pdf
https://zhuanlan.zhihu.com/p/46313756/
https://zhuanlan.zhihu.com/p/410776234
https://zhuanlan.zhihu.com/p/346427014
https://blog.csdn.net/weixin_43610114/article/details/126684999?spm=1001.2101.3001.6650.11&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-11-126684999-blog-119963140.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-11-126684999-blog-119963140.pc_relevant_default


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具